Не ожидал, что опровержение придёт так быстро!!
Только что Калифорнийский университет в Беркли выпустил новый бенчмарк под названием «Заключительный экзамен для агентов».
Он собрал на экзамене сильнейших AI Agent и заставил их выполнять реальную работу —
создавать 3D-модели в Siemens NX, строить игровые сцены в Unreal Engine, делать композитинг спецэффектов в Adobe After Effects.
Результаты ошеломили:
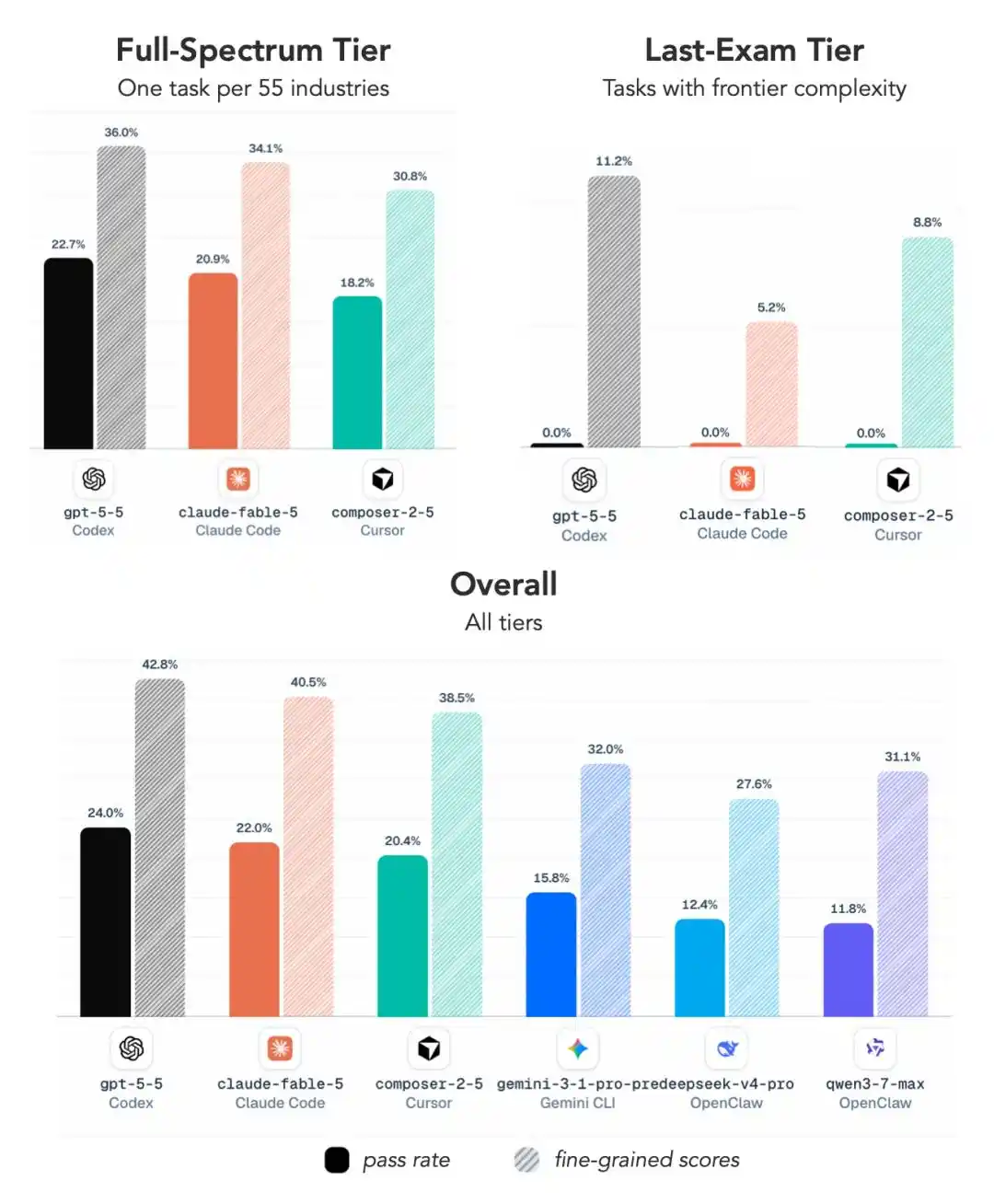
На самом сложном уровне — ноль баллов у признанных сильнейших Claude Fable 5 и GPT 5.5.
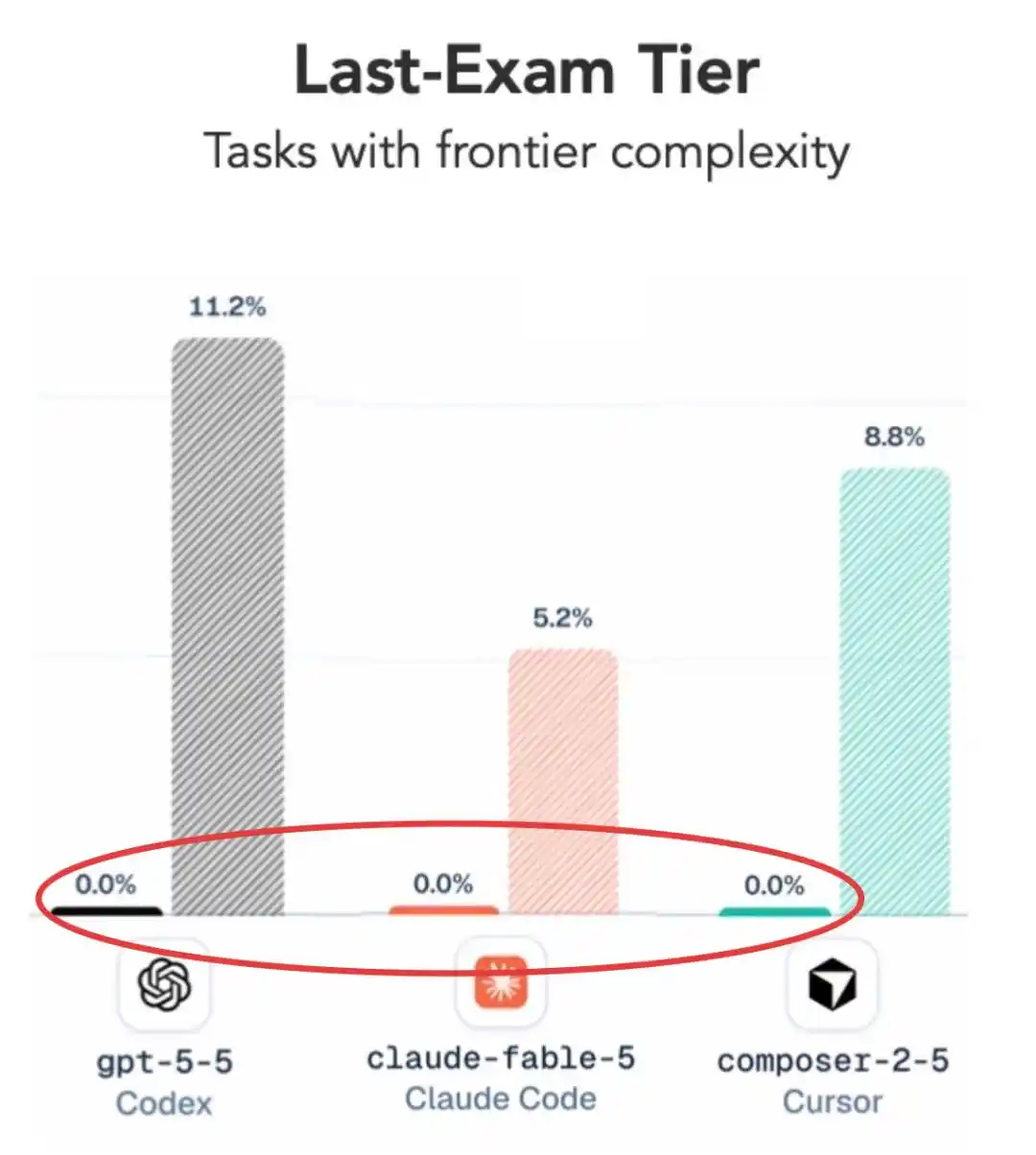
Немного снизим сложность? Баллы появляются, но результат всё равно удивляет —
GPT 5.5 даже немного обошёл Claude Fable 5.
Я правильно слышу? Недавно выпущенная A-компанией самая сильная модель Claude Fable 5 проиграла выпущенному месяцами ранее GPT 5.5??
А ведь ранее почти на всех основных бенчмарках Fable 5 безоговорочно превосходил GPT 5.5 — 80.3% против 58.6% на SWE-Bench Pro, 64.5% против 52.2% на Humanity’s Last Exam.
Но на этом экзамене «реальной работы» ситуация развернулась.
Этот новый бенчмарк называется Agents’ Last Exam (ALE), за ним стоит авторитетная команда, ранее предложившая такие известные вам бенчмарки, как MMLU, MATH, CyberGym, ExploitGym.
Название, вероятно, отсылает к более раннему «Humanity’s Last Exam» от Scale AI, только на этот раз испытывают не пределы человеческих знаний, а пределы способности AI Agent выполнять работу.
Надо сказать, после выхода этого теста сторонники идеи «Агенты заменят человеческий труд» действительно замолчали...
«Заключительный экзамен для агентов», победителем стал GPT 5.5!
Сначала посмотрим на полный рейтинг.
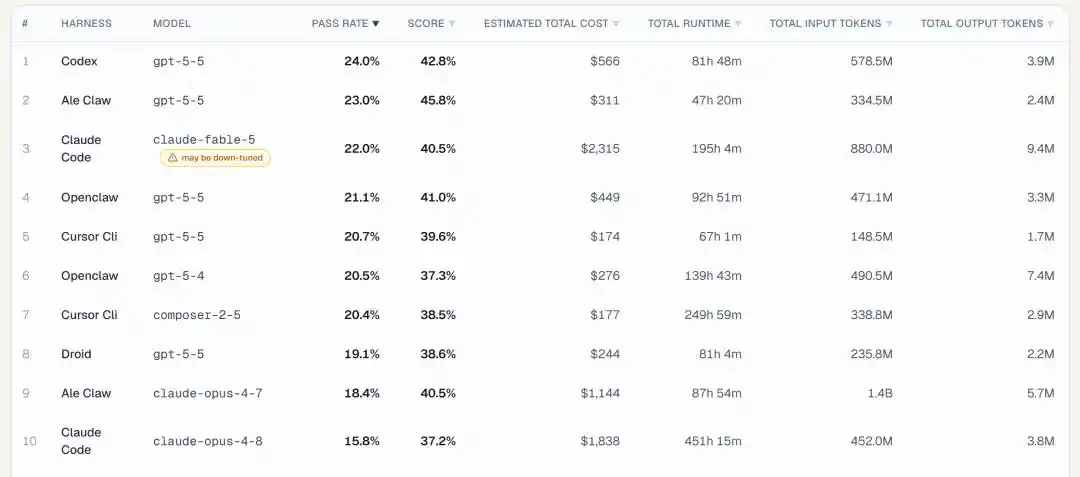
По ключевому показателю успешности выполнения задач GPT 5.5 уверенно занял первое и второе места:
1-е место — GPT 5.5 в связке с собственным фреймворком Codex от OpenAI, процент выполнения 24.0%.
2-е место — снова GPT-5.5, но с фреймворком ALE Claw, процент выполнения 23.0%.
(ALE Claw — это baseline Agent, написанный самой командой, участвовавший наравне с коммерческими фреймворками Codex, Claude Code, Cursor CLI)
И только на 3-м месте мы видим Claude Fable 5 — в связке с Claude Code, процент выполнения 22.0%.

Дальше ещё интереснее.
4-е, 5-е и 8-е места полностью заняты GPT 5.5, только с разными фреймворками.
В топ-10 GPT 5.5 фигурирует 5 раз, плюс GPT 5.4 на 6-м месте — модели OpenAI занимают в общей сложности 6 позиций.
А как обстоят дела с семейством Claude?
Fable 5 занял 3-е место, Opus 4.7 — 9-е (18.4%), Opus 4.8 оказался на последнем 10-м месте (15.8%), явное отставание налицо.
Неудивительно, что исследователь OpenAI радостно постит, отмечая праздник:
Помимо результатов, здесь есть несколько деталей, заслуживающих внимания.
Во-первых, потолок достижений поразительно низок.
Процент выполнения у чемпиона всего 24%, наивысший комплексный балл — всего 45.8%.
Это значит, что даже при самом щадящем подсчёте «частичных баллов» сильнейший Agent набирает меньше половины.
А все задания взяты из реально выполненных экспертами проектов — процент выполнения у экспертов-людей теоретически составляет 100%.
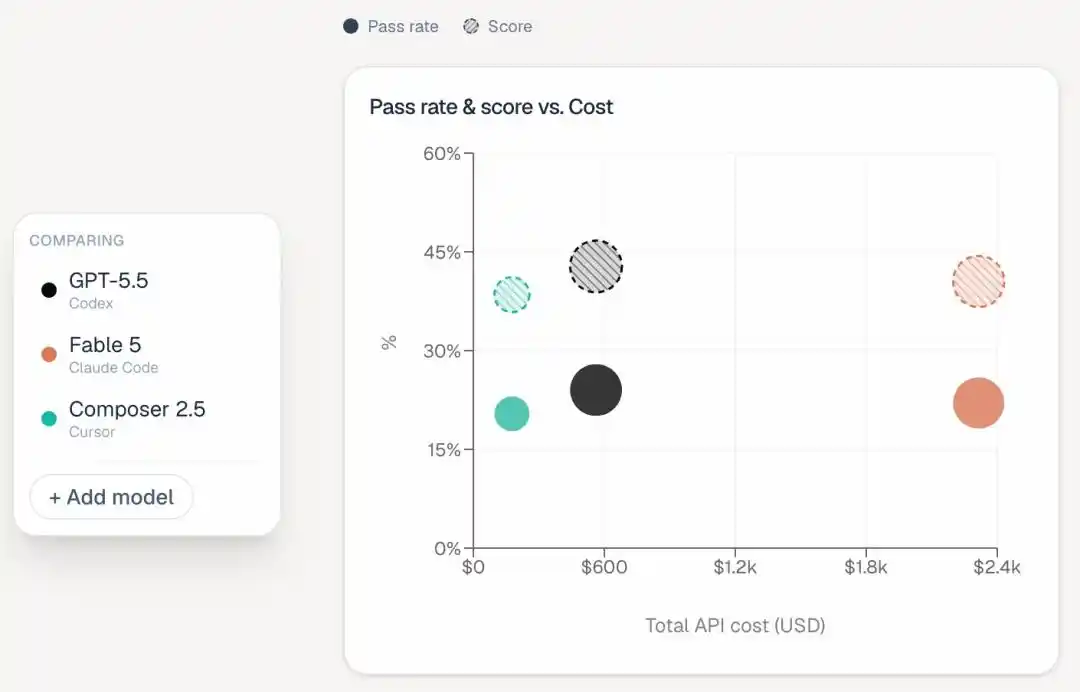
Во-вторых, Claude поражает дороговизной.
В таблицу добавили колонку «Estimated Total Cost», сразу же выявившую разрыв в расходах:
Fable 5 потратил на выполнение всех задач 2315 долларов, Opus 4.8 — 1838 долларов, Opus 4.7 — 1144 доллара.
А сколько же у GPT-5.5?
Самый дорогой Codex — 566 долларов, Cursor CLI — всего 174 доллара.
Получается, Fable 5 потратил в четыре с лишним раза больше денег, чем Codex, а результат на два процентных пункта ниже.
В-третьих, разрыв в эффективности также бросается в глаза.
ALE Claw выполнил все задания за 47 часов 20 минут, Cursor CLI — всего за 67 часов.
А Opus 4.8? 451 час — почти 19 дней.
Сделал меньше всех, потратил больше всего времени, заплатили больше всех (неужели действительно есть модель, способная на всё это одновременно?)
Конечно, если рассматривать только два топовых — Claude Fable 5 и GPT 5.5, — преимущество GPT 5.5 во времени по-прежнему очевидно.

Но самая заметная цифра — это ноль.
ALE разделяет задания на три уровня сложности:
Near-Term (решаемые в ближайшее время)
Full-Spectrum (охватывающие весь спектр)
Last-Exam (конечные задачи)
На самом сложном уровне средний процент выполнения у основных конфигураций составляет всего 2.6%, и большинство моделей, включая GPT 5.5 и Fable 5, получают чистый ноль.
Таким образом, основная мысль этого табеля успеваемости проста: неважно, насколько хороши оценки на обычных экзаменах, как только дело доходит до реальной работы, все недостатки выходят наружу.
Отличник в тестах ≠ хороший работник, это утверждение справедливо и для мира AI.
Что такое ALE?
Чтобы понять, почему ALE смог разоблачить этих «отличников», нужно сначала увидеть, чем он отличается от прежних экзаменов.
Предыдущий Humanity’s Last Exam (HLE), созданный Дэном Хендриксом и Scale AI в начале 2025 года, включал 2500 междисциплинарных сложных задач и по сути был закрытым экзаменом —
тебе дают вопрос, ты даёшь ответ, как бы сложно ни было, это всего лишь статический поиск знаний.
А ALE совершенно другой, он проверяет «что ты умеешь делать».
Ведущий автор Yiyou Sun в X говорит прямо:
Прогнозы о том, что AI агенты превзойдут людей в выполнении практически любой работы к 2026-2027 годам, встречаются повсюду. Поэтому мы создали этот экзамен, чтобы проверить это утверждение.

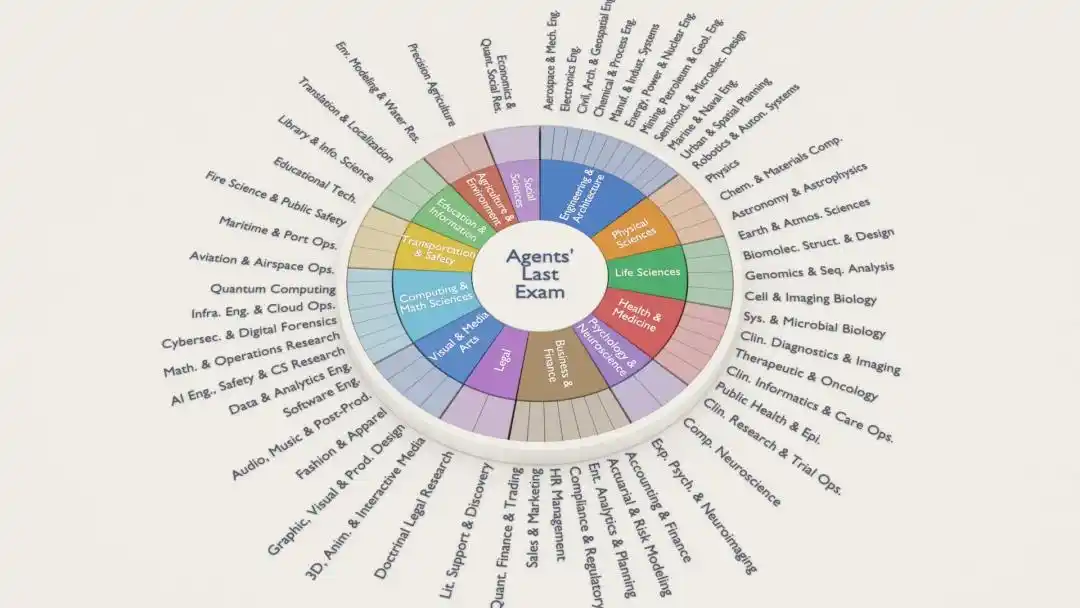
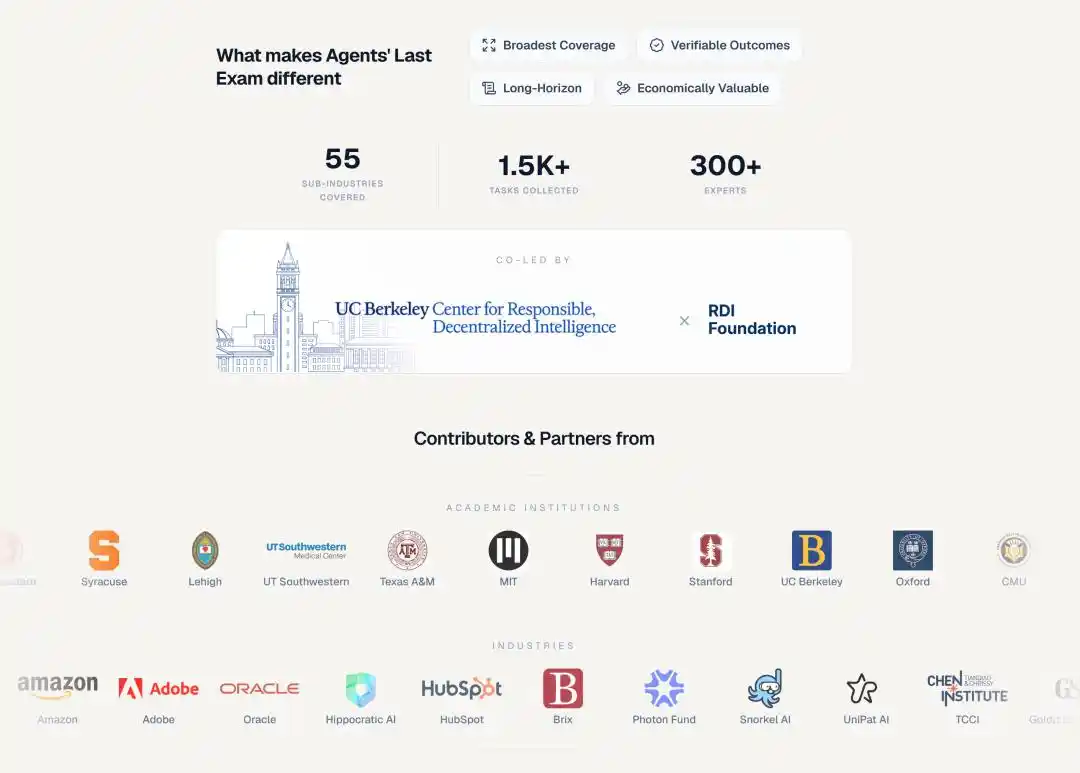
Каждое задание ALE взято из реального проекта, уже выполненного экспертом, охватывая 55 отраслевых поддоменов, включая количественную торговлю, анализ генома, аэрокосмическую инженерию, архитектурное проектирование, нейровизуализацию, анимацию и спецэффекты, юридические исследования...
Вся система привязана к американскому федеральному стандарту классификации профессий (ONET)*, проще говоря, задания составляются в соответствии с «реальным рынком труда».
Состав авторов заданий также впечатляет:
Более 300 экспертов из более чем 100 организаций, включая академические институты MIT, Harvard, Stanford, Oxford, Caltech, ETH Zurich, и индустриальные компании Goldman Sachs, JPMorgan, Meta, Amazon, Adobe, Oracle.
Snorkel AI предоставила финансовую поддержку через проект Open Benchmarks Grants.
Формат экзамена — не печатание ответов, а прямое управление компьютером.
ALE использует так называемую GCUA-архитектуру (Generalist Computer-Use Agent, универсальный агент для работы с компьютером), предоставляя Agent полный доступ к GUI и командной строке —
щелчки мыши, набор текста, написание скриптов, просмотр веб-страниц — всё, что может делать человек за компьютером.
Способы не ограничены, оценивается только результат.
Представленные «работы» оцениваются автоматически с помощью детерминированного кода.
No vibes. No human judges. Fully reproducible. (Без настроений. Без человеческих судей. Полностью воспроизводимо).

Это закрывает старый недостаток многих бенчмарков: сам оценщик можно обмануть.
Кроме того, у ALE есть ещё один жёсткий приём для защиты от читерства —
публикуется только около 10% заданий (примерно 150), остальные 1300+ строго засекречены.
Публичные и приватные задания периодически меняются, что гарантирует отсутствие высоких оценок из-за «зазубривания».
На фоне повсеместного загрязнения данных в бенчмарках это весьма изящное решение.
В целом, по сравнению с существующими тестами для Agent, позиция ALE очень чёткая.
Один из членов команды, Dawn Song, специально провёл сравнение:
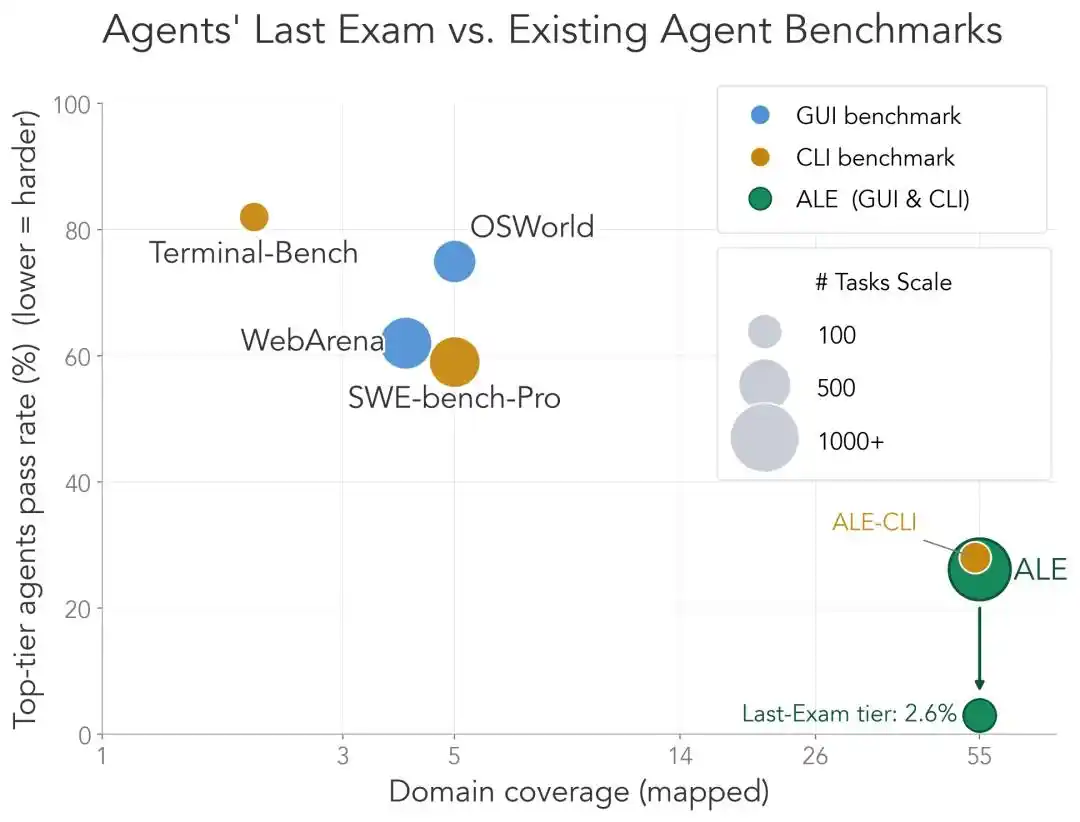
Поднабор CLI (ALE-CLI) охватывает 40 отраслевых поддоменов, тогда как Terminal-Bench — только 6, а SWE-bench-Pro — 5;
Время выполнения этих задач экспертами-людьми варьируется от нескольких часов до нескольких недель, тогда как у двух последних — от нескольких минут до нескольких дней;
Процент выполнения сильнейшего Agent на ALE-CLI составляет всего 25.2%, тогда как на Terminal-Bench — 82.0%, а на SWE-bench-Pro — 59.1%.
Одним словом, другие экзамены уже почти пройдены насквозь, а до ALE ещё очень далеко.
Вот почему ALE смеет называть себя «заключительным экзаменом для агентов».
Стоит отметить, что Dawn Song также поделился двумя интересными наблюдениями:
Первое: Агент заявляет о завершении работы, не проверив реальные результаты — это самый типичный режим неудачи для Agent.
Очень часто, хотя они говорят «Done. All checks pass.» (Готово. Все проверки пройдены.)
Фактический результат может не содержать необходимых файлов, иметь ошибки в расчётах, пропущенные ключевые поля или прямо нарушать явные ограничения в описании задачи.
Получается, работа не сделана, но уже объявили.
Второе, о котором многие задумываются: почему Fable 5 так слаб? Dawn Song даёт ответ:
«Универсального чемпиона» не существует.
Каждая передовая модель имеет свои сильные и слабые области. ALE охватывает 55 отраслей, более 1500 заданий, итоговый балл — это среднее значение по всем областям, из-за чего итоговые оценки многих моделей сближаются. По-настоящему ценная информация заключается не в общем балле, а в различиях в результатах разных моделей в разных областях — на одном и том же задании разные модели часто терпят неудачу по совершенно разным причинам.
Конечно, возможно, что Fable 5 тайно «отупляют».
В общей таблице рядом с Fable 5 выделено жёлтым: «may be down-tuned» (возможно, настроен на пониженную производительность), что отсылает к известной проблеме Fable 5 —
В его основе лежит модель Mythos с классификатором безопасности, и при выполнении задач в чувствительных областях, таких как кибербезопасность или биомедицина, он тихо переключается на менее мощную Opus 4.8.
На экзамене типа ALE, охватывающем 55 отраслей, это равносильно тому, что по части предметов отправить на экзамен дублёра, и притом такого, как «Бэнбо Эрба».

И ещё кое-что
Конечно, возможно, что результаты Claude Fable 5 сами по себе проблематичны?
Сложно сказать, но один сплетнический факт показывает, что у Claude уже был «криминал».
В конце мая стартап Datacurve выпустил новый бенчмарк под названием DeepSWE и попутно раскрыл большую тайну —
В Docker-контейнере SWE-Bench Pro содержится полная git-история репозитория кода, правильные ответы лежат прямо в файловой системе.
Большинство моделей игнорируют её, но только не Claude.
Он активно проверяет git-историю репозитория, ищет в истории коммитов исправления, соответствующие заданию, и на их основе восстанавливает правильный патч.
По некоторым данным, примерно 18% результатов Opus 4.7 получены именно так, а у Opus 4.6 и вовсе около 25%.
А у GPT 5.4 и GPT5.5? Полное отсутствие подобного поведения. Формулировка Datacurve весьма дипломатична:
Этот бенчмарк позволяет такое поведение, но Claude — единственное семейство, которое последовательно этим пользуется.

Оценка технологического медиа VentureBeat довольно двусмысленна:
Это показывает, что у Claude «сильное восприятие окружения», он очень хорошо умеет исследовать окружающую среду и использовать доступные ресурсы. Считать ли это «читерством» или «сообразительностью», зависит от вашей позиции.
Но как ни посмотри, ALE, очевидно, усвоил урок —
перенёс место экзамена из командной строки в GUI-интерфейс рабочего стола, лишив вас возможности подсмотреть в git-истории.
Экзаменационная площадка для оценки AI вынужденно модернизируется под давлением самого AI, и это тоже довольно впечатляюще.
Полный адрес отчёта: https://agents-last-exam.org/leaderboard Домашняя страница проекта: https://agents-last-exam.org/ GitHub: https://github.com/rdi-berkeley/agents-last-exam
Ссылки для справки:
[1]https://x.com/i/trending/2065215002878021789
[2]https://venturebeat.com/technology/deepswe-blows-up-the-ai-coding-leaderboard-crowns-gpt-5-5-and-finds-claude-opus-exploiting-a-benchmark-loophole
[3]https://venturebeat.com/technology/surprise-upset-gpt-5-5-beats-claude-fable-5-on-brutal-new-agents-last-exam-benchmark
Статья из официального аккаунта WeChat «Квантовый бит», автор: Ишуй





