Сдерживание вычислительной мощности
С конца прошлого года такие отечественные производители GPU, как Moore Thread, Muxi Co., Ltd., Biren Technology и Enflame Technology, подняли волну капитала. Однако за пиршеством богатства на вторичном рынке становится все более очевидной скрытая линия, вызывающая все более насущные проблемы.
За последние годы отечественные AI-чипы в основном сосредоточились на относительно безопасных и периферийных задачах, связанных с "выводом", например, недавно Doubao планировал закупить 50 000 чипов Enflame Technology для задач вывода, чтобы удовлетворить высокочастотные вызовы этого крупнейшего китайского AI-приложения.
А на вершине иерархии вычислительной мощности в области обучения AI отечественные чипы в настоящее время могут участвовать только в периферийных "вспомогательных" задачах.
Чипы для обучения AI в основном используются для обучения моделей искусственного интеллекта, в процессе которого выполняется большое количество матричных операций и корректировок параметров, поэтому они должны обладать мощными вычислительными способностями и высоким энергоэффективностью, быть более производительными и, соответственно, дорогими, как, например, NVIDIA A100, H100, H200 и серия AMD MI300;
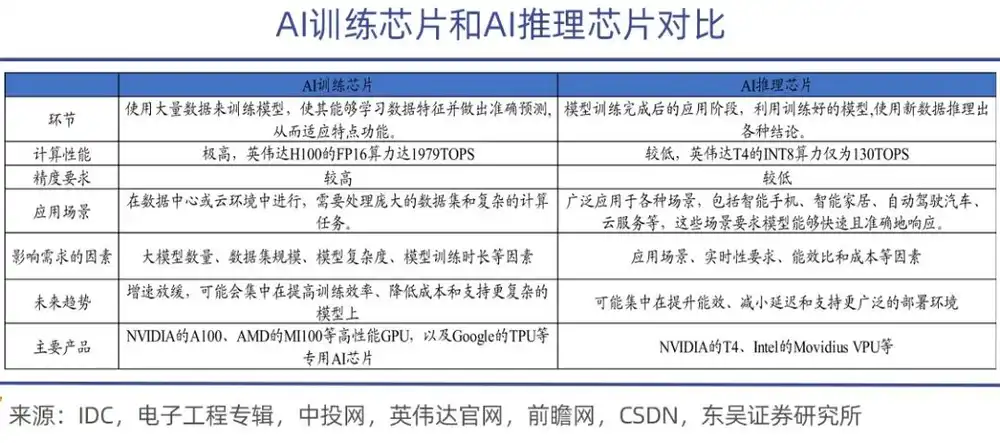
В сравнении с этим задачи чипов для вывода значительно проще. Они используются на этапе развертывания после завершения обучения модели, в основном отвечая за выполнение задач вывода модели, к которым предъявляются высокие требования к реальному времени; чипы вывода должны обладать быстрым откликом и низким энергопотреблением при обеспечении точности.
Уместная аналогия: обучение — это дать AI-модели "усвоить знания", а вывод — заставить большую модель "применять знания". На этапе обучения чипу для обучения необходимо использовать огромные объемы данных для "кормления" динамически обновляемых параметров уровня миллиардов, триллионов и даже десятков триллионов, что требует не только мощной вычислительной способности, но и эффективной пропускной способности, коммуникационных возможностей, а также обеспечения стабильности в кластерах уровня десятков тысяч карт.
Истоки разрыва между китайскими и американскими моделями лежат именно в этих "невидимых местах", особенно в отсутствии высокопроизводительных чипов для обучения.
Согласно закону Scaling Law для больших моделей, чем больше параметров модели, тем линейно возрастает потребность в вычислительной мощности, а экспоненциально растущие затраты на вычисления и аппаратное обеспечение делают обучение больших моделей "эксклюзивной игрой" для горстки технологических гигантов.
Среди американских технологических гигантов только Meta планирует к концу 2026 года развернуть более 1,2 миллиона высокопроизводительных GPU, с годовыми инвестициями свыше 145 миллиардов долларов; по другим оценкам, совокупные вычислительные мощности AI у Google эквивалентны 5 миллионам NVIDIA H100, что составляет 1/4 от мирового объема для одной компании.
Капитальные затраты четырех компаний — Amazon, Microsoft, Alphabet и Meta — в этом году достигли 725 миллиардов долларов, что на 77% больше, чем в прошлом году; этот объем эквивалентен 13% от общих годовых частных внутренних инвестиций США. Morgan Stanley прогнозирует, что к 2027 году капитальные затраты американских технологических компаний могут достичь рекордных 1,1 триллиона долларов.
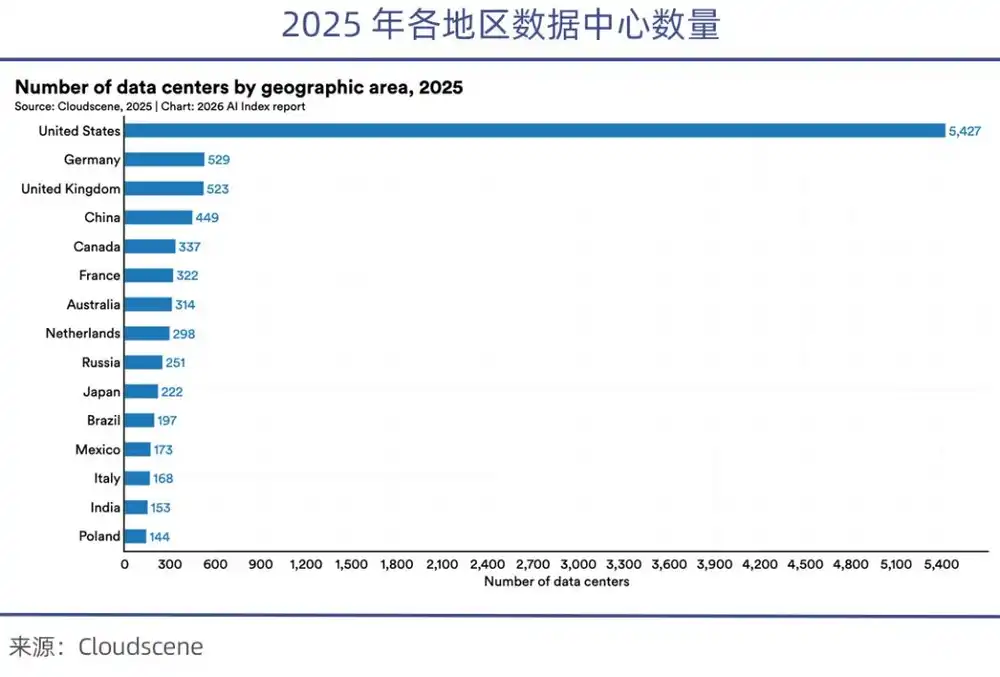
В настоящее время США контролируют более 70% мировых высокопроизводительных GPU, и после запрета на поставки чипов доступные в Китае высокопроизводительные чипы составляют лишь 1/8 от американских. В отчете Stanford AI Index Report 2026 указывается, что количество центров обработки данных в США (5427) более чем в 10 раз превышает количество в Китае.
Согласно расчетам Китайской академии информационных и коммуникационных технологий (CAICT), к началу 2025 года масштаб вычислительной мощности США составлял 2400 EFLOPS, а Китая — 1053 EFLOPS, что более чем в два раза превышает показатели Китая.
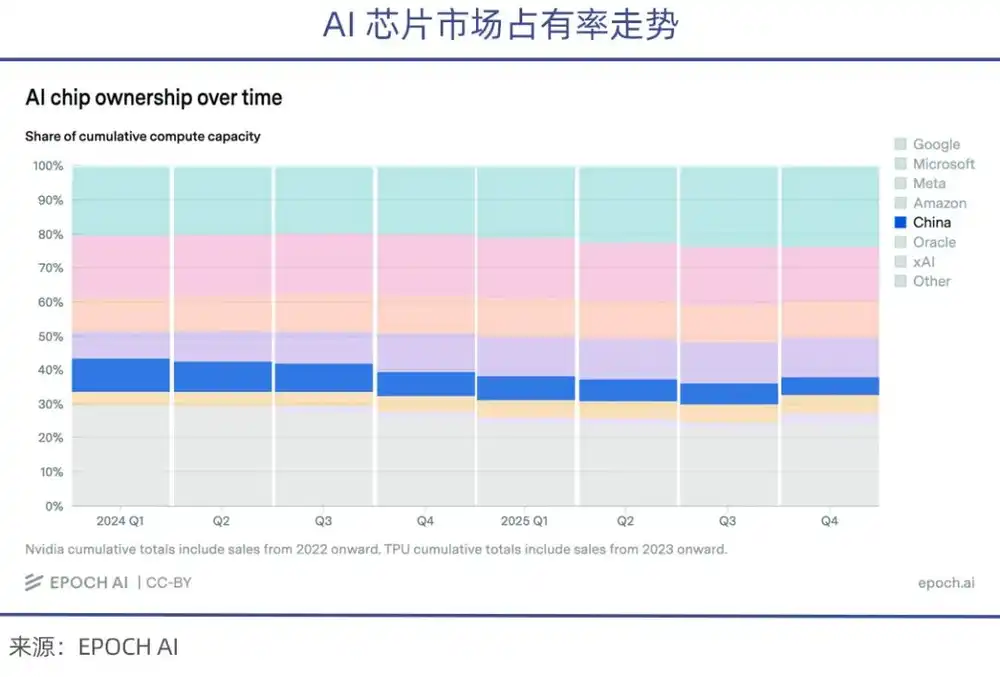
Каждая из четырех упомянутых технологических гигантов обладает масштабом вычислительной мощности, превышающим совокупные показатели всех китайских AI-компаний.
Это подавляющее преимущество в вычислительной мощности позволяет американским компаниям завершать более десятка итераций экспериментов с большими моделями в течение года.
Маск идет еще дальше: его xAI владеет кластером Colossus 2, который называют первым в мире "AI-кластером гигаваттного уровня". Поэтому он смело заявляет, что одновременно обучает 7 моделей — две по 1 триллиону, две по 1,5 триллиона, одну по 6 триллионов и одну по 10 триллионов параметров; такая "эстетика насилия" возможна только при крайне избыточной вычислительной мощности.

В то же время из-за ограничений США на экспорт чипов доля китайских компаний в поставках высокопроизводительных AI-чипов в последние годы продолжает снижаться (по статистике epoch.AI).
Можно без преувеличения сказать, что огромный разрыв в вычислительной базе приведет к тому, что китайский ИИ надолго останется на этапе догоняющего развития, а процесс, в котором отечественные большие модели догонят американских коллег, станет еще более трудным.
Разница поколений
"Темпы инноваций в Китае неудержимы", "Тот, кто думает, что Китай не сможет создать (чипы), действительно ошибается. Разрыв между Китаем и США составляет всего наносекунды".
Основатель NVIDIA Джэнсон Хуанг не раз публично хвалил прогресс китайской полупроводниковой промышленности.

Маск также часто выражает аналогичные взгляды в X — "Китай обязательно решит проблему зависимости от зарубежных чипов, и в области вычислительной мощности искусственного интеллекта он, несомненно, превзойдет все другие страны мира", "Китай выиграет гонку искусственного интеллекта на Земле".
Когда столь громкие имена в технологическом мире чрезмерно восхваляют развитие ИИ в Китае, легко поверить, что это правда. Очевидно, что эти заявления содержат элементы "убийства похвалой". Некоторые американские СМИ продолжают пропагандировать мнение о том, что разрыв между китайскими и американскими моделями крайне мал, пытаясь исказить факты и скрыть некоторые объективные истины.
В связи с этим все области, связанные с ИИ в Китае, должны сохранять ясность и спокойствие.
Если можно сказать, что современные китайские передовые большие модели мало отличаются от американских аналогов при решении стандартизированных проблем, то в сложных промышленных и корпоративных условиях разрыв становится более очевидным.
По сравнению с передовыми моделями американских компаний, таких как Anthropic, Китай все еще является догоняющей стороной. Американская CAISI оценивает, что самая мощная китайская модель DeepSeek V4 Pro отстает от американского авангарда примерно на 8 месяцев.
Недавно в интервью The Wall Street Journal Кай-Фу Ли отметил, что если брать за ориентир такие американские топовые модели, как Claude Fable 5 от Anthropic, то США в настоящее время опережают Китай примерно на 15 месяцев.

Большие модели следуют закону Scaling Law: чем больше параметров модели, чем больше данных для обучения и чем больше вычислительных ресурсов вложено, тем лучше производительность модели. В настоящее время самые передовые американские большие модели вступили в эпоху триллионов параметров, и скорость их итерации продолжает увеличиваться.
Самая мощная модель Anthropic Mythos достигла 10 триллионов параметров, и ее обучение обошлось в 10 миллиардов долларов; xAI Colossus 2 одновременно обучает 7 моделей, включая модели с 6 триллионами и 10 триллионами параметров; OpenAI выполняет итерацию модели с 4 триллионами параметров всего за месяц.
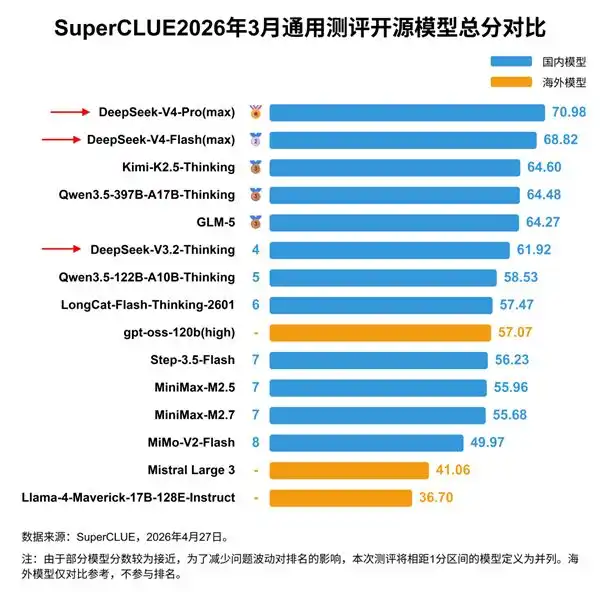
Общее количество параметров самой мощной китайской модели DeepSeek V4 Pro составляет 1,6 триллиона, что примерно в 6 раз меньше, чем у американских передовых моделей с десятками триллионов параметров.
Серия Claude от Anthropic уже признана самой мощной AI-моделью для программирования за последние два года, а Mythos снова изменил общественное восприятие, его производительность еще более мощная по сравнению с предыдущим флагманом Oups 4.6.
OpenBSD славится самой безопасной системой в отрасли, но Mythos нашел уязвимость, которую не обнаруживали в течение 27 лет; он также нашел уязвимости в FFmpeg и ядре Linux, которые не обнаруживались в течение нескольких лет или даже более десяти лет, причем все это было обнаружено автономно, без помощи человека.
Важно понимать, что "предварительное обучение" большой модели определяет верхний предел возможностей модели, и невозможно посредством "дообучения" настроить модель уровня триллионов параметров до уровня возможностей модели с 10 триллионами параметров. А определяющим фактором предварительного обучения являются высокопроизводительные вычислительные чипы, которые определяют масштаб параметров и скорость итерации обучения.
Председатель правления iFLYTEK Лю Цинфэн прямо заявил, что в настоящее время ведущие производители больших моделей, особенно американские гиганты, строят платформы сверхбольших вычислительных мощностей. А отечественные вычислительные мощности действительно переживают болезненный период, что привело к ограничениям при обучении на очень длинных текстах.
Таким образом, разрыв в вычислительной мощности является источником различий между китайскими и американскими моделями.
Подъем отечественных производителей
Одна компания монополизирует 90% мирового рынка высокопроизводительных AI-чипов для обучения — это помогает NVIDIA сохранять трон самой дорогой компании в мире. Ее общая рыночная капитализация в какой-то момент превысила ВВП Германии, третьей по величине экономики мира в 2025 году.
По данным TrendForce, в первом квартале 2026 года на мировом рынке GPU-серверов NVIDIA захватила 68%, AMD заняла 5%-6%, а совокупная доля отечественных производителей GPU составила менее 4%.
Благодаря преимуществу первопроходца, сверхвысоким техническим барьерам, высокоскоростной взаимосвязи, программной экосистеме и привязке к передовым технологическим процессам TSMC, NVIDIA доминирует в мире. В высокопроизводительных сценариях обучения NVIDIA GB300 превосходит AMD MI325, а также Cambricon Siyuan 690 и Moore Thread MTT40, особенно при обучении больших моделей с триллионами параметров, где его производительность на 30% выше, чем у конкурентов.
В условиях запрета на экспорт Хуан ранее заявил, что доля NVIDIA на китайском рынке (новая) практически свелась к нулю, остался лишь существующий рынок. При поддержке политики импортозамещения появились такие компании, как Huawei Ascend 910, Hygon DCU ShenSuan 2, Cambricon Siyuan 370/590, а также Moore, Muxi и другие.
Среди них Ascend 910 — самый мощный вычислительный чип Huawei, вычислительная мощность Ascend 910B достигает 640 TOPS (INT8), что сопоставимо с чипом NVIDIA A100.
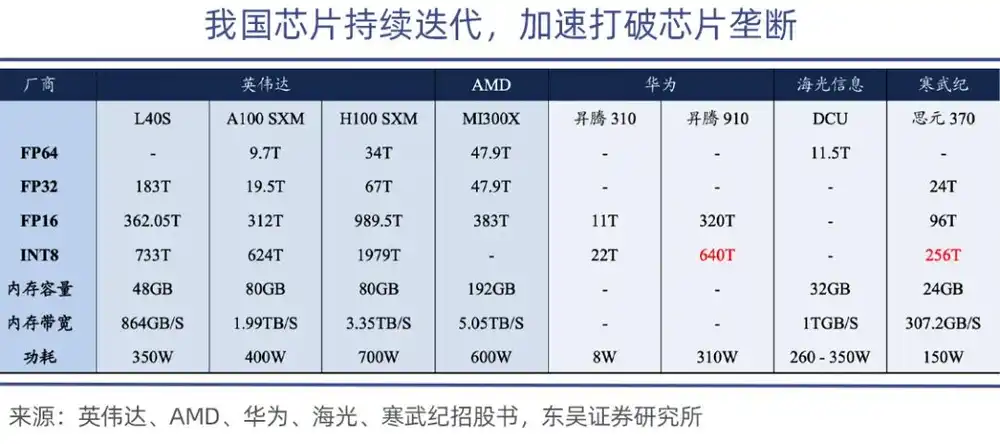
На уровне абсолютной производительности отечественные GPU, хотя и все еще имеют разрыв, могут начать со сценариев вывода и периферийных вычислений; в настоящее время отечественные GPU в основном удовлетворяют потребности государственных и корпоративных пользователей в общем выводе, разрыв с продуктами NVIDIA среднего уровня сократился до 15%-20%, что делает замену возможной.
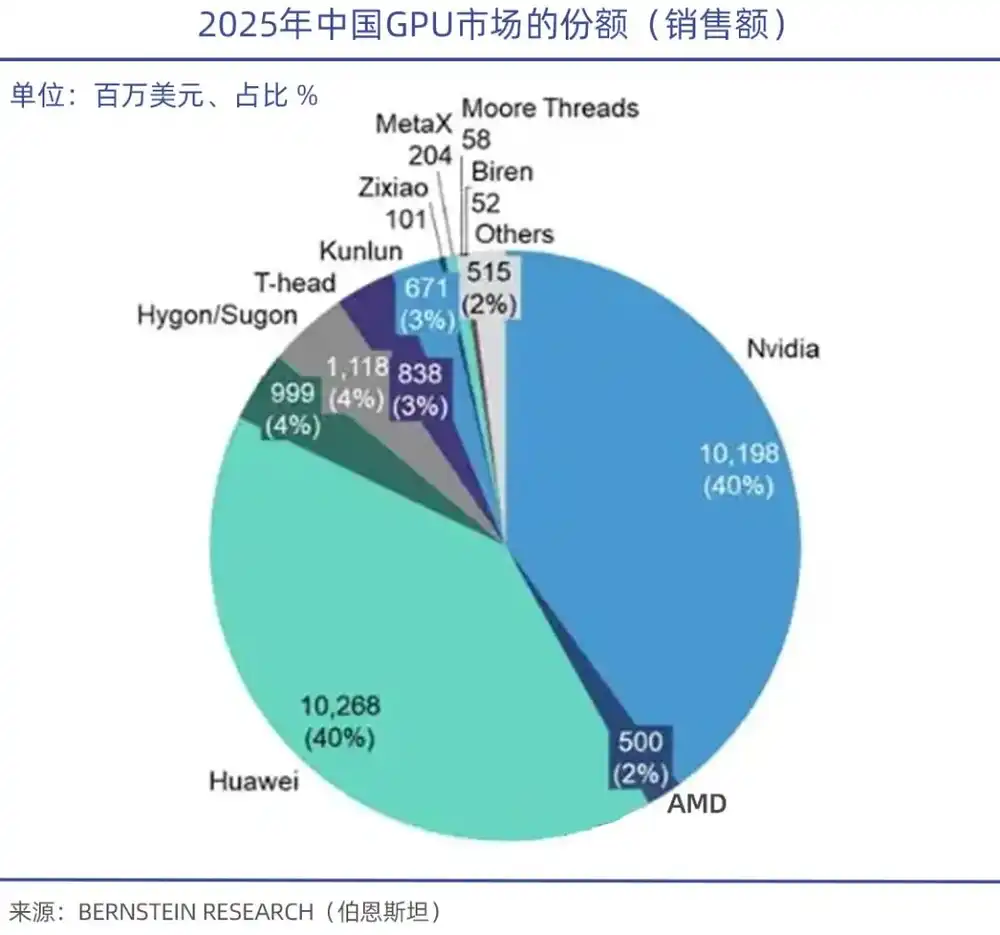
Следует особо отметить, что хотя производительность вычислений важна, именно техническая программная экосистема за ней является слабым местом отечественных GPU. Как и CUDA, которая является основой империи GPU NVIDIA, академик Китайской инженерной академии Чжэн Вэйминь отметил, что ключевой проблемой отечественных AI-чипов является недостаточно хорошая экосистема; если бы экосистема была хорошей, даже при 60% производительности нашлись бы пользователи.
Можно сказать, что программная экосистема является самым жестким барьером на рынке GPU, и в этом отношении возможности NVIDIA также трудно заменить.
Экосистема CUDA развивалась более десяти лет и насчитывает более 4 миллионов разработчиков, сотни тысяч моделей с открытым исходным кодом, полный набор инструментов сторонних производителей, охватывающих AI-обучение, вывод, графический рендеринг, научные вычисления, создавая мощный и неповторимый барьер экосистемы.
По данным IDC, в настоящее время более 95% мировых AI-моделей разрабатываются на основе экосистемы CUDA. Отечественным GPU при поддержке политики необходимо долгосрочное сотрудничество с промышленной цепочкой, а средствам массовой информации и рынку капитала необходимо проявить достаточное терпение.
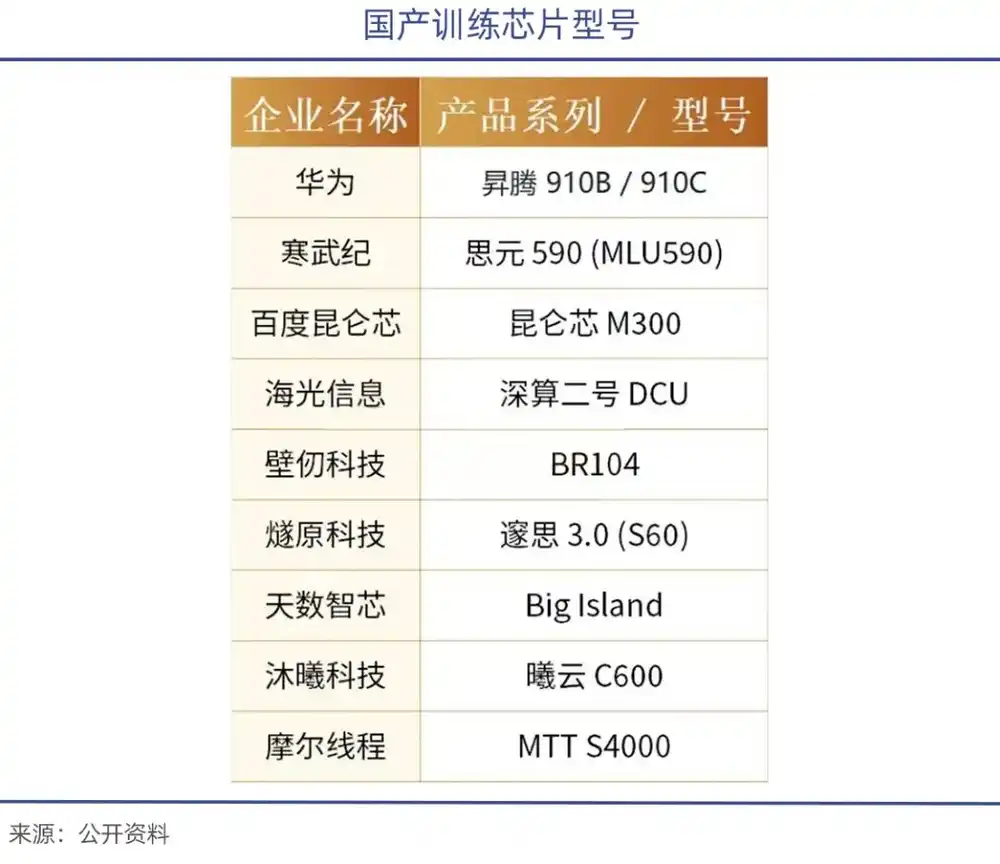
В январе этого года Zhipu совместно с Huawei открыли исходный код нового поколения модели генерации изображений GLM-Image; эта модель, основанная на оборудовании Huawei Ascend Atlas 800T A2 и AI-фреймворке Ascend MindSpore, завершила полный цикл от обработки данных до обучения модели, став первой SOTA-мультимодальной моделью, полностью обученной на отечественных чипах;
Moore Thread также совместно с Пекинской академией искусственного интеллекта (BAAI) завершила полный цикл обучения самостоятельно разработанной модели воплощенного интеллекта RoboBrain 2.5 на основе кластера интеллектуальных вычислений MTT S5000 и фреймворка FlagOS-Robo. Этот результат впервые подтвердил пригодность отечественных вычислительных кластеров для обучения больших моделей воплощенного интеллекта.
Видно, что отечественные GPU уже добились прорывов в совместимости и построении экосистемы и переходят от "точечных прорывов" в области вывода к "постепенной адаптации" в области обучения, что уже является значительным прогрессом.
Заключение
В целом, в условиях ограничений на импорт передовых зарубежных чипов можно "идти на двух ногах", сочетая западные и китайские технологии, одновременно уделяя приоритетное внимание поддержке отечественных вычислительных чипов для удовлетворения насущных рыночных потребностей.
Подлинность спроса не вызывает сомнений, "теория пузыря" все еще существует, но ее голос не становится все громче. Глобальный энтузиазм в отношении строительства ИИ уже превзошел ранние этапы развития любой другой отрасли в истории.
С начала этого года мировой рынок капитала снова переживает суперцикл ИИ; акции Samsung, SK Hynix, Broadcom, TSMC неоднократно достигали рекордных значений; на внутреннем рынке жесткие технологии, представленные такими компаниями, как Cambricon, также демонстрируют сильный рост, а рыночная капитализация гиганта оптических модулей InnoLight в какой-то момент превысила показатели Maotai.
Оглядываясь на историю развития полупроводниковой промышленности Южной Кореи, страна приложила общенациональные усилия для поддержки индустрии микросхем памяти, пережила самые темные времена и в конечном итоге победила Японию, став абсолютным лидером мировой индустрии памяти.
Будь то микросхемы памяти, микросхемы для мобильных телефонов или даже современные AI-чипы, Китай все еще находится на этапе догоняющего развития, и это отнюдь не дело одного дня. Но благодаря огромному рынку, постоянно появляющимся AI-талантам, мощному капиталу отечественные GPU уже начинают демонстрировать определенную совместимость и способны решить многие реальные потребности AI-компаний.
В этой партии по искусственному интеллекту, связанной с судьбой нации, Китай и США являются одновременно соперниками и партнерами, обладающими технологиями, рынками и ресурсами, в которых нуждается другая сторона.
Эта статья из официального аккаунта WeChat: Juchao WAVE , редактор: Ян Сюжань, автор: Се Цзэфэн, оригинальное название: "Проблемы вычислительной мощности в китайско-американской партии по искусственному интеллекту | Juchao"





