Именно сегодня вышел свежий рейтинг Code Arena!
Qwen3.7-Max с результатом 1541 балла ворвался в мировой топ-4, обогнав целый ряд ведущих моделей, таких как GPT-5.5, Gemini 3.5 Flash и другие.
Впереди него остались только Claude Opus 4.7 и Opus 4.6.
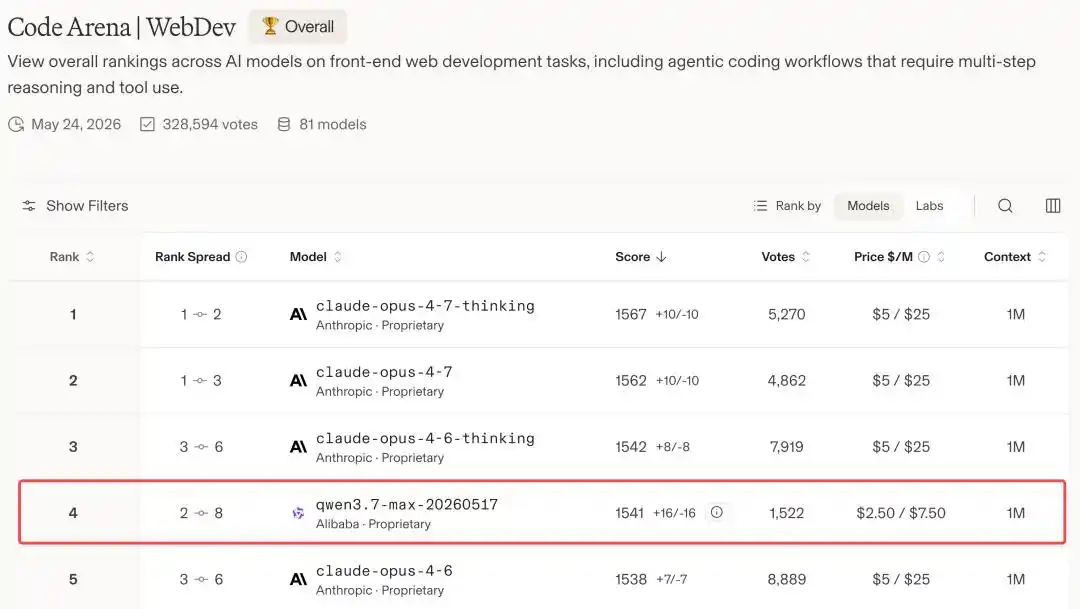
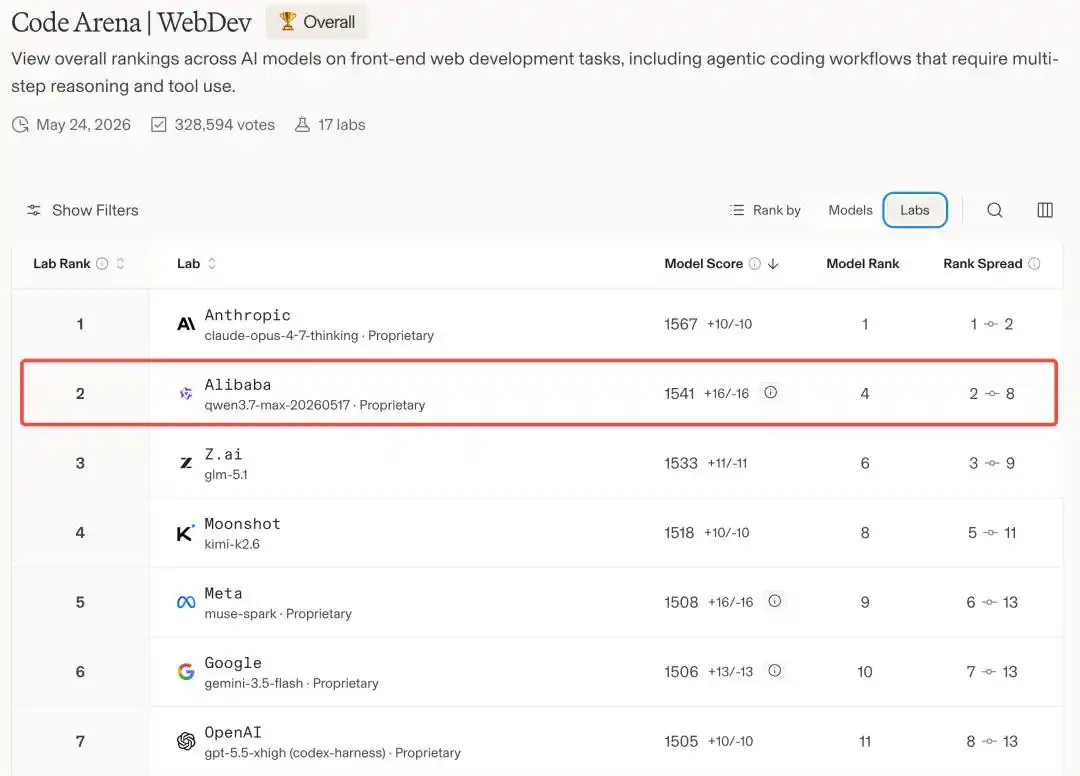
Другими словами, на мировой арене моделей программирования Alibaba — единственный китайский производитель, пробившийся за этот стол, занимающий второе место после Anthropic.
Qwen3.7-Max врывается в мировой топ-5
Единственная модель не от Claude
На самом деле, ещё до публикации рейтинга Code Arena, Qwen3.7-Max уже завоевала репутацию в среде зарубежных разработчиков.
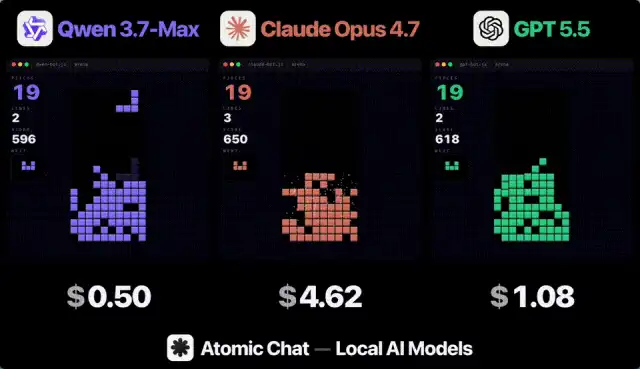
Atomic Chat провёл жёсткое сравнение, поставив Opus 4.7, GPT-5.5 и Qwen3.7-Max соревноваться друг с другом. Задача — написать самообучающийся ИИ для игры «Тетрис».
В итоге, Qwen3.7-Max не только превзошла Opus 4.7 и GPT-5.5 при стоимости токенов всего в $1.32, но и повысила производительность на 56%.
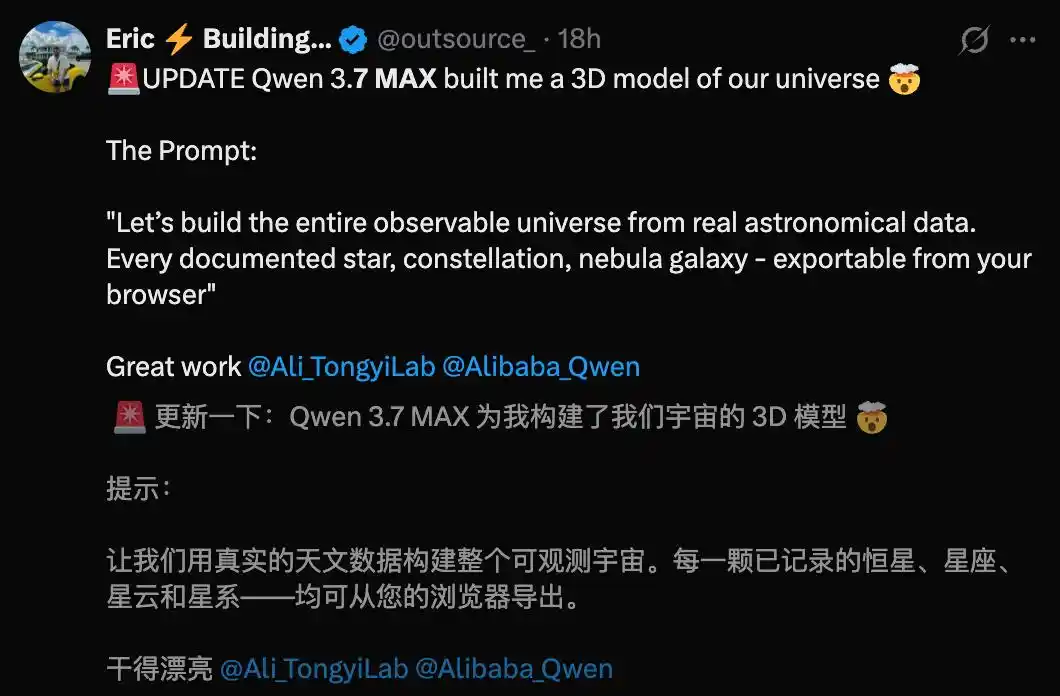
Другой зарубежный разработчик решил, чтобы Qwen3.7-Max построила 3D-модель вселенной, и результат можно охарактеризовать как потрясающий.
В задаче по генерации «3D пиксельной модели миниатюрной пагоды» скорость и качество вывода Qwen3.7-Max также полностью превзошли конкурентов.

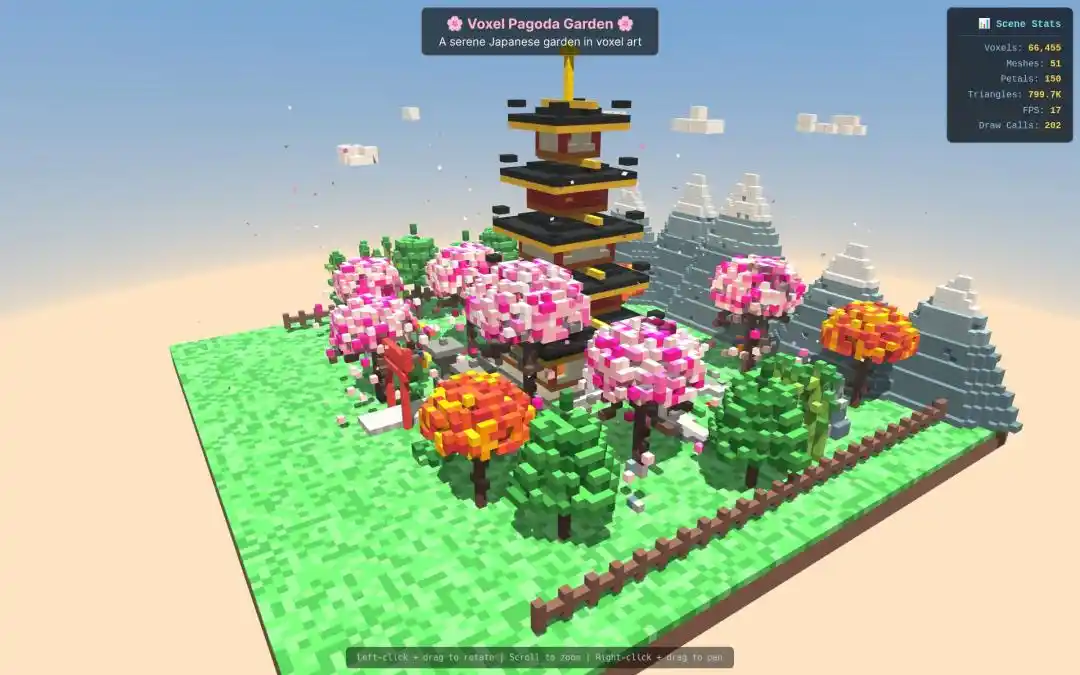
Разработчик Пол Куверт также высоко оценил, что после подключения Qwen3.7-Max к Hermes Agent и OpenCode, она в основном может заменить GPT-5.5 и Opus 4.7.
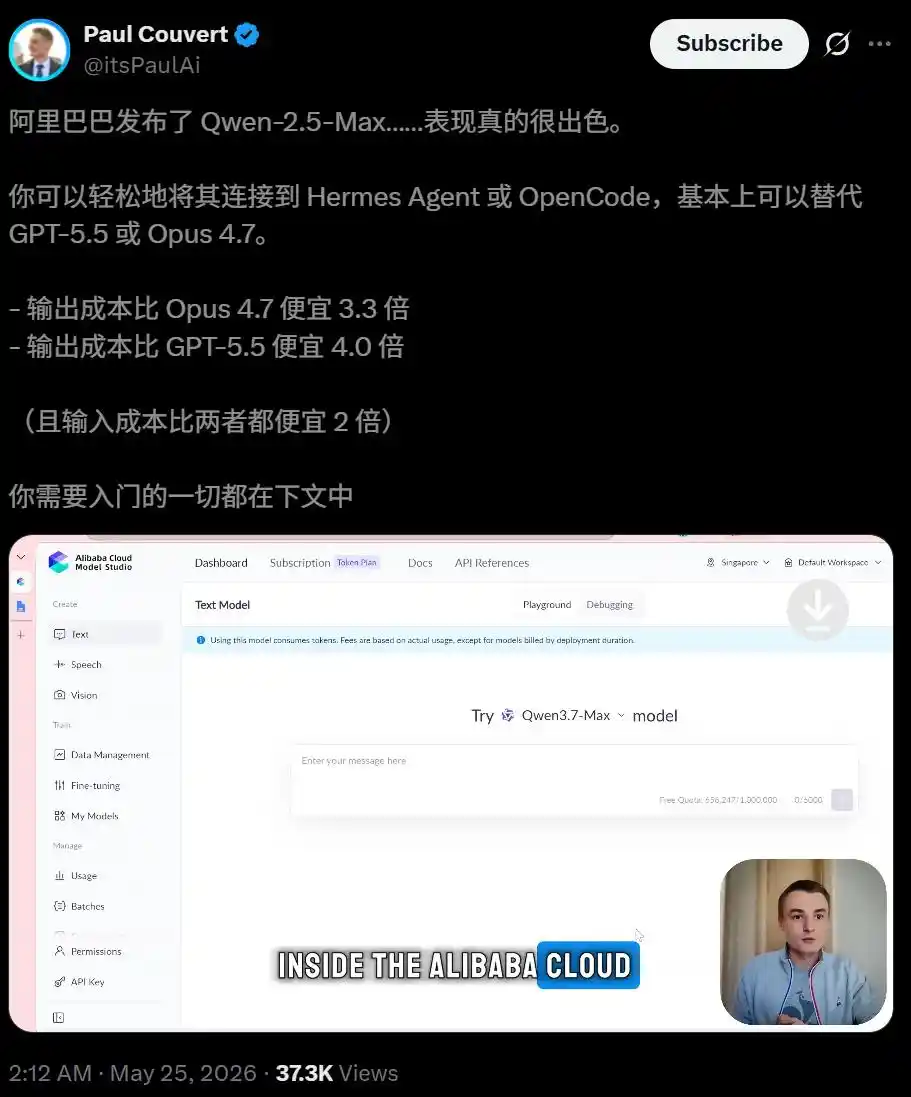
Программирование — невероятно мощное
Однако высокие бенчмарки — это одно, а реальные испытания — другое.
Мы устроили Qwen3.7-Max жёсткое испытание в виде задачи по созданию «гоночной игры».
Подробный промпт был передан модели, и вскоре Qwen3.7-Max прямо выдала готовый к запуску HTML-файл.

В первой версии была небольшая ошибка: клавиши поворота A/D были перепутаны (влево/вправо).
Но после второго раунда простой корректировки через диалог, полноценная 3D-гоночная игра была запущена.

Честно говоря, в момент открытия мы были немного шокированы.
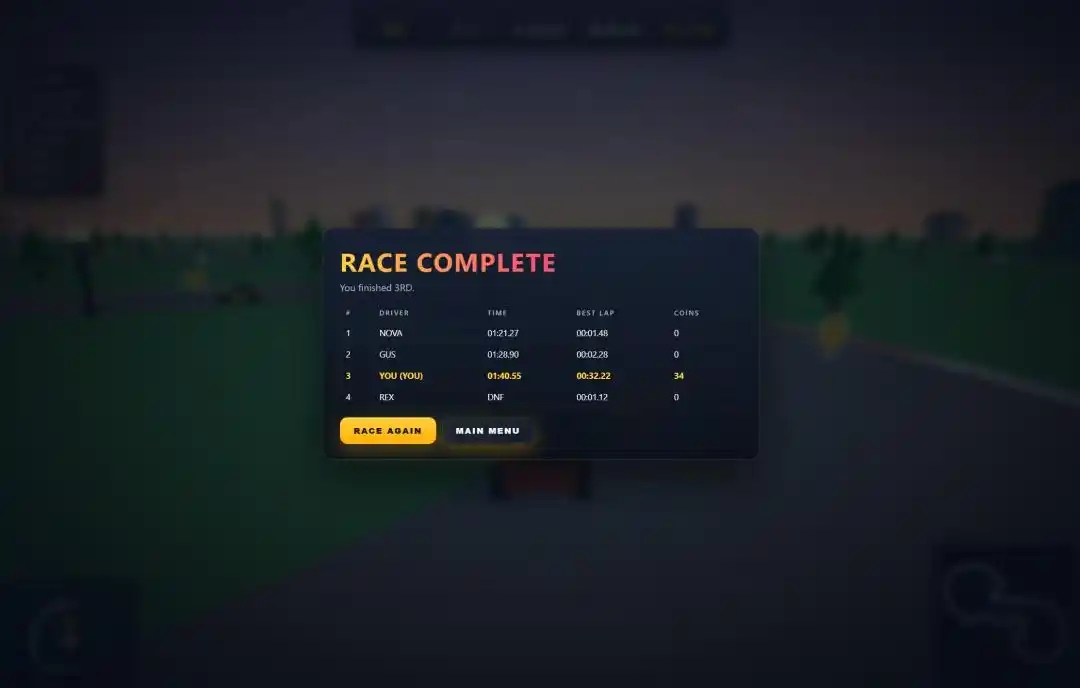
Четыре машины на трассе одновременно, 3 круга кольцевой гонки, на трассе разбросано более 100 золотых монет, при столкновении с препятствием происходит замедление и потеря контроля.
Панель результатов после гонки включала рейтинг, время, количество монет, самый быстрый круг — ничего не упущено.
Но по-настоящему удивили две детали, которые сделал только Qwen3.7-Max.
Первая — начальный экран. После тестирования четырёх моделей, только он создал полноценный начальный экран для игры, и нажатие «Start» запускало гонку. Остальные три сразу начинали гонку, без даже заглавного экрана.
Вторая — звуковые эффекты. В конце промпта было дополнительное требование добавить звук рева двигателя и звук сбора монет. Из четырёх моделей только Qwen3.7-Max реализовал этот бонус, добавив и звук двигателя, и звон монет.
Давайте посмотрим на результаты других участников.
Графика Gemini 3.5 Flash заметно беднее, не хватает того ощущения объёма.
С расположением элементов UI тоже проблемы: информация на приборной панели разбросана по четырём углам экрана, визуальный фокус рассеян.
В то время как Qwen3.7-Max разместил ключевые показатели в центре экрана, что более естественно для взгляда игрока.

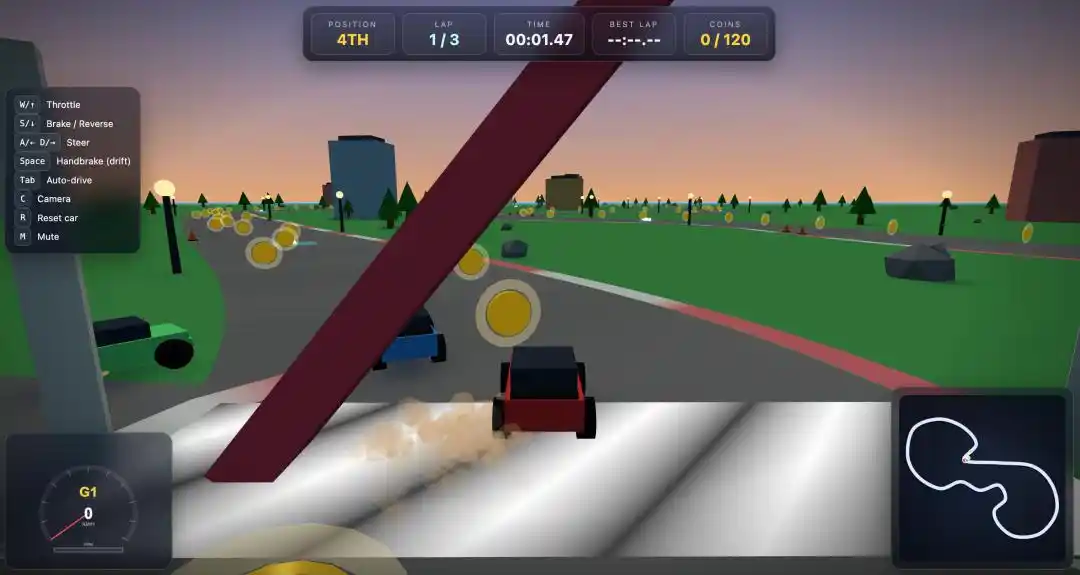
Результат Claude Opus 4.6... сложно описать словами.
Не только монет на трассе было катастрофически мало, но и 3 машины с ИИ двигались почти синхронно, без какой-либо случайности, как будто скопированные.
Наконец, GPT-5.5.
Видно, что качество графики действительно лучше, чем у первых двух, и управление более плавное.
Но непонятно почему, монеты были сделаны в виде жёлтых «пончиков»...
Форма — мелочь. Ключевое в том, что Gemini, Claude и ChatGPT потребовалось несколько раундов исправления багов, чтобы запустить все функции.
Только Qwen3.7-Max в первом раунде сгенерировал в основном играбельную версию.
Результаты тестов близки, практические испытания подтверждают, а цена составляет лишь доли от конкурентов. Остальное — за разработчиками и их выбором.
«Базовая» модель эпохи Agent
То, как Qwen3.7-Max смог продемонстрировать такой уровень на самой конкурентной арене программирования, скрыто в его продуктовом позиционировании.
Несколько дней назад, когда Alibaba представляла Qwen3.7-Max, ей был присвоен очень специфический ярлык: Базовая модель для Agent.
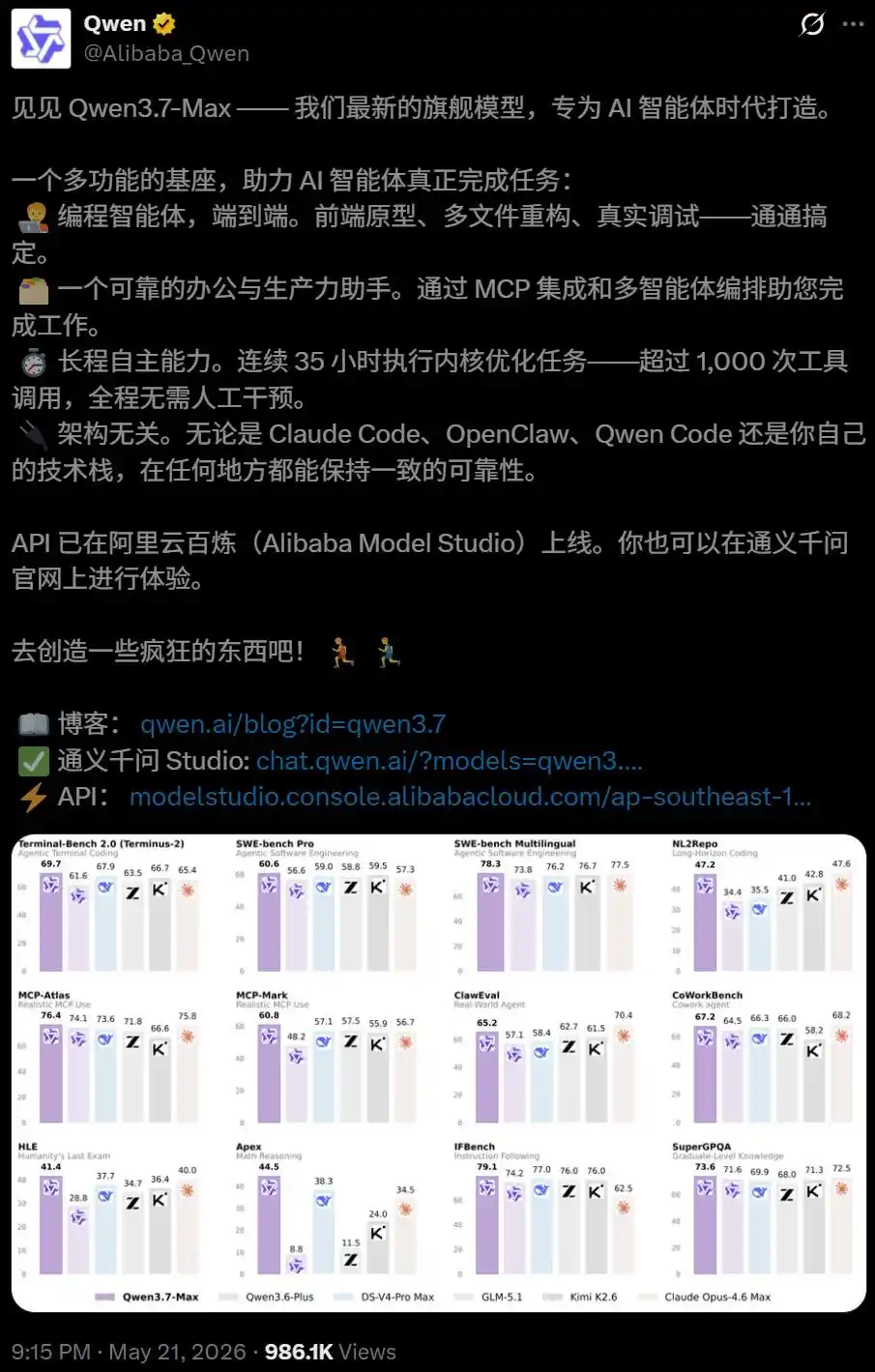
Она создана как модель, предназначенная для длительного автономного выполнения задач.
Данные внутреннего тестирования показывают, что в одной автономной задаче по программированию Qwen3.7-Max непрерывно работала 35 часов, выполнив 1158 вызовов инструментов.
В итоге сгенерированный код по сравнению с эталонной реализацией Triton достиг ошеломляющего 10-кратного среднего геометрического ускорения.
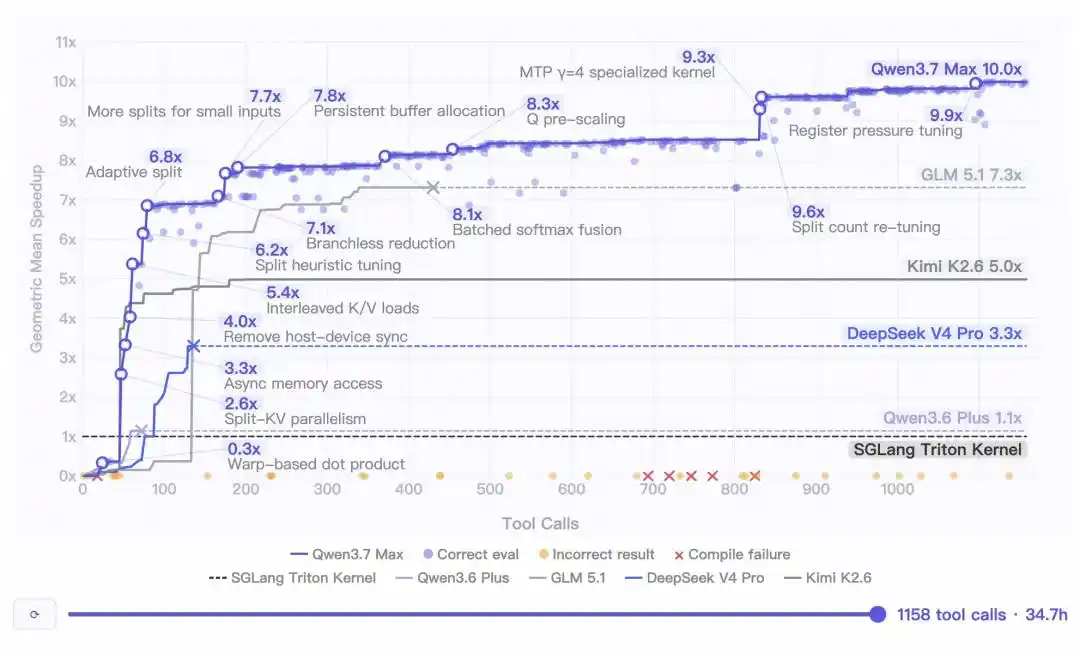
Ещё более впечатляет её способность вести «затяжные бои» —
Даже после 30 часов рассуждений модель сохраняла остроту и продолжала находить новые возможности для оптимизации.
Полностью без деградации контекста, без дрейфа инструкций, без бесконечных циклов!
Нужно признать, что сложность не в самих 1000 вызовах инструментов. С распространением протокола MCP, 1000 вызовов — не редкость.
Сложность в 35 часах последовательных рассуждений.
Большинство моделей «ломаются» при выполнении длительных задач: либо контекст накапливается и путается, цели, поставленные вначале, к концу полностью забываются; либо они входят в бесконечный цикл, повторяя одну и ту же неудачную стратегию.
Qwen3.7-Max смогла реализовать принцип «постоянно делать правильные вещи».
Раскрытие ключевых технологий
Мы полагаем, что этот скачок Qwen3.7-Max в программировании может быть связан с улучшением двух методов обучения.
Во-первых, расширение среды (Environment Expansion).
При обучении программированию каждая задача для Qwen3.7-Max разделяется на три независимых измерения: сама задача, среда выполнения и способ проверки. Эти три компонента комбинируются произвольно.
Одна и та же задача иногда выполняется в среде Claude Code, иногда в OpenClaw, иногда с другим способом проверки.
Эффект похож на то, как стажёра ротируют по всем проектным группам. Он вынужден учиться универсальным стратегиям решения проблем, а не «как схитрить в конкретной среде».
Это объясняет неинтуитивное явление: Qwen3.7-Max стабильно показывает себя в средах Claude Code, OpenClaw, Qwen Code, без ситуации «отлично в своей среде, но провал в другой».

Второе улучшение — длительное автономное выполнение (Long-Range Autonomous Execution).
В обучение команда внедрила фреймворк «динамической накопительной игры на выживание».
То есть, модель принимает последовательные решения на протяжении более тысячи шагов в постоянно меняющейся симулированной среде, самостоятельно строит гипотезы, корректирует стратегию на основе обратной связи, и при этом не должна страдать от «коррупции контекста» из-за долгой работы.
Есть наглядные данные: в симуляции управления стартапом в течение целого года по бенчмарку YC-Bench, Qwen3.7-Max достигла выручки в 2.08 миллиона долларов, что в два раза больше, чем у предыдущего поколения (1.05 млн).
Что ещё важнее, она продемонстрировала эволюцию стратегии: в середине, столкнувшись с кризисом, смогла самостоятельно изменить направление, выявить и заблокировать злонамеренных клиентов, в конечном итоге сойдясь к стабильному циклу выполнения.
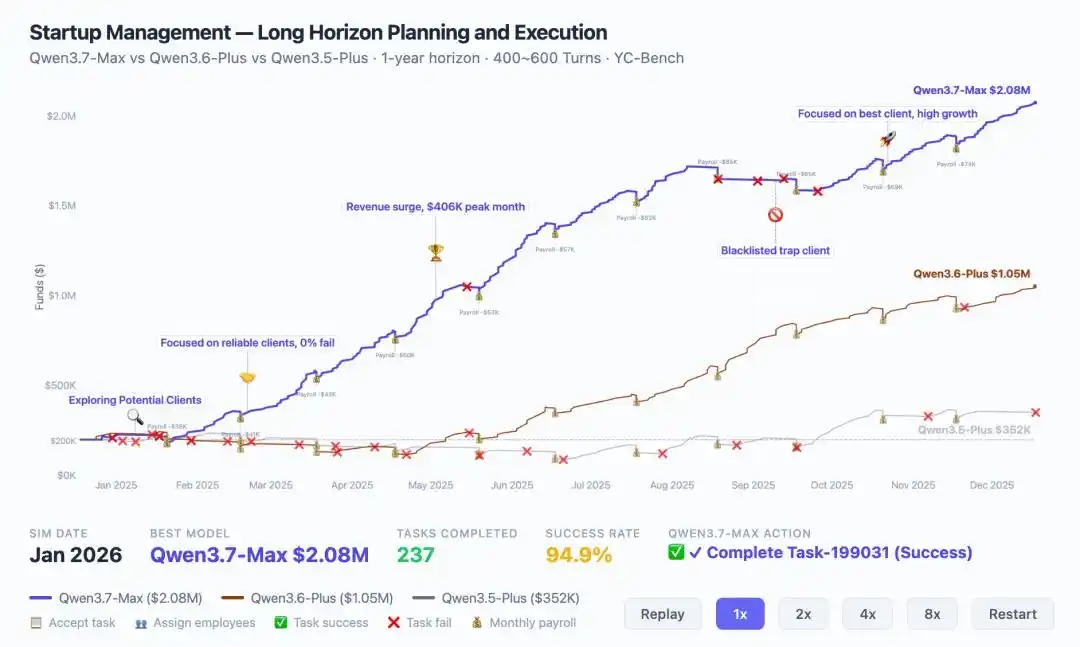
Это основа для случая с 35-часовой оптимизацией ядра, и именно поэтому в Kernel Bench L3, Qwen3.7-Max смогла обеспечить ускорение в 96% сценариев.
А программирование — лишь первое поле битвы. Эта основа долгосрочных рассуждений и вызова инструментов указывает на более масштабные амбиции — универсальную базовую модель для Agent.
В финал программирования добавился новый «нарушитель спокойствия»
С момента своего запуска, Code Arena всегда тестировал суровые навыки: многошаговые рассуждения, оркестрация инструментов, доставка целых проектов — всё это настоящие испытания уровня Agent.
Сегодня Qwen3.7-Max с результатом 1541 балла вклинилась на четвёртое место, между Opus 4.6 Thinking и Opus 4.6.
На этой трассе, где Claude доминировал большую часть года, она дала свой ответ: китайские модели — не просто догоняющие, они тоже могут быть определяющими игроками.
Мировая гонка моделей программирования больше не является монополией Кремниевой долины.
Источники:
https://arena.ai/leaderboard/code/webdev
Статья взята с официального аккаунта WeChat «Новая Эпоха Искусственного Интеллекта», автор: ASI Апокалипсис





