За последние два года модели генерации видео стремительно развиваются: от потрясающих результатов Sora в конце 24-го года до взрывного появления множества моделей, таких как Google Veo, Sora 2, серия Kling и, в начале этого года, Seedance 2.0. Качество видео, генерируемого ИИ, совершило качественный скачок и теперь позволяет создавать кинематографически реалистичные ролики продолжительностью в несколько минут, с множеством персонажей и сложными сценами.
В то время как сторона генерации стремительно развивается, внимание исследовательского сообщества к детекции AI-видео остается умеренным.
А в реальности мы легко можем наблюдать, что мультимодальная природа видео, несущая гораздо большую обманчивость, чем изображения, оказывает огромное социальное влияние:
На различных социальных платформах появляется все больше фальшивых видео, сгенерированных ИИ, и их количество, качество и охват стремительно растут. Когда пользователи спрашивают базовые модели, такие как Grok или Doubao, «сгенерировано ли видео ИИ», ответы часто сводятся к простым да/нет без объяснений и надежности; на таких платформах, как Xiaohongshu, реально снятые видео часто помечаются как «возможно, сгенерированы ИИ».
Между быстрым развитием генерации и недостатком внимания к детекции зияет огромная пропасть, и мы должны своевременно обратить на это внимание: в эпоху быстрых итераций генерации видео ИИ, на каком этапе находятся исследования по детекции таких видео, какую парадигму сменяют и в каких направлениях следует двигаться в будущем.
В этом контексте исследователи из MBZUAI, Китайского народного университета и Гарвардского университета совместно написали и опубликовали обзор объемом в пятьдесят страниц. Впервые систематизировав технические пути от низкоуровневого визуального восприятия до высокоуровневых мировых рассуждений с точки зрения зрения и языка, они проанализировали настоятельную необходимость в многоуровневой, динамической, прослеживаемой и объяснимой системе достоверной детекции, основанной на совокупности доказательств. Работа уже принята на ACL 2026.

Ссылка на статью:https://www.researchgate.net/doi/10.13140/RG.2.2.31713.88168
Ссылка на GitHub:https://github.com/dxhou/AI-Generated-Video-Detection
Ссылка на Homepage:https://AIgcvdetection.github.io
Переосмысление цели детекции видео, сгенерированных ИИ
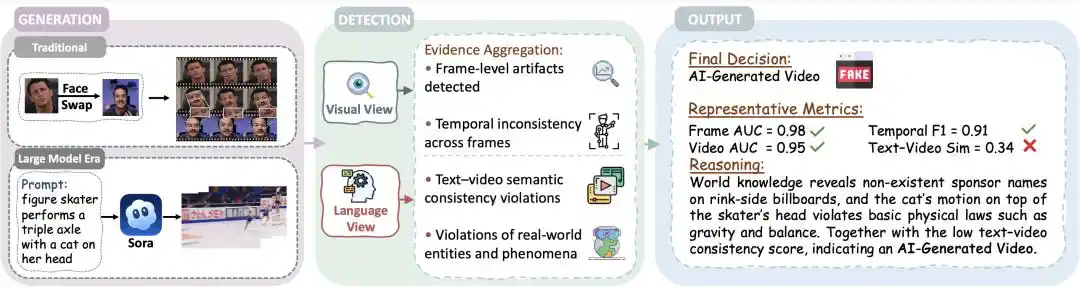
Рисунок 1 | Полный процесс детекции видео, сгенерированных ИИ: от стороны генерации и двойного ракурса детекции до совокупности доказательств
До эры генеративного ИИ видео, созданные ИИ, оставляли относительно заметные визуальные артефакты. Исходя из этой предпосылки, в ранних сценариях Deepfake, таких как замена лица, проверки на уровне кадров с точки зрения визуального восприятия было достаточно.
Однако за последние два года качество видео в эпоху стремительно развивающегося генеративного ИИ постепенно перешагнуло эту «предпосылку». Человеческому глазу становится все труднее отличить реальное, полное видео от поддельного. В этой ситуации простой бинарный вывод детектора уже не удовлетворяет потребностям, и крайне важно ответить на вопрос: на основе каких доказательств детектор делает достоверное суждение.
Данный обзор сначала расширяет границы задачи детекции: он указывает, что вывод детектора должен эволюционировать от «бинарной классификации правда/ложь» к структурированным, объяснимым и достоверным суждениям, тем самым продвигая объект детекции к проверке расхождений между «виртуальным миром» в видео и «реальным миром».
Следовательно, обзор сначала переопределяет цель детекции, переформулируя ее как «верификацию фактической достоверности», то есть проверку того, соответствуют ли утверждения о содержании видео («кто, когда, где, что произошло») одновременно на перцептивном и когнитивном уровнях реальному миру. Помимо проверки визуальных и межмодальных аспектов, необходимо далее оценивать, не противоречат ли эти утверждения внешним «фактам, физическим законам и мировым знаниям».
Объекты детекции: три парадигмы видео, сгенерированных ИИ

Рисунок 2 | Три типа парадигм видео, сгенерированных ИИ, определенные в данном обзоре
С 2020 года по настоящее время парадигмы генерации видео ИИ претерпели изменения: от локальных манипуляций с видео с помощью GAN в раннюю эпоху Deepfake, до рекомбинации аудио и видео, такой как замена артикуляции и голоса, и далее до полного синтеза видео ИИ, поддерживаемого «симуляторами мира» на основе латентных диффузионных моделей, подобных Sora. Обзор делит видео, сгенерированные ИИ, на следующие три парадигмы:
Видео с локальными манипуляциями, сохраняющие реальный носитель (Local Manipulation Video, LMV)
LMV долгое время была наиболее типичной и зрелой парадигмой для традиционной детекции Deepfake. Само видео обрабатывает локальные области реально снятого видео, например, заменяет лицо или фон; при этом большая часть структуры исходного видео, такая как сцена, действия персонажей, движение камеры, освещение, обычно сохраняется. Поэтому большинство ранних методов были сосредоточены именно на локальных артефактах, частотных характеристиках, геометрических аномалиях и региональной согласованности. Однако способности генеративных моделей в области локального слияния, адаптации освещения и переноса идентичности становятся все сильнее, а обработка на платформах и вторичное распространение еще больше стирают многие мелкие следы; акцент в детекции парадигмы LMV постепенно смещается на робастность методов детекции в различных сценариях.
Редактирование аудио и видео при кросс-модальных ограничениях (Audio-Visual Editing, AVE)
Парадигма AVE в основном возникла в 2024 году. В таких видео, сгенерированных ИИ, изменяются внутренние соответствия, уже установленные в самом видео, между изображением и звуком, артикуляцией, идентичностью говорящего, ритмом речи, содержанием субтитров и т.д. Сюда входит синтез лица, управляемый речью, переозвучка исходного видео, изменение артикуляции, замена говорящего и т.п. Это заставляет сторону детекции перейти от поиска визуальных артефактов к проверке того, действительно ли существуют отношения между несколькими модальностями внутри видео, рассматривая звук, артикуляцию, идентичность и содержание вместе, чтобы найти действительно значимые подсказки.
Сквозной генеративный синтез видео (Generative Video Synthesis, GVS)
В парадигме GVS, взрывной рост которой произошел в 2025 году, модель напрямую генерирует целые видео на основе условий, таких как текст, изображения, шум и т.д., больше не полагаясь на реальное видео в качестве основы. Это создает совершенно новые вызовы для детекции.
Такие видео часто выглядят реалистично на отдельном кадре или в коротком промежутке времени, но в длительных пространственно-временных последовательностях могут проявляться уязвимости: например, действия персонажей или их положение в сцене не могут быть согласованы с предыдущими кадрами, форма объектов или их движение меняются, нарушая физические законы, или само событие в видео не может существовать в реальном мире.
Соответственно, подход к детекции парадигмы GVS не может ограничиваться локальной или межмодальной согласованностью, а должен перейти на более высокий уровень, исходя из долгосрочной согласованности, здравого смысла, физических законов, нарратива и причинно-следственных связей, фактической достоверности и прослеживаемости на уровне утверждений, проверяя в длительных пространственно-временных последовательностях, является ли само содержание правдоподобным, и оценивая, может ли содержание видео быть достоверным на всех уровнях в реальном мире.
Генеалогия методов детекции на четырех уровнях с двойной перспективой «Видео-Язык»
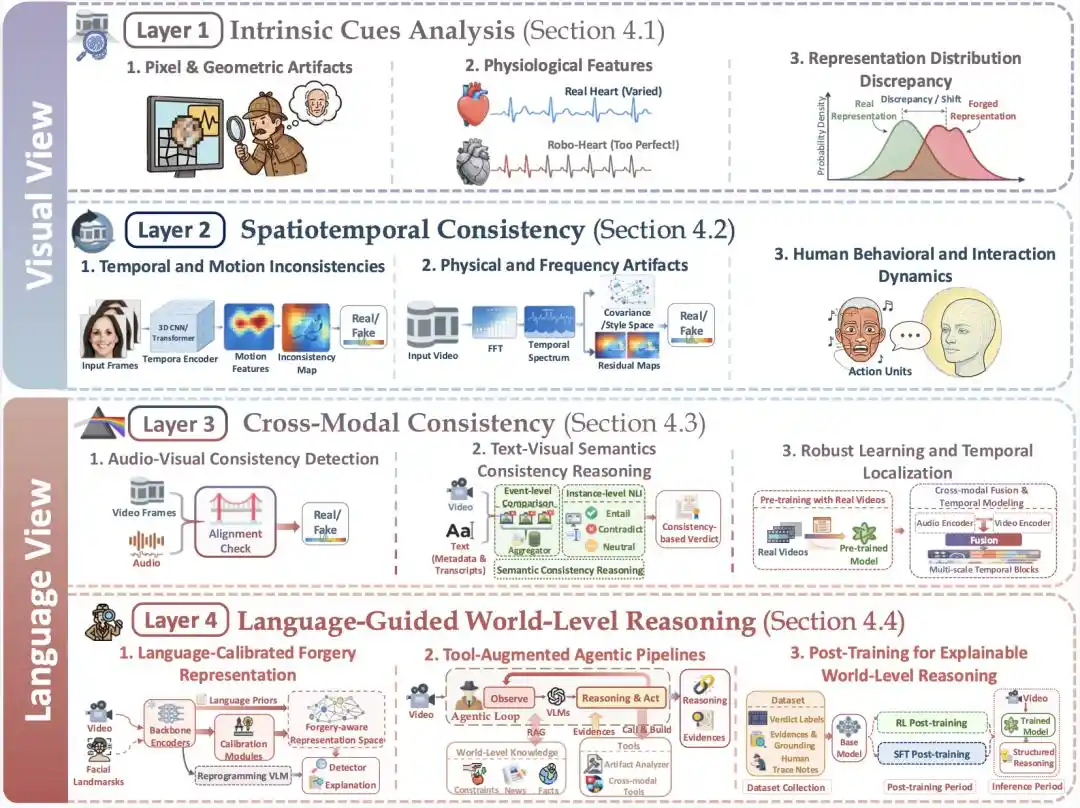
Рисунок 3 | Четырехуровневая структура Vision-Language Dual-View: первые два уровня ориентированы на визуальную перспективу, последние два переходят к языковой
В настоящее время модальные перспективы для детекции видео, сгенерированных ИИ, разделились и могут быть разделены на два основных научных вопроса: первый исходит из визуальной модальности и фокусируется на низкоуровневом сигнальном анализе и пространственно-временной согласованности изображения.
Другой исходит из языковой модальности и охватывает, в том числе, кросс-модальную языковую информацию самого видео, оценивая, «действительно ли видео хорошо согласованно повествует между модальностями»; а также использует языковую модальность для привнесения рассуждений, связанных со знаниями и фактами о мире, оценивая, «может ли содержание видео выдержать проверку внешними знаниями, фактами, законами реального мира».
Обзор улавливает эту тенденцию, предлагая организовать методы исследований и парадигмы оценки детекции видео, сгенерированных ИИ, с точки зрения двойной перспективы «Видео-Язык», и на этой основе далее представляет следующую четырехуровневую картину методов от низкоуровневого восприятия до высокоуровневого познания.
Она включает следующие четыре уровня:
Уровень 1, Низкоуровневые визуальные подсказки (Intrinsic Cues Analysis): Первое сито
Методы уровня 1 сосредоточены на исследовательском вопросе: Соответствуют ли низкоуровневые визуальные сигналы видео статистическим закономерностям, которым должно удовлетворять реальное видео, и существуют ли в видео низкоуровневые подсказки, внесенные процессами генерации или редактирования моделью ИИ.
На уровне низкоуровневых сигналов реальное видео будет соответствовать определенным статистическим свойствам, а видео, полученное в результате реальной съемки и обработки, будет естественным образом соответствовать процессам захвата, кодирования и постобработки; в то время как процесс генерации ИИ часто оставляет следы, отклоняющиеся от распределения реального видео, такие как единообразные стили, водяные знаки и артефакты, связанные с конкретной моделью, обнаруживаемые неестественные физиологические сигналы и т.д. Методы первого уровня, исходя из визуальной перспективы, проводят анализ, моделируя, извлекая и усиливая эти низкоуровневые сигналы. Включая детекцию:
Аномалий в частотной области, текстуре, границах, паттернах шума и геометрических аномалий;
Физиологических сигналов на лице, таких как пульс, крошечные движения мышц, ритм моргания;
Существования систематического смещения в пространстве признаков между реальными и сфабрикованными видео.
Уровень 2, Пространственно-временная согласованность (Spatiotemporal Consistency): Проверка «плавности» видео
Методы Уровня 2 ориентированы на концепцию «последовательной комбинации кадров видео в пространстве и времени» и сосредоточены на исследовательском вопросе: Удовлетворяет ли поток изображений видео в пространственно-временном измерении характеристикам, которым должны соответствовать процессы движения объектов в реальном видео. Реально снятое видео ограничено непрерывной траекторией камеры и реальными условиями окружающей среды, изменения между соседними кадрами в объектах и фоне будут демонстрировать непрерывные, предсказуемые пространственно-временные паттерны, соответствующие физической осуществимости и движению камеры. В то время как видео, сгенерированные ИИ, в длительных временных последовательностях могут проявлять пространственно-временные несоответствия, такие как искажение объектов, дрейф фона, внезапное размытие, аномалии в остаточном движении и т.д. Включая детекцию:
Временных и двигательных несоответствий, таких как деформация локальных объектов, дрейф фона, внезапное размытие, аномалии остаточного движения;
Динамики человеческого поведения и взаимодействия, такой как изменения выражения лица, динамика идентичности, ритм взаимодействия между персонажами в кадре;
Физических и частотных аномалий, связанных с временной частотой и непрерывностью изображения.
Уровень 3, Кросс-модальная согласованность (Cross-Modal Consistency): Внутренняя многомодальная проверка видео
Уровень 3 является ключевой точкой перелома во всей структуре: детекция начинает входить в область внутренней многомодальной проверки видео, сосредотачиваясь на исследовательском вопросе: Согласованы ли различные модальности в видео — изображение, звук, субтитры и т.д. — «на всех уровнях, повествуя об одном и том же содержании».
В реальном видео аудио, текст и изображение часто находятся в высокой степени согласованности. В то время как в видео, сгенерированных ИИ, могут существовать системные несоответствия между артикуляцией и речью, идентичностью и голосовым отпечатком, изображением и текстом. Методы третьего уровня проводят детальный многогранный анализ согласованности между модальностями. Включают три типа:
Детекция согласованности между звуком и изображением;
Введение субтитров, заголовков, транскриптов, описательных текстов с последующим семантическим согласованием «текст-видео»;
Обучение робастности для временной локализации межмодальных несоответствий.
Уровень 4, Языково-управляемое рассуждение на мировом уровне (Language-Guided World-Level Reasoning): Фокусировка на расхождениях между видео и реальным миром
Перспектива детекции Уровня 4 переходит от «внутренней согласованности видео» к «непротиворечивости с правилами и знаниями внешнего реального мира». Исследовательский вопрос меняется на: Может ли содержание видео в семантическом и фактическом измерениях действительно существовать в реальном мире, является ли оно правдоподобным.
Все содержание реального видео должно соответствовать фактам, физическим законам, предметным знаниям, здравому смыслу и т.д. реального мира. В то время как содержание видео, сгенерированных ИИ, часто трудно полностью согласовать с реальным миром, и именно это пространство использует четвертый уровень. Включает:
Использование промптов, текстовых априорных знаний, текстовых прототипов или легких модулей для перекалибровки пространства представлений модели, чтобы модель легче сопоставляла наблюдаемые аномалии с более четкими семантическими категориями;
Рассмотрение детекции как процесса проверки фактов, построение агента-исследователя, который умеет искать информацию, использовать инструменты, возвращаться и корректировать суждения, связывая выводы с доказательствами, выводами инструментов, процессом проверки и т.д.;
Через тонкую настройку, обучение с предпочтениями, моделирование вознаграждения и обучение с подкреплением, внедрение в саму модель «как выбирать доказательства, как организовывать объяснения, как делать выводы». Акцент на предоставлении четкого, структурно устойчивого вывода детекции с полной цепочкой доказательств.
Эволюционная карта стороны генерации и стороны детекции
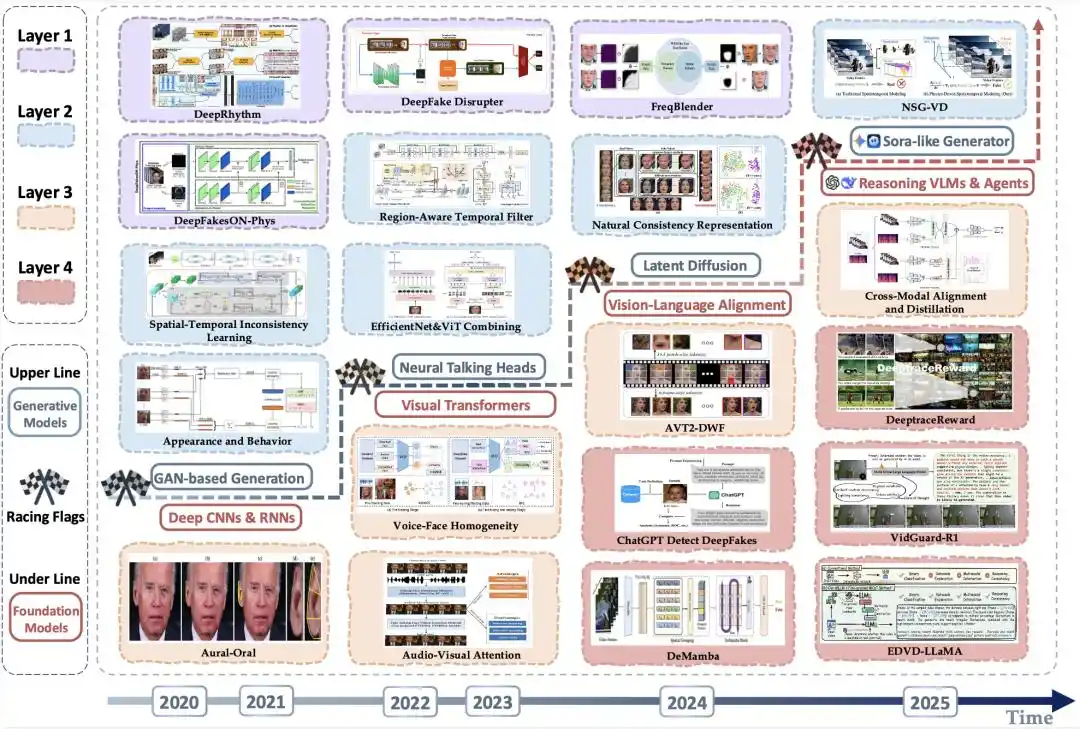
Рисунок 4 | Эволюционная карта репрезентативных методов детекции: одновременное продвижение угрозы со стороны генерации и улучшения со стороны детекции
На рисунке выше вдоль временной оси показано, как угроза со стороны генерации постоянно повышает «потолок» правдоподобия, которого могут достигать «фальшивые видео». На фоне эволюции базовых моделей, на которые опираются технологии детекции, — от глубоких сверточных и рекуррентных сетей к визуальным трансформерам, а затем к мультимодальным большим языковым моделям с возможностями рассуждения и системам агентов — показана эволюционная карта стороны детекции, переходящей от визуального анализа к многомодальной верификации и детекции на основе высокоуровневых рассуждений.
Обзор далее приводит временную статистику распределения методов детекции по уровням: в 2020 году доля методов уровня 3/4 составляла всего 7.7%, к 2023 году выросла до 40.0%, а в 2025 году превысила половину.
В целом, фокус методов детекции постоянно смещается вверх: изначально он был сосредоточен в основном на первом и втором уровнях, но по мере того, как генерируемые видео становятся все более гладкими и правдоподобными, детекция все больше переходит на третий и четвертый уровни.
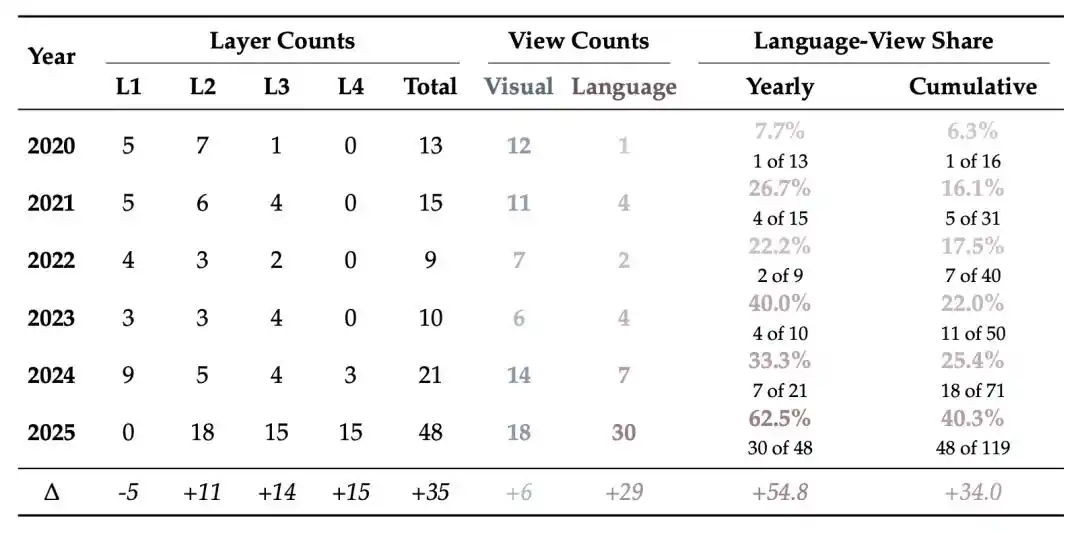
Рисунок 5 | Статистика изменения распределения методов детекции: доля языковой перспективы постепенно растет
Оценка методов детекции
Перед целью верификации фактической достоверности оценка методов детекции должна дать ответ: освоила ли модель переносимые визуальные подсказки, способна ли она распознавать пространственно-временные и кросс-модальные несоответствия, может ли она эффективно оценивать факты, знания и мировые ограничения. Обзор систематически описывает эволюцию метрик оценки и наборов данных от эры традиционного Deepfake до сегодняшнего дня.
Метрики оценки с двойной перспективой «Видео-Язык»
Общие метрики: Acc / AUC по-прежнему необходимы, но явно недостаточны
Acc, AUC, Precision, Recall, F1, EER, PR-AUC, а также методы агрегации на уровне кадра (frame-level) и видео (video-level) по-прежнему являются основным общим языком для сравнения различных методов, позволяя проводить горизонтальное сравнение методов разных уровней. Однако эти базовые метрики, оставаясь необходимыми, не могут соответствовать требованиям к объяснимости и достоверности оценки в рамках цели верификации фактической достоверности.
Метрики с визуальной перспективы: Оценка устойчивости в условиях реальных помех
Центр тяжести оценки заключается в том, остаются ли первоначальные подсказки детектора действенными при столкновении с изменениями распределения, сжатием при распространении и реальными помехами окружающей среды. Делятся на следующие два типа:
- Робастность низкоуровневых подсказок: включая TPR@FPR=α при фиксированном пороге, кросс-датасетное тестирование, стресс-тестирование с возмущениями и т.д.
- Пространственно-временная и физическая согласованность: акцент на отчетности на уровне видео (video-level reporting), падении производительности при временных возмущениях (temporal perturbation drop), исключении движения (motion ablation), а также на том, ухудшается ли модель значительно после удаления временной информации, чтобы оценить, действительно ли детектор анализирует непрерывность всего видео, а не продолжает полагаться на «ярлыки» в отдельных кадрах.
Метрики с языковой перспективы: Оценка многомодальной локализации и рассуждений
Область охвата путей детекции с языковой перспективы шире, и метрики оценки уже не могут быть сведены к простому набору классификационных показателей. Обзор предлагает следующую иерархию:
- Кросс-модальное согласование и временная локализация: Эти метрики оценки ориентированы на точность детекции в кросс-модальном согласовании и способность детектора локализовать подсказки в конкретные временные промежутки. Помимо базовых Acc и AUC, часто добавляются AP, AR, Recall@K, mAP@IoU и т.д.
- Мировые знания и рассуждения: При столкновении с более высокоуровневой проблемой «может ли событие, описываемое в видео, быть подтверждено здравым смыслом, физическими законами, внешними знаниями и конкретными доказательствами», метрики оценки детекции должны включать человеческие суждения (human judgments), попарные предпочтения (pairwise preferences), ответы на вопросы (question answering), а также такие метрики, как BLEU, ROUGE-L, METEOR, CIDEr, сходство на основе эмбеддингов (embedding-based similarity) для оценки качества объяснений.
Наборы данных: Переорганизация по трем парадигмам объектов детекции
Подавляющее большинство наборов данных, используемых для обучения и оценки методов детекции, естественным образом дифференцируются в соответствии с упомянутыми выше парадигмами видео, сгенерированных ИИ. Обзор систематизирует их следующим образом:
- Наборы данных для парадигмы LMV: Основной акцент оценки сосредоточен на стабильности визуальных подсказок методов детекции, а также на том, остаются ли эти подсказки действенными в условиях искажений, сжатия и распространения в разных доменах; такие наборы данных постоянно приближаются к реальным условиям, включая временные рассуждения и оценку объяснимости.
- Наборы данных для парадигмы AVE: Такие наборы данных часто делают больший акцент на детальной временной разметке, более четких кросс-модальных соответствиях, а также на более сильном моделировании локальных расхождений и семантических несоответствий. Они проверяют, может ли модель обнаружить, что аудио и видео не говорят об одном и том же, может ли она локализовать момент возникновения расхождения, способна ли различать проблемы синхронизации, идентичности и семантики.
- Наборы данных для парадигмы GVS: Полностью синтезированные видео, с одной стороны, постоянно ослабляют явные следы редактирования, а с другой — непрерывно бросают вызовы детекции, такие как разнообразие генераторов, семантическое несоответствие и риск переноса; соответствующие оценки меняются быстрее всего; от первоначального сбора большого количества полностью синтезированных видео для оценки точности детекции развитие пришло к таким работам, как LOKI, GenWorld, DAVID-X, DeeptraceReward, которые включают симуляцию мира, разметку на уровне дефектов, воспринимаемые человеком признаки подделки в систему оценки.
Связанные оценки для диагностики моделей генерации видео
Ресурсы, связанные с оценкой детекции, не ограничиваются наборами данных, предназначенными непосредственно для детекции. Фактически, в исследованиях, связанных с компьютерным зрением и мировыми моделями, многие диагностические оценки качества генерации моделей создания видео, а также оценки способности моделей понимания видео обнаруживать ошибки также могут служить важным ориентиром для детекции. Обзор систематизирует эти диагностические оценочные работы, которые могут служить дополнительным ресурсом, в соответствии с постепенно продвигающейся цепочкой оценки:
- Сначала проверяется, соответствуют ли объекты, атрибуты, взаимодействия и изменения состояний в видео основным физическим законам;
- Затем рассматриваются мировая динамика и причинно-следственные связи, то есть могут ли локальные законы распространяться на все видео, формируя непрерывный, связный процесс событий, соответствующий мировым знаниям;
- Наконец, проверяется, могут ли системы, такие как модели понимания видео, преобразовать ошибки различного уровня в сгенерированных видео в четкие, понятные, поддающиеся проверке суждения.
От «способности различать» к «способности доказывать»
Высококачественные видео, сгенерированные ИИ, постоянно повышают планку правдоподобия поддельного контента. Задача, с которой сталкивается детекция, все сложнее свести к простой оценке правда/ложь, требуется проверка фактической достоверности; соответственно, этап оценки и сама система детекции также должны расширяться вместе с расширенными границами задачи:
Динамическая система оценки, ориентированная на доказательства
Столкнувшись с новыми сложными видео, сгенерированными ИИ, с большой продолжительностью, оценка должна отвечать не только на вопрос «умеет ли модель классифицировать», но и «на какие именно подсказки модель опиралась для правильного или ошибочного суждения». Грубая разметка данных в оценке скрывает много действительно ключевой информации, разметка данных, обучение моделей и отчетность о результатах также должны двигаться вперед. Необходимо снова разбить видео на проверяемые пропозициональные единицы, преобразовать «длинные временные повествования» в операционные структурированные объекты, такие как цепочки событий, траектории состояний сущностей или графы событий, чтобы проводить причинно-следственную и ограничительную проверку в длительных временных масштабах, тем самым далее задаваясь вопросом, «какую именно пропозицию уловила детекция» и «соответствуют ли доказательства и суждения друг другу».
Кроме того, большинство детекторов все еще оцениваются в условиях «закрытого мира»: в реальных сценариях развертывания постоянно появляются новые модели генерации видео, инструменты редактирования и стили контента, разные платформы вводят свои процессы понижающей дискретизации, транскодирования и фильтрации. Чтобы устранить этот долгосрочный пробел в робастности, необходимо позаимствовать механизмы непрерывного обновления по типу arena/leaderboard, включая вновь выпускаемые генераторы и новые цепочки транскодирования платформ в наборы для оценки потоковым образом.
Достоверная, объяснимая система детекции, сочетающая двойную перспективу
Для достижения объяснимой детекции фактической достоверности, упомянутой выше, необходимо сочетать два пути — восприятие и познание, объединяя способность визуальной перспективы выявлять визуальные артефакты и пространственно-временные несоответствия со способностью высокоуровневой языковой перспективы к структурированным рассуждениям, тем самым打通 четырехуровневую картину методов с двойной перспективой. С одной стороны, текущие визуально-языковые модели и модели понимания видео имеют относительно слабые способности к дискриминации, связанные с «перцептивной достоверностью», и нуждаются в дополнении методами визуальной перспективы. С другой стороны, для видео, сгенерированных более мощными моделями и средствами противодействия детекции, обладающих высокой перцептивной достоверностью, необходима детекция на семантическом и фактическом уровне с языковой перспективы.
Далее, создание явного пути рассуждений «распознавание — локализация — объяснение». Это означает, что в вышеупомянутой системе с двумя путями каждый вызов инструмента или ссылка на знание должны быть строго привязаны к конкретному этапу аргументации.
Кроме того, вышеупомянутая система детекции, построенная на «стороне контента», должна перекрестно проверяться с возможными сигналами аутентификации «на стороне источника» и т.д., связывая анализ содержания с отслеживанием происхождения. В конечном итоге формируется межуровневая, многомодальная система детекции, а также достоверное, объяснимое пространство доказательств.
Заключение
Детекция видео ИИ — это задача, которая будет становиться только сложнее.
Для будущих исследований и практического применения детекции AIGC-V данный обзор предоставляет более приближенную к реальным потребностям развертывания карту, заново определяет задачу детекции видео, сгенерированных ИИ, предлагает четырехуровневую структуру с двойной перспективой «Видео-Язык», и на этой основе систематизирует существующие методы, соответствующие бенчмарки и метрики оценки, одновременно связывая эти уровни с вызовами реального развертывания, пробелами в существующих оценках и появляющимися направлениями развития.
В рамках этой структуры указываются несколько ключевых требований, которым должна соответствовать достоверная детекция, включая приоритет доказательств, прослеживаемость выводов, а также устойчивость в условиях разнообразия генераторов и реальных сценариев.
В будущем достоверная детекция видео ИИ вряд ли сможет быть выполнена какой-либо отдельной областью самостоятельно, она становится междисциплинарной проблемой, с которой сталкиваются исследования в области компьютерного зрения, обработки естественного языка, многомодального понимания и мировых моделей: компьютерное зрение обеспечивает моделирование пространственно-временных доказательств и устойчивость анализа, обработка естественного языка — способность декомпозиции утверждений, рассуждений, обоснования доказательств и объяснений, исследования в области многомодальности и мировых моделей предоставляют более сильные возможности кросс-модального согласования и более богатые априорные знания о физике, причинности и временной согласованности.
Только объединив эти способности, детекция видео сможет постепенно выйти за рамки поиска локальных артефактов и перейти к более строгой «концепции реальности»: вопрос уже не только в том, выглядит ли видео правдоподобно, а в том, являются ли сущности, события и динамические процессы в нем всегда верными ограничениям реального мира, в поиске все более размывающейся границы между виртуальным миром и реальным миром.
Источники: https://www.researchgate.net/doi/10.13140/RG.2.2.31713.88168
Эта статья из WeChat официального аккаунта «Новые интеллектуальные элементы» («新智元»), редактор: LRST