【Введение】Мировая позиция упала с 2-го до 10-го места, самая сильная модель Claude подверглась разоблачению за «снижение интеллекта», BridgeBench предоставил железные доказательства! Но Anthropic это не волнует?
Anthropic кончен?
Недавно директор по AI в AMD подтвердил снижение интеллекта Claude Code, прямо заявив: «Уже непригоден для сложных задач».
Теперь новый отчёт оценки BridgeBench нанёс Anthropic ещё один сокрушительный удар!
Данные шокируют: глобальный рейтинг Claude Opus 4.6 резко упал со 2-го на 10-е место:
Точность катастрофически снизилась с 83,3% до 68,3%, уровень галлюцинаций почти удвоился, увеличившись на 98%.
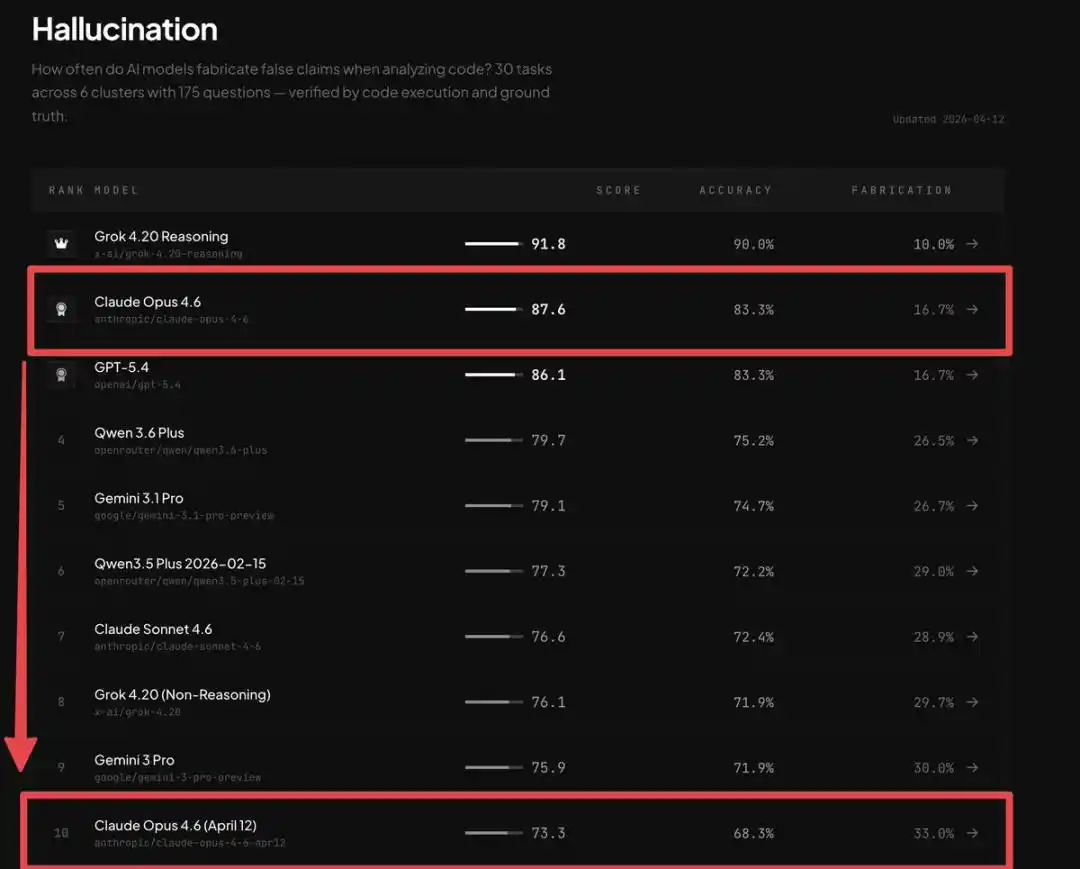
В тот момент, когда Claude стал глупеть, а пользовательский опыт ухудшился, холодные цифры положили конец всем сомнениям пользователей —
Проблема не в них, Claude Opus 4.6 действительно стал хуже!
Пользователи Claude чувствуют себя обманутыми!
Представьте, если вы полагаетесь на эту модель для выполнения любых критических задач, а они могут без вашего ведома просто заменить её на гораздо худшую.
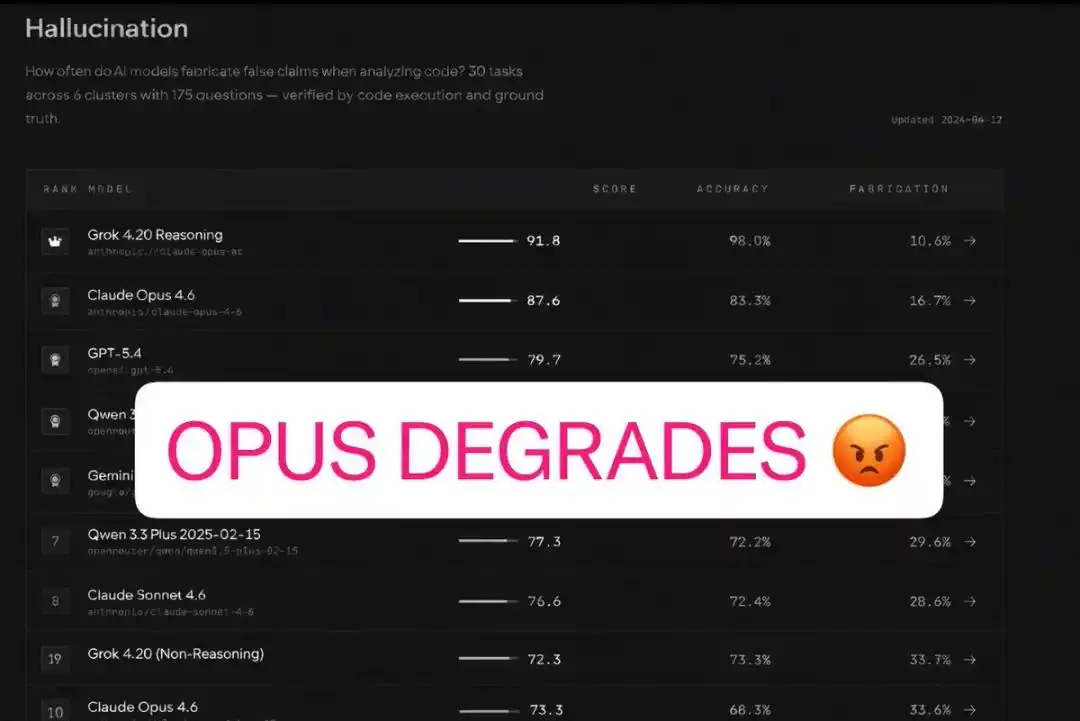
Но пользователи спрашивают: «Как это вообще законно?». Доверие начинает рушиться, насмешки над Anthropic заполонили сеть, даже самые верные сторонники начали сомневаться.
Но пока все смеются, у Anthropic вышел королевский ход — просочился скриншот, предположительно внутреннего интерфейса инструмента.
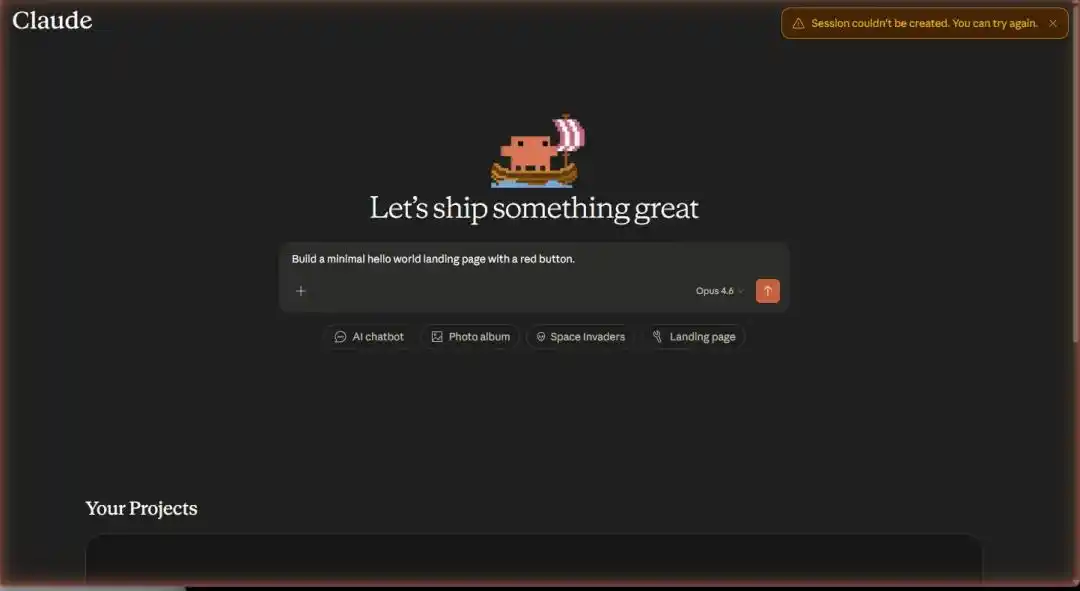
То, что показано на изображении, мгновенно сделало все дискуссии о «глупости Claude» неактуальными — Claude Projects тестирует полноценную систему для создания full-stack приложений.
Не помогает писать код, а помогает создавать продукты.
Пока все спорили о баллах моделей, Anthropic уже сменила игровой стол.
Что скрывается в утекшем изображении?
Сначала о том, что же засняли на том скриншоте.
Согласно перекрёстной проверке из множества источников, утекшее изображение демонстрирует «комплект для разработки в один клик», который в настоящее время тестируется внутри Claude Projects.
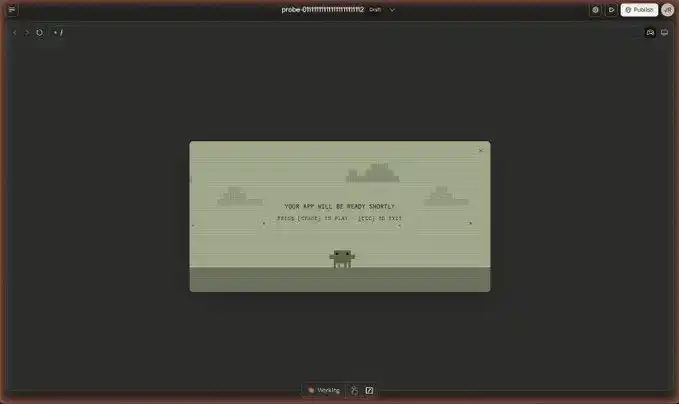
В интерфейсе чётко перечислен ряд предустановленных шаблонов: AI-чат-боты, интерактивные мини-игры, коммерческие лендинги, SaaS-дашборды для данных... Почти покрывая самые частые сценарии потребностей независимых разработчиков.
Но шаблоны — это только поверхность.
То, что действительно заставляет ахнуть, — это цепочка full-stack возможностей behind the templates —
Аутентификация? Отметил — настроил.
База данных? Выбрал тип — создал.
Фронтенд-интерфейс? Описал — сгенерировал.
Деплой в продакшен? Одно нажатие.
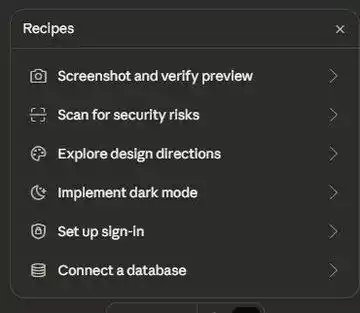
Это не «AI-辅助 программирование». Это «AI-замена программированию», и даже не нужно дистиллировать ваш Skill.
Чтобы понять вес этих слов, нужно看清 текущее слоистое положение дел с инструментами AI-программирования.
- Логика Cursor — «заставить вас писать быстрее в IDE» — он оптимизирует скорость кодинга, программист остаётся главным героем.
- Логика Replit — «дать возможность писать код тем, кто не умеет» — он снижает порог входа, но вам всё ещё нужно понимать логику кода.
- Логика Vercel — «сделать деплой незаметным» — он решает последний километр, но前面的路 вам нужно пройти самим.
Каждый из них занял свой сегмент в цепочке разработки ПО, каждый довёл его до предела.
Но то, что пытается сделать Claude, находится в совершенно другом измерении.
Cursor делает программистов в 10 раз быстрее, Replit позволяет не-программистам писать код — но Claude хочет сделать сам акт «писания кода» излишним.
Первое — это революция эффективности, второе — уничтожение категории.
Согласно утекшей информации, движком, лежащим в основе работы этой системы, является именно Opus 4.6 — та самая модель, над которой смеялась вся сеть.
Mythos «недостаточно силён» — возможно, намеренно?
Самое核心ное и спорное предположение, возможно, заключается в следующем —
Anthropic, возможно, вообще не волнует, на каком месте Mythos находится в рейтинге.
Звучит как поиск оправданий для неудачника? Давайте посчитаем.
Когда ваша стратегическая конечная цель — стать «full-stack application platform», роль модельного слоя fundamentally меняется.
Ему больше не нужно быть «самым умным», ему只需要 быть «достаточным».
Ключ к победе в платформенной конкуренции никогда не заключается в мощности底层 движка, а в том, насколько глубока привязка верхнеуровневой экосистемы.
Windows победила Mac не потому, что её ОС была элегантнее, а потому, что её программная экосистема была богаче. Android раздавил Windows Phone не потому, что его ядро было продвинутее, а потому, что разработчиков было больше.
В платформенных войнах «лучший» никогда не был причиной победы, «самый используемый» — был.
На публике Дарио Амодеи неоднократно повторял одну фразу: «Кодирование умрёт.»
Но утечка full-stack конструктора впервые дала这句话 вещественное доказательство на уровне продукта.
Дарио говорил не пророчество. Он говорил о дорожной карте, которая выполняется.
Если это рассуждение верно, то то, что Mythos лидирует на HLE против GPT-5.4 Pro (без инструментов 56.8 vs 42.7), но сравнялся на GPQA (94.4 vs 94.5) и был обойдён на BrowseComp (89.3 vs 86.9) — значение этих данных становится совершенно иным.
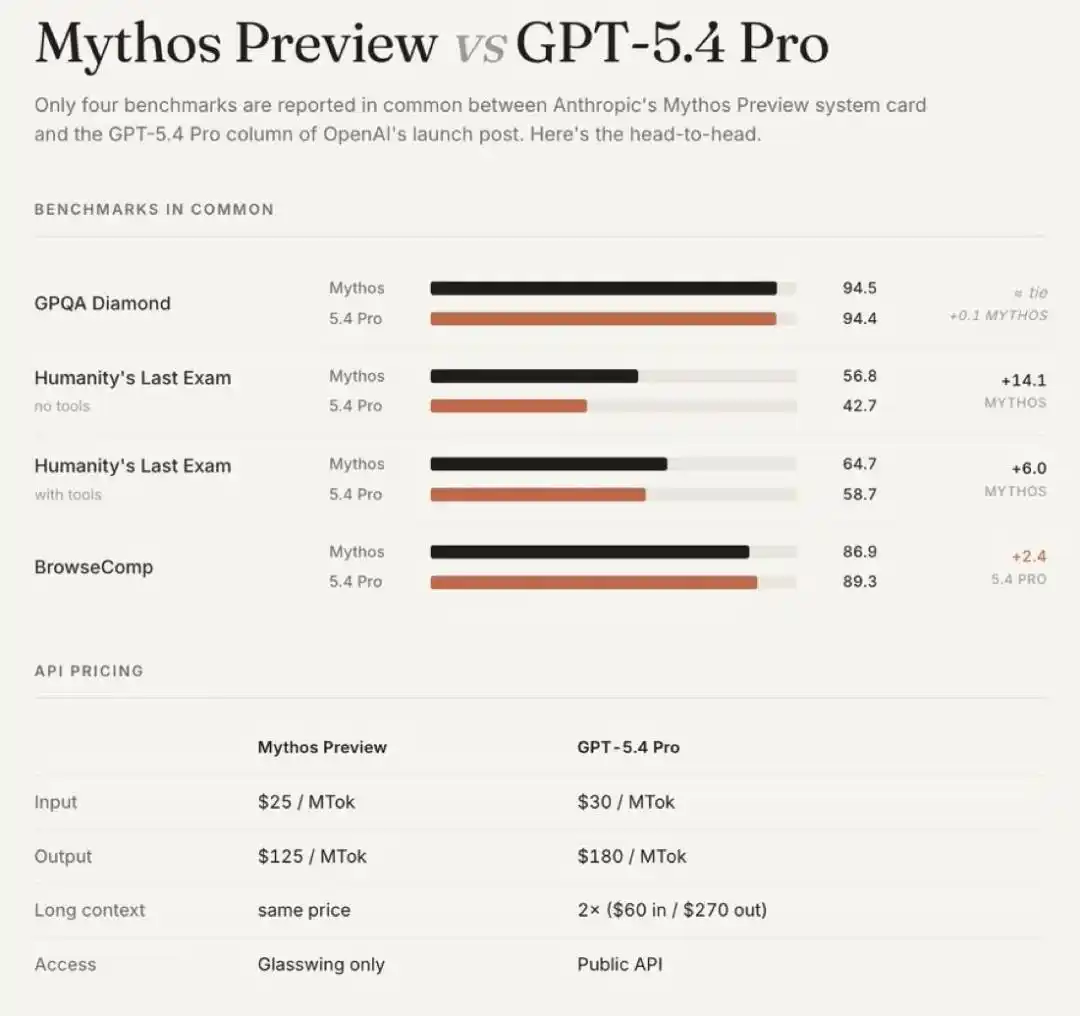
Это не «Anthropic проиграл», а «Anthropic выборочно перестал здесь напрягаться».
Направить ограниченные вычислительные ресурсы в гонку вооружений рейтингов, чтобы поддерживать虚幻ный ярлык «номер один», или же направить мощности в full-stack конструктор — продукт, который может напрямую создавать коммерческую ценность?
Для компании с годовым доходом в 300 миллиардов долларов, которой нужно доказывать инвесторам свою способность к коммерциализации, этот выбор несложен.
Модели достаточно, чтобы работать, а платформенная привязка — это ров.
Жестокая правда коммерческой конкуренции такова: пользователям плевать, 94.4 у вас балл GPQA или 94.5, пользователи关心的是 «Я скажу фразу, и приложение запустится ли».
Страх после 300 миллиардов годового дохода
Годовой доход Anthropic только что превысил 300 миллиардов долларов, обогнав OpenAI.
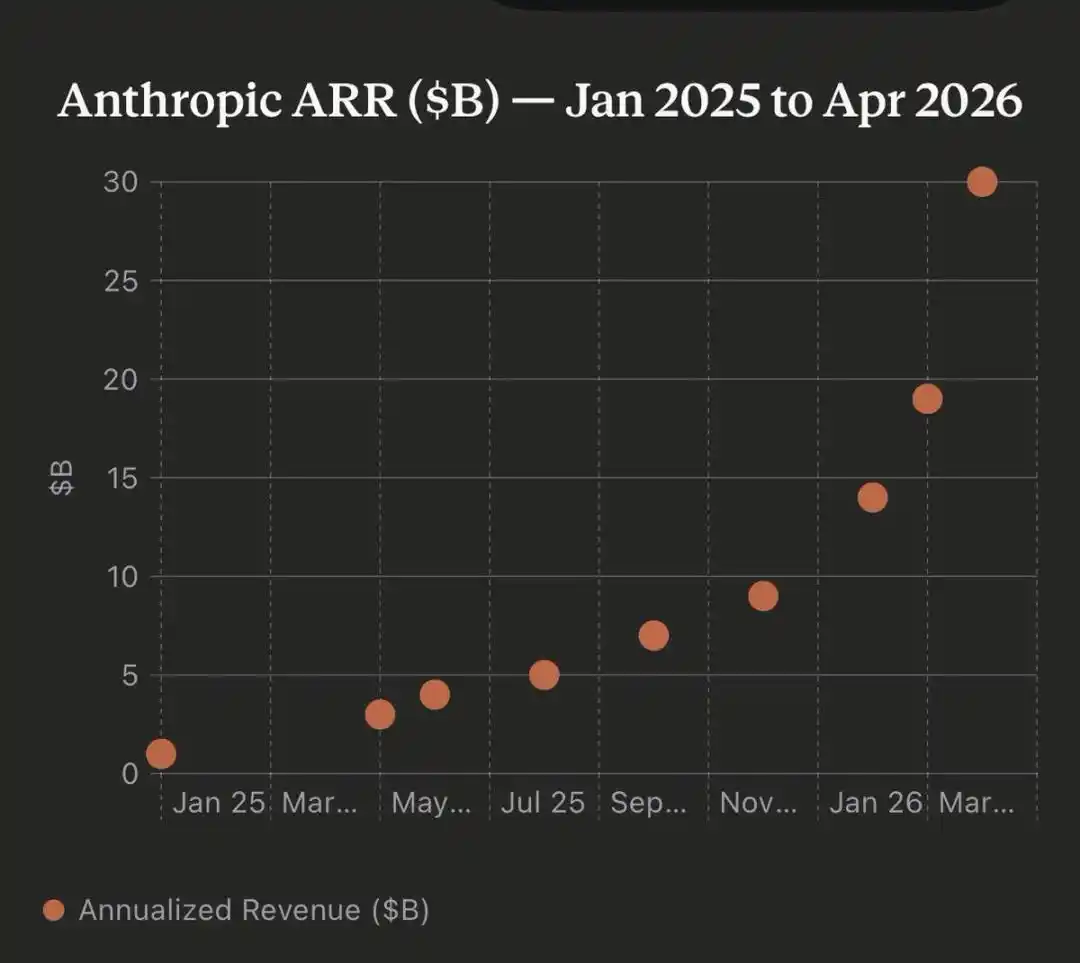
За 15 месяцев годовой доход Anthropic вырос с 1 миллиарда долларов до 300 миллиардов
Это цифра, из-за которой любая стартап-компания откроет шампанское.
Но если вы Дарио Амодеи, ваша главная эмоция сейчас — не празднование, а страх.
Потому что подавляющее большинство этих 300 миллиардов поступило от вызовов API. А API, по сути, является чрезвычайно опасной бизнес-моделью.
Почему? Потому что API означает, что ваш клиент использует ваши возможности для создания своих собственных продуктов.
Сегодня они вызвали API Claude и сделали платформу AI-поддержки, завтра сделали AI-инструмент для письма, послезавтра сделали AI-помощник для программирования.
Каждый успешный клиент строит своё здание на вашем фундаменте. Звучит прекрасно — до того дня, когда другая модельная компания предложит более дешёвый, примерно такой же хороший API, и ваши клиенты массово мигрируют за одну ночь.
Это кошмар «коммодитизации моделей»: когда разница на модельном уровне становится всё меньше, ценообразование API превращается в ценовую войну без победителей.
OpenAI почувствовала этот страх, поэтому она лихорадочно делает C2C-продукты — ChatGPT, GPTs, кастомные ассистенты. Google почувствовал этот страх, поэтому он засунул Gemini в поиск, почту, документы и каждый свой продукт.
Все они делают одно и то же: прежде чем модели станут дешёвыми как капуста, превратиться в платформу, без которой пользователи не могут жить.
Full-stack конструктор Anthropic — это самая радикальная версия той же логики.
Её подтекст таков:
Вместо того чтобы ждать, пока другие построят платформу поверх моего API, а затем в день падения цен на модели отшвырнут меня — лучше я сначала сам построю платформу.
Вам не нужно вызывать мой API, вы можете прямо на моей платформе создавать приложения. Ваши пользовательские данные у меня, ваш workflow у меня, ваша среда деплоя у меня. К тому времени, если вы захотите сменить модель? Можно, но весь ваш бизнес придётся переделывать.
Это не продуктовое innovation, это инстинкт выживания.
300 миллиардов выручки доказывают, что Anthropic способна зарабатывать деньги, но утечка暴露ила истинное беспокойство Anthropic — просто уметь зарабатывать недостаточно, нужно, чтобы от вас зависели.
Завершение: звёздное небо и иллюзии
Давайте отступим на шаг от бизнес-нарратива и вернёмся к исходной точке технологической оценки.
Текущие самые сильные большие модели — будь то Claude, GPT или Gemini — находятся примерно на уровне 70% возможностей. Скорость роста этой цифры за последние полгода заметно замедлилась.
Переход от 70% к 100% зависит не от набирания баллов в рейтингах, не от лишних процентных пунктов в GPQA. Это зависит от становления незаменимой инфраструктурой — как электрическая сеть, вам не важно, какие турбины использует электростанция, вы просто знаете, что свет включается, кондиционер охлаждает.
Full-stack конструктор Anthropic впервые позволил увидеть, что AI-компания серьёзно задумалась об этом пути «инфраструктуризации».
Больше не зацикливаясь на тщеславной войне «моя модель умнее твоей на 0.1 балла», а直接 отвечая на более фундаментальный вопрос: как сделать так, чтобы миллиард людей不知不觉 каждый день использовали мои штуки?
Потому что итог AI в конечном счёте определяет не то, у кого экзаменационные баллы выше. А то, кто первым станет той электрической сетью, без которой никто не может обойтись.
Источники:
https://x.com/cryptopunk7213/status/2043405326196867127
https://x.com/iruletheworldmo/status/2043332977136975994
https://x.com/marmaduke091/status/2043382991901147158
Эта статья из WeChat Official Account «新智元», редактор: KingHZ