Общеизвестно, что обучение больших моделей чрезвычайно дорого.
Но также известно, что снижение точности вычислений может значительно снизить стоимость обучения. DeepSeek-V3, используя обучение в формате FP8, снизил стоимость до 5,6 миллиона долларов, что уже привлекло внимание всей индустрии.
После успеха FP8 индустрия продолжает исследовать границы низкой точности: если снизить точность с FP8 до FP4, насколько ещё можно снизить стоимость обучения?
Теоретически, вычислительная пропускная способность FP4 может быть в два раза выше, чем у FP8. NVIDIA Blackwell и AMD MI350 уже на аппаратном уровне имеют нативную поддержку вычислений FP4, при этом B200 от NVIDIA заявляет пиковую производительность FP4 до 4500 TOPS (разряженная). Аппаратное обеспечение готово, но со стороны программного обеспечения и алгоритмов возникает проблема:
Обучение больших моделей с нуля на FP4 является крайне нестабильным процессом.
За последние два года такие работы, как LLM-FP4, предобучение NVFP4 и другие, пробовали этот путь, но лишь немногие подходы смогли чисто и надёжно провести полный цикл предобучения с 4-битной точностью, сохранив качество сходимости, близкое к FP8.
Что ещё хуже, причина сбоев оставалась неясной. Анализ предполагал, что причина нестабильности обучения на FP4, вероятно, заключается в недостатке случайности.
Но недавно AMD совместно с Университетом штата Пенсильвания опубликовала статью, которая меняет традиционные представления и даёт новое чёткое объяснение для нативного обучения FP4.

- Название статьи: Pretraining large language models with MXFP4 on Native FP4 Hardware
- Ссылка на статью: https://arxiv.org/abs/2605.09825
В этой статье, на GPU AMD Instinct MI355X, используя формат MXFP4, был выполнен полный цикл предобучения модели Llama 3.1-8B. Скорость сквозного обучения оказалась на 9-10% выше, чем у базовой линии FP8, при увеличении затрат на токены всего на 8-9%. Это первый полный эксперимент по предобучению большой модели, выполненный на нативном оборудовании FP4 (не программной эмуляции).
Что ещё важнее, статья раскрывает ключевую проблему: источник нестабильности обучения FP4 — не недостаток случайности, а структурная ошибка микромасштабирования, которая накапливается и усиливается вдоль чувствительных путей градиентов.
Что такое MXFP4
Прежде чем разбирать статью, необходимо понять формат данных MXFP4.
Традиционное целочисленное квантование обычно использует один масштабирующий коэффициент для всего тензора. Ключевой конструкцией MXFP4 является «микромасштабирование» (Micro-scaling): тензор разбивается на небольшие блоки (например, по 32 элемента), для каждого блока выделяется общий экспоненциальный коэффициент (формат E8M0), а каждый элемент внутри блока представлен 4-битным числом с плавающей запятой. Формула восстановления может быть записана как:
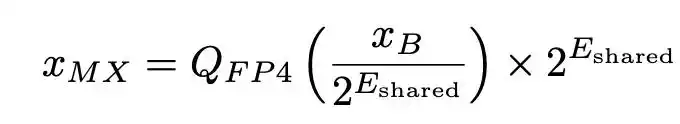
где E_shared — это максимальный экспоненциальный коэффициент в блоке, а Q_FP4 — значение, округлённое до ближайшего представимого 4-битного числа с плавающей запятой.
Преимущество микромасштабирования заключается в следующем: каждый блок имеет свой собственный динамический диапазон и не «заложник» глобальных выбросов. Это значительно улучшает качество представления 4-битных чисел с плавающей запятой по сравнению с простым глобальным квантованием.
Но даже с микромасштабированием обучение на FP4 остаётся нестабильным.
Поисковая экспериментальная работа: корень нестабильности
Исследовательская группа сначала разработала контрольный эксперимент с пошаговой проверкой.
Одно полное вычисление линейного слоя Transformer включает три операции универсального матричного умножения:
Fprop (прямое распространение): вычисление Y = XW^T, получение значений активации.
Dgrad (градиент активации): вычисление ∇X = ∇Y · W, передача градиента обратно на вход.
Wgrad (градиент весов): вычисление ∇W = (∇Y)^T · X, получение градиента для обновления весов.
Исследовательская группа, сохраняя все остальные факторы неизменными, постепенно заменяла эти три операции с FP8 на MXFP4, наблюдая влияние каждого шага на сходимость. Все эксперименты выполнялись на AMD Instinct MI355X с использованием нативных тензорных ядер FP4, без зависимости от программной эмуляции.
Задачей обучения была стандартная конфигурация MLPerf: предобучение Llama 3.1-8B на наборе данных C4, целевой метрикой сходимости была перплексия на валидационной выборке, равная 3.3.
Первые два шага привели к умеренному дополнительному расходу токенов, но как только Wgrad также был заменён на MXFP4, расход сразу подскочил до 26-27%.
Wgrad является узким местом обучения FP4. Прямое распространение и градиент активации имеют значительную толерантность к квантованию FP4, но как только градиент весов квантуется до 4 бит, качество сходимости значительно ухудшается.
Ранее преобладала интуиция в индустрии, что ошибка квантования FP4 по сути является проблемой шума, поэтому её можно «сгладить», вводя случайность. Две распространённые стратегии:
Стохастическое округление (Stochastic Rounding): введение случайности при квантовании, чтобы математическое ожидание ошибки округления было равно нулю.
Случайное преобразование Адамара (Randomized Hadamard): перед квантованием используется преобразование Адамара со случайными переворотами знаков для размывания распределения данных.
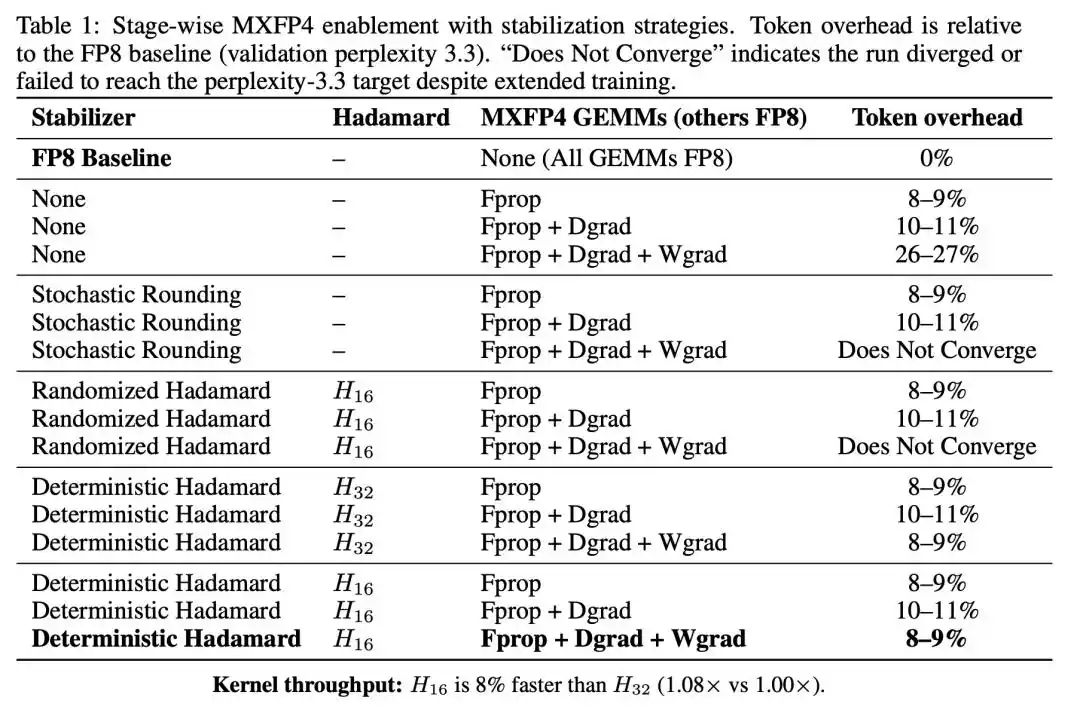
После квантования Wgrad обе стратегии случайности не только не стабилизировали обучение, но и напрямую привели к отсутствию сходимости. Случайность не помогла, а, наоборот, внесла больше эффективной ошибки квантования на критических путях градиентов.
Напротив, детерминированное преобразование Адамара снизило общие затраты на токены с 26-27% до 8-9%, а траектория обучения плотно следовала за базовой линией FP8.
Это результат, имеющий большую диагностическую ценность. И случайное, и детерминированное преобразования Адамара являются ортогональными преобразованиями, оба могут размывать распределение энергии выбросов, и теоретически должны иметь схожий эффект смягчения ошибок квантования. Но их производительность в сценарии Wgrad кардинально противоположна, что раскрывает суть проблемы:
Нестабильность обучения FP4 обусловлена структурными ошибками, создаваемыми микромасштабированием MXFP4 на чувствительных путях градиентов. Стратегии случайности терпят неудачу, потому что они вносят разные шаблоны ошибок на каждом шаге, и эти изменяющиеся шаблоны накапливаются вдоль пути градиентов, усиливая нестабильность. Детерминированное преобразование эффективно именно потому, что оно применяет одинаковое преобразование на каждом шаге, заставляя шаблоны ошибок оставаться согласованными и избегая их накопления.
Сквозная эффективность: пропускная способность шага обучения +20%, общее ускорение 9-10%
После добавления детерминированного преобразования Адамара и применения полного цикла MXFP4, показатели эффективности следующие:

Пропускная способность шага обучения увеличилась на 20%, и после вычета дополнительных 8-9% затрат на токены, общее сквозное ускорение всё равно составляет 9-10%.
Учитывая, что точность была напрямую снижена с 8 бит до 4 бит, такое качество сходимости и степень ускорения весьма впечатляют.
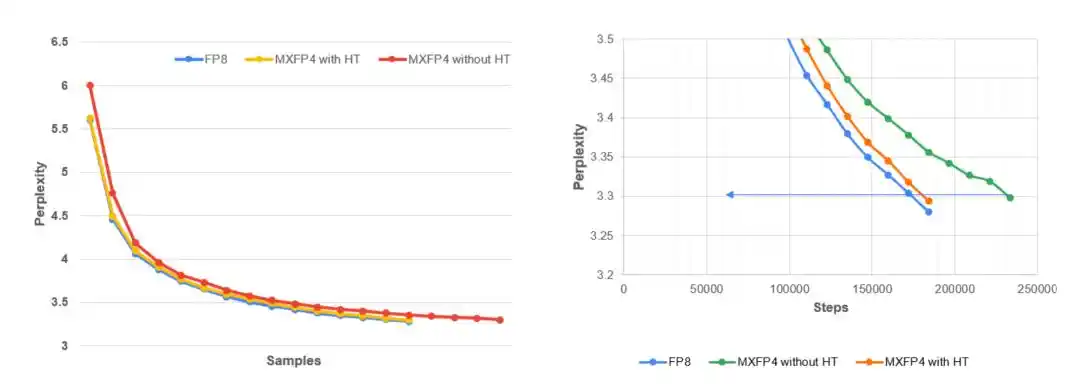
Левый график: кривая изменения перплексии на валидационной выборке модели Llama 3.1–8B в зависимости от количества токенов обучения при предобучении по стандарту MLPerf на наборе данных C4. Результаты показывают, что MXFP4 + детерминированное преобразование Адамара работает очень близко к FP8, в то время как полный цикл MXFP4 без стабилизации сходится медленнее и менее стабилен. Правый график: увеличенный вид поздних этапов обучения. Целевая перплексия по MLPerf составляет 3.3. По сравнению с нестабилизированным запуском MXFP4, детерминированное преобразование Адамара (H16) сохраняет гораздо более тесное соответствие с базовой линией FP8.
Примечательно, что авторы в статье подчёркивают важное ограничение: эффективность этой схемы обучения FP4 (набор данных MLPerf C4 + Llama 3.1-8B) уже подтверждена, но нельзя напрямую предполагать, что она будет бесшовно переноситься на все модели, все наборы данных и все методы обучения. Поведение обучения FP4 может сильно зависеть от конкретной конфигурации, и конкретные стратегии стабилизации необходимо перепроверять для каждого сценария.
Заключение
Если поместить эту статью в более широкий контекст индустрии, можно выделить как минимум три уровня значимости.
Первый уровень: она отвечает на фундаментальный вопрос «почему». Предыдущие работы по обучению FP4 в основном фокусировались на «как сделать, чтобы оно не падало», тогда как эта статья впервые даёт чёткое причинно-следственное объяснение: сбой вызван структурными ошибками микромасштабирования на пути Wgrad, а не недостатком случайности. Само по себе это объяснение имеет методологическую ценность: оно говорит последующим исследователям, что при столкновении с нестабильностью при обучении с низкой точностью, следует в первую очередь искать источники структурных ошибок, а не слепо добавлять случайность.
Второй уровень: она перемещает FP4 из сферы «исключительно для вывода» в сферу «пригодности для обучения». Ранее консенсус в индустрии заключался в том, что FP4 подходит только для квантования при выводе, а для обучения требуется как минимум FP8. NVIDIA, продвигая на Blackwell именно FP4 для вывода, а не для обучения, также отражала это мнение. Эта статья, выполнив полный цикл предобучения на нативном оборудовании FP4, означает, что вычислительные мощности FP4, подготовленные для вывода на MI355X и Blackwell, теоретически также могут быть использованы для обучения. Если обучение на FP4 окажется работоспособным на более крупных моделях и в большем количестве сценариев, это фактически удвоит доступные вычислительные мощности для обучения на существующем оборудовании.
Третий уровень: она использует открытый стандарт OCP. MXFP4 является частью стандарта форматов микромасштабирования OCP (Microscaling Formats), поддержанного совместно семью компаниями: AMD, NVIDIA, Intel, Meta, Microsoft, Arm, Qualcomm. Использование открытого стандарта означает, что этот метод может быть перенесён на оборудование разных производителей и не будет заблокирован в рамках одной экосистемы.
От FP16 до FP8, DeepSeek-V3 уже доказал, что уменьшение точности вдвое может значительно снизить стоимость обучения. От FP8 до FP4, эта статья сделала ключевой первый шаг. Каждое снижение точности меняет экономику обучения больших моделей.
Эта статья взята из официального аккаунта WeChat «Машинное сердце» (ID:almosthuman2014), редактор: Лэн Мао.








