Разрушая традиционную парадигму предобучения больших моделей, команда выпускника 'Цинхуа' 00-х Вана Гуана представила новую работу:
Они заменили стандартный Transformer иерархической рекуррентной моделью (HRM), предложив эффективное предобучение HRM-Text, превосходящее Scaling.

Ссылка на статью: https://arxiv.org/abs/2605.20613
Используя примерно в 100-900 раз меньше обучающих токенов и, по оценкам, в 96-432 раза меньше вычислительных ресурсов, чем стандартная базовая модель, HRM-Text все равно продемонстрировал производительность, сопоставимую с открытыми моделями от 2B до 7B параметров.
При этом, используя 1B параметров, 40B уникальных токенов и стоимость обучения около 1500 долларов, HRM-Text достиг следующих результатов на основных бенчмарках: MMLU 60.7%, ARC-C 81.9%, DROP 82.2%, GSM8K 84.5%, MATH 56.2%.
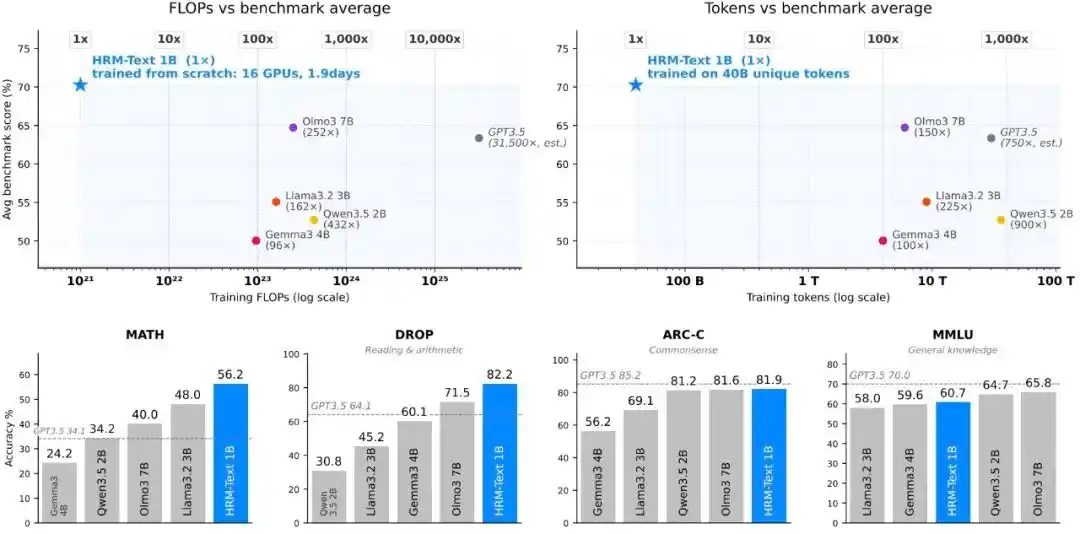
Рис.| Эффективность предобучения.
На этой основе они ясно заявили: Структурный приоритет и целенаправленные цели обучения могут значительно снизить порог предобучения. Эта схема обучения делает возможным обучение базовой модели с нуля.
Как устроен HRM-Text?
Предобучение больших языковых моделей (LLM) все больше зависит от ограниченного числа организаций, обладающих достаточными вычислительными и данными ресурсами. Обучение конкурентоспособной базовой модели часто требует триллионов токенов, тысяч GPU и даже десятков миллионов долларов на вычислительные мощности.
Однако текущий режим обучения неэффективен, большая часть вычислений тратится на промпты, форматное заполнение и веб-шум в нерелевантных токенах, в результате чего значительная часть тренировочных мощностей не служит непосредственно выводу.
В этой работе исследовательская команда переработала архитектуру и цели обучения, сделав предобучение HRM-Text относительно более эффективным.
Архитектура: Используется иерархическая рекуррентная модель с двумя временными масштабами, разделяющая вычисления на медленный H-модуль и быстрый L-модуль. Стандартный Transformer выполняет одно прямое распространение для каждого токена, тогда как HRM будет выполнять многораундовые рекурсивные обновления на одном и том же токене. Модули H и L каждый составляют лишь половину параметров рекурсивного ядра, а общий объем вычислений примерно эквивалентен 4-кратному рекурсивному развертыванию одного и того же набора параметров, что увеличивает вычислительную глубину без увеличения количества параметров.
Цель обучения: Вместо стандартного авторегрессивного предобучения на полном тексте, обучение проводится непосредственно на парах 'инструкция-ответ', потери рассчитываются только для части ответа, и в сочетании с маской PrefixLM, позволяя части инструкции иметь двунаправленное внимание, а части ответа генерироваться с причинно-следственной маской.
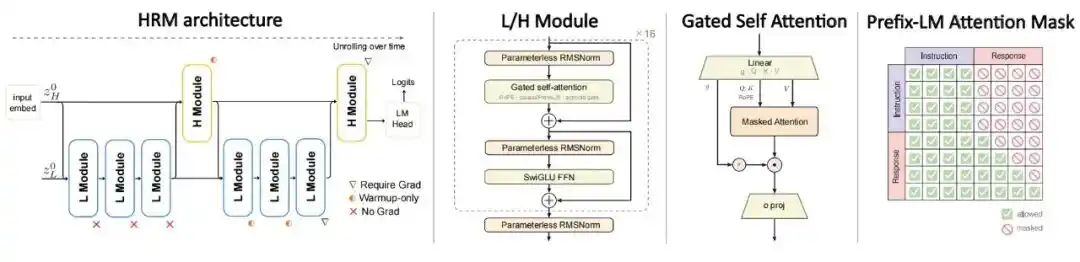
Рис.| Архитектура HRM-Text.
Для повышения стабильности рекуррентного обучения исследовательская команда внедрила MagicNorm и Warmup Deep Credit Assignment.
MagicNorm — это стратегия смешанной нормализации, использующая асимметрию глубины прямых и обратных вычислений при усеченном обратном распространении (Truncated BPTT). Внутри модулей используется PreNorm, а на выходе модуля дополнительно добавляется нормализация, что повышает стабильность глубокого рекуррентного обучения.
Warmup Deep Credit Assignment на начальном этапе обучения передает градиенты только для последних 2 рекуррентных шагов, а затем линейно расширяется до последних 5 шагов. Этот механизм обучения позволяет модели стабильно сходиться на более коротких кредитных путях, а затем постепенно вводить более длинные зависимости.
Каковы результаты?
Экспериментальные результаты показывают, что HRM-Text демонстрирует явные преимущества в эффективности архитектуры, целях обучения и общей производительности.
1. Эффективна ли рекуррентная архитектура при фиксированных вычислительных затратах на обучение
Результаты показывают, что при выравнивании FLOPs, HRM 1B превосходит Transformer 1B, Transformer 3B, Looped Transformer 1B и RINS 1B по большинству бенчмарков; сравнение с TRM также показывает, что обучение HRM более стабильно.
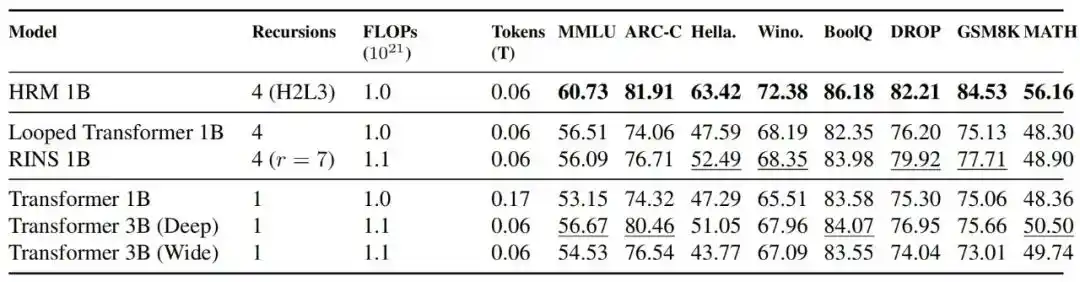
Рис.| Сравнение производительности и стабильности с моделями Transformer. HRM сохраняет стабильную динамику обучения при всех масштабах, в то время как модели Transformer при масштабе в 1 миллиард параметров показали серьезную нестабильность. Кроме того, при масштабе 0.6B HRM требуется в 2 раза меньше вычислений, чем моделям Transformer, чтобы достичь конкурентоспособных результатов по большинству бенчмарков.
2. Полезны ли цель выполнения задачи и PrefixLM
Эксперименты по исключению (абляции) показывают, что при выравнивании FLOPs, показатель MMLU для Transformer 1B увеличивается с 40.55 при стандартной авторегрессии до 47.72 после введения цели выполнения задачи, затем до 53.15 после добавления PrefixLM и, наконец, до 60.73 после замены архитектуры на HRM.
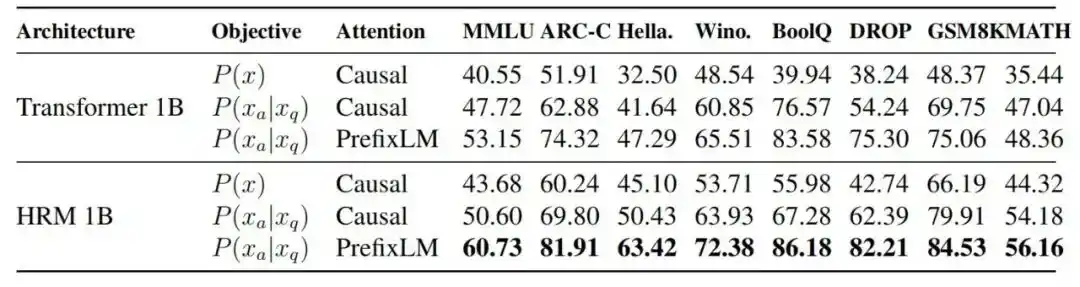
Рис.| Сравнение производительности различных архитектур моделей и целей обучения.
3. Насколько эффективен HRM-Text по сравнению с современными открытыми моделями
HRM-Text 1B достигает 60.7, 81.9, 82.2, 84.5 и 56.2 на MMLU, ARC-C, DROP, GSM8K и MATH соответственно. По сравнению с открытыми моделями, у которых обычно значительно больший бюджет на обучение, используя всего 40 миллиардов уникальных токенов и 1 миллиард параметров, он вошел в диапазон производительности открытых моделей от 2B до 7B; требуемое для обучения количество токенов меньше вплоть до 900 раз, вычислительные затраты меньше вплоть до 432 раз.
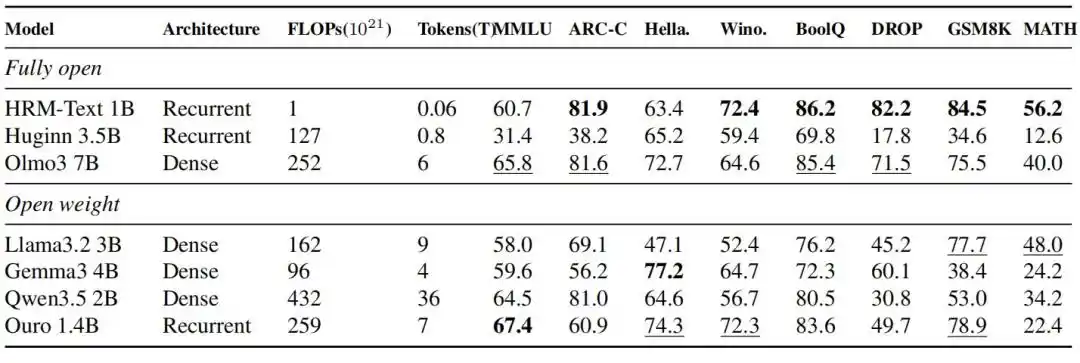
Рис.| Результаты оценки HRM-Text 1B по сравнению с полностью открытыми моделями и моделями с открытыми весами того же периода.
4. Привносит ли рекуррентная структура большую эффективную глубину
Результаты показывают, что стандартный Transformer и Looped Transformer стабилизируются на более мелких слоях, тогда как HRM на более глубоких слоях по-прежнему сохраняет более заметные изменения представлений между блоками, более низкое косинусное сходство и более высокие значения KL logit lens.
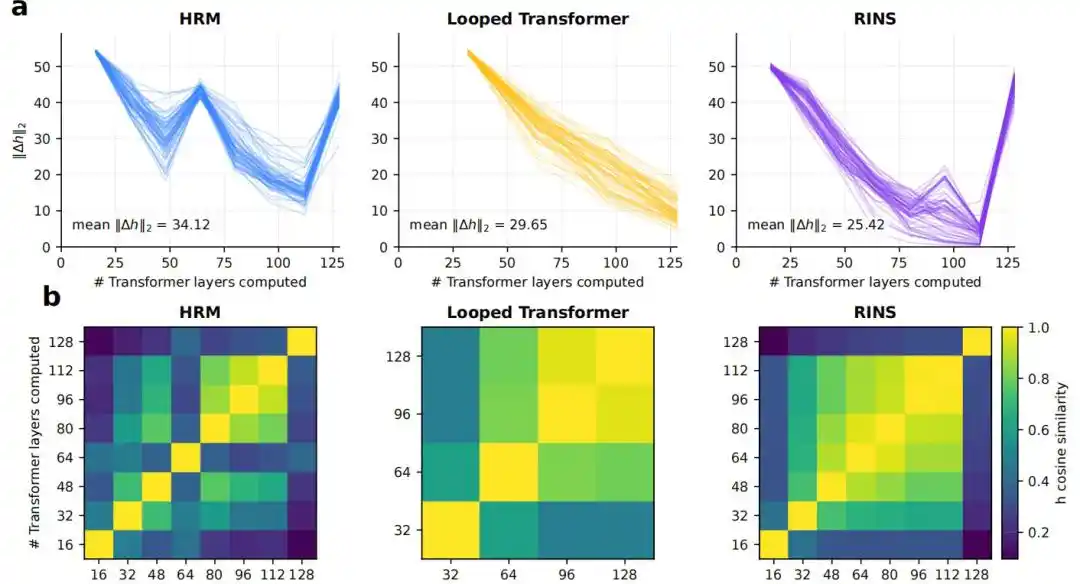
Рис.| Анализ эффективной глубины.
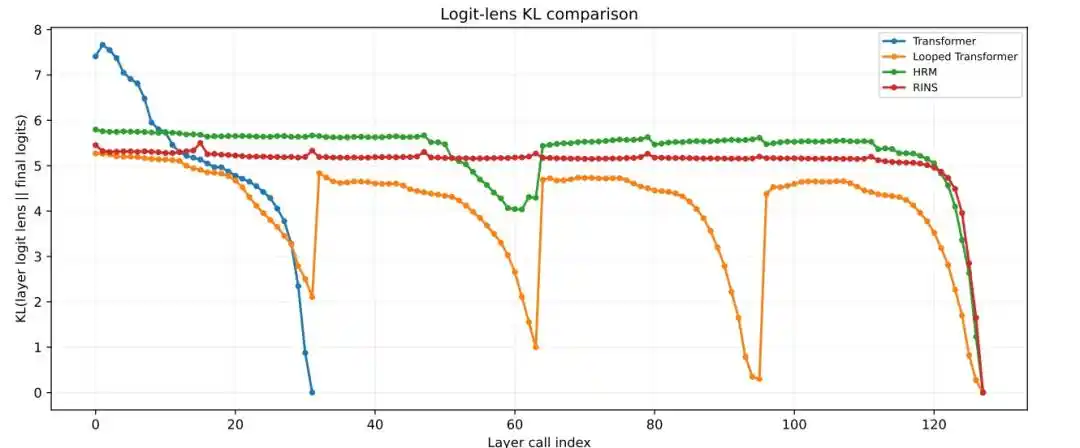
Рис.| Послойный анализ KL Logit Lens.
Недостатки и направления на будущее
Несмотря на то, что HRM-Text показал впечатляющие результаты в задачах, требующих вывода, этот метод все еще имеет ограничения, и предлагаются направления для будущих исследований.
1. Движение к разделению «знаний» и «рассуждений»
В настоящее время, более широкий охват фактических знаний по-прежнему в большей степени зависит от масштаба модели и широты данных. HRM-Text обучался только на 40 миллиардах уникальных токенов, и явные источники знаний составляют лишь часть данных в смеси, отформатированной под задачи. В будущем исследователям необходимо отдельно проектировать компактное ядро рассуждений и внешнее хранилище фактов, передавая широту знаний тщательно отобранным корпусам, модулям с поисковым усилением (RAG) или обучаемой памяти.
2. Адаптивное время вычислений
Циклическое планирование HRM-Text обеспечивает большую эффективную последовательную глубину, но это также означает, что модель должна выполнять фиксированное количество рекуррентных шагов при выводе. В будущем перспективным направлением может стать внедрение механизма адаптивного времени вычислений, позволяющего простым примерам останавливать вычисления раньше, а полный цикл бюджета оставлять для сложных примеров, что снизит стоимость вывода.
3. Ограниченный текущий диапазон проверки масштабирования
Текущие эксперименты по масштабированию охватывают только контрольную группу Transformer с 3 миллиардами параметров и HRM-Text с 1 миллиардом параметров. Исследовательская команда отмечает, что требуется дальнейшая проверка в последующих работах, сохранятся ли аналогичные преимущества в эффективности при более крупных масштабах моделей.
4. PrefixLM и фреймворки вывода
В настоящее время PrefixLM все еще сталкивается с определенными ограничениями в инженерной реализации при практическом развертывании. Хотя он может работать на стандартных фреймворках для вывода текста, таких как vLLM, это требует поддержки пользовательских масок внимания на этапе предзаполнения (prefill). При расширении до многотурных диалоговых сценариев необходимо дополнительно разработать механизм KV-cache, который гарантирует двунаправленную видимость внутри сегментов пользователя, а также обеспечивает, чтобы процесс генерации со стороны ассистента продолжал следовать причинно-следственным ограничениям.
Более подробные технические детали см. в оригинальной статье.
Эта статья взята с официального аккаунта WeChat "Академические заголовки" (ID: SciTouTiao), автор: Ся Цяньсы.








