Редакция Machine Heart
Недавно представленная Google открытая модель Gemma 4 стала большим сюрпризом для индустрии.
Она использует технологическую архитектуру, родственную Gemini 3, поддерживает нативную многомодальность, заняла третье место в мировом рейтинге Arena AI и предлагает несколько моделей. Меньшие модели — E2B (2,3B эффективных параметров) и E4B (4,5B эффективных параметров) — можно развертывать и запускать локально на мобильных устройствах с контекстным окном до 128K, что делает их «карманной заменой Gemini».
Как и ожидалось, модель быстро стала новой игрушкой для пользователей смартфонов.
Пост пользователя X набрал сотни тысяч просмотров. В видео он показал, как запускает Gemma 4 на iPhone локально, включая обработку изображений, аудио и управление фонариком. Он отметил, что Gemma 4 невероятно быстра и ощущается как магия.

На iPhone 17 Pro измерили скорость: если телефон использует чип Apple, то с помощью MLX (фреймворка машинного обучения от Apple), оптимизированного под эти чипы, скорость вывода модели может превышать 40 токенов в секунду.

На Samsung Galaxy также достигли аналогичной скорости, даже в режиме размышления. Это заставило многих воскликнуть: «Слишком быстро, чтобы быть правдой».
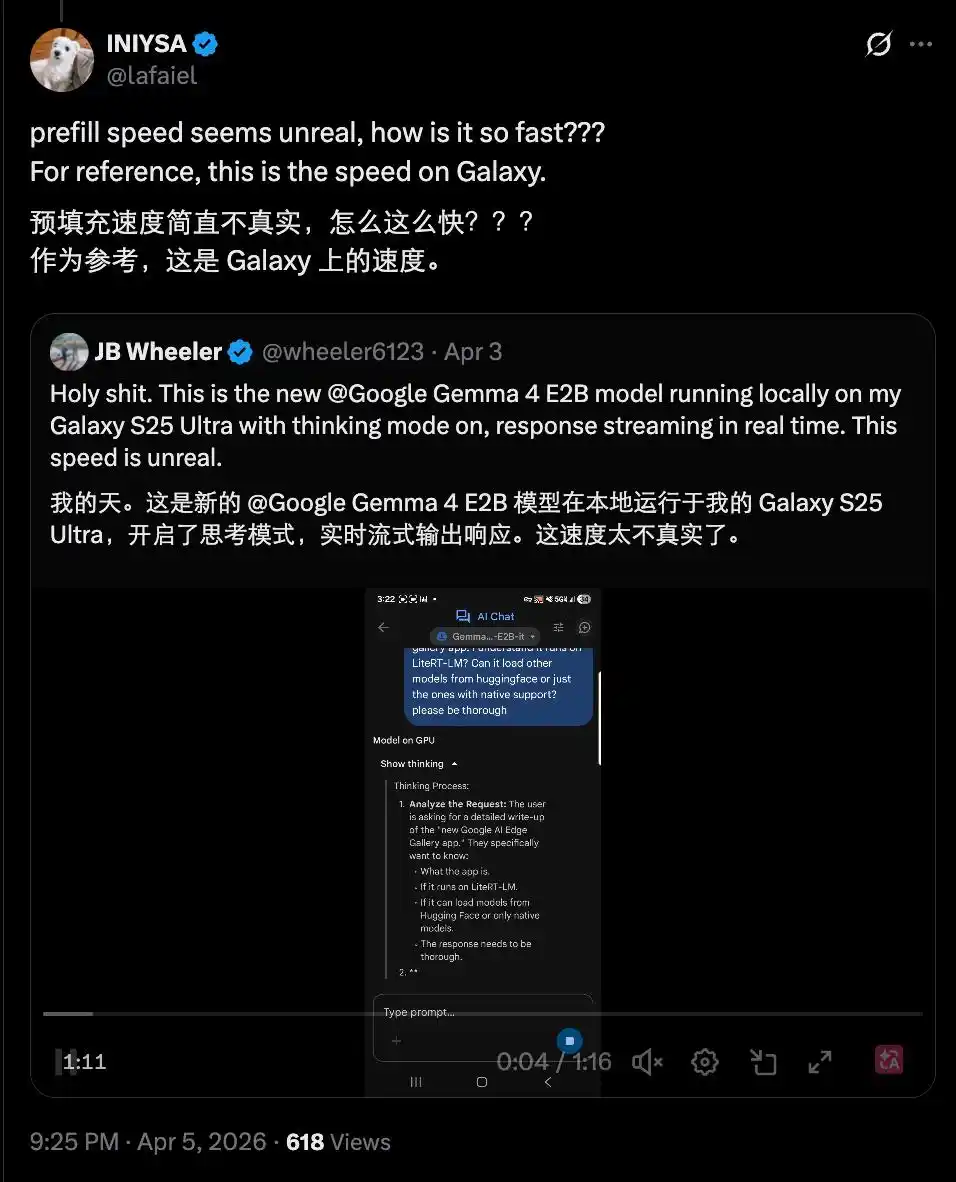
Такая скорость делает запуск моделей ИИ на мобильных устройствах жизнеспособным вариантом в будущем, особенно полезным в чувствительных сценариях, таких как медицина.
Контекстное окно в 128k также делает这些小模型 более привлекательными.
Как же запустить? Всё просто, это не только для гиков, ведь Google выпустил официальное приложение — Google AI Edge Gallery. Желающие могут скачать его, затем загрузить нужную версию модели и запустить.

И, будучи официальным продуктом Google, беспокоиться о безопасности особо не стоит.
Помимо мобильных версий, некоторые пробовали запускать более крупные версии Gemma 4 на мощном железе, например, Gemma 4 Mixture-of-Experts 26B на MacBook Pro с M5 Pro.

При обычном диалоге модель всё ещё довольно быстра, генерация текста и объяснение кода идут гладко.

Но когда её начали использовать как coding agent, возникли проблемы. Для работы агента требуются большой контекст (у Gemma 4 26B — 256k), сложные промпты и стабильный вызов инструментов. Gemma 4 явно не справлялась: зависала, выдавала ошибки или некорректные структуры вывода.

Переломный момент наступил, когда модель заменили на qwen3-coder. В той же среде создание файлов, выполнение команд и многошаговые задачи пошли нормально. Проблема, по его мнению, не в фреймворке агента, а в том, оптимизирована ли модель для «вызова инструментов + структурированного вывода». Здесь Gemma 4, возможно, не дотягивает, либо разработчик ещё не нашёл правильный способ использования.

Кроме того, некоторые отмечают, что интеллектуальный уровень Gemma 4 пока несколько ограничен.
Тем не менее, появление такого «производительного малютки», как Gemma 4, нельзя недооценивать. Если в будущем множество повседневных запросов, чатов, простых рассуждений, генерации кода и понимания изображений можно будет выполнять локально, без покупки токенов, то поставщикам токенов придётся несладко?
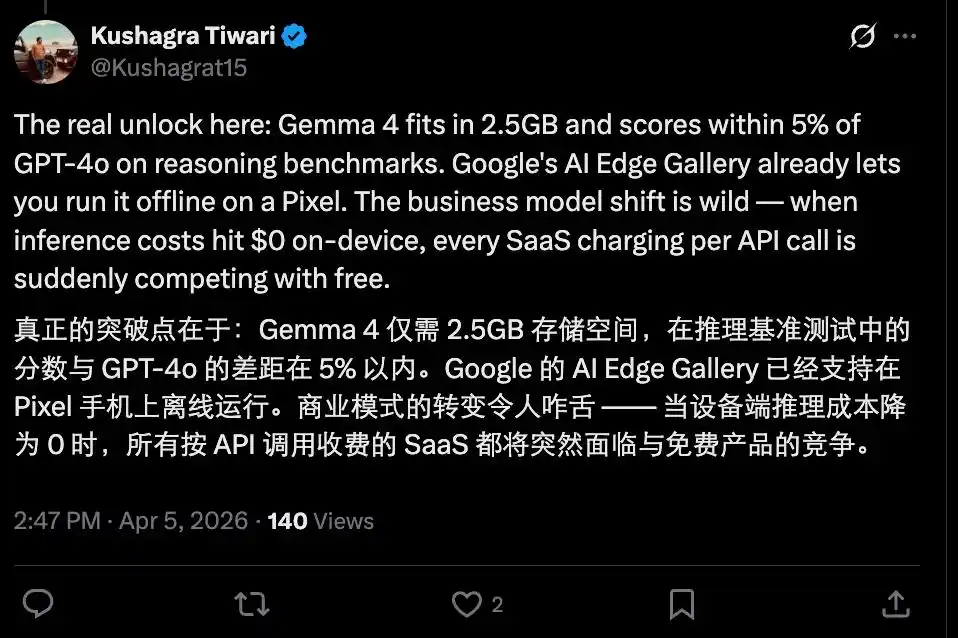
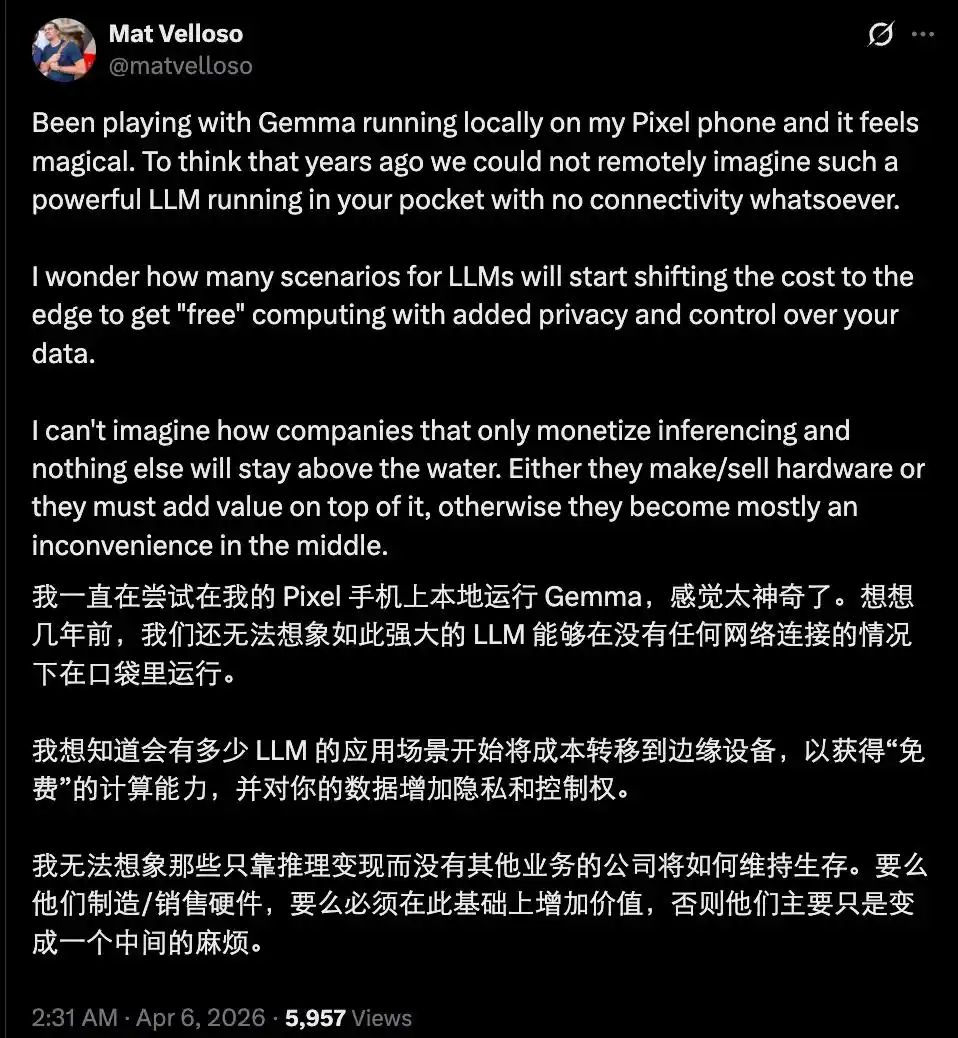
Конечно, сейчас ситуация не столь печальна. Ведь между открытыми моделями и передовыми закрытыми флагманами ещё есть разрыв, и большинство мощных открытых моделей по-прежнему ограничены аппаратными возможностями, пока не достигли приемлемого уровня на edge-устройствах.
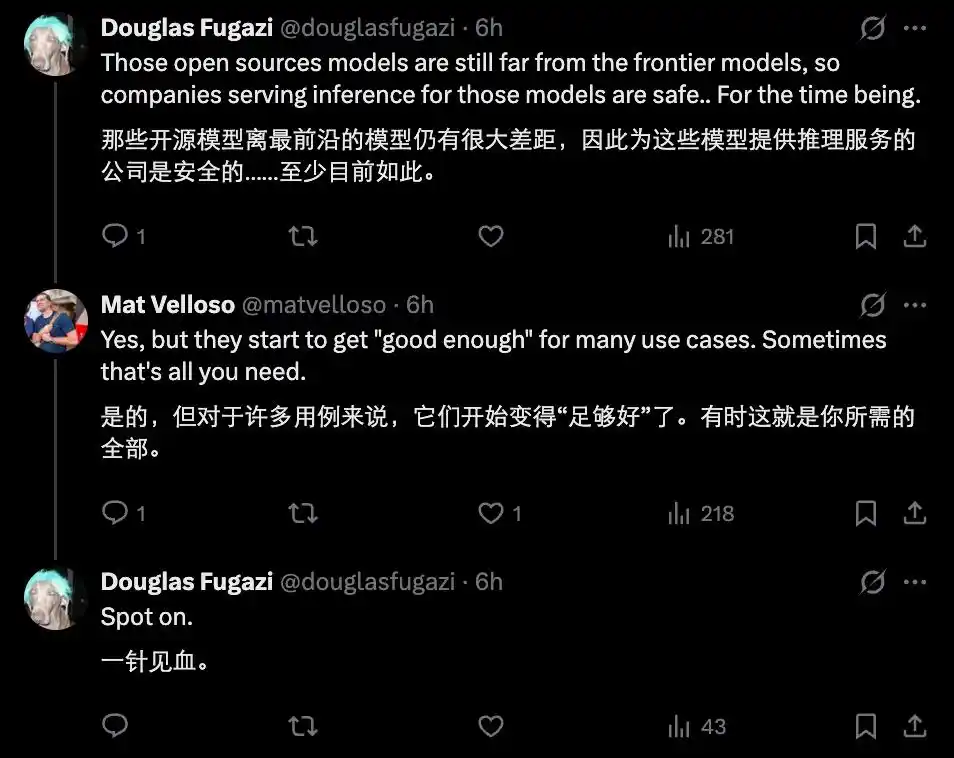
Но тренд будущего ясен. В краткосрочной перспективе облачные закрытые модели сохранят лидерство в сложных рассуждениях и масштабной многозадачной коллаборации. Но в долгосрочной — с прогрессом железа и оптимизацией квантования, edge-модели постепенно отвоюют у облака高频简单任务 (высокочастотные простые задачи).
Поставщикам, живущим только за счёт продажи токенов и API-подписок, придётся активнее бороться за «по-настоящему сложные» части — сверхмощные агенты, сверхдлинный надёжный контекст и специализированные возможности, требующие огромных объёмов актуальных данных.
Gemma 4 — это только начало. Следующим сюрпризом может стать edge-модель, в повседневном использовании которой пользователь вообще не почувствует разницы между «локальным» и «облачным». Когда этот день наступит, вся бизнес-модель индустрии ИИ переживет настоящую перетряску.
Статья из WeChat Official Account «Machine Heart» (ID: almosthuman2014), автор: Редакция Machine Heart







