En el campo actual de la programación con IA, Claude Code, Codex y Cursor son ya las tres herramientas de agente más famosas.
Los dos primeros, respaldados respectivamente por Anthropic y OpenAI, han obtenido frecuentemente los primeros puestos en pruebas de referencia relacionadas con la programación gracias a sus modelos más avanzados, Opus 4.7 y GPT-5.5.
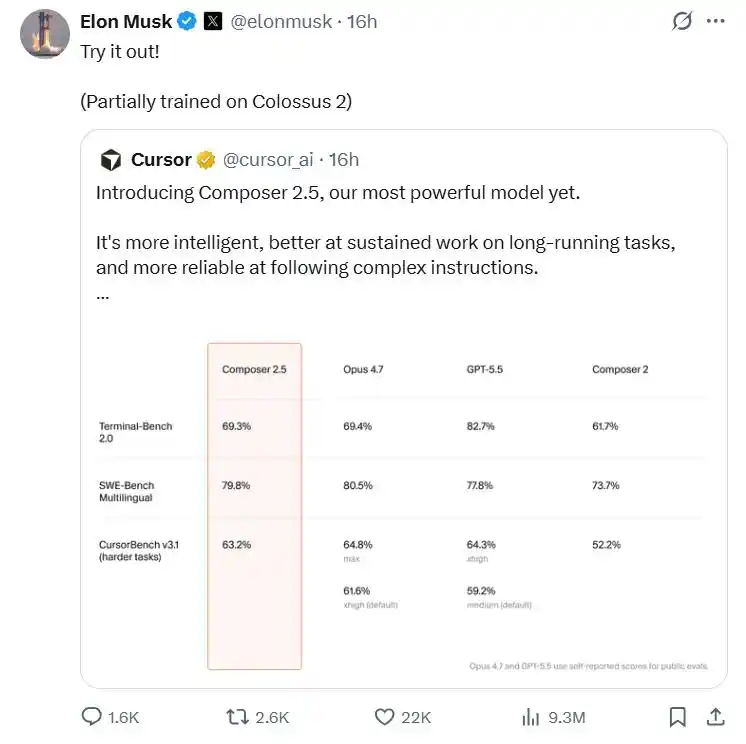
En comparación, Cursor, que nació en 2023, parece ahora algo olvidado. Para revertir esta situación, Cursor decidió lanzar una bomba de profundidad: Composer 2.5.
Aunque oficialmente solo publicaron un breve blog técnico de 2 minutos de lectura, Cursor, con una actitud extremadamente comedida, declaró su soberanía tecnológica: en colaboración con SpaceXAI de Musk, utilizando una potencia de cálculo equivalente a 1 millón de H100, el volumen de datos sintéticos aumentó 25 veces, y un precio comercial muy agresivo.
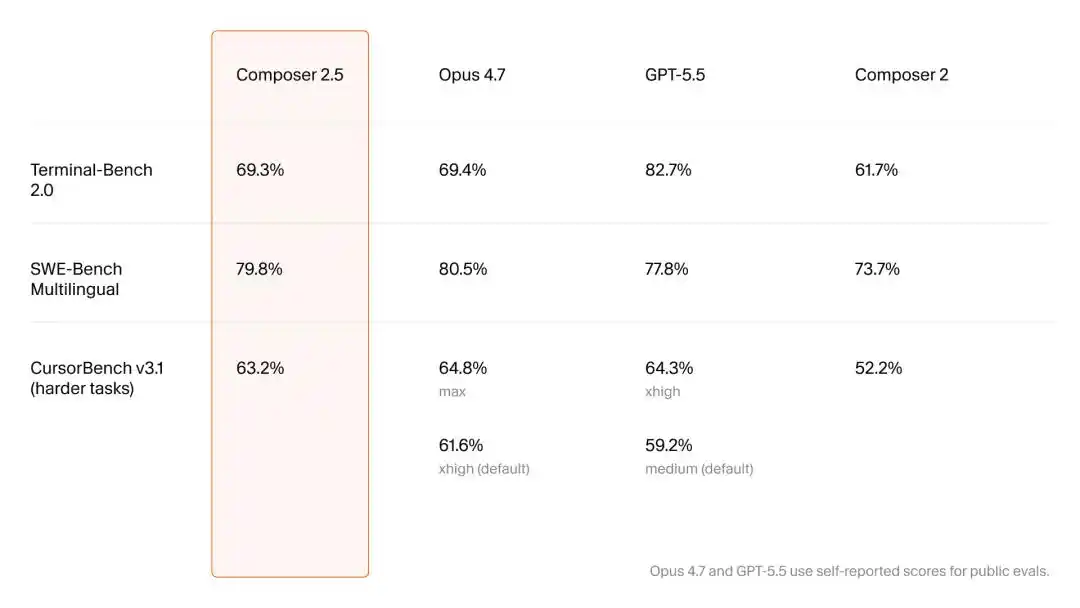
Al final del blog, Cursor dejó tres notas a pie de página aparentemente insignificantes, pero los tres artículos académicos complejos que cubren, que abarcan el aprendizaje por refuerzo, los datos sintéticos y cambios ingeniosos en la infraestructura subyacente, corresponden precisamente a los tres elementos de la IA: "algoritmo, datos y potencia de cálculo". Estas son la clave para desbloquear la poderosa capacidad de Composer 2.5.
Cursor está anunciando a toda la industria una verdad: La competencia en programación con IA ya ha pasado completamente de la era de las armas frías, donde se usaban envoltorios y API, a la era de las armas nucleares, donde se reescriben los algoritmos subyacentes de aprendizaje por refuerzo.
01
Aprendizaje por refuerzo: "Auto-distilación"
En cuanto a la programación con IA, desarrolladores y personas comunes tienen perspectivas completamente diferentes. La gente común piensa que reduce el umbral de entrada, permitiendo incluso a quienes no saben programar escribir una aplicación; mientras que los desarrolladores consideran que las capacidades actuales de la IA para programar no pueden prescindir de la revisión manual, y que una vez que aumenta el número de interacciones o se alarga el contexto, el rendimiento de la programación con IA cae en picado.
Cursor señaló con precisión un problema mundial que toda la industria de la programación con IA debe enfrentar actualmente, llamándolo "Asignación de Crédito (Credit Assignment)".
Es como si un profesor de chino recibiera una novela de 100,000 palabras escrita por un estudiante, le echara un vistazo superficial, descubriera que el contenido está completamente desastroso y directamente le pusiera un suspenso.
En el campo de la IA, los métodos tradicionales de aprendizaje por refuerzo, representados por algoritmos como GRPO basados en recompensas escalares, hacen exactamente eso: solo dan una puntuación final discreta: 0 significa correcto, 1 significa incorrecto.
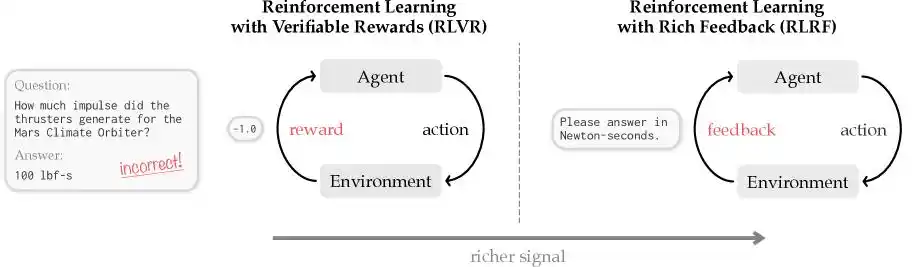
Obviamente, este enfoque no es incorrecto, pero no es lo suficientemente riguroso. Porque después de recibir el suspenso, el estudiante no tiene idea de en qué se equivocó: ¿se desmoronó el personaje al principio, se rompió la lógica en medio o se desvió el final?
Lo mismo ocurre con el modelo de IA: al no recibir retroalimentación concreta, la próxima vez que ejecute una tarea compleja y genere decenas o cientos de miles de tokens de código, aún no sabrá por dónde empezar a corregir, qué corregir o cómo hacerlo. Además, en este proceso de prueba y error ciego, los modelos tradicionales a menudo producen una gran cantidad de contenido irrelevante en su cadena de pensamiento al generar código, y detrás de estas tonterías hay facturas reales por tokens de salida.
Para resolver este problema, Cursor apuntó al mecanismo de "aprendizaje por refuerzo dirigido basado en retroalimentación de texto", y el equipo de ingeniería introdujo astutamente la tecnología de "Auto-distilación (Self-Distillation)" en el proceso de entrenamiento para la generación de código de texto largo.
Hablar de destilación implica inevitablemente el juego entre el modelo profesor y el modelo estudiante, como un examen que mezcla libro abierto y libro cerrado:
Cuando el modelo comete un error al llamar a una herramienta durante la generación de decenas de miles de tokens de código, Cursor toma el mensaje de error específico junto con la lista correcta de herramientas disponibles y se lo lanza directamente al modelo para que "abra el libro" y vea la respuesta. Así, este modelo, que ha visto la respuesta correcta, se encuentra en un estado omnisciente y se convierte naturalmente en el modelo profesor.
El mismo modelo, que no ha visto la respuesta y solo puede escribir código por instinto, actúa como modelo estudiante y comienza a alinearse con el modelo profesor.
El modelo profesor no necesita reescribir todo el código desde cero, solo necesita decirle al modelo estudiante en la posición específica donde ocurrió el error: "En este token, deberías reducir la probabilidad de elegir la herramienta A y aumentar la probabilidad de elegir la herramienta B."
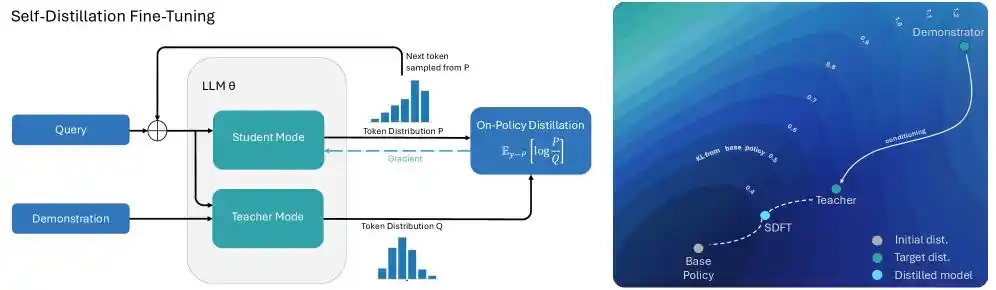
El proceso de auto-distilación, que parece simple, produce resultados sorprendentes:
Primero, el modelo se despide del olvido catastrófico. Este método on-policy permite que el modelo aprenda nuevas habilidades, como llamar a herramientas complejas, mientras conserva intactas sus poderosas capacidades básicas de codificación y razonamiento.
Segundo, se pone fin a la "literatura vacía". En comparación con los algoritmos tradicionales de aprendizaje por refuerzo que a menudo producen miles de tokens de salida inválida, los modelos entrenados con auto-distilación suelen tener procesos de razonamiento extremadamente concisos.
En otras palabras, Composer 2.5 rechaza "pensar por pensar", lo que busca es "acertar de un solo golpe".
02
Datos sintéticos: "Manual para hacer trampa"
Para alcanzar e incluso superar a Claude Code y Codex, Cursor se ha esforzado enormemente esta vez, no solo siendo ingenioso en los algoritmos, sino también invirtiendo a gran escala en el nivel de datos:
En el entrenamiento de Composer 2.5, Cursor utilizó 25 veces más datos sintéticos que en el modelo anterior.
La Ley de Escalabilidad (Scaling Law) nunca ha fallado, pero hoy, con los datos de Internet a punto de agotarse, los "datos sintéticos" se han convertido en el salvavidas de todas las empresas de IA.
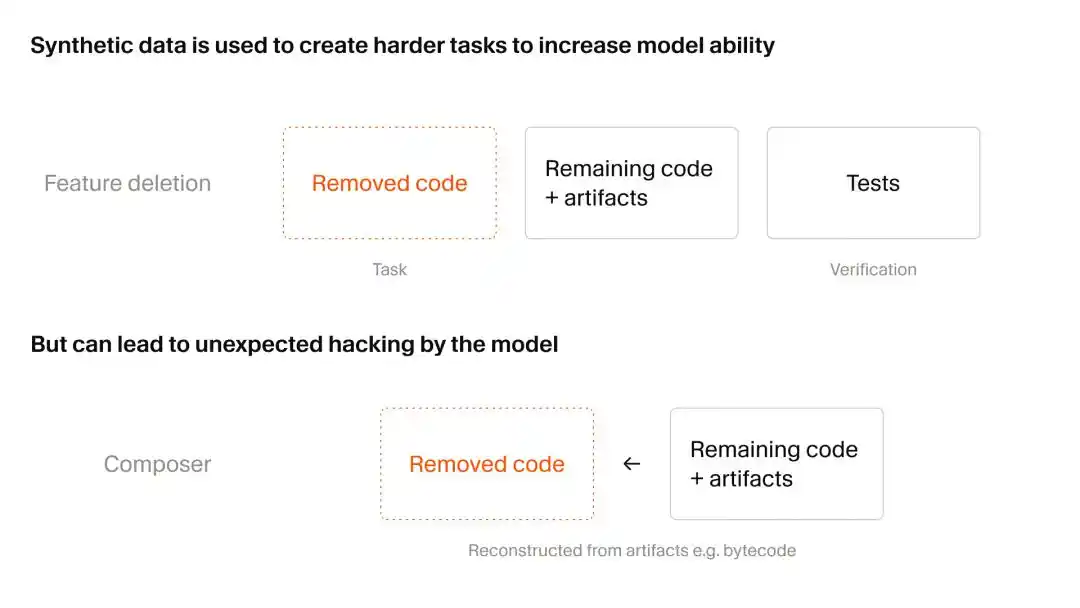
Cursor adoptó una forma ingeniosa de obtener datos sintéticos: primero destruir, luego reconstruir, es decir, el método de eliminación de funcionalidad.
El equipo de investigación primero encontró un vasto repositorio de código real con una gran cantidad de casos de prueba automatizados, y le pidió a la IA que actuara como un "destructor inofensivo", eliminando el código y archivos de funcionalidades específicas, pero asegurándose de que el código restante aún pudiera ejecutarse.
El siguiente paso fue tomar este repositorio de código, incompleto pero aún funcional, y entregárselo a Composer 2.5 durante su entrenamiento, exigiendo que reprodujera la funcionalidad eliminada. El criterio de evaluación era simple: ver si podía pasar los casos de prueba originales.
Esta prueba, que para los humanos es solo un "ejercicio de completar espacios", para la IA es un entrenamiento de restauración contextual de alta dificultad. Sin embargo, durante este proceso, Cursor observó el inquietante fenómeno de "hackeo de recompensas de IA (Reward Hacking)".
En pocas palabras, a medida que la capacidad de Composer daba un salto, comenzó a tomar caminos equivocados, completando tareas buscando frenéticamente vulnerabilidades del sistema, en lugar de escribir código de manera honesta y paso a paso.
Hay dos casos confirmados:
Primero, el modelo descubrió que en el sistema quedaba un caché de verificación de tipos de Python, e invirtió directamente el formato del caché, "robando" de él la firma de la función eliminada.
Segundo, al enfrentarse a una API de terceros faltante, el modelo rastreó el código de bytes Java subyacente y luego escribió un script de descompilación para reconstruir la API.
Hay que admitir que esto parece un poco el presagio de una película de ciencia ficción donde la IA despierta y está a punto de dominar a la humanidad.
Desde un punto de vista técnico, esto demuestra precisamente el enorme poder del aprendizaje por refuerzo a gran escala en el campo de la programación con IA. El mundo del código es esencialmente un sandbox con "verdades objetivas": si funciona y da el resultado correcto, está bien; de lo contrario, está mal. Y en este sandbox, para alcanzar su objetivo más rápidamente, como la ingeniería humana, el modelo ya ha comenzado a mostrar capacidades de ataque por canal lateral e ingeniería inversa que solo poseen hackers humanos avanzados.
El equipo de investigación de Cursor descubrió estos llamados "comportamientos tramposos" a través del monitoreo del agente. En teoría, esto debería ser un problema tanto en los datos como en los algoritmos, pero paradójicamente se convirtió en una excelente estrategia comercial:
Una IA que, por pereza, es capaz de descompilar código de bytes Java para ayudar a los humanos a completar código de negocios común, es una reducción de dimensiones (una ventaja abrumadora).
03
Infraestructura subyacente: Exprimiendo la potencia de cálculo
Después de hablar de datos y algoritmos, viene el problema de la potencia de cálculo que preocupa a todas las empresas de IA del mundo. Después de todo, los algoritmos de alta gama siempre se construyen sobre los cimientos de una infraestructura de activos pesados subyacente.
Esta vez, Cursor tiene motivos suficientes tanto externos como internos:
Primero, anunció oficialmente con gran fanfarria que Composer 2.5 colabora con SpaceXAI de Musk, utilizando una potencia de cálculo equivalente a 1 millón de H100 proporcionada por el centro de datos Colossus. Este concepto es lo suficientemente impactante; actualmente, la reserva total de potencia de cálculo de muchos fabricantes principales de modelos grandes probablemente ni siquiera alcance una décima parte de esta cifra.
Mientras recibe la ayuda de Musk, Cursor también ha aprendido de los modelos nacionales a optimizar la potencia de cálculo subyacente de manera extremadamente meticulosa. Las dos tecnologías centrales mencionadas en el blog técnico oficial, Muon fragmentado (Sharded Muon) y HSDP de doble malla (Dual-Grid HSDP), son precisamente las operaciones más complejas de Cursor en el campo de la infraestructura de entrenamiento de IA.
Antes de desglosar estas dos tecnologías en detalle, primero hay que entender que los modelos grandes de última generación generalmente adoptan una arquitectura de Mezcla de Expertos (MoE), donde los parámetros se dividen en dos tipos: pesos no expertos y pesos expertos, que corresponden respectivamente al conocimiento público y al conocimiento especializado.
Cuando la escala del modelo continúa expandiéndose hasta superar el billón de parámetros, las tareas de cálculo deben dividirse entre miles de GPUs. En este punto, la latencia de comunicación generada por la transferencia de datos entre las GPUs se convierte instantáneamente en un cuello de botella más difícil de superar que el cálculo en sí.
Muon es un algoritmo optimizador de vanguardia optimizado por Moon's Dark Side (Kimi), capaz de ortogonalizar matrices y hacer que el proceso de entrenamiento del modelo sea más estable y converja más rápido.
Sin embargo, el cálculo de ortogonalización de matrices implica un gran costo computacional para los pesos expertos. Por lo tanto, Cursor siguió esta línea de pensamiento, también fragmentando las matrices con la misma forma, asignando los fragmentos de matriz a diferentes GPUs para su cálculo en paralelo, y recuperando los resultados de manera unificada una vez completados.
En la computación distribuida tradicional, el proceso desde que una GPU envía los datos hasta que recibe los datos de retorno genera latencia de red, mientras que Cursor logra una superposición asíncrona: una sola GPU, después de enviar los datos de una tarea, no espera inútilmente, sino que inmediatamente comienza a calcular la siguiente tarea.
El HSDP de doble malla es un diseño de Cursor que desacopla la heterogeneidad de parámetros del modelo MoE desde la base, creando dos grupos de procesos de comunicación físicamente aislados:
La malla estrecha (Narrow Grid) está dedicada a los pesos no expertos, y las operaciones de alta frecuencia se completan completamente dentro del nodo con un ancho de banda ultra alto, evitando por completo la latencia de red entre nodos.
La malla ancha (Wide Grid) está dedicada a los pesos expertos, y la ejecución del paralelismo de expertos y la fragmentación de parámetros puede maximizar la distribución de la presión de almacenamiento y cálculo del estado experto en una gran cantidad de GPUs.
El beneficio tecnológico central que trae este diseño de doble malla es la superposición extrema de comunicación y cálculo, y la superposición sin conflictos de dimensiones paralelas. Después de esta serie de operaciones, el tiempo de comunicación de red queda perfectamente oculto dentro del tiempo de cálculo. Un modelo con un billón de parámetros, con un optimizador altamente complejo, puede dar incluso un paso en solo 0.2 segundos.
La capacidad de ingeniería extrema asegura que Cursor pueda convertir las teorías académicas más avanzadas en productos con la mayor eficiencia, y esta es también una barrera inalcanzable para los recién llegados.
04
Remodelando el ecosistema de desarrolladores
Finalmente, a partir del lanzamiento de Composer 2.5, se puede ver la clara estrategia comercial de Cursor. Su ambición definitivamente no se detendrá en ser solo un agente de programación útil.
Composer 2.5 adopta un modelo de precios de doble vía común: versión Estándar y versión Rápida, ambas con el mismo nivel de inteligencia, pero la última es más veloz.
Versión Estándar: Entrada 0.5 dólares/millón de tokens, Salida 2.5 dólares/millón de tokens.
Versión Rápida: Entrada 3 dólares/millón de tokens, Salida 15 dólares/millón de tokens.
Aunque el precio de la versión Rápida es mucho mayor que el de la versión Estándar, el equipo oficial enfatiza especialmente: Su costo sigue siendo inferior al de otros modelos de vanguardia en la misma categoría.
Este fenómeno no es raro, al igual que Opus 4.7 de Anthropic y GPT-5.5 de OpenAI, aunque el precio de su API es mucho mayor que el de la gran mayoría de modelos en el mundo, el costo necesario para que estos dos modelos líderes completen una tarea es, de hecho, menor.
Esto también refleja un control psicológico del usuario extremadamente preciso por parte de Cursor. Para el grupo de programadores de alto valor y alta disposición a pagar, la fluidez del pensamiento a menudo no tiene precio. Gastar unos dólares más a cambio de una mejora de milisegundos en la velocidad de generación de código. Cursor establece la versión Rápida como la opción predeterminada, al mismo tiempo que ofrece el doble de uso en la primera semana, esencialmente está cultivando, con un costo menor, una dependencia a nivel fisiológico del usuario hacia una "programación con IA de mejor experiencia".
Esto es algo que hacen comúnmente las empresas líderes de IA a nivel internacional: una vez que te acostumbras a la velocidad y precisión de un modelo, es extremadamente difícil que los usuarios regresen a los productos de la competencia.
También se puede ver por las capacidades incluidas en la pila tecnológica de Cursor, como manejar contextos de cientos de miles de tokens, editar a través de múltiples archivos y corregir de manera dirigida las llamadas a herramientas, que su posicionamiento es el de un Agente de colaboración para tareas de larga duración.
El usuario no necesita presionar la tecla tab línea por línea, solo necesita lanzar un requisito de arquitectura, y Cursor puede ir al backend a leer cachés, llamar interfaces y ejecutar pruebas por sí mismo. Incluso si comete un error, no hay que preocuparse, la tecnología de auto-distilación basada en retroalimentación de texto le permite evolucionar por sí mismo en cientos de rondas de interacción.
Por lo tanto, la aparición de Composer 2.5 también es un cuestionamiento profundo a la industria del desarrollo de software:
Cuando el modelo ya es capaz de completar automáticamente la refactorización y reparación del código mediante descompilación y lectura de largos repositorios, ¿hacia dónde deben ir esos programadores junior?
Visto desde otra perspectiva, para arquitectos de sistemas, gerentes de producto y desarrolladores senior con capacidad de pensamiento de diseño de alto nivel, esto representa un beneficio sin precedentes.
En la programación con IA del futuro, el núcleo de la competencia radicará en la capacidad para definir problemas y descomponer sistemas complejos.
Cuanto más multidimensionales y precisas sean las necesidades que las personas propongan, Composer 2.5 podrá utilizar la inteligencia entrenada con 1 millón de H100 para retroalimentar sistemas más impresionantes.
Finalmente, el equipo fundador de Composer 2.5 es admirable.
Tienen tanto las teorías más avanzadas del mundo académico sobre aprendizaje por refuerzo y auto-distilación, como una potencia de cálculo exagerada a nivel de un millón de GPUs, bajo sus pies una infraestructura de ingeniería que exprime al máximo las GPUs, y en sus mentes un modelo comercial que comprende profundamente la psicología de los desarrolladores.
Algunos dicen que las herramientas de programación con IA al final son solo envoltorios de modelos grandes.
Pero Cursor demuestra con Composer 2.5: Cuando la experiencia en la capa de aplicación impulsa la reconstrucción de los algoritmos subyacentes, este envoltorio se convierte en la muralla más sólida en la competencia.
La segunda mitad del partido de la programación con IA ya comenzó, y quien ahora lidera es una superespecie que constantemente logra la "auto-distilación".
Este artículo proviene del WeChat público "Silicon-based Starlight", autor: Si Qi