The AlphaFold throne is in peril!
Nature publishes: The Biohub backed by Zuckerberg has dropped a bombshell, releasing 1.1 billion protein structure predictions in one go, surpassing the AlphaFold database by 800 million entries.
The underlying AI model, ESMFold2, is claimed to comprehensively outperform AlphaFold3.
More crucially, it is completely open-source and unrestricted for commercial use.

https://www.nature.com/articles/d41586-026-01686-3
Google DeepMind's hard-earned dominance in protein AI over the years is being shaken by an open-source disruptor.
The landscape of the protein AI race may be rewritten.
1.1 Billion Protein Structures, Served All at Once
On May 27th, the biomedical institution Biohub, founded by Mark Zuckerberg and his wife, officially launched the ESM Atlas protein structure database.
1.1 billion predicted protein structures, plus 6.8 billion protein sequence entries.
AlphaFold's database has accumulated over 200 million structure predictions. ESM Atlas arrives with 800 million more.
The AI model generating these predictions is called ESMFold2, developed by a team led by Biohub's scientific lead, Alex Rives.

Rives stated:
This atlas reveals the full picture of protein biology, especially its most unknown parts.
Why is protein structure prediction important?
Proteins are the core components driving life. Knowing their shape allows us to understand their function, thereby designing new drugs and conquering diseases.
AlphaFold won the Nobel Prize in Chemistry for this, becoming a landmark case of AI transforming science.
Now, a new model stands up with a dataset five times larger.
As an AI Model, Where Does ESMFold2 Excel?
ESMFold2 takes a different technical path than AlphaFold.
It's built upon a "protein language model" released in 2024. Its core idea borrows from NLP practices, treating protein sequences as "language" to understand. Trained on tens of billions of protein data points, the model learns to predict 3D structure directly from sequence.
AlphaFold's AI peers should find this familiar—it's the same logic large language models use to learn human language.
The coverage of training data is a key variable.
ESMFold2 incorporates a vast amount of microbial protein data from environments like soil and oceans, which is a gap in AlphaFold's database.
With broader coverage, the model's understanding of the "protein world" is more complete.
The Biohub team claims ESMFold2 outperforms AlphaFold3 in predicting complex structures of protein-protein interactions.
But the most convincing aspect isn't benchmarks, but real-world validation.
The team used ESMFold2 to design novel proteins, synthesized them in the lab for testing, and a high proportion of the designs functioned as intended.
From "prediction" to "design" to "verification," running this pipeline extends value from papers to the real world.

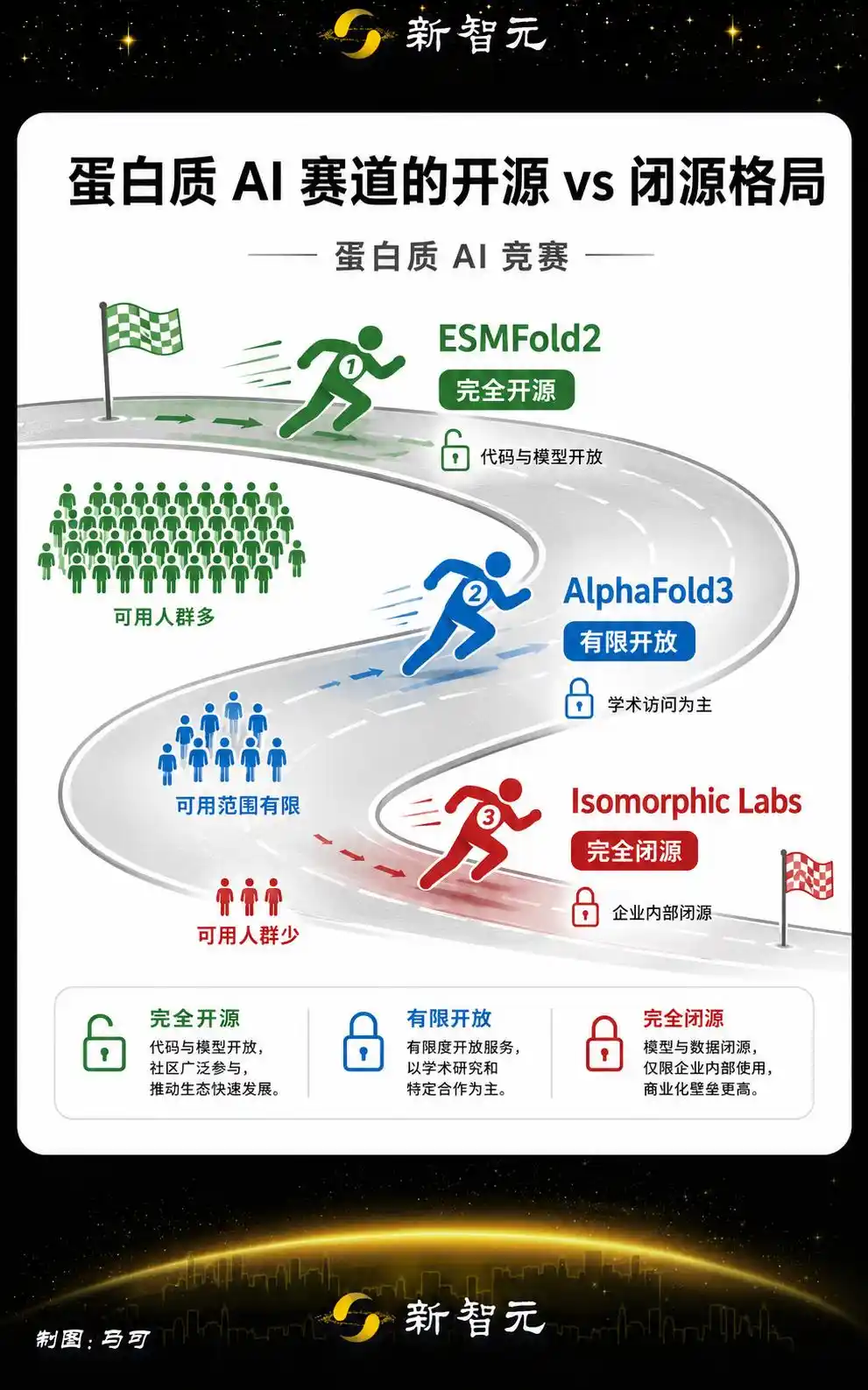
Completely Open-Source, This is the Real Killer App
ESMFold2's sharpest competitive weapon is being fully open-source with no commercial restrictions.
The strategic significance of this choice becomes clearer when viewed within the context of the entire AI industry.
While AlphaFold has an open database, AlphaFold3 initially imposed restrictions on commercial use upon release.
Isomorphic Labs under Google DeepMind went a step further, making its protein interaction prediction model this year entirely closed-source.
Further Reading: Google Releases "AlphaFold 4," No Longer Open-Source! Performance Crushes Predecessor
MIT computational biologist Ovchinnikov directly pointed out the value of open-source: "I expect many people will be excited to try ESMFold2."
The leverage effect of open-source AI has been fully demonstrated in the large language model arena, with Meta's Llama series being the prime example.
A sufficiently powerful open-source model can mobilize the global community to iterate, apply, and discover uses the original developers never imagined.
The situation in the protein AI field is even more unique. Globally, countless labs and research institutions urgently need a free, unrestricted structure prediction tool. No matter how powerful a closed-source model is, its reachable user base is limited.
Biohub's choice to go fully open-source aligns with Meta's strategy in large language models.
The Zuckerberg-affiliated strategy in AI is becoming increasingly clear—using open-source as infrastructure and building an ecosystem as a moat.
Do Fellow Experts Buy It?
The academic response is positive, but reservations are also clear.
Gemma Atkinson from Lund University, Sweden, called ESM Atlas "should be a phenomenal resource for biology."
Christine Orengo from University College London acknowledged its value but emphasized that the predictions need independent verification.

A sharper question came from Martin Steinegger of Seoul National University.

He is concerned about ESMFold2's performance when facing "novel structures" that differ significantly from known proteins.
His team previously found that the first version of ESMFold was not stellar in this regard. This question remains unresolved for ESMFold2.
MIT's Ovchinnikov offered the most measured judgment, suggesting that ESM Atlas might be better positioned as a supplement to the AlphaFold database.

He also noted that Isomorphic Labs' closed-source model and some other open-source models not directly compared by Biohub have achieved similar levels of results.
The lead of ESMFold2 might not be as large as the paper suggests.
This caution precisely reflects that competition in the protein AI race has become white-hot.
Open-source, closed-source, academic, commercial—models of all stripes are iterating at an extremely fast pace.
Today's "strongest" might be surpassed in six months. This pace is already very similar to the arms race in the large language model field.
When AI Begins to Read Life's Source Code
In the past, determining a protein's 3D structure could take months to years of lab work.
AlphaFold first proved AI could do it in minutes.
Now, ESMFold2 pushes the prediction scale to 1.1 billion, covering a vast number of proteins never before characterized.
Extrapolating forward along this path, when AI can accurately predict all protein structures and design novel functional proteins validated effectively by experiments, then AGI's landing in life sciences might be closer than most anticipate.
If and when ASI truly arrives, biology would no longer be a discipline it needs to "study," but a system that can be "engineered."
Designing life at the molecular level, customizing proteins on demand, rewriting the rules of evolution.
It sounds like science fiction, but tools like ESMFold2 are gradually turning "science fiction" into an "engineering problem."
Today, 1.1 billion protein structures are laid out on the table, free for any scientist worldwide with an internet connection to use.
This means AI's ability to understand life has reached another level.
Reference: https://www.nature.com/articles/d41586-026-01686-3
This article is from the WeChat public account "New Zhiyuan" (新智元), author: ASI启示录; editor: Marco








