«Deep Think превзошел/сравнялся с конкурентами во всех соревнованиях»!
Только что старший исследователь Google DeepMind Conglong Li на платформе X опубликовал 12 постов, представив беспрецедентный отчет об успехах.

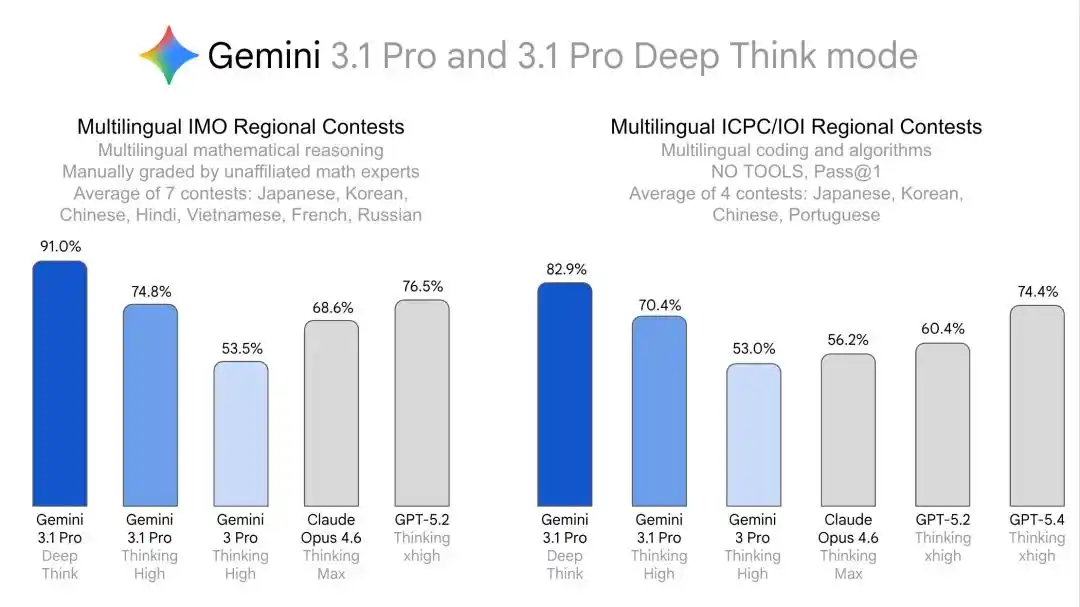
Один ИИ, один и тот же «мозг», восемь экзаменов на разных языках, все сданы на высокие баллы.
Для любой модели такие результаты являются исключительными.
От золотой медали IMO до полного охвата региональных олимпиад
Этот успех Deep Think в достижении высоких результатов в различных рейтингах — не внезапная единичная вспышка, а кривая развития способностей, которая формировалась почти год.
Сначала — покорение самого сложного поля логических рассуждений.
В июле 2025 года Gemini Deep Think впервые достиг уровня золотой медали на Международной математической олимпиаде (IMO), набрав 35 баллов из 42. В то же время показал аналогично высокий уровень на финале мирового чемпионата ICPC.
Эти два достижения уже официально опубликованы в блоге DeepMind.
Google DeepMind затем внес эти результаты в официальный блог, обозначив их как знак того, что Deep Think преодолел «порог мировых соревнований» в математике и программировании.
Затем Deep Think начал переход от «чемпионского прорыва в отдельных дисциплинах» к «системной проверке на кросс-языковых, междисциплинарных и разнообразных сценариях».
В феврале 2026 года Google опубликовал три статьи в блоге.
Одна представила саму модель Gemini 3.1 Pro, другая — крупное обновление специального режима рассуждений Deep Think, третья — от команды научных открытий DeepMind, которая напрямую позиционирует Deep Think как «мультипликатор человеческого интеллекта».
Обновленный Deep Think представил ряд жестких показателей:
Humanity's Last Exam — 48.4% (без инструментальной помощи), ARC-AGI-2 — 84.6% (официальная проверка фонда ARC Prize), рейтинг Elo в соревновательном программировании Codeforces — 3455, письменные части Международной физической олимпиады 2025 и Международной химической олимпиады — на уровне золотой медали.
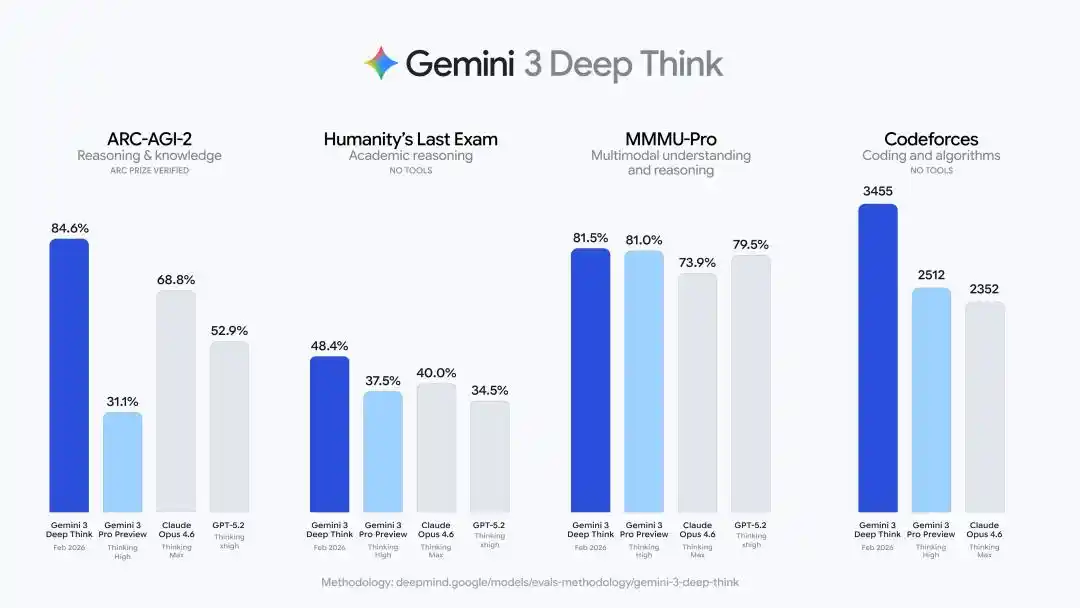
Эта траектория очень четкая: сначала использовать мировые соревнования, такие как IMO и ICPC, чтобы доказать свои мощные способности к рассуждению, а затем использовать результаты многоязыковых, региональных и междисциплинарных олимпиад, чтобы доказать свою универсальную способность к глубоким рассуждениям со стабильным переносом между языками и областями.
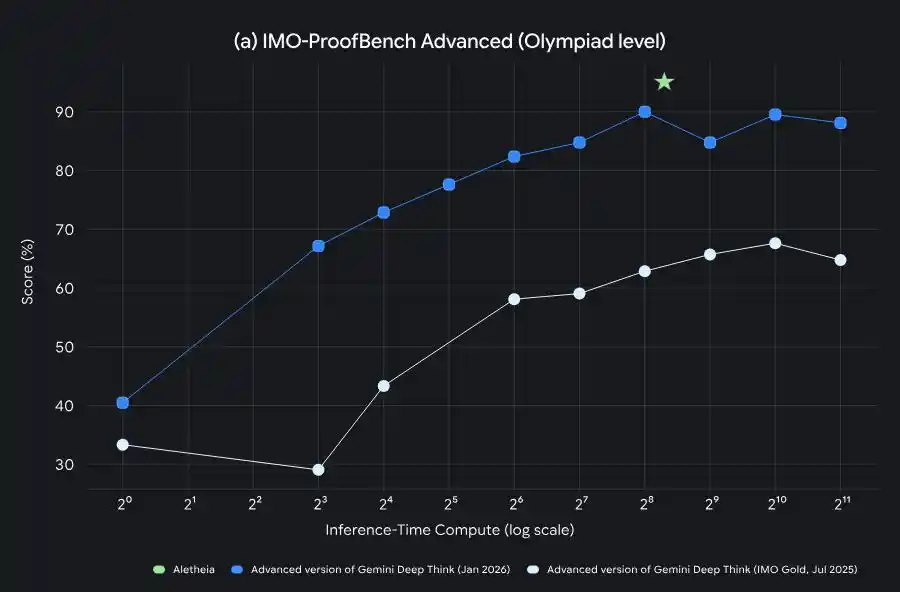
Эволюция способностей Gemini Deep Think от золотой медали IMO до ускорения научных исследований уровня PhD
Детальный разбор табеля успеваемости на 8 языках
Теперь давайте подробно рассмотрим этот табель.
Японский язык наиболее яркий.
35-я Японская математическая олимпиада (JMO Finals) 2025 года — идеальный результат.
Азиатский предварительный этап ICPC в Японии — идеальный результат.
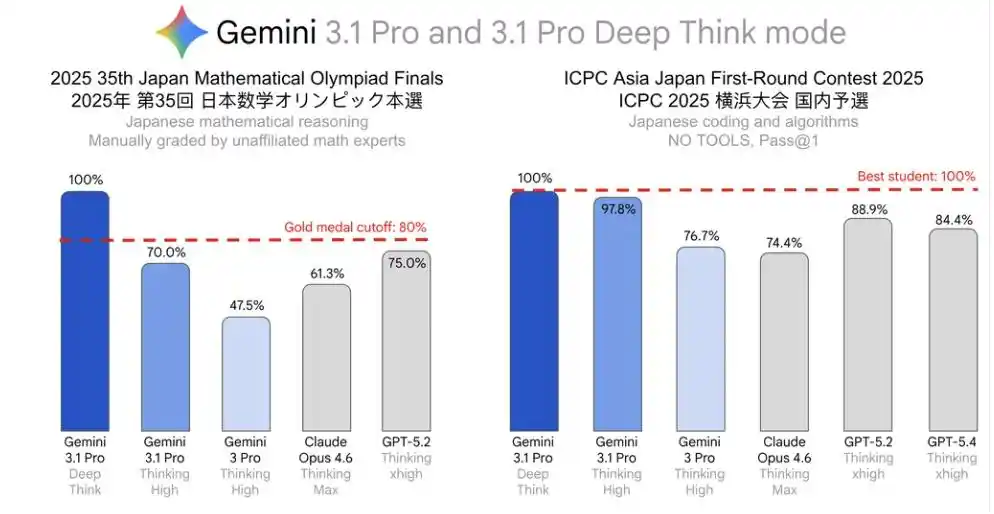
При этом результат JMO Finals даже превысил уровень 80% от наивысшего балла в том году, достигнув стандарта, официально называют «эквивалентным золотой медали».
Французский язык также на 100%.
С китайским интереснее.
На 41-й Китайской математической олимпиаде (CMO) Deep Think набрал 86.3%, что очень впечатляюще. Но на Китайской олимпиаде по информатике (NOI) — только 63.3%.
Разрыв между 86.3% и 63.3% очерчивает реальные границы способности ИИ к рассуждению.
В математических олимпиадах модель сталкивается с абстрактными выводами, построением доказательств и многошаговыми умозаключениями, что как раз является сильной стороной Deep Think.
Но в олимпиадах по информатике проблема заключается не только в том, чтобы «понять», но и в переводе логики в исполняемый код, контроле граничных условий, учете ограничений сложности и избежании ошибок на уровне реализации.
Первое ближе к чистым рассуждениям, второе требует одновременного прохождения «рассуждений + проектирования алгоритмов + инженерной реализации».
В результатах олимпиад на других языках — корейском, хинди, вьетнамском, русском, португальском — Deep Think также превзошел конкурентов или, по крайней мере, сравнялся с ними.
Если снова объединить японский, французский и китайский, то最不обычным в этот раз является не то, что какая-то одна дисциплина была сдана на идеальный балл, а то, что одна и та же модель, одна и та же система рассуждений Deep Think, на экзаменационных работах на multiple языках показала результаты уровня первого эшелона.
Насколько надежен этот табель?
Но здесь есть ключевой пробел:
Conglong Li не привел конкретных сравнительных данных конкурентов: все результаты получены из внутреннего тестирования Google. Нет независимого повторения третьей стороной, нет официального подтверждения организаторами олимпиад, методы оценки полностью не раскрыты.
Каждая задача решалась один раз или много раз с выбором лучшего результата? Сколько вычислительных ресурсов было использовано при рассуждении? Было ли вмешательство ручного prompt-инжиниринга?
Эти детали, напрямую влияющие на ценность результатов, также не упомянуты.
Еще один момент, который легко пренебречь: все эти экзамены являются региональными отборочными турами, а не международными финалами.
Между сложностью задач региональных этапов и международных финалов — разница в orders величины.
Исследователь четко сказал, что эти результаты «будут включены в model card», но на момент публикации model card еще не обновлена.
Таким образом, пока это все еще похоже на табель, который ученик сам оценил, сам опубликовал и еще не передал в учебную часть для заверения печатью.
Многоязыковая справедливость в науке — забытое настоящее поле битвы
Почему Google专门 потратил силы на оценку региональных олимпиад на 8 языках?
Текущая оценка способностей ИИ к рассуждению почти полностью основана на английском языке.
MATH, GSM8K, HumanEval, ARC-AGI... все это на английском.
Всем математикам, физикам, инженерам мира, чей родной язык не английский, при использовании научных инструментов ИИ приходится сначала преодолевать языковой барьер.
Google выбрал эти 8 языков не случайно.
Японский, корейский, китайский покрывают важные научные центры Восточной Азии, хинди, вьетнамский — emerging рынки, французский, русский, португальский — Европу и Южную Америку.
Вместе это — большая часть глобального научного производства.
DeepMind в официальном блоге позиционирует Deep Think как «мультипликатор человеческого интеллекта», заявляя, что он может «обрабатывать поиск знаний и строгую проверку, позволяя ученым сосредоточиться на концептуальной глубине и творческом направлении».
В сочетании с этими многоязыковыми результатами, подтекст этих слов понять нетрудно: этот мультипликатор предназначен не только для ученых, говорящих на английском.
Более примечательно то, как далеко Deep Think уже продвинулся в научном применении.
DeepMind представила интеллектуального агента для математических исследований под названием Aletheia, работающего на основе Deep Think, который может автономно генерировать, проверять и修订ить решения исследовательских математических проблем.
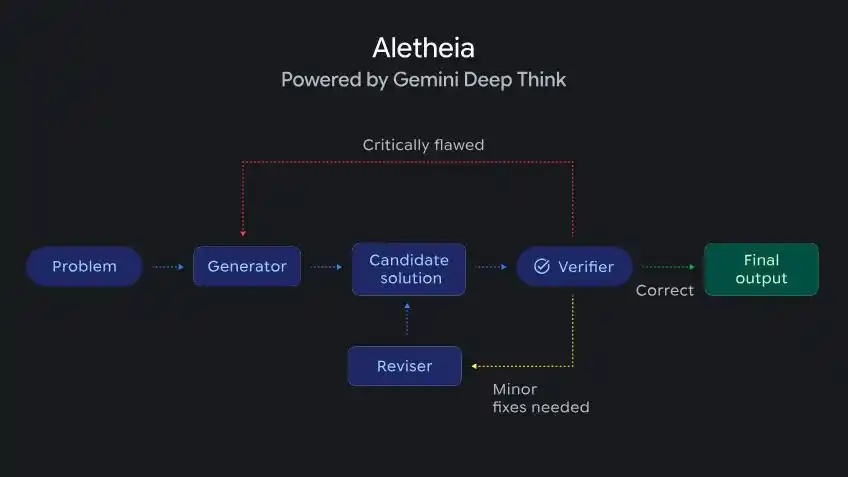
Aletheia, управляемый Deep Think, способен к итеративному生成, проверке и исправлению исследовательских математических проблем
Aletheia уже参与 создании нескольких исследовательских статей, одна из которых полностью выполнена ИИ самостоятельно, вычислив specific структурные константы в арифметической геометрии.

Кроме того, в полуавтономной оценке 700 открытых математических проблем он独立 решил 4 ранее нерешенные проблемы.
Режим Gemini Deep Think также показал огромный потенциал в области компьютерных наук, физики, экономики и других областях.
В области компьютерных наук Deep Think помог опровергнуть гипотезу, остававшуюся нерешенной в течение десяти лет, в области физики нашел новое аналитическое решение для гравитационного излучения космических струн, в области экономики расширил теорему теории аукционов.
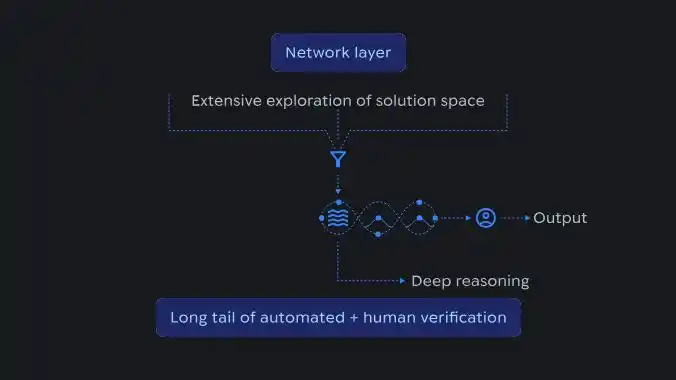
Схема процесса рассуждений ИИ, показывающая, как крупномасштабное исследование пространства решений на сетевом уровне агрегируется в структурированные рассуждения и подтверждается с помощью автоматизированной и ручной проверки.
Совместно с экспертами, решая 18 исследовательских难题, расширенная версия Gemini Deep Think помогла突破 long-standing bottlenecks в областях алгоритмов, машинного обучения и комбинаторной оптимизации, теории информации以及 экономики.
Это уже далеко выходит за рамки «решения олимпиадных задач».
Пока конкуренты соревнуются в рейтингах английских benchmark'ов, Google уже нашел новое поле битвы в области «ускорителей научных исследований с ИИ».
Самое важное в этом деле — не баллы,真正的 сигнал behind it заключается в том, что языковые барьеры инструментов ИИ для науки решаются как инженерная проблема.
Если этот путь будет пройден, ученые всего мира, ведущие исследования на японском, корейском, китайском, хинди, впервые окажутся на одной стартовой линии с носителями английского языка.
На этот раз Google уже выложил карты на стол.
Что касается того, кто из конкурентов сделает ответный ход,相信 мы скоро это увидим.
Источники:
https://blog.google/intl/ja-jp/company-news/technology/gemini-31-pro-gemini-31-pro-deep-think/%20
https://deepmind.google/blog/accelerating-mathematical-and-scientific-discovery-with-gemini-deep-think/%20
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/%20
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-deep-think/
Статья из WeChat Official Account «新智元» (XinZhiYuan), автор: 新智元