Kressey from the Aofeisi Quantum Bit | Official Account QbitAI
Just one week after DeepSeek open-sourced DSpark, it's been ported to Apple computers.
The ported version is called mlx-dspark, running the Gemma-4 12B and Qwen3-4B models.
After installation, the generation speed of these two models on Mac increased by 1.6x and 1.4x respectively.
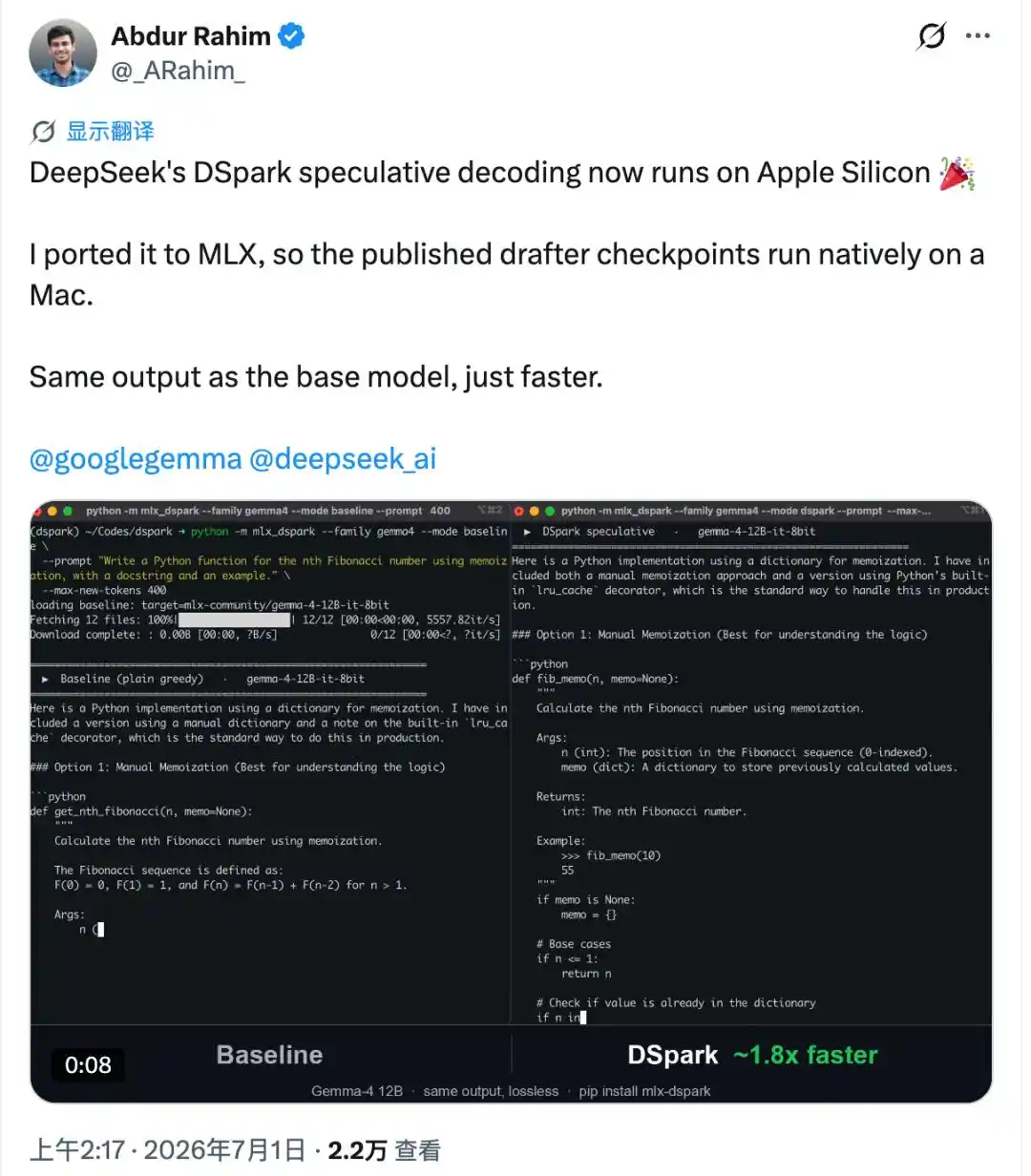
More importantly, it achieved something most ported versions can't — the output is byte-for-byte identical to the original model, not a single character off.
In other words, speed is gained without sacrificing any quality.
The person behind this is Abdur Rahim, an engineer who tinkers with open-source projects in his spare time. He single-handedly created the first native Mac version since DSpark was open-sourced.
Mac Running LLMs, Speed Boost of 60%
For DeepSeek's DSpark, open-sourced on June 27th, the official figures show a speed improvement of 60% to 85% in server-side scenarios.
However, this technology initially only had implementations for data center GPUs, with no version adapted for Apple Silicon.
mlx-dspark is the first native Apple Silicon version of this technology.

The idea behind DSpark is to pair a smaller model to assist the target model. The small model first generates several candidate tokens in one go, then the target model verifies them all at once, accepting the correct ones and rejecting the wrong ones for re-guessing.
The cost of this step differs between data centers and Apple computers.
On data center GPUs, verifying a batch of candidate tokens is more like chartering a bus—the fare is fixed regardless of the number of passengers. Since decoding is already memory-bound, verifying a few more tokens hardly adds any time.
Apple Silicon is more like a metered taxi—the more candidate tokens verified, the higher the meter runs.
Rahim tested it practically. For Gemma-4 12B, each additional token verified costs about 14 milliseconds. He calculated this into a cost model, concluding that the speed ceiling on Apple Silicon is around 2.2x.
In short, Rahim ported this assisting small model from HuggingFace's checkpoint and paired it with the target models Gemma-4 12B and Qwen3-4B.
He also rebuilt the verification process within the MLX framework and quantized the weights to 4-bit.

As a result, on the M4 Pro, compared to Apple's official MLX tool, Gemma-4 12B's generation speed increased from 18.4 tok/s to about 30 tok/s, about 1.6x the original; Qwen3-4B increased from 52.9 tok/s to about 73 tok/s, about 1.4x the original.
Additionally, in mlx-dspark, Rahim did something most porting work doesn't.
Ported Version, High-Fidelity Reproduction Possible
Most versions that port large models locally only support greedy decoding, meaning they pick the highest probability token at each step.
In mlx-dspark, Rahim implemented the temperature sampling method originally described in the DSpark paper. The draft model provides candidate tokens, and the acceptance probability is min(1, p/q), with unaccepted parts resampled from the residual.
He personally verified that the output from this process strictly equals the exact distribution the target model would give at the same temperature, not a discounted approximation.
Most speculative decoding implementations only do the greedy version because verifying the correctness of greedy mode is simple—just compare byte-by-byte.
The extra step Rahim took was personally checking the output distribution generated in sampling mode to confirm it wasn't distorted.
What precision the target model responsible for verification should be was a pitfall he figured out through trial.
If the small model was paired with a base target model without instruction fine-tuning, only 47% of the candidate tokens passed verification; switching to the corresponding instruction-tuned version increased this ratio to 82%.
He also tested switching the target model to bf16 precision. The increase in verification cost outweighed the increase in acceptance rate, making it slower, so leaving the target model at 8-bit by default is most cost-effective.
The small model responsible for generating candidate tokens uses a different precision.
The draft model itself was compressed by him. After 4-bit quantization, it's only 1.8GB, easily fitting into memory, and runs without loss.
The result is that DSpark not only achieved acceleration but also successfully reproduced the 16% to 18% acceptance rate improvement mentioned in the paper on the device.
DFlash Also Integrated, Faster on Code Tasks
After the tweet was posted, a comment appeared in the replies. Jian Chen, one of the authors of the DFlash paper, asked if they could try his team's model.
DFlash is another speculative decoding scheme proposed in a paper published by z-lab in May. The team lead author is Zhijian Liu, an assistant professor at UCSD and simultaneously a research scientist at NVIDIA.
DFlash's approach is different from DSpark. It uses a single parallel "block diffusion" to denoise an entire block of 16 tokens, rather than guessing step-by-step with dependencies like DSpark.
Rahim got to work quickly.
Using a porting script written by Jian himself, he connected the z-lab released gemma4-12B-it-DFlash to the Gemma-4 target model in mlx-vlm. On the same Mac, he ran another head-to-head comparison against the DSpark he just tested.
On code and math tasks, DFlash's block decoding acceptance length reached 5.95 to 6.20, speed about 36 tok/s, achieving about 2.1x, beating DSpark.
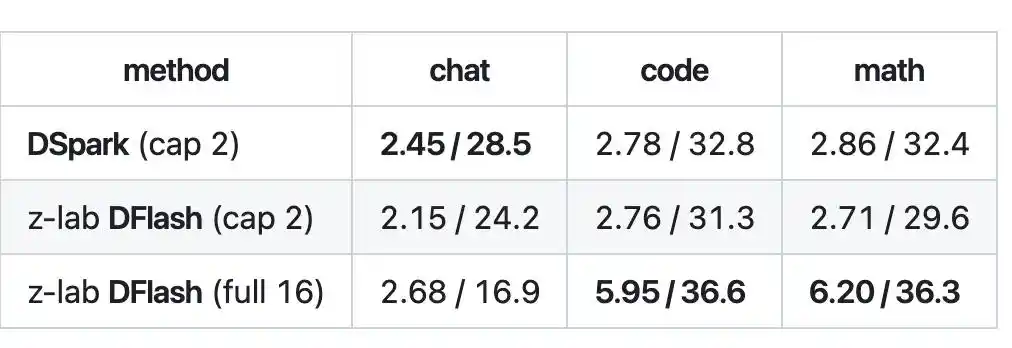
However, DFlash generates an entire block of 16 tokens at once, but the target model may not accept all of them. The portion that actually passes verification is only a part, referred to in the industry as the "acceptance length"—it's not always possible to fill all 16.
Therefore, in scenarios like open chat where content is unpredictable, the acceptance length doesn't increase, the block isn't fully utilized, and DFlash's advantage doesn't show.
DSpark's Markov head exists precisely to address this same issue. Parallel generation of an entire block of tokens means positions further back are calculated independently, making them prone to misalignment. The Markov head adds a layer of dependency between these positions specifically to correct this.
The result is, in chat scenarios, DSpark is actually faster than DFlash.
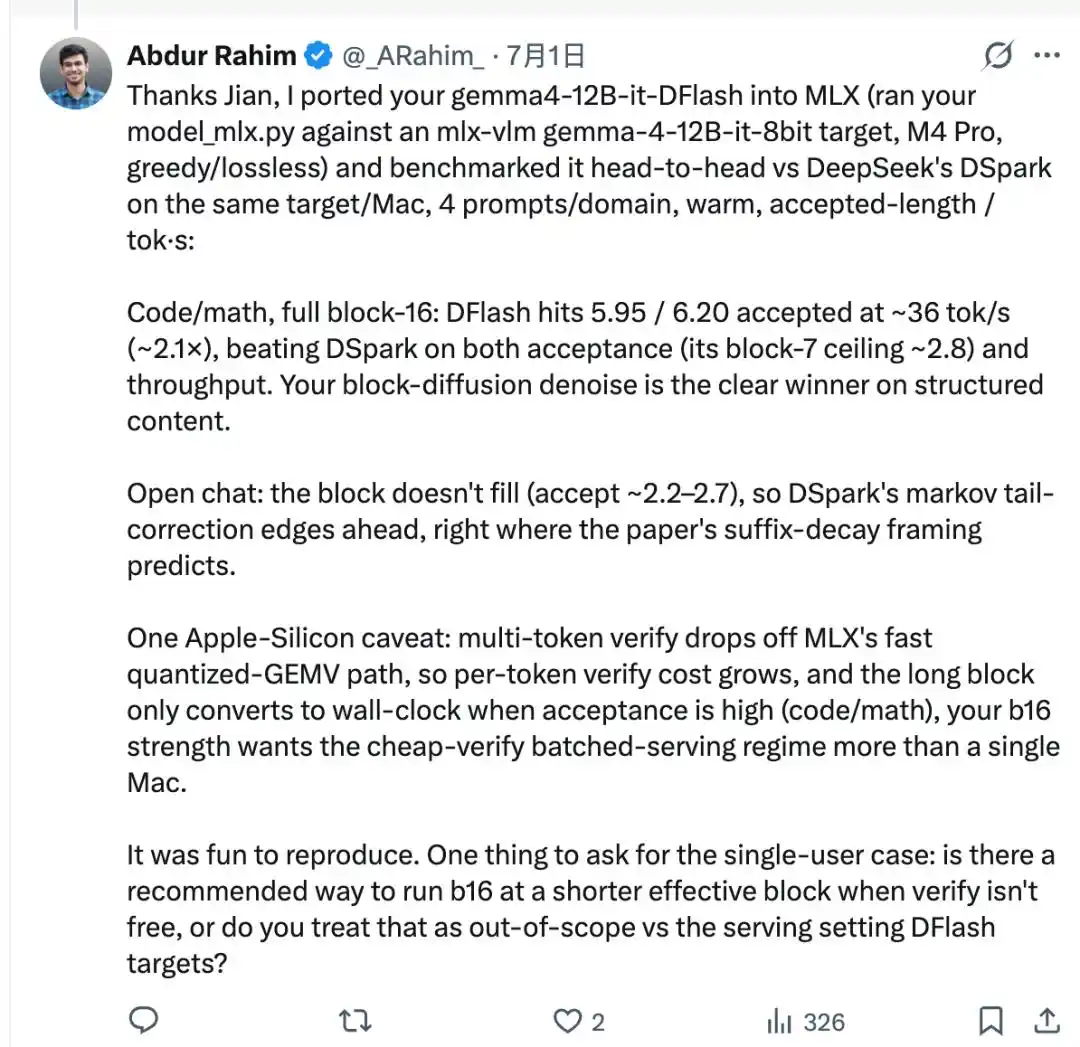
The subsequently updated mlx-dspark v0.0.3 officially integrated the z-lab original DFlash into the package, adding a parameter to manually shorten DFlash's effective block length—use short blocks for chat scenarios, and still use the full 16-token block for code and math scenarios.
After this, the same Mac, the same package, can handle both chat and code/math tasks, no longer needing to switch between the DSpark and DFlash projects.
Rahim said in his tweet that the same method should also work on larger Qwen3-8B and 14B draft models.
Reference Links:[1]https://x.com/_ARahim_/status/2072021710602432577[2]https://github.com/ARahim3/mlx-dspark
This article is from the official WeChat account "QbitAI", author: Focus on Frontier Technology






