撰文:Kunal
编译:Luffy,Foresight News
过去一年,我一直沉浸在加密推特(现在的 X 平台)中。在此,我想分享我认为对打造个人品牌品牌有用的一些想法。
TLDR:
-
保持真实:在这个充斥着 AI 生成内容的世界,真实最有力量
-
保持一致性:每天活跃,推特平台会奖励积极用户,打造个人品牌需要很长时间
-
善用数据:将互动量和曝光量作为反馈循环,在有效的内容上加大投入,摒弃无效内容
基础操作
-
立即开始发帖:每天至少 1 条推文,推特喜欢活跃用户,这能确保你的内容在走红时获得更多推送
-
开通高级订阅会员(这还用说吗,非高级会员在推特上就像 NPC 一样):最好是高级加强版,这样你可以撰写长文(比如本文),还能获得回复率提升
-
清晰的个人简介:包括当前职位、1-2 个过往职位和专业领域
-
头像:要么是精美的头像照,要么是 NFT,并且在不同平台保持一致
-
关注数与粉丝数的比例(关注的人要比粉丝少)
-
头像和封面图要在视觉上协调美观
-
如果你的项目有 Twitter 认证标识:为项目申请 Twitter 附属徽章(对品牌建设有好处,虽不会直接提升算法推荐)
-
置顶一条关于你正在打造的项目的推文
-
发帖内容不止于加密货币:偶尔分享你的喜好、日常观察等,不要把自己变成广告牌
-
团队魅力:鼓励整个团队发帖并互动,让你的团队和品牌账号放大你最优质的帖文
-
团队的品牌一致性:让你的项目在视觉上具有辨识度,比如相似的头像 / 视觉元素
Nillion 的眼罩标识
-
加入活跃的 NFT 社区:积累声望,使用热门 NFT 作为头像,参与社区互动
-
将表现好的推文在 6-8 小时后转发(出现在新的时区)
-
视频内容:如果你能创作短视频内容,这在加密推特上是个捷径;这里满是文字,视频内容的门槛很低。
-
在会议上分享你的推特账号:这能帮助你获得一些新粉丝,跳出当前的圈子
-
找到你的细分领域:你希望因某一项擅长的事被记住。
保持一致性
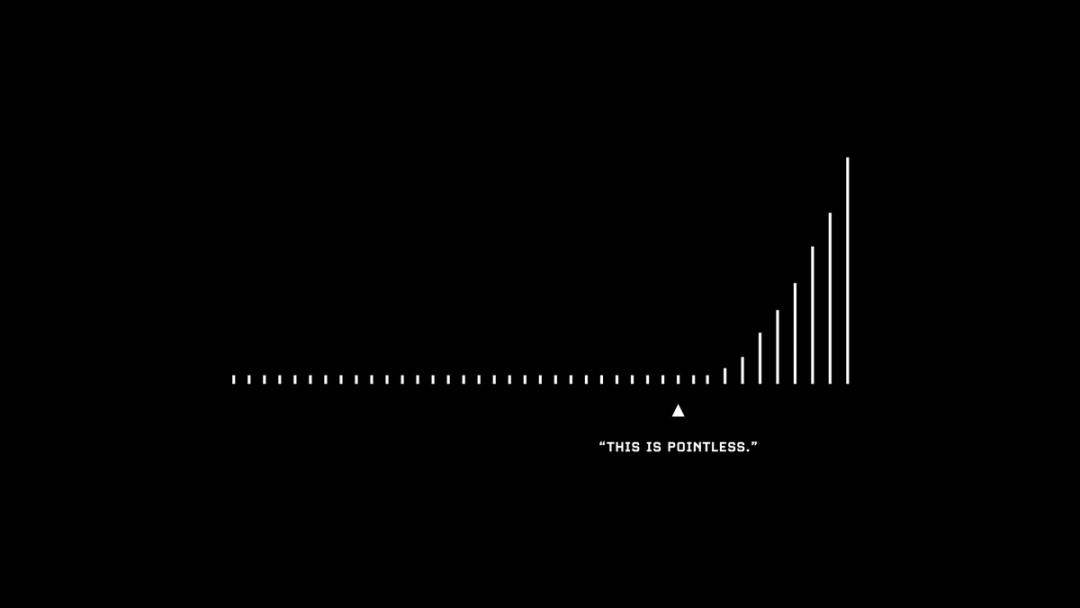
打造个人品牌需要时间。受众增长初期通常很缓慢,后期会加速。
不要成为 「推销员」
-
不要只发布关于自己项目的内容,不要变成广告牌,首先你要像个真实的人。
-
一个值得参考的比例是 4:1,在推特上,尤其是加密货币领域这种 「狂热」 群体中,每发 1 条推广内容,就要搭配 4 条有价值或有趣的内容。
-
推广时,要讲究技巧。没人在乎你在打造什么,他们在乎的是 「能用它做什么」,它能为他们带来什么价值?苹果推销 iPod 时,不会说 「512MB 内存」,而是说 「把 1000 首歌装进口袋」。
几个基础的算法技巧
-
不要用标签(拜托,现在不是 2012 年了)
-
第一条推文千万不要放链接,推特会大幅降低这类内容的优先级。如果需要,放在线程的第二条推文中。
-
尝试推特平台的新功能 :直播、文章、长文等。推特会优先推荐新格式的内容
成长框架(0 到 10 万粉丝)
这部分内容引用自推特用户@alexonchain
Level 1(0→100 粉丝):搭建基础
核心逻辑:冷启动阶段,先靠 「强关系 + 个人基础建设」 破冰。
关键动作:
-
撬动身边人脉(朋友、熟人),把 「0 粉丝」 这个尴尬数据打破,先有第一批 「种子用户」;
-
把个人资料(头像、简介、背景等)清晰化,让人一眼知道 「你是谁、能提供啥价值」;
-
别想着 「走捷径、搞大规模」,先参与小社群、输出价值、积累弱连接(比如在兴趣圈子里活跃),耐心等第一批粉丝攒起来。
Level 2(100→1000 粉丝):扩大社交圈
核心逻辑:从 「强关系」(朋友)拓展到 「弱关系」(同好、小博主),靠 「真实活跃 + 差异化」 圈粉。
关键动作:
-
保持 「真实、有趣、有料」 的状态,别装!平台上大家更愿意关注 「活生生的人」,不是刻板的 「人设」;
-
主动连接真正能支持你的人(比如同领域小博主、目标受众),别乱蹭,找 「价值观 / 兴趣匹配」 的;
-
去互动那些领域内的中小博主(不是头部大 V,而是和你粉丝量接近、内容优质的),互相借力;
-
找到自己的 「差异化」(比如别人写干货,你用故事讲干货;别人严肃,你幽默),慢慢让内容有记忆点。
Level 3(1000→10k 粉丝):用内容破圈
核心逻辑:基础盘稳了,开始靠 「优质内容 + 更大范围连接」 突破。
关键动作:
-
把精力往 「高质量、独特内容」 倾斜(比如深度干货、独家视角),让现有粉丝当 「传播燃料」(他们觉得好,会主动转发);
-
从 「互动中小博主」 升级到 「碰瓷大账号」(比如在大 V 评论区输出有价值观点、合作互动),借大 V 流量池曝光;
-
继续疯狂 「攒关系」,别停!不管是同领域创作者、潜在受众,多互动、多连接,关系网越密,传播路径越多;
-
内容、互动保持 「一致性」,别今天发美食、明天发科技,让粉丝对你的 「定位」 越来越清晰。
Level 4(10k→100k 粉丝):定义个人风格
核心逻辑:粉丝量变大后,「聚焦 + 拒绝水互动 + 创新内容形式」 才是长久之计。
关键动作:
-
all in「你真正感兴趣 + 数据验证有效的内容」(兴趣驱动才能持久,数据验证说明受众买单),别为了流量乱追热点、丢了自己;
-
拒绝 「低质量互动」(比如为凑数乱评论、买僵尸粉),这些会稀释你的 「个人特色」,让粉丝觉得你 「很水」;
-
创新内容形式(比如别人写图文,你做播客;别人搞直播,你做互动游戏),把 「独特内容」 变成个人品牌的 「护城河」。
Level 5(100k + 粉丝):保持初心与迭代
核心逻辑:粉丝量到顶流后,「别飘 + 持续创新 + 回馈粉丝」 是留存关键。
关键动作:
-
记住 「粉丝为啥关注你」(比如你一开始靠 「讲职场干货 + 真诚」 吸粉,别后来变成纯广告号),别丢了最初的 「价值锚点」;
-
永远别停在 「舒适区」,持续升级内容(比如从 「职场干货」 到 「职场资源对接」「行业趋势预判」),保持 「领域内最优质」 的竞争力;
-
别当 「高高在上的博主」,尽可能多和粉丝互动(比如翻牌评论、搞粉丝问答),让他们觉得 「你没变、还重视我们」,粘性才会高。
我该发些什么内容?
-
记录你打造公司的历程:公开建设
-
与用户交流 / 征求建议:例如 ,「你最喜欢的钱包体验是什么」,用你的推特做调研和用户反馈
-
创建定期系列:每周更新 / 本周完成了什么?重复能创造价值
-
讨论你对行业的愿景,而不仅仅是你的项目,展现思想领导力
-
你的内容要么有教育意义,要么能带来娱乐性,两者都能传递价值
好的,技巧很棒,但我该从哪里开始?
一些内容灵感
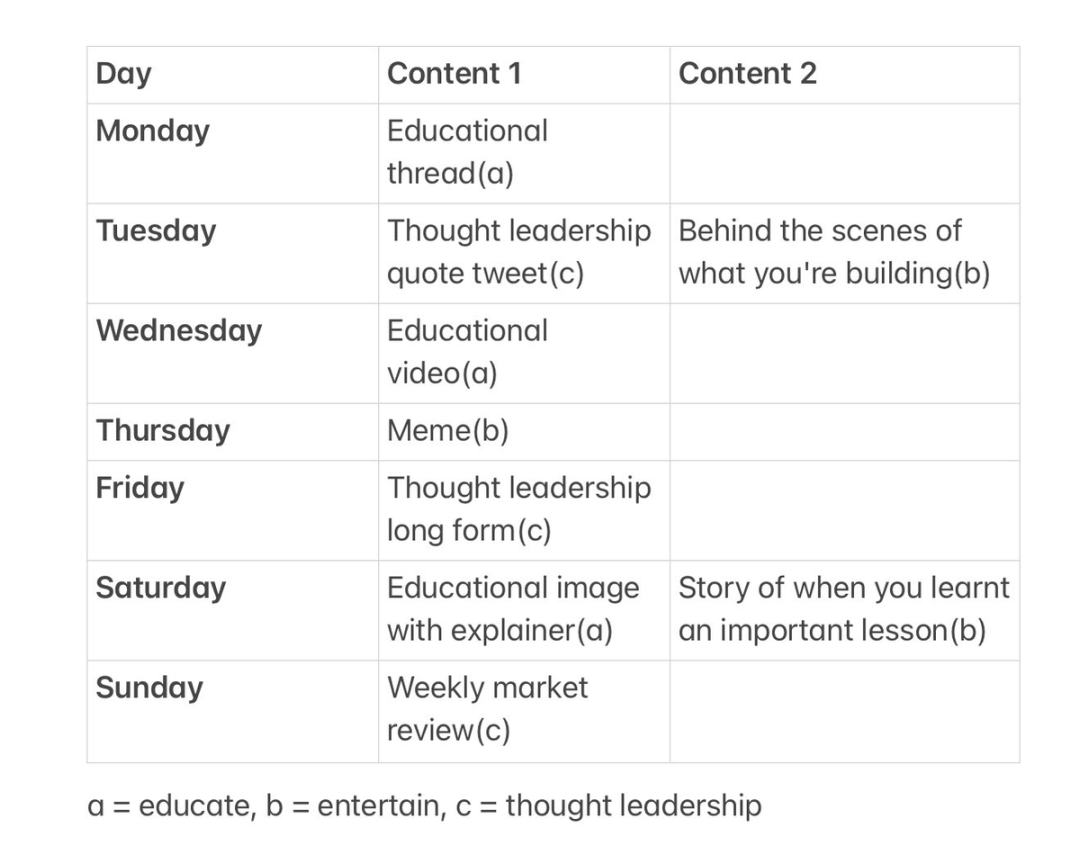
来源:@alexonchain
更多内容灵感
本部分内容引用自推特用@ishverduzco
你是谁?
-
你的故事是什么?
-
你是如何走到今天的?
-
你的爱好是什么?
-
你有什么痴迷的事物?
-
你的性格是怎样的?
-
你在网上的兴趣爱好是什么?
-
你最喜欢的创作者有哪些?
-
你普通的一天是怎样过的?
你在做什么工作?
-
你的公司是什么?
-
你在打造什么?
-
它为什么重要?
-
和你的团队一起工作是什么感觉?
-
有没有机会公开赞美你的团队?
-
有什么即将发布的产品或公司公告吗?
-
最近有没有达成什么里程碑,或者即将达成什么?
-
客户对你的产品有什么评价?
-
你的公司历程是怎样的?
你擅长什么?
-
有什么事你比大多数人做得好?
-
你是如何变得擅长这件事的?
-
你为什么会被它吸引?
-
你能向新手解释你所知道的吗?
-
你对当前趋势有什么大胆的看法吗?
-
在你的细分领域,你观察到了哪些别人没注意到的东西?
-
关于你的工作,你被问到最多的问题是什么?
-
关于你的工作,有什么误解吗?
积极回复
-
在打造账号的初期,回复优于发帖。当你与他人的推文互动时,你会更频繁地出现在他们的时间线上
-
使用推特列表与优质账号互动,减少噪音,每天积极回复他们
-
回复热门的推文,热门推文下的回复也能获得大量曝光
-
为你喜欢的顶级账号开启通知(可选,我个人讨厌通知)
-
一定要回复你推文中的评论,推特喜欢对话,会优化滚动体验
-
加入小团体(Telegram 聊天群),在群里分享你的推文,获得初始互动量助推
-
每天留出时间回复,用推特列表减少噪音
-
浏览时,收藏优质推文,作为自己创作内容的参考
数据分析
将数据分析作为反馈循环,重复使用并重新整理表现好的内容,摒弃表现差的内容
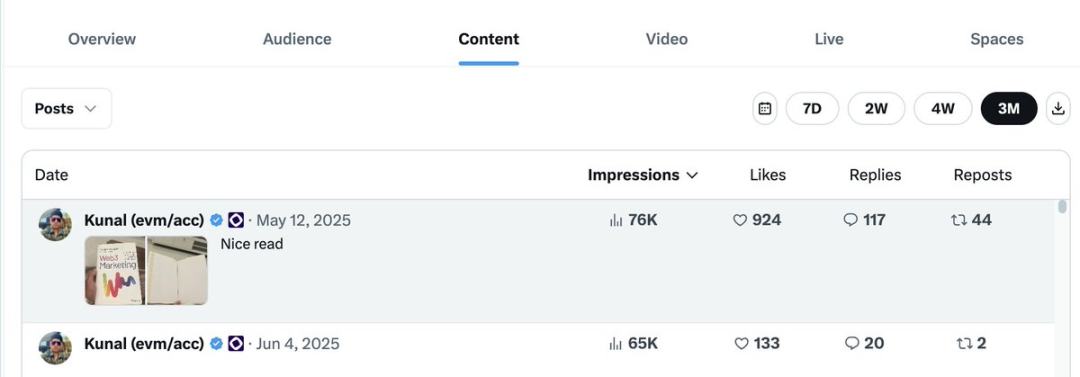
优化曝光量:更多曝光→更多个人主页访问→新粉丝
工具
-
Typefully:用于撰写草稿和排期
-
ChatGPT:用于获取推文灵感,或润色文字;但是用 AI 获取推文的框架,不要用它直接写内容





