От редактора: Когда многие люди используют Claude Code, самое непосредственное впечатление — токены расходуются слишком быстро, длинные сессии легко "съедают" лимит. Но с точки зрения инженеров Anthropic, реальное влияние на стоимость оказывает не то, сколько кода вы написали, а то, насколько система постоянно повторно использует уже обработанный контекст.
Основная идея, которой делится эта статья, — как экономить токены с помощью механизма кэширования. Автор за неделю сэкономил более 300 миллионов токенов благодаря кэшированию, достигнув 91 миллиона в один день. Поскольку стоимость кэшированного токена составляет всего 10% от стоимости обычного входного токена, это означает, что 91 миллион кэшированных токенов фактически стоят примерно как 9 миллионов обычных токенов. Причина, по которой длинные сессии Claude Code кажутся более "выносливыми", не в том, что модель работает бесплатно, а в том, что большое количество повторяющегося контекста успешно переиспользуется.
Ключ к кэшированию промптов (prompt caching) — "не прерывать кэш". Claude Code кэширует системные подсказки, определения инструментов, CLAUDE.md, правила проекта и историю диалогов послойно; до тех пор, пока префикс последующих запросов остаётся неизменным, Claude может напрямую читать из кэша, а не обрабатывать весь контекст заново. Внутри Anthropic также отслеживают показатель повторного использования кэша промптов, поскольку это влияет не только на лимиты пользователей, но и напрямую на стоимость обслуживания модели и эффективность работы.
Обычным пользователям не нужно понимать все технические детали, достаточно усвоить несколько ключевых привычек: не оставлять сессию бездействующей более 1 часа; правильно выполнять "передачу сессии" (session handoff) при смене задачи; избегать частой смены моделей; большие документы по возможности помещать в Projects, а не постоянно вставлять их в диалог.
Эта статья — скорее не просто рассказ о технике экономии токенов, а предложение подхода к использованию Claude Code, более близкого к мышлению инженера: рассматривать контекст как актив, который нужно управлять, чтобы кэш постоянно переиспользовался, а длинные сессии выполняли меньше повторяющихся вычислений.
Ниже оригинальный текст:
На этой неделе я сэкономил 300 миллионов токенов, 91 миллион за день, за неделю — более 300 миллионов.
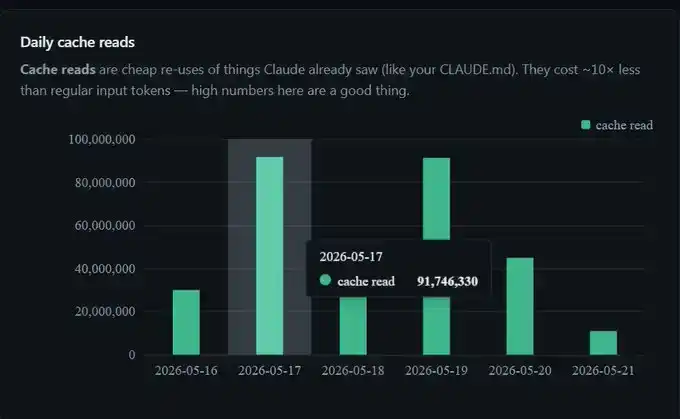
Я не менял никаких настроек. Это просто обычная работа промпт-кэширования в фоновом режиме.
Но когда я действительно понял, что такое кэш и как избежать его "сброса", при том же самом лимите использования мои сессии стали длиться дольше. Итак, вот краткое руководство 80/20 по промпт-кэшированию в Claude Code, без глубоких технических деталей уровня API.
TL;DR
Стоимость кэшированного токена составляет всего 10% от стоимости обычного входного токена. 91 миллион кэшированных токенов фактически стоят примерно как 9 миллионов токенов.
TTL (время жизни) кэша для подписочной версии Claude Code — 1 час; для API по умолчанию — 5 минут; для Sub-agent — всегда 5 минут.
Кэш делится на три уровня: системный, проектный, уровень диалога.
Смена модели в середине сессии сбрасывает кэш, включая включение режима "opus plan".
Как именно считается стоимость кэша?
Каждый кэшированный токен стоит 10% от стоимости обычного входного токена.

Поэтому, когда на моей панели управления видно, что за день 91 миллион токенов попал в кэш, фактическая оплата примерно эквивалентна обработке 9 миллионов токенов. Вот почему по сравнению с отсутствием кэширования при длительном использовании Claude Code кажется, что сессии почти "бесплатно" продлеваются.
На панели управления стоит обратить внимание на две цифры:
Cache create: Разовые затраты при записи контента в кэш. Они начнут приносить пользу в следующем раунде диалога.
Cache read: Токены, которые Claude повторно использует из кэша, например, ваш CLAUDE.md, определения инструментов, предыдущие сообщения и т.д. По сравнению с повторной обработкой как ввода, они дешевле в 10 раз.

Если у вас высокий показатель Cache read, значит, вы эффективно используете кэш; если этот показатель низкий, значит, вы платите за один и тот же контекст снова и снова.
У Тарика из Anthropic есть фраза, которая меня глубоко впечатлила: "Мы фактически отслеживаем процент попаданий в промпт-кэш (cache hit rate), и как только он становится слишком низким, срабатывает сигнал тревоги, даже объявляется инцидент уровня SEV."
Он также написал хорошую статью в X. Когда процент попаданий в кэш высок, происходят четыре вещи одновременно: Claude Code ощущается быстрее, стоимость обслуживания Anthropic снижается, ваша подписка кажется более "выносливой", а длинные сессии кодирования становятся более реальными.
Но если процент попаданий низкий, проигрывают все.

Таким образом, стимулы обеих сторон на самом деле совпадают: Anthropic хочет, чтобы у вас был высокий процент попаданий в кэш, и вы сами тоже этого хотите. То, что действительно мешает, — это некоторые, казалось бы, незначительные привычки, которые незаметно сбрасывают кэш.
Как кэш увеличивается в каждом раунде диалога?
Кэширование зависит от префиксного совпадения (prefix matching).
Не нужно погружаться в глубокие технические детали, просто поймите одну вещь: если всё, что было до определённой позиции, полностью совпадает с уже закэшированным содержимым, Claude может повторно использовать эти закэшированные токены.
Новая сессия обычно разворачивается примерно так:
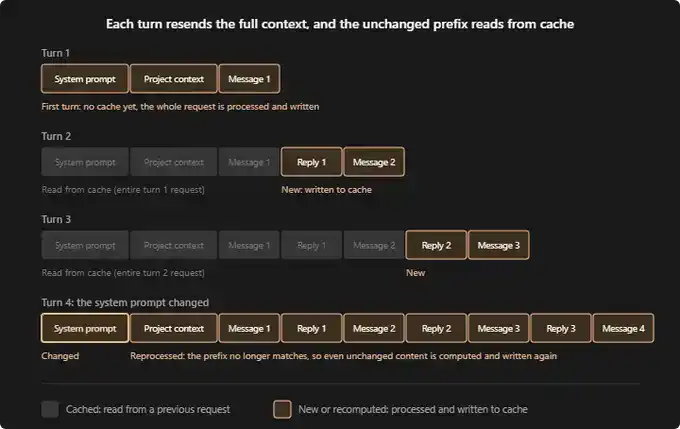
Согласно документации Claude Code, новая сессия обычно работает так:
Первый раунд диалога: Кэша ещё нет. Системные промпты, контекст вашего проекта (например, CLAUDE.md, memory, правила), а также ваше первое сообщение обрабатываются заново и записываются в кэш.
Второй раунд диалога: Весь контент из первого раунда теперь закэширован. Claude нужно обработать только ваш новый ответ и следующее сообщение. Стоимость этого раунда будет намного ниже.
Третий раунд диалога: Логика та же. Предыдущий диалог по-прежнему хранится в кэше, только последний раунд взаимодействия нужно обработать заново.
Сам кэш можно разделить на три уровня:

Из статьи Тарика в X:
Системный уровень (System layer): Включает базовые инструкции, определения инструментов (read, write, bash, grep, glob) и стиль вывода. Этот уровень кэшируется глобально.
Проектный уровень (Project layer): Включает CLAUDE.md, memory, правила проекта. Этот уровень кэшируется по проектам.
Уровень диалога (Conversation): Включает ответы и сообщения, растёт с каждым раундом диалога.
Если в середине сессии что-либо на системном или проектном уровне изменяется, весь контент должен быть заново закэширован с самого начала. Это самая "дорогая" операция. Представьте: вы уже дошли до 16-го сообщения, и вдруг меняете системный промпт, или делаете перерыв на час, тогда все токены, начиная с первого сообщения, должны быть обработаны заново.
Путаница с 1 часом и 5 минутами
Это место, где легче всего запутаться.
Подписочная версия Claude Code: TTL по умолчанию — 1 час.
Claude API: TTL по умолчанию — 5 минут. Вы можете повысить его до 1 часа, но за более высокую стоимость.
Sub-agent на любом тарифе: Всегда 5 минут.
Веб-чат Claude.ai: Официально не задокументировано. Возможно, как и в подписочной версии, но я не проверял.
Несколько месяцев назад многие жаловались, что лимиты подписки Claude расходуются слишком быстро. Тогда некоторые думали, что Anthropic тихо снизила TTL с 1 часа до 5 минут без уведомления пользователей. Но это не так, TTL Claude Code по-прежнему составляет 1 час.
Проблема в том, что документация Claude Code и API размещена отдельно, а это две совершенно разные вещи, что вызвало немало путаницы.
Если вы активно используете рабочие процессы с Sub-agent или напрямую используете API, то цифра в 5 минут важна. Но для 95% пользователей Claude Code реально важно учитывать только это окно в 1 час.
Три привычки, покрывающие 95% пользователей
Вот то, что я считаю по-настоящему полезным в повседневном использовании.
Не делайте слишком долгих перерывов
Если вы бездействовали более часа, предыдущий контент в основном уже "протух" в кэше. Ваше следующее сообщение будет заново строить кэш. В этом случае вместо того, чтобы возобновлять уже "остывшую" старую сессию, часто дешевле сделать чёткую передачу (handoff) и начать новую сессию.
При смене задачи — просто начните заново
/compact или /clear сами по себе сбрасывают кэш, так что лучше использовать этот момент для полного сброса.
Я сделал себе навык "session handoff skill" (навык передачи сессии) вместо /compact. Он подводит итог тому, что мы завершили, какие решения ещё в ожидании, какие файлы самые важные и с чего следует продолжить. Затем я выполняю /clear, вставляю это резюме и могу продолжать так, будто ничего не прерывалось.
Команда compact иногда тоже работает медленно. А этот handoff skill обычно выполняется меньше чем за минуту.
В чате Claude большие документы по возможности помещайте в Projects
Механизм кэширования на Claude.ai официально не очень подробно описан, но очевидно, что Projects и обычные потоки диалога используют разные методы оптимизации. Поэтому, если вам нужно вставить большой документ, лучше поместите его в Project, а не напрямую в диалог.
Какие действия незаметно сбрасывают кэш?
Есть несколько вещей, которые полностью сбрасывают кэш без явного предупреждения.
Смена модели: Поскольку кэширование зависит от префиксного совпадения, а у каждой модели свой собственный кэш. Как только вы меняете модель, следующий запрос будет обрабатывать полную историю без каких-либо попаданий в кэш.
Режим "Opus plan": Эта настройка использует Opus на этапе планирования, а Sonnet — на этапе выполнения. Я рекомендовал её в некоторых видео по оптимизации токенов не просто так. Но важно понимать, что каждое переключение плана по сути является сменой модели, а значит, требует перестройки кэша. В долгосрочной перспективе это всё равно помогает продлить сессии, но вам нужно знать, что происходит на самом деле.
Редактирование CLAUDE.md в середине сессии возможно: Это изменение не вступит в силу немедленно, а будет применено при следующем перезапуске. Таким образом, текущий кэш не пострадает.
Моя панель управления "бесплатными" токенами
Скриншоты, которые я показывал ранее, взяты из токен-панели управления.
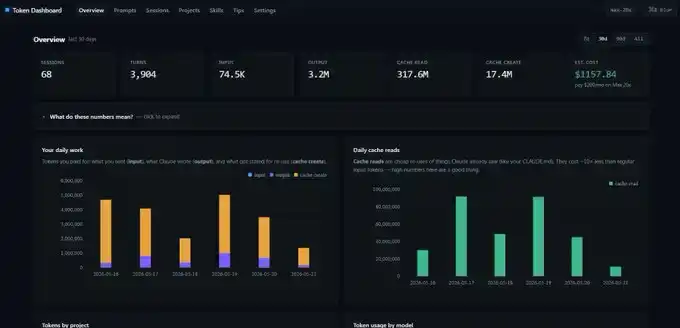
Это простой репозиторий на GitHub. Вы даёте ссылку Claude Code, чтобы он развернул его локально на localhost, и он будет читать все ваши прошлые записи сессий, а не начинать статистику с нуля. Сразу же вы увидите ежедневные данные по input, output, cache create и cache read.
Но есть один нюанс: эта панель управления считает данные по токенам на локальном устройстве. Если вы переключитесь с настольного ПК на ноутбук, цифры не будут полностью совпадать. У каждого устройства свой собственный набор статистики.
Итог
Промпт-кэширование — это тема, в которую можно глубоко погрузиться. В статье Тарика всё описано полнее, чем здесь, если хотите увидеть полную картину, стоит почитать.
Но вам не нужно полностью понимать все детали, чтобы извлечь выгоду. Достаточно усвоить ключевые 80/20: кэшированные токены в 10 раз дешевле обычных; TTL Claude Code — 1 час; смена модели сбрасывает кэш; чёткая передача между задачами обычно выгоднее, чем продолжение использования старой сессии после её "протухания".