Автор | Ван Бо, «Дзяцзы Гуаннянь»
Источники, близкие к DeepSeek, сообщили «Дзяцзы Гуаннянь», что внутри DeepSeek организуется новая команда Harness, направленная на создание продуктов в виде интеллектуальных агентов для работы с кодом, внутренне ориентируясь на Claude Code компании Anthropic.
Старший научный сотрудник DeepSeek Чэнь Дэли также подтвердил эту информацию в социальных сетях, заявив: «DeepSeek организует новую команду Harness для работы над продуктами и исследованиями в направлении Harness», и прямо указал, что «проще говоря, это ориентация на Claude Code, создание DeepSeek Code Harness».
Это не обычный набор персонала.
Информация о вакансиях показывает, что DeepSeek открыла две ключевые должности: Менеджер продукта Harness и Инженер-разработчик Harness, место работы в настоящее время ограничено Пекином. Офис DeepSeek в Пекине находится в Центре Ронгке Чжисюнь в районе Хайдянь, недалеко от Пекинского университета и Университета Цинхуа. В официальных источниках это место описывается как расположенное в «Столетней инновационной зоне AI Цзинчжан», а в народных кругах оно также находится в недавно популярном «районе Ван Хуйвэня».


Ключевое определение: Модель + Управление = Агент
В описании вакансии ключевая формула помещена на самое видное место:
Эту фразу почти можно считать внутренним определением DeepSeek пути продуктивизации на следующем этапе: сама модель является лишь основой агента, а управление контекстом, вызов инструментов, планирование задач, чтение и запись файлов, изменение кода, выполнение в терминале, сбор обратной связи, цикл оценки — всё это ключевые части, которые действительно позволяют агенту интегрироваться в рабочий процесс.
В описании вакансии далее написано: «Мы превращаем передовые возможности моделей DeepSeek в ведущие продукты-агенты. Вся работа, кроме самой модели, относится к сфере Harness». Кроме того, эта должность будет участвовать во всем процессе создания «Настольного продукта-агента DeepSeek» и «определять понимание Harness в DeepSeek».
«Дзяцзы Гуаннянь» анализирует, что DeepSeek хочет не просто создать плагин-помощник по коду, а дополнить промежуточный слой между моделью и реальным рабочим процессом.
Прошлый год доказал: способность работать с кодом не означает, что разработчики действительно будут её использовать; способность модели писать код не означает, что она может последовательно выполнять инженерные задачи.
То, что действительно меняет рабочий процесс разработчиков, — это не отдельная модель Claude, а Claude Code; не отдельная модель GPT, а Codex; не ответ с кодом в окне чата, а инженерный агент, который может войти в терминал, понять проект, читать и записывать файлы, выполнять команды, исправлять ошибки, управлять Git и вызывать инструменты.
Раньше самой сильной стороной DeepSeek была модель. Теперь она начинает добавлять тот самый слой «рук» над моделью.
I. Почему DeepSeek подчеркивает Harness
В традиционном контексте продуктов AI «помощник по коду» обычно означает два типа продуктов: один — это плагин автодополнения в IDE, другой — вопросы и ответы по коду в окне чата.
Но слово, которое постоянно появляется в этом наборе персонала DeepSeek, — это не Code Assistant, а Harness.
В инженерном контексте Harness изначально означает «испытательный стенд» или «рабочий фреймворк». В контексте агентов это скорее внешняя система, которая заставляет модель действительно действовать. Модель отвечает за понимание, рассуждение и генерацию, а Harness отвечает за подключение этих возможностей к реальной среде.
В описании должности упоминается, что эта роль требует планирования дорожной карты продукта DeepSeek Harness, координации исследователей, инженеров, сообщества open source и конечных пользователей, а также глубокого общения с исследователями команды обучения модели для реализации совместной эволюции модели и Harness.
Это предложение ключевое.
Оно показывает, что DeepSeek хочет не просто обернуть существующую модель в оболочку, а сделать сам продукт-агент частью эволюции модели. Раньше обычная логика продуктов в компаниях, занимающихся большими моделями, была такова: исследовательская команда сначала обучает модель, а продуктовая команда затем создает приложения на основе возможностей модели. Но в эпоху агентов этот порядок меняется. Продукт перестает быть просто выходом для возможностей модели, а становится тренировочной площадкой для них.
Неудача кодового агента в реальном проекте может быть вызвана не проблемой взаимодействия с продуктом, а неправильным способом сжатия длинного контекста моделью; возможно, это не проблема цепочки вызова инструментов, а нестабильная стратегия модели по декомпозиции задач; также это может быть не недостатком способностей к коду, а отсутствием постоянного понимания инженерных ограничений, обратной связи от тестов и намерений пользователя.
Таким образом, ценность команды Harness заключается не только в «создании продукта», но и в превращении реальных задач разработки в источник постоянной эволюции модели.
II. Почему DeepSeek обязательно должен дополнить Code Harness?
DeepSeek давно сделал ставку на возможности работы с кодом. От DeepSeek-Coder до DeepSeek-Coder-V2, инвестиции DeepSeek в модели для кода постоянно растут, поддерживаемые языки, длина контекста и способность выполнять сложные задачи постоянно улучшаются. Проблема не в отсутствии возможностей для работы с кодом, а в том, что ранее эти возможности в основном оставались на уровне модели и еще не превратились в высокочастотный продукт в ежедневном рабочем процессе разработчиков.
Популярность Claude Code доказала одну вещь: конкуренция в области AI Coding переходит от конкуренции за возможности моделей к конкуренции за вход в рабочий процесс разработчика.
Это также урок, который DeepSeek должен восполнить сейчас. Более тонкий момент в том, что до официального выхода DeepSeek сообщество разработчиков уже создало для него версию «DeepSeek-версии Claude Code».
Проект с открытым исходным кодом под названием DeepSeek-TUI ранее стал популярным в сообществе разработчиков. Это coding agent, работающий в терминале, который может читать и записывать файлы, выполнять команды Shell, искать в Интернете, управлять Git и координировать под-агентов через интерфейс TUI.
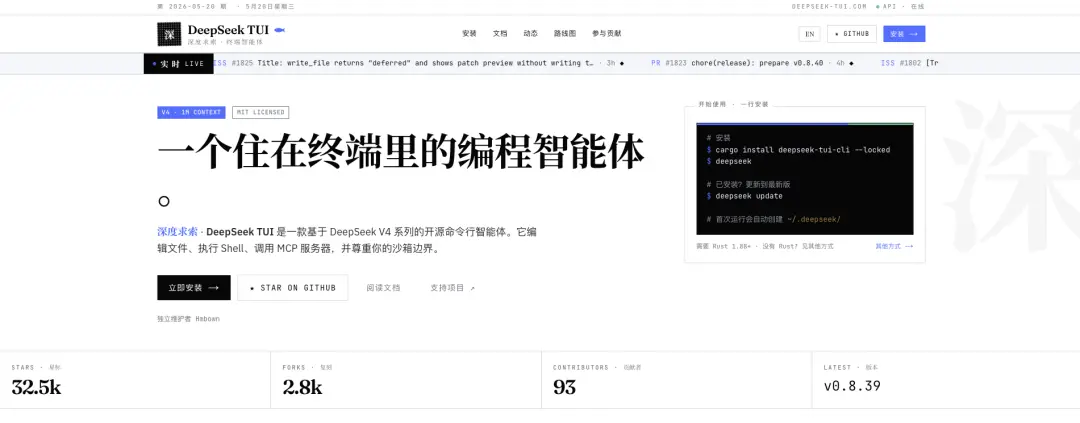
Популярность DeepSeek-TUI указывает на две проблемы:
-
Базовая готовность мышления: Модель DeepSeek уже воспринимается разработчиками как основа для создания агента по коду. В противном случае сообщество не стало бы естественным образом создавать вокруг неё продукты в стиле Claude Code.
-
Отсутствие на официальном уровне: DeepSeek не хватает не внимания к модели, а официального Harness.
В глазах разработчиков привлекательность DeepSeek-TUI очевидна: низкая стоимость, доступность в Китае, длинный контекст, относительно низкий порог развертывания. Многие китайские разработчики не отказываются от Claude Code по желанию, а из-за ограничений по цене, стабильности доступа, системе учетных записей и корпоративному соответствию.
Но у проектов сообщества есть естественные границы:
-
Как бы ни был активен сторонний проект с открытым исходным кодом, ему трудно по-настоящему понять ритм внутренней эволюции возможностей модели;
-
Он может адаптироваться вокруг API, но не может влиять на то, как обучается модель;
-
Он может работать над промптами, цепочками инструментов и оптимизацией взаимодействия, но ему трудно систематически внедрять обратную связь от огромного количества реальных задач в улучшение модели.
Именно в этом заключается значение официального Harness.
Если DeepSeek сам создает Code Harness, у него есть несколько преимуществ, которых нет у проектов сообщества: сотрудничество с командой модели, право на проектирование интерфейсов, замкнутый цикл обучающих данных, внутренние сценарии реальных задач, а также долгосрочная способность управлять экосистемой разработчиков.
Сообщество open source уже проложило путь: разработчикам действительно нужна версия Claude Code от DeepSeek. Теперь DeepSeek должен вернуть этот путь и сделать его своим основным продуктом.
А официальное начало найма персонала DeepSeek означает, что он наконец готов лично выйти на поле.
Чэнь Дэли ещё в ноябре прошлого года на Всемирной интернет-конференции в Учжэне 2025 года упомянул: «Одним из ключевых преимуществ нашей компании является долгосрочность, настойчивое следование основной линии — прорывам в области передового интеллекта. И в этом процессе мы также отказались от многих побочных дел, не занимаемся теми краткосрочными и быстрыми побочными вещами».
После войны моделей начинается настоящая война агентов. На этот раз DeepSeek должен восполнить самый критический слой между моделью и действием — Harness.
DeepSeek наделяет свою модель парой рук.