Без предупреждения! Спустя год Цукерберг наконец вернулся!
Прямо сейчас первый продукт Суперразумной лаборатории Meta (MSL) вышел в свет —
Muse Spark, кодовое название Avocado, то самое легендарное «Авокадо».
Это настоящий «универсальный боец-шестигранник»: нативная мультимодальность, использование инструментов, визуальные цепочки рассуждений, оркестрация множества агентов — всё на высшем уровне.

Сначала о самом впечатляющем числе.
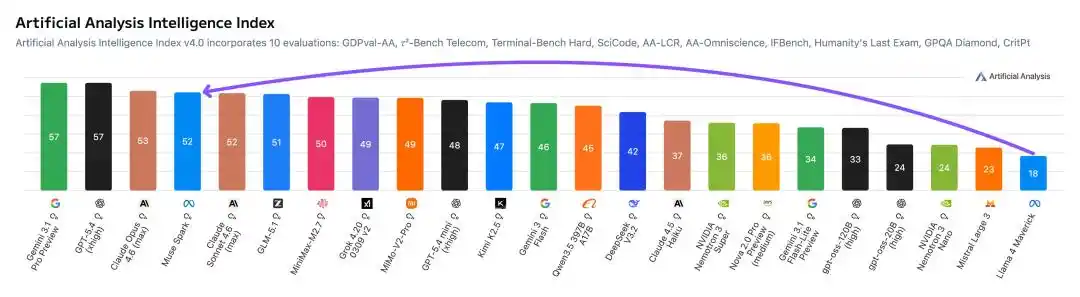
В тестах Artificial Analysis Muse Spark набрал ошеломляющие 52 балла, уступив только Gemini 3.1 Pro, GPT-5.4 и Opus 4.6.
Для сравнения, прошлогодний Llama 4 Maverick набрал лишь жалкие 18 баллов.
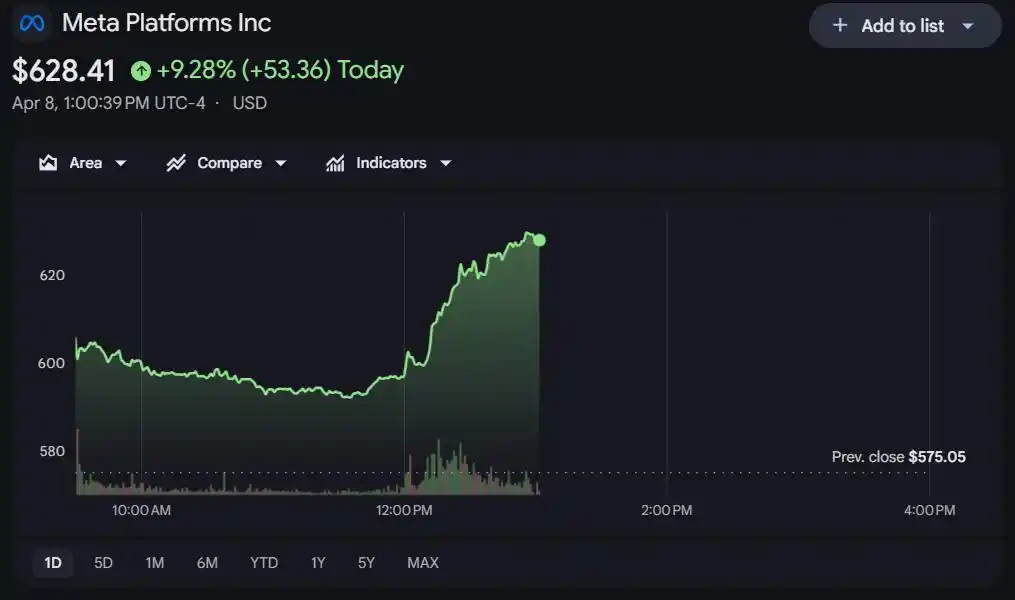
Скачок с 18 до 52 баллов привёл к тому, что акции Meta на бирже взлетели почти на 10%.
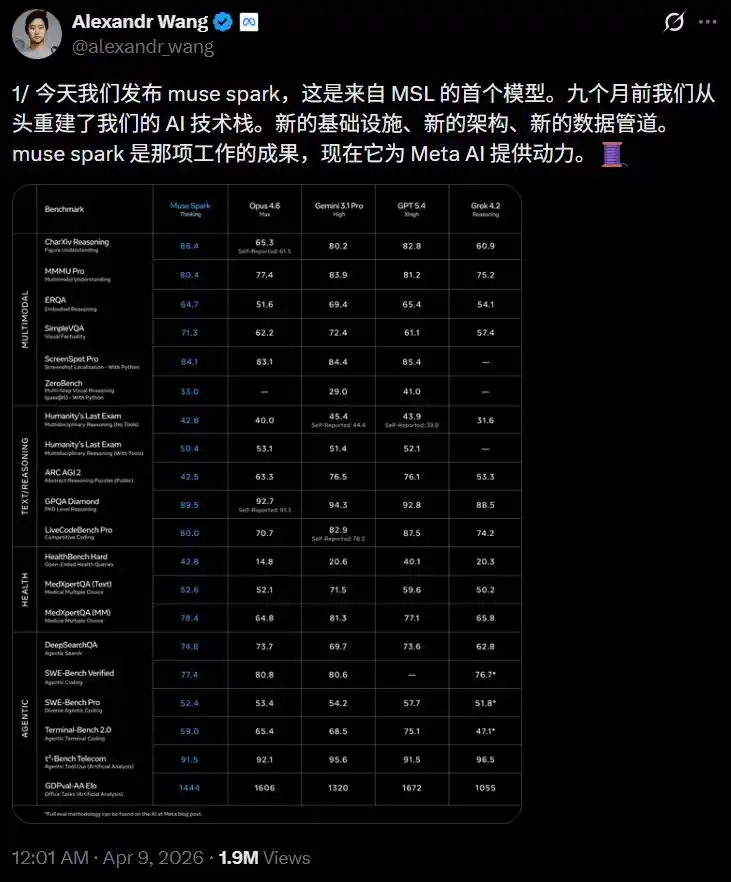
Главный директор по AI Meta Александр Ван (Alexandr Wang) был так взволнован, что опубликовал подряд девять твитов в X.
Девять месяцев назад мы с нуля перестроили весь стек AI-технологий: новая инфраструктура, новая архитектура, новые конвейеры данных. Muse Spark — результат этой работы.
Китайские исследователи из команды MSL также устроили настоящий флешмоб в соцсетях. Эти люди год назад перешли из OpenAI, DeepMind в только что созданную лабораторию, ставя на сегодняшний день.
Главный научный сотрудник MSL Шэнцзя Чжао (Shengjia Zhao)直言不讳地说: «Мы перестроили весь технологический стек для поддержки Scaling, и это только начало».




Стоит отметить, что Muse Spark также представил «Режим размышлений» (Contemplating), аналог Gemini Deep Think и GPT Pro, где несколько агентов думают параллельно и协同 отвечают.
Достаточно ввести «Помоги спланировать 7-дневный культурно-гастрономический тур во Флориду для семьи из 5 человек, дети 12, 9 и 7 лет», и Muse Spark одновременно запустит трех дочерних агентов: один будет планировать маршрут по культуре и еде, другой искать развлечения для детей, третий координировать логистику и проживание.
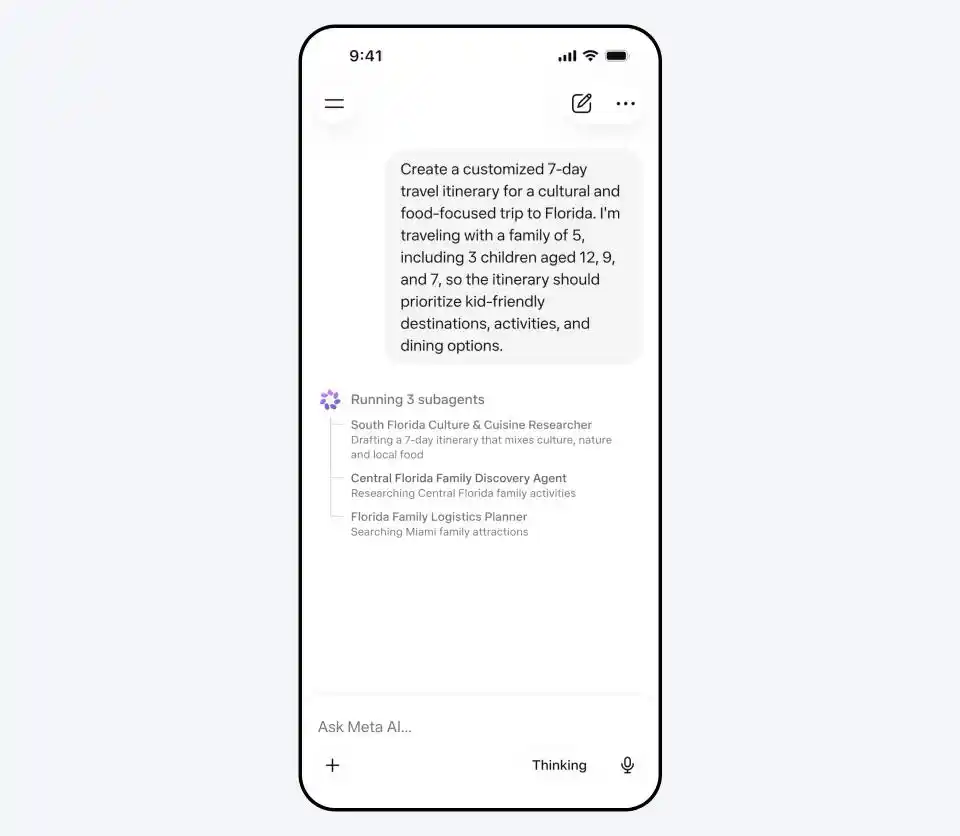
В настоящее время модель уже доступна на meta.ai и в приложении Meta AI. Превью-версия API открыта для部分 пользователей.
Функционал сначала развернётся в США, в ближайшие недели будет интегрирован с Facebook, Instagram и WhatsApp.
Бесплатно, без ограничений, но закрытый исходный код.
Далее, ключевые моменты:
· Artificial Analysis: 52 балла, Llama 4 Maverick — только 18
· Нативная мультимодальность + визуальные цепочки рассуждений, второе место в визуальном зачёте после Gemini 3.1 Pro
· «Режим размышлений»: множественные агенты думают параллельно, HLE — 58%
· Потребность в вычислительных ресурсах для предобучения сокращена до 1/10 от Llama 4
· В обучении участвовали 1000+ клинических врачей, ответы на медицинские вопросы превосходят всех
· Мысли самостоятельно сжимаются, потребление токенов лишь 1/3 от Opus
· Apollo Research обнаружил, что модель может感知, когда её тестируют на безопасность
Бенчмарки догнали лидеров, но с кодом ещё есть проблемы
Сначала жёсткие данные.
Meta сравнили Muse Spark (режим Thinking) с Opus 4.6, Gemini 3.1 Pro, GPT 5.4, Grok 4.2 по более чем 20 бенчмаркам, охватывающим мультимодальность, текстовые рассуждения, здоровье и агентов.
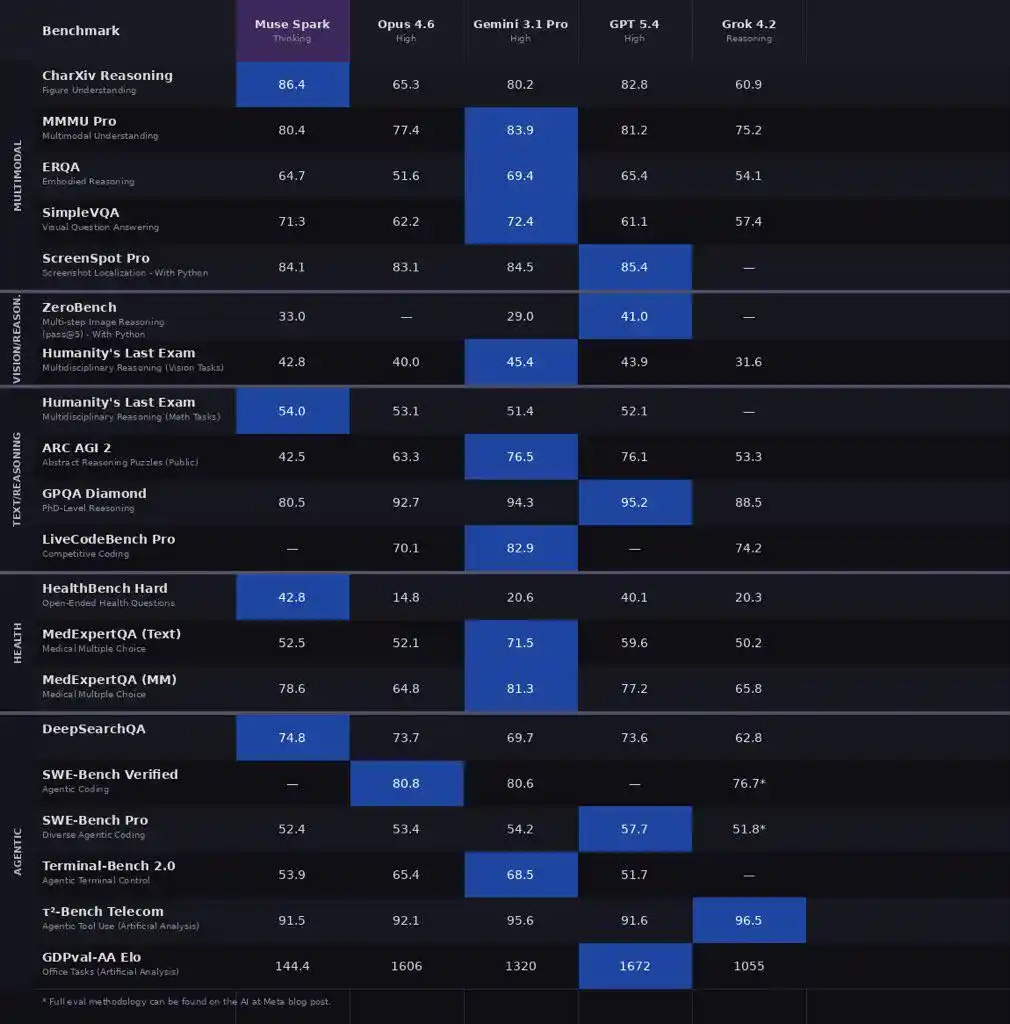
Переразмеченные результаты пользователями Reddit
Мультимодальность — самая сильная сторона Muse Spark.
CharXiv понимание 86.4, превосходит GPT 5.4 (82.8) и Gemini 3.1 Pro (80.2).
ScreenSpot Pro定位 скриншотов 84.1, немного выше, чем у Opus 4.6 (83.1).
ZeroBench многошаговое зрение 33.0, у Gemini 3.1 Pro — 29.0.
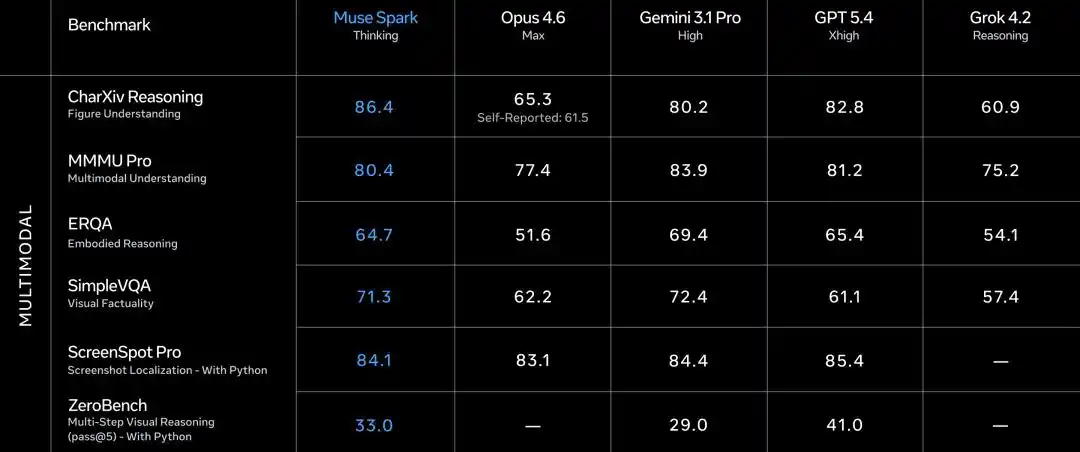
В текстовых дисциплинах результаты перемежаются.
GPQA Diamond博士级问题 89.5, Opus 4.6 получил 92.7, Gemini 3.1 Pro — 94.3.
ARC AGI 2 абстрактное мышление 42.5, значительно отстаёт от Opus 4.6 (63.3) и Gemini (76.5).
LiveCodeBench Pro соревновательное программирование 80.0, Gemini 82.9, GPT 5.4 набрал 87.5.
Meta сама признаёт, что в коде и длительных агентских задачах Muse Spark ещё отстаёт от сильнейших моделей.
Однако поразило всю сеть то, что Muse Spark может напрямую преобразовывать изображения в код, и результат впечатляет!
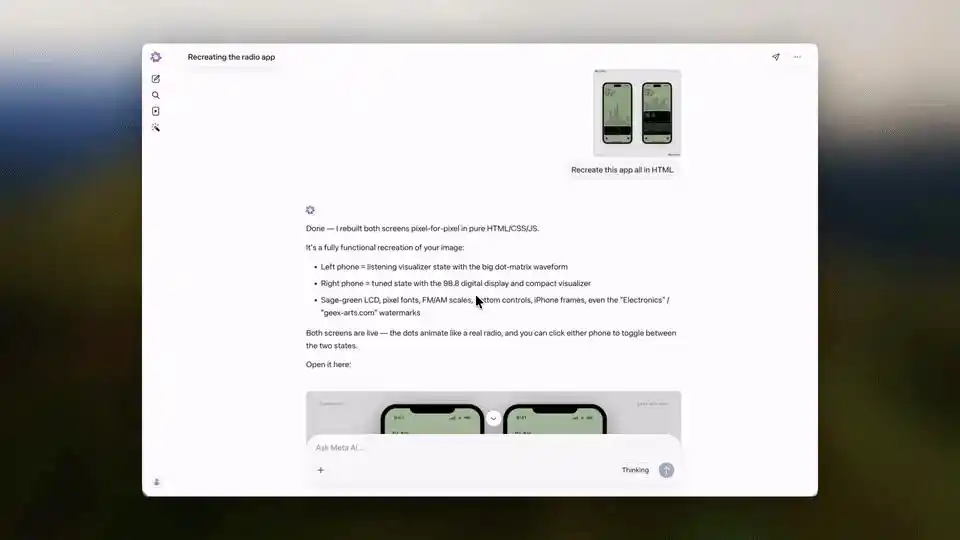
Но в медицинской сфере Muse Spark очень агрессивен.
HealthBench Hard открытые медицинские вопросы 42.8, у Gemini 3.1 Pro только 20.6, GPT 5.4 — 40.1.
MedXpertQA мультимодальная медицина 78.4, также близок к Gemini (81.3, здесь Gemini немного выше), но значительно превосходит Opus 4.6 (64.8).
Сотрудничество с более чем 1000 клинических врачей на этапе обучения по очистке и отбору данных действительно дало ощутимый эффект.
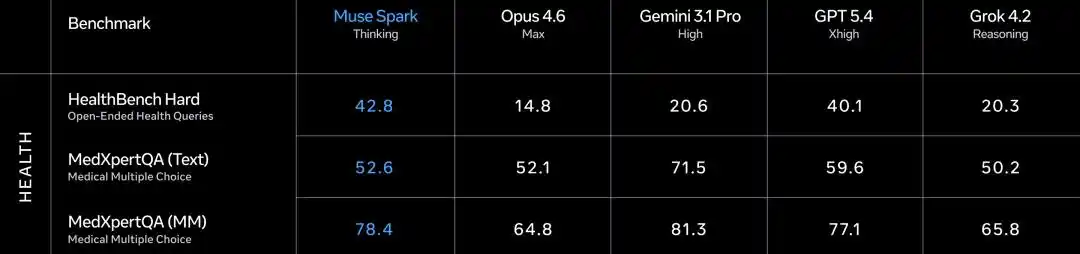
Агентское направление также заслуживает внимания.
DeepSearchQA поисковый агент набрал 74.8, самый высокий среди пяти.
τ2-Bench использование инструментов 91.5, наравне с GPT 5.4.
GDPval-AA Elo офисный агент достиг 1444, превзошёл Gemini (1320), но уступил Opus 4.6 (1606).
В SWE-Bench разрыв заметен: Verified 77.4 vs Opus 80.8 vs GPT 82.9 (据称78.2), Pro 52.4 vs GPT 57.7.
Краткий итог бенчмарков: выиграл мультимодальность и здоровье, паритет в мышлении, чуть отстаёт в коде и агентах.
Александр Ван: Ошибки Llama 4 не повторятся, «Авокадо» не набирало баллы искусственно
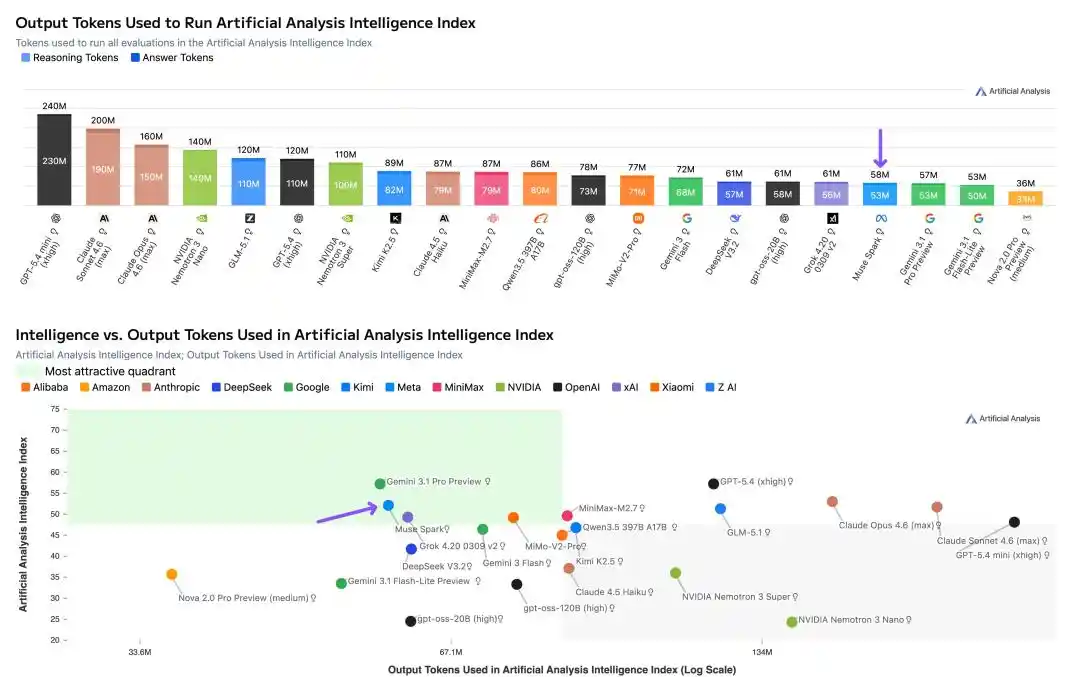
Независимое тестирование Artificial Analysis также выявило важную деталь — эффективность токенов.
Для прохождения всего набора тестов Intelligence Index Muse Spark использовал 58 миллионов выходных токенов, что сопоставимо с Gemini 3.1 Pro (57 миллионов), но значительно меньше, чем Opus 4.6 (157 миллионов) и GPT-5.4 (120 миллионов).
При том же уровне интеллекта потребляется в два-три раза меньше токенов.
Кроме того, на FrontierMath с задачами от математических гуру, Muse Spark на уровнях 1-3直接 превзошёл Gemini 3.1 Pro, но на 4 уровне оказался на последнем месте.

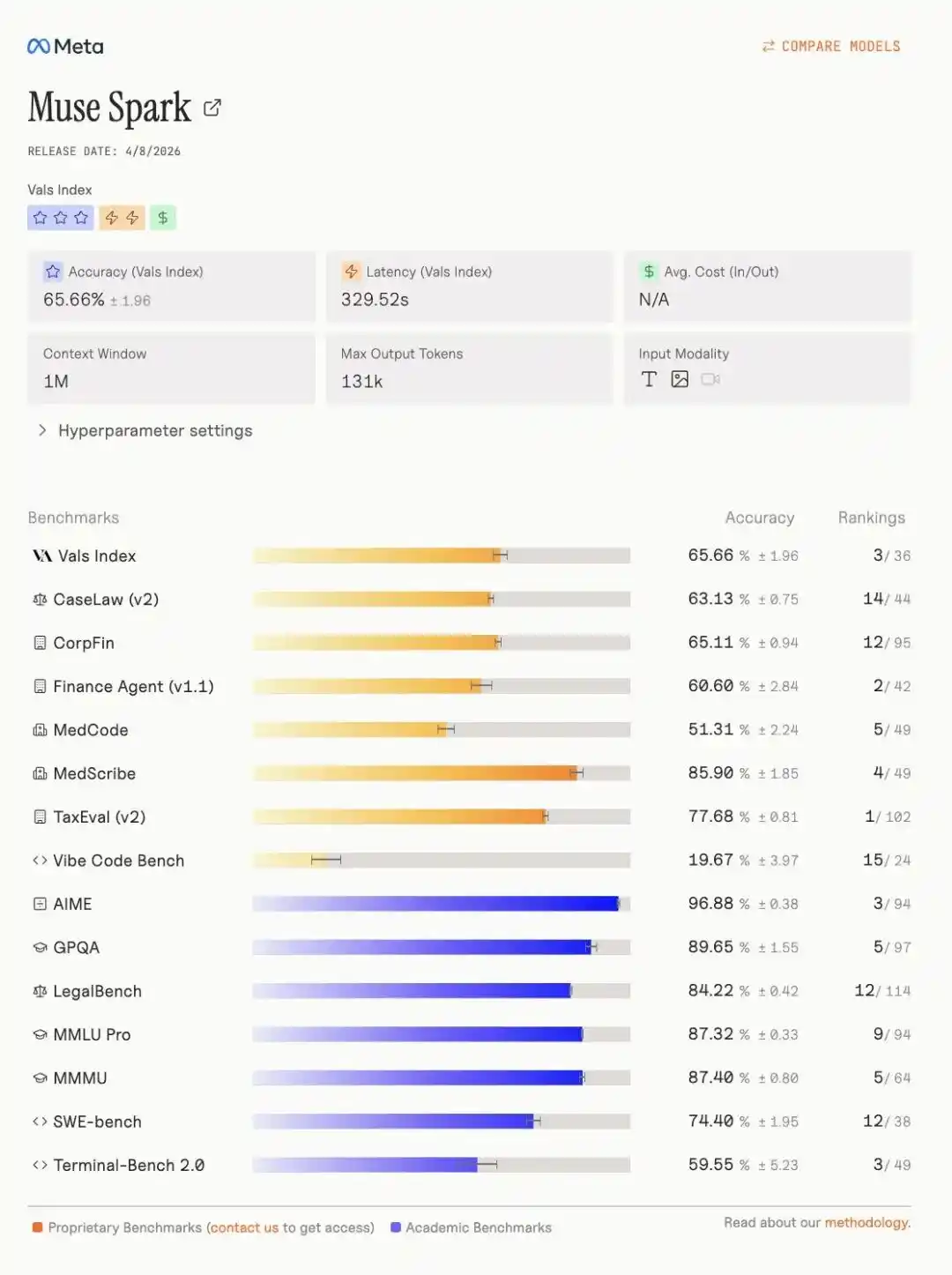
Более того, в рейтинге Vals Index Muse Spark уверенно занял третье место с следующими具体 показателями.
Спустя год после выхода Llama 4, Meta снова вернулась в первый эшелон AGI.
Множественные агенты думают параллельно, 58% на «Последнем экзамене человечества»
«Режим размышлений» — козырная карта Muse Spark.
Традиционный режим размышлений — это один агент думает дольше, а режим созерцания — это несколько агентов думают одновременно и в конце汇总 ответ.
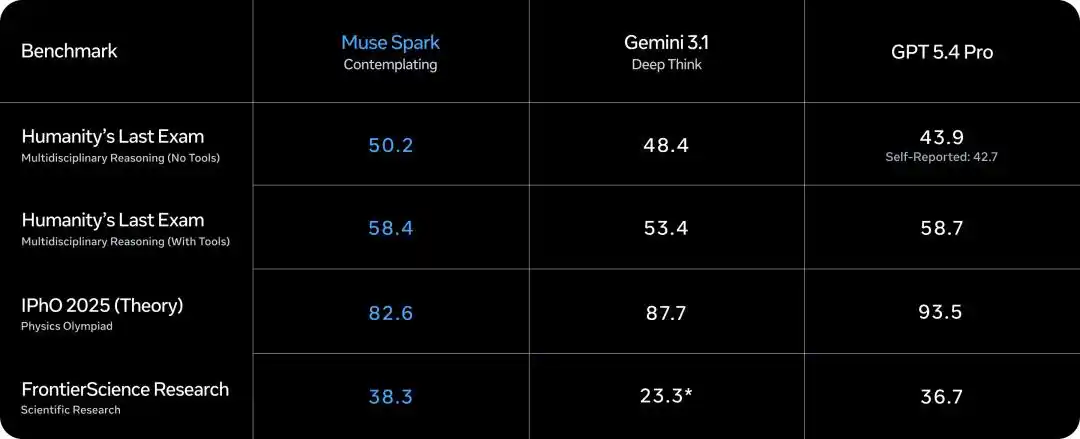
Humanity's Last Exam (без инструментов), Muse Spark в режиме размышлений набрал 50.2, Gemini Deep Think — 48.4, GPT 5.4 Pro — 43.9.
Humanity's Last Exam (с инструментами), 58.4, Gemini — 53.4, GPT 5.4 Pro — 58.7, почти ничья.
FrontierScience Research научные исследования 38.3, Gemini Deep Think только 23.3, GPT 5.4 Pro — 36.7.
Однако на теоретических задачах物理奥赛 IPhO 2025, Muse Spark в режиме размышлений набрал 82.6, а GPT 5.4 Pro — 93.5, разрыв不小.
В целом, режим размышлений позволил Muse Spark на самых сложных комплексных задачах мышления действительно достичь уровня первого эшелона.
Цель — «Персональный сверхразум», сфотографируй — и получи личного диетолога
Meta четко определила направление для Muse Spark — это персональный сверхразум.
Говоря человеческим языком, это AI-помощник, который понимает тебя и твой окружающий мир.
В плане мультимодальности, Muse Spark с самого底层 разработан для междисциплинарной интеграции визуальной информации.
Официальные演示 несколько сценариев.
Сфотографируй судоку, и Muse Spark превратит его в интерактивную игру, в которую можно играть в веб-браузере.
Сфотографируй кофемашину и кофемолку, он сначала отметит все ключевые компоненты, а затем сгенерирует интерактивное веб-руководство по приготовлению латте.
При наведении курсора на某个 шаг, bounding box соответствующего компонента на фотографии автоматически подсвечивается, визуальные подсказки и шаги действий一一对应.
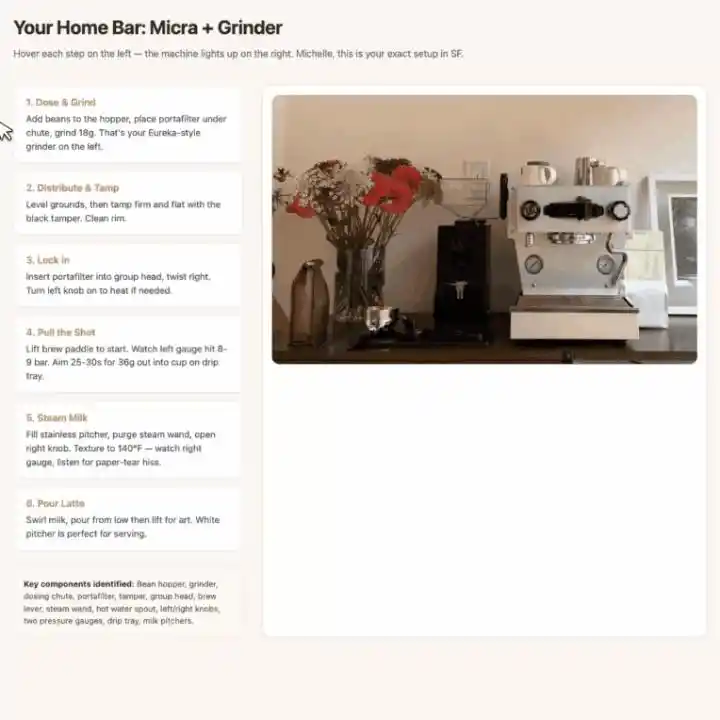
Медицинские сценарии ещё более многообещающи.
Сфотографируй стол с едой, скажи «У меня повышенный холестерин, я пескетарианец», и Muse Spark отметит рекомендуемые продукты зелёными точками, а нерекомендуемые — красными.
Контроль粒度 промптов очень детальный, чётко прописана логика UI-взаимодействия.
Цифры оценки здоровья отображаются прямо над точками без наведения, при наведении всплывает подробная информация о калориях, углеводах, белках и жирах, причём всплывающее окно должно быть «всегда поверх,不能被其他点挡住».

Тот же подход с фотографированием瑜伽动作.
Он определяет, какие группы мышц растягивает каждая поза,标注 уровень сложности, при наведении даёт советы по коррекции осанки. Два изображения человека拼在一起 слева и справа, оцениваются по шкале от 1 до 10 баллов.
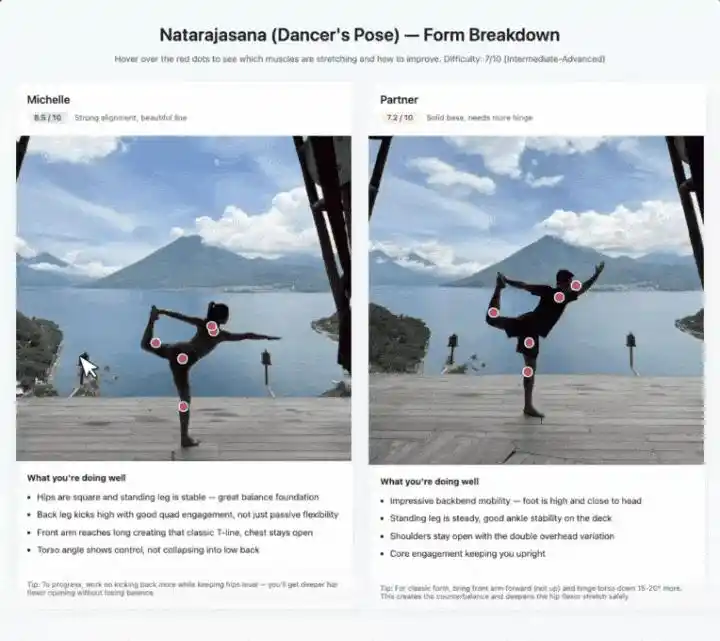
В основе этих демо лежит комбинация визуальных STEM-вопросов, распознавания сущностей и定位 объектов.
По отдельности ничего особенного, но объединённые в сценарии, они действительно позволяют увидеть产品意图 behind термина «персональный сверхразум».
Ещё одна новая функция, которую стоит выделить отдельно, — «Режим покупок».
Ван в твите сказал, что режим покупок может «распознавать создателей, бренды и стильный контент, на которые вы подписаны в Instagram, Facebook и Threads, и преобразовывать это в персонализированные рекомендации».
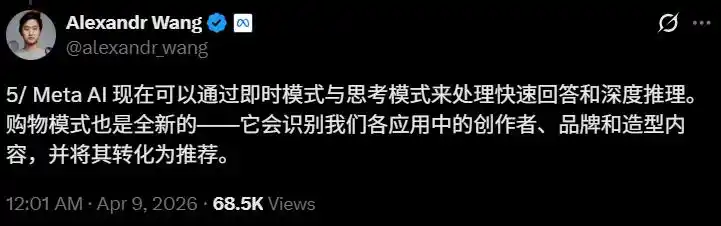
Это уникальное преимущество Meta: данные о поведении 3 миллиардов ежедневных активных пользователей в соцсетях + AI-помощник по покупкам — огромное пространство для коммерциализации.
Три кривые Scaling, вычисления сокращены на 90%, мысли само-сжимаются
Главное в техническом блоге — не бенчмарки, а Scaling.
Meta разбила производительность Muse Spark на три оси: предобучение, обучение с подкреплением, вычисления во время тестирования. Каждая подкреплена соответствующей кривой масштабирования.
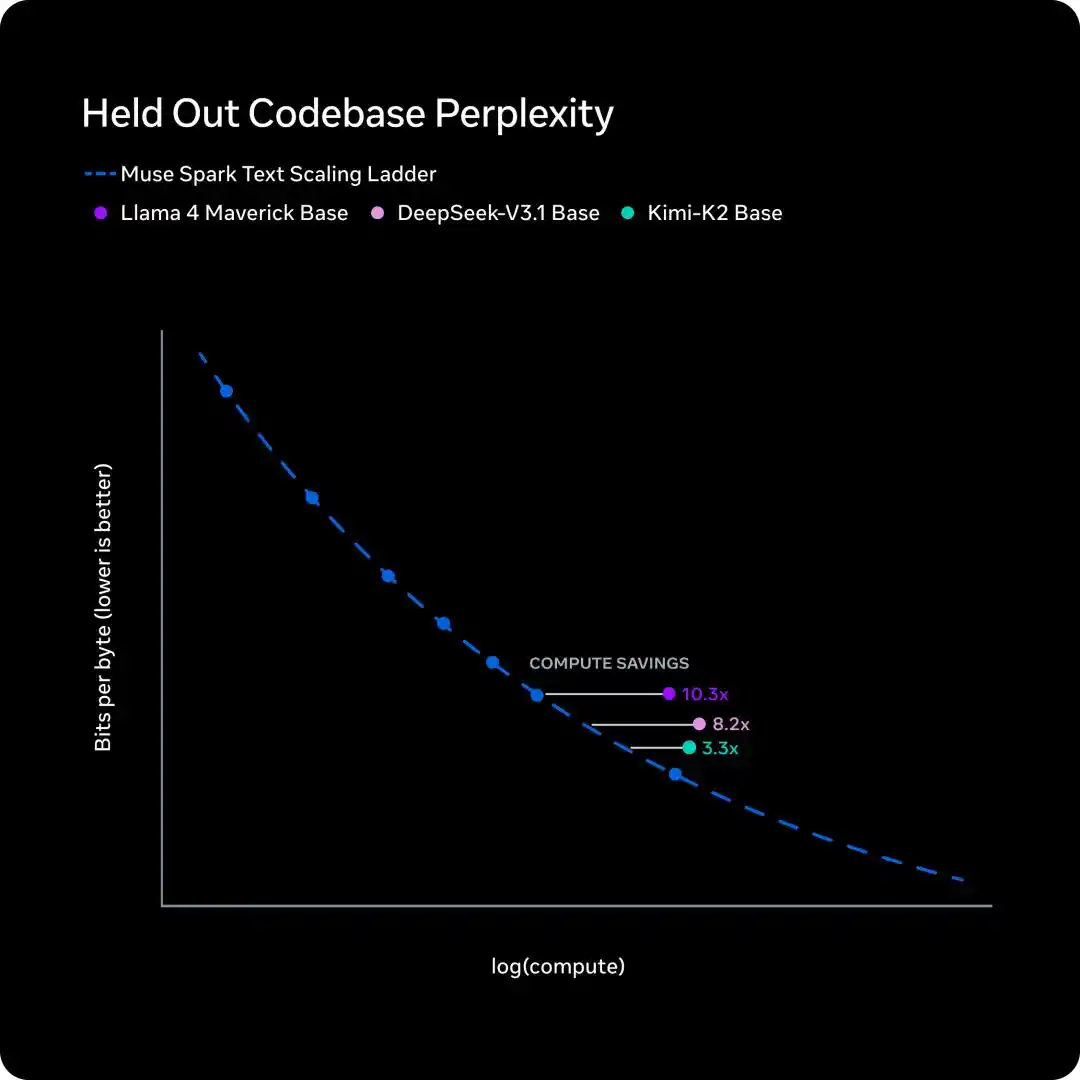
Предобучение: та же способность, вычисления сокращены до 1/10
За последние девять месяцев Meta полностью обновила стек технологий предобучения: переработаны архитектура, алгоритмы оптимизации, стратегии данных.
Чтобы измерить эффект, Meta аппроксимировала Scaling Law на серии небольших версий, а затем сравнила, сколько вычислительных FLOPs требуется для достижения одного и того же уровня производительности.
Вывод категоричен: для того же уровня способностей Muse Spark требуется менее десятой части вычислительных мощностей по сравнению с Llama 4 Maverick.
Эта кривая говорит об одном: Meta не просто закупает больше GPU, а с底层 повышает отдачу от каждой единицы вычислений.
Юйчэнь Цзинь (Yuchen Jin) из Университета Вашингтона в X точно подметил: «Я до сих пор считаю, что инфраструктура — это настоящий 护城河 AI-лабораторий. Потому что если ты можешь обучать быстрее, исследователи могут быстрее экспериментировать с большим количеством идей.»
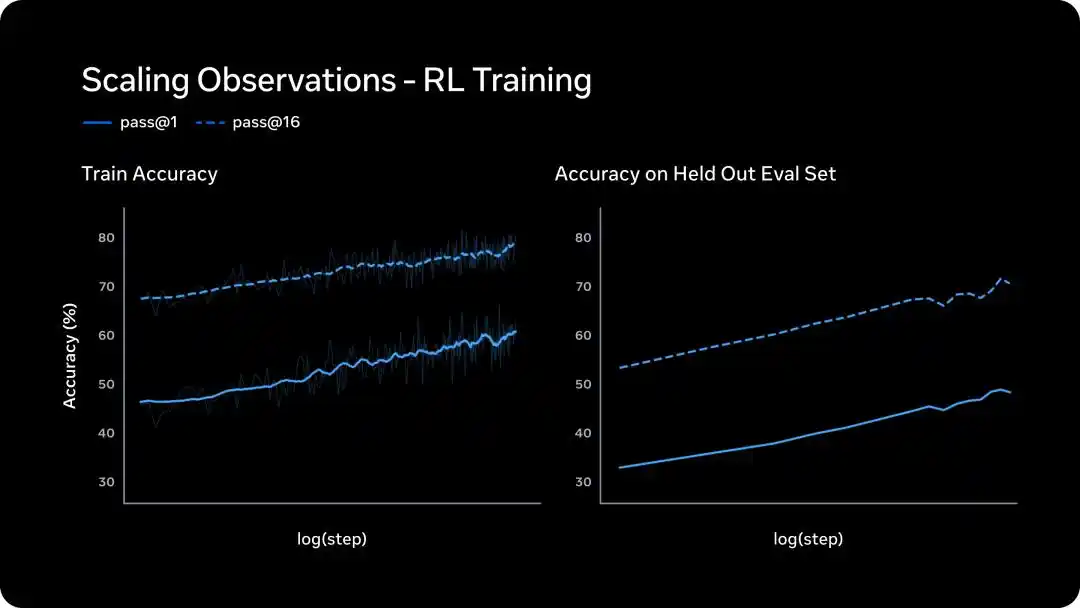
Обучение с подкреплением: логарифмически-линейный рост, обобщение на невиданные задачи
Крупномасштабное RL печально известно своей нестабильностью, но Meta заявляет, что кривые RL в новом технологическом стеке异常 гладкие.
Левый график показывает производительность на обучающей выборке. pass@1 и pass@16 (хотя бы один правильный из 16 попыток) демонстрируют логарифмически-линейный рост.
Это означает, что RL повышает надёжность, не жертвуя разнообразием решений. Muse Spark не «идёт напролом по одному пути», он сохраняет гибкость для исследования различных подходов.
Правый график важнее — это точность на отложенной оценочной выборке.
Кривая同样稳步 растёт, что означает: прогресс, достигнутый благодаря RL, — не зубрёжка, а способность обобщать на совершенно новые, невиданные ранее задачи.
Вычисления во время тестирования: мысли сначала расширяются, затем сжимаются, затем снова расширяются
Это самая технически сложная и интересная часть.
RL научил Muse Spark сначала «прокрутить в уме» перед ответом — это и есть вычисления во время тестирования.
Но проблема в том, что предоставление такого сервиса миллиардам пользователей неподъёмно по стоимости токенов.
Решение Meta состоит из двух шагов.
Первый шаг — добавление «штрафа за время размышления» в обучение RL. Ты можешь думать дольше, но за слишком долгое раздумье будешь оштрафован.
Это ограничение вызвало интересный феномен «фазового перехода».
Производительность на подмножестве AIME такова: на ранних стадиях обучения Muse Spark улучшал точность, думая дольше, кривая延伸 вправо.
Затем штраф за длину triggered «сжатие мыслей». Muse Spark научился решать ту же задачу с гораздо меньшим количеством токенов, кривая折返向左.
После завершения сжатия он снова удлинил процесс решения, чтобы бросить вызов более сложным задачам.
Вся траектория描绘出先右拐, 再左拐, 再右拐的三段式 путь эволюции.
Второй шаг — решение проблемы задержки.
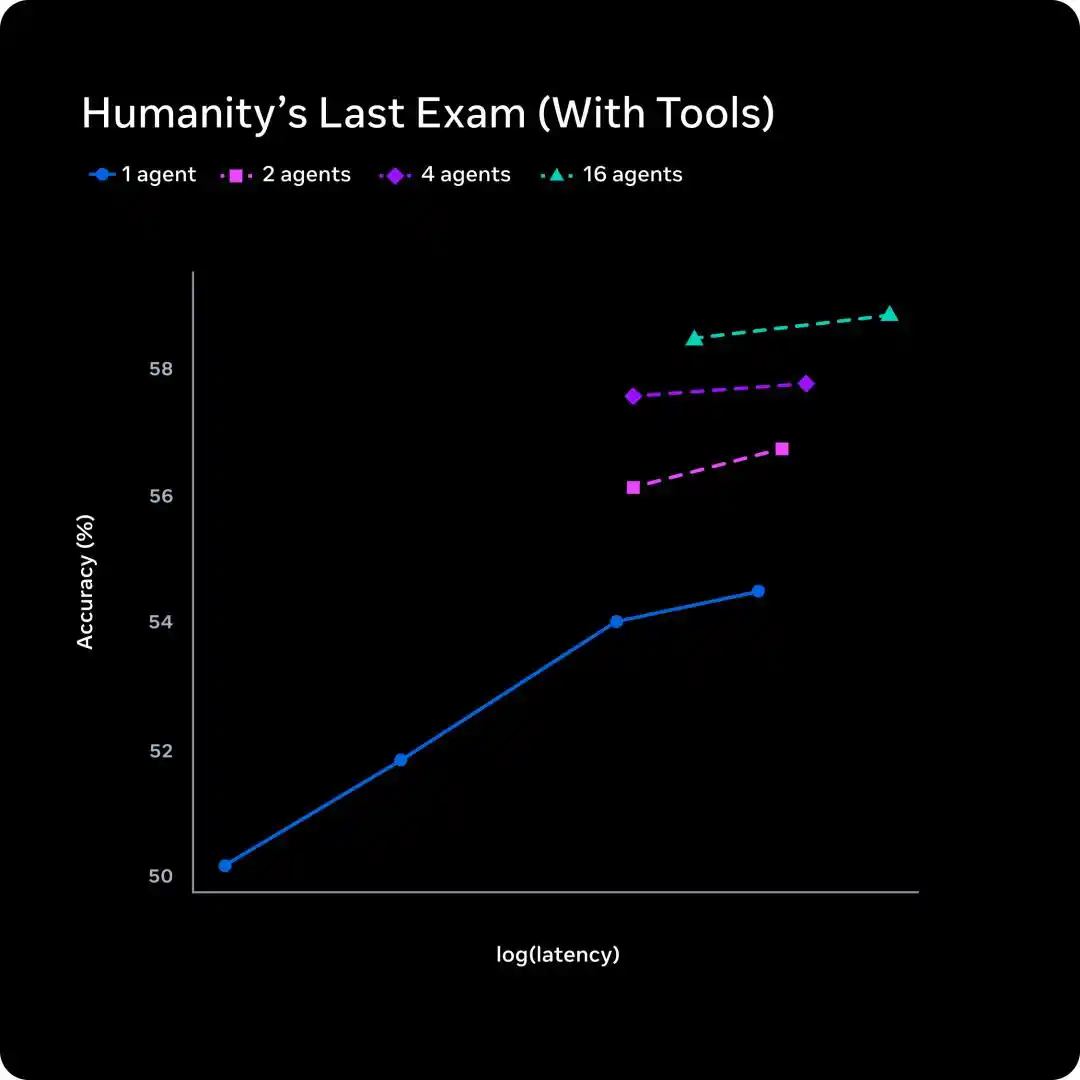
Один агент думает дольше — задержка линейно растёт.
Подход Meta — увеличение количества параллельных агентов: 1, 2, 4, 16 агентов думают одновременно.
Согласно графику, 16 агентов при схожем уровне задержки повысили точность примерно с 54% до约 58%.
Традиционное Scaling во время тестирования — это обмен времени на качество, а Multi-Agent Scaling — это обмен степени параллелизма на качество при几乎 неизменной задержке.
Команда «самых дорогих китайцев» Кремниевой долины сдала первый экзамен
За Muse Spark стоит прошлогодняя полная перестройка AI-системы Meta Цукербергом.
В июне 2025 года Meta приобрела 49% акций Scale AI за 14,3 миллиарда долларов, переманив её основателя Александра Вана на должность первого главного директора по AI Meta и создав Суперразумную лабораторию Meta (MSL).
В то же время присоединились бывший CEO GitHub Нат Фридман (Nat Friedman) (совместное руководство продуктами и прикладными исследованиями), сооснователь SSI Дэниел Гросс (Daniel Gross), а также 11 исследователей, перешедших из OpenAI, DeepMind, Anthropic.

Теперь выпуск Muse Spark доказывает一件事: девятимесячная перестройка Meta超级智能实验室 принесла результаты.
Эффективность предобучения выросла на порядок, кривые масштабирования RL гладкие и предсказуемые, в мультимодальности и медицине достигнут уровень первого эшелона.
Но разрыв в коде и агентах налицо, режим размышлений ещё не открыт полностью, график открытия исходного кода также остаётся «пожеланием».
Более现实ное давление заключается в том, что на той же неделе Anthropic выпустила якобы «слишком сильный для публикации» Mythos, а новое творение OpenAI с кодовым названием Spud также в пути.
За 14,3 миллиарда куплен входной билет. Следующие экзамены будут настоящими.
参考资料:
https://ai.meta.com/blog/introducing-muse-spark-msl/
https://ai.meta.com/blog/scaling-how-we-build-test-advanced-ai/
https://ai.meta.com/static-resource/muse-spark-eval-methodology
https://x.com/alexandr_wang/status/2041909376508985381
本文来自微信公众号“新智元”,作者:新智元