Lilian Weng has finally published a blog post after a three-year hiatus.
Just moments ago, a long-form article by former OpenAI Vice President Lilian Weng, delayed for over three years, went viral.
In this blog post titled "Scaling Laws, Carefully," she deconstructs Scaling Laws from start to finish—
The law on which the AI industry has bet tens of billions of dollars is far more fragile than anyone imagined.
One-Minute Summary: What This 10,000-Word Article Says
A single formula has governed the entire industry for five years. Scaling Laws state that "increasing model size, feeding more data, and scaling up compute will improve performance at a fixed rate." It turned AI from alchemy into a calculable business, indirectly directing the flow of hundreds of billions of dollars.
OpenAI and DeepMind gave opposite answers. For the same question of "how to allocate compute budget," OpenAI in 2020 said models should scale faster than data, while DeepMind in 2022 said both should scale proportionally. It was later discovered that the root of the divergence was a difference in parameter accounting plus insufficient experimental scale.
Even the winner's formula has bugs. DeepMind's optimal allocation ratio, copied industry-wide for two years, was found in 2024 during a line-by-line reproduction: the loss function used mean instead of sum, causing the optimizer to stop prematurely, and the output parameters were not the true optimum.
Applying patterns from small models to predict large models requires great caution. This curve was fitted on relatively small models; when extrapolated to trillion-parameter scale, a rounding difference can cause conclusions to diverge significantly. The blog includes an interactive simulator—drag the sliders to see it with your own eyes.
There's an even more fundamental issue: data is running out. The formula assumes infinite data supply, but high-quality text is finite. This is why the entire industry is collectively shifting towards reinforcement learning, test-time computation, and synthetic data.
One Straight Line, Hundreds of Billions of Dollars
As is well known, the core of Scaling Laws can be simply summarized in one sentence—
The larger the model, the more data, the more compute, the better the performance. And this "better" is not random; it follows precise mathematical laws.
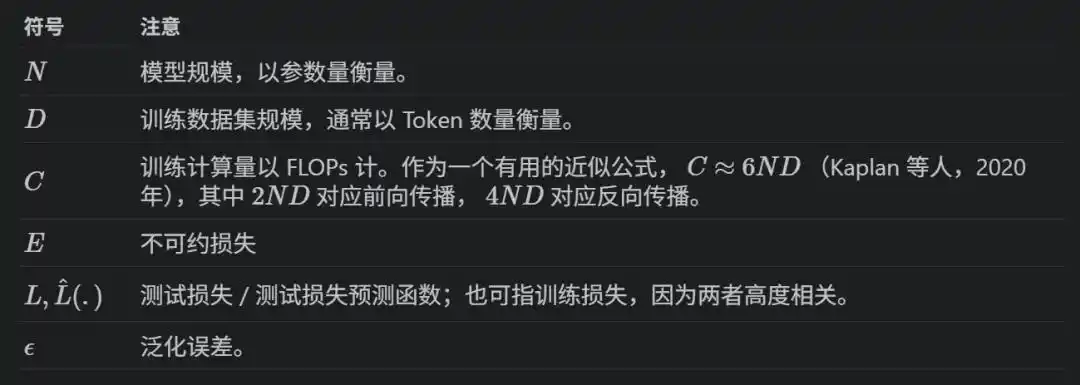
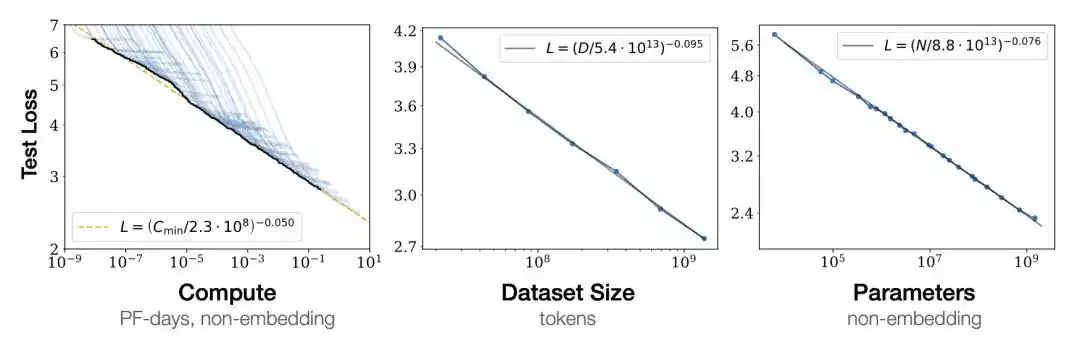
Plotting training loss on a log-log scale shows it decreases in a straight line as model parameter count N, data volume D, and compute C increase.
Written as a formula: L(x) = E + A/x^α, where x can be N, D, or C; E is the theoretical optimal loss (the entropy of the data itself); A and α are fitted constants.
Training a model with N parameters on D tokens requires total compute C ≈ 6ND—2ND for forward pass, 4ND for backward pass.
This straight line means performance gains are predictable.
Run a few small models first, fit the straight line, extrapolate to the right, and you can estimate the performance of a large model. No need to actually spend hundreds of millions training the large model to know if it works.
Before this, deep learning was often ridiculed as "alchemy"—knowing what works, but not why.
In 2020, OpenAI's Kaplan published this power law, pulling alchemy into the realm of "predictability" for the first time.
This is the confidence behind all large model companies' massive investments.
But on the most critical advice the formula gives—how to allocate compute budget between model and data—OpenAI and DeepMind gave opposite answers.
The Same Problem
OpenAI and DeepMind Produced Opposite Answers
The conclusion reached by OpenAI's Kaplan team in 2020 was: optimal model size N_opt ∝ C^0.73.
Translated: if compute increases 10x, allocate 5.5x to model and 1.8x to data—models should scale much faster than data.
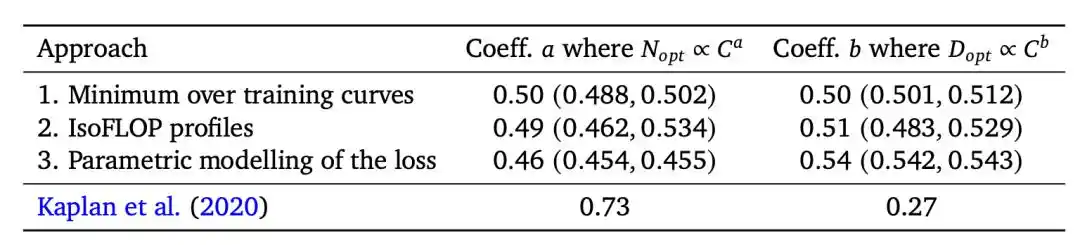
This directly guided GPT-3's training plan.
A 175-billion parameter model was fed only 300 billion tokens (a token is the smallest unit of text processed by a model, roughly 1-2 tokens per word).
By later standards, this was severely undertrained.
In 2022, DeepMind's Chinchilla team reached the opposite conclusion: N_opt ∝ C^0.50, models and data should scale proportionally.

Engineers later distilled it into an oft-quoted number: optimal token-to-parameter ratio is roughly 20:1.
Then DeepMind staged a head-to-head match.
Their Gopher: 280B parameters with 300B tokens. Chinchilla: 70B parameters with 1.4T tokens. Both models used the same compute.
Chinchilla dominated completely.
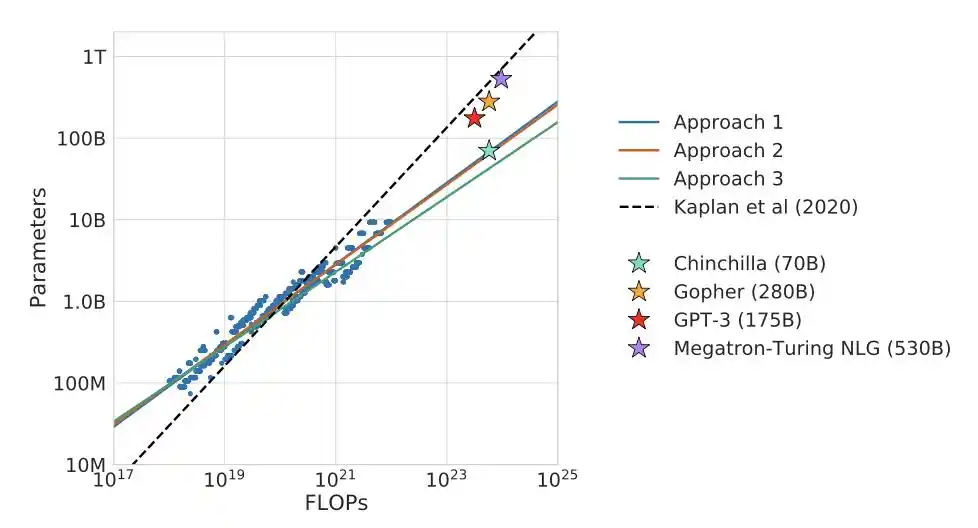
A smaller, well-fed model beat a larger, starved opponent.
Industry consensus flipped: from "scale up models" to "most models are undertrained."
0.73 vs 0.50, opposite answers to the same problem, would have you allocate your compute budget in two completely different directions.
The Reason Turned Out to be an "Accounting Problem"
In 2024, two researchers published a reconciliation paper in the top-tier machine learning journal TMLR, tracing this divergence to its root.
The conclusion is laughable.
First reason: they counted parameters differently.
Models have a type of parameter layer called embedding, responsible for converting text into numerical vectors the model understands. In small models, this layer constitutes a large proportion of total parameters—maybe one-third for models with tens of millions of parameters.
Kaplan excluded embedding when counting parameters; Chinchilla included it.
This single difference in parameter accounting was enough to distort the final fitted power-law exponent.
They gave a concise correction formula: N = N_\E + ω·N_\E^(1/3), where N_\E is parameter count without embedding, ω is a constant. For small models, the second term is large, embedding influence significant; as models grow larger, the second term approaches zero, and the two counting methods converge.
Second reason: Kaplan's experimental scale was too small.
Kaplan's largest tested model was only 1.5B parameters, while Chinchilla's experiments scanned up to over 16B. In log-log coordinates, tiny fitting deviations are magnified dramatically during extrapolation.
Using unified parameter accounting, they rederived Chinchilla's formula and discovered a key pattern—
The power-law exponent changes with compute scale. Within Kaplan's small-scale experimental range, the exponent was indeed close to 0.73; but as scale increased, the exponent converged to 0.50.
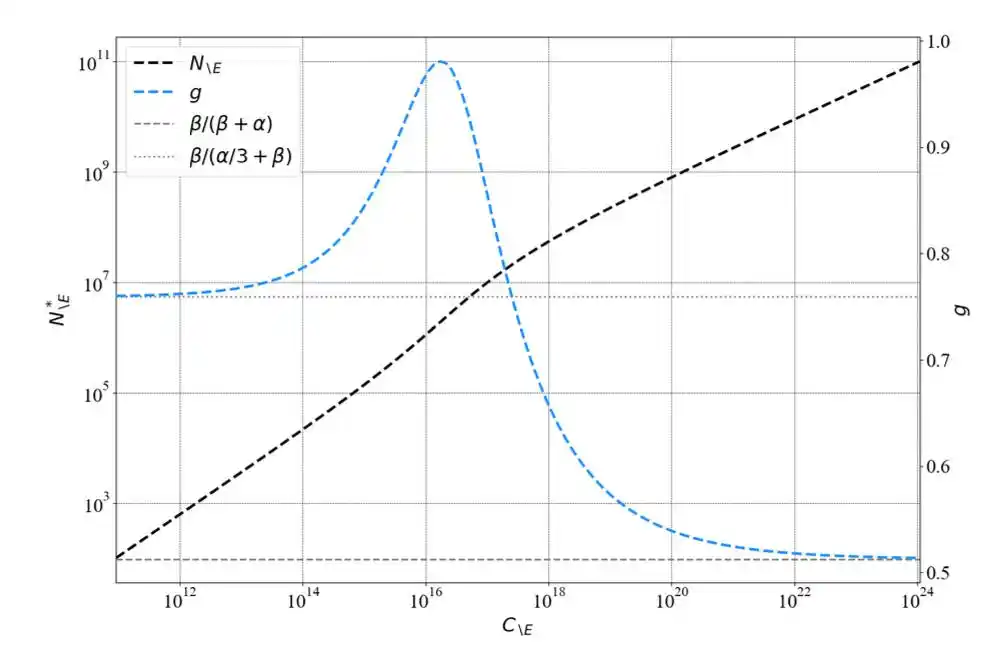
Kaplan wasn't "wrong"; he was correct within his experimental scope.
But he extrapolated a locally valid rule into a global conclusion.
An accounting issue of how to count parameters, plus insufficient experimental scale, led two top teams to give opposite resource allocation advice.
The entire industry adjusted training recipes based on this conclusion for two years.
Even the Winner Has Bugs
Kaplan was corrected by Chinchilla—that's the standard narrative everyone knows.
But Weng took a step further—Chinchilla's own methodology also has problems.
The Chinchilla paper used three independent methods to cross-validate its conclusion:
Method 1: Vary data volume with fixed model size
Method 2: Plot iso-compute curves (IsoFLOP profiles)
Method 3: Directly fit parameters to the loss formula L(N,D) = E + A/N^α + B/D^β
Three paths pointing to the same conclusion, seeming very robust.
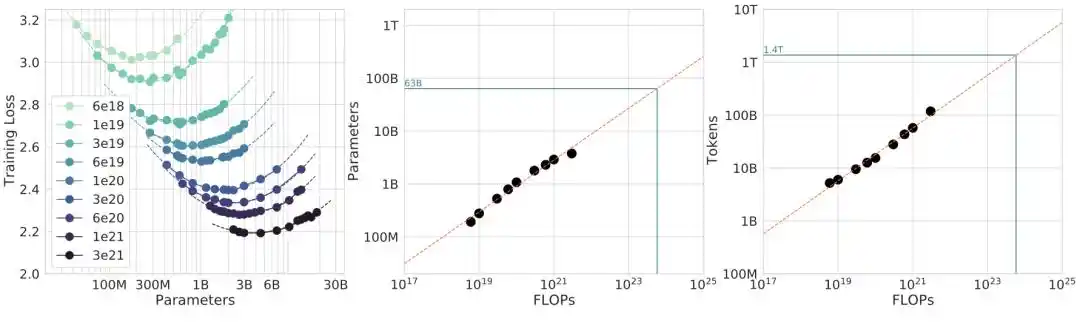
Method 3's mathematical derivation is especially elegant: Optimizing L(N,D) under constraint C ≈ 6ND yields a closed-form solution N_opt ∝ (C/6)^(β/(α+β)). When α ≈ β, the exponent is approximately 0.5, meaning models and data scale proportionally. That's the mathematical origin of 0.50.
In 2024, a team from AI research institute Epoch AI manually extracted raw data points from Chinchilla's paper charts and reran the fitting for Method 3.
Two bugs, each more astonishing than the last.
Bug 1: The loss function used mean instead of sum.
When fitting these five parameters, Chinchilla needed to minimize the gap between predicted loss and actual loss.
The complete optimization objective: min Σ Huber_δ(log L̂(Nᵢ,Dᵢ) − log Lᵢ), where Huber Loss is an outlier-insensitive loss function (δ = 10⁻³), paired with the L-BFGS-B optimizer to search for the optimum.
The problem lies in a detail: they took the mean (average) of Huber Loss per sample, not the sum. Averaging over a few hundred samples compressed the loss value to an extremely small magnitude.
The L-BFGS-B optimizer has a built-in convergence criterion. It stops automatically when the loss value is sufficiently small. Seeing such a tiny value, it mistakenly assumed convergence and stopped.
The optimizer never finished running. The output parameters were not the true optimum.
Bug 2: Key parameters were only kept to two decimal places.
In the Chinchilla paper, two core exponents controlling the power-law shape were retained only to two decimal places.
It seems like harmless rounding.
But when deriving other constants from these rough numbers, the error was amplified exponentially. The final confidence intervals were unreasonably narrow—narrow enough to require precision achievable only after over 600,000 experiments, while they actually ran fewer than 500.
A formula revered industry-wide for two years concealed a bug where the loss function didn't finish running.
Weng's blog also includes an interactive simulator with three sliders controlling loss precision, loss noise, and fitting range.
Each adjustment changes the fitted Scaling Law.
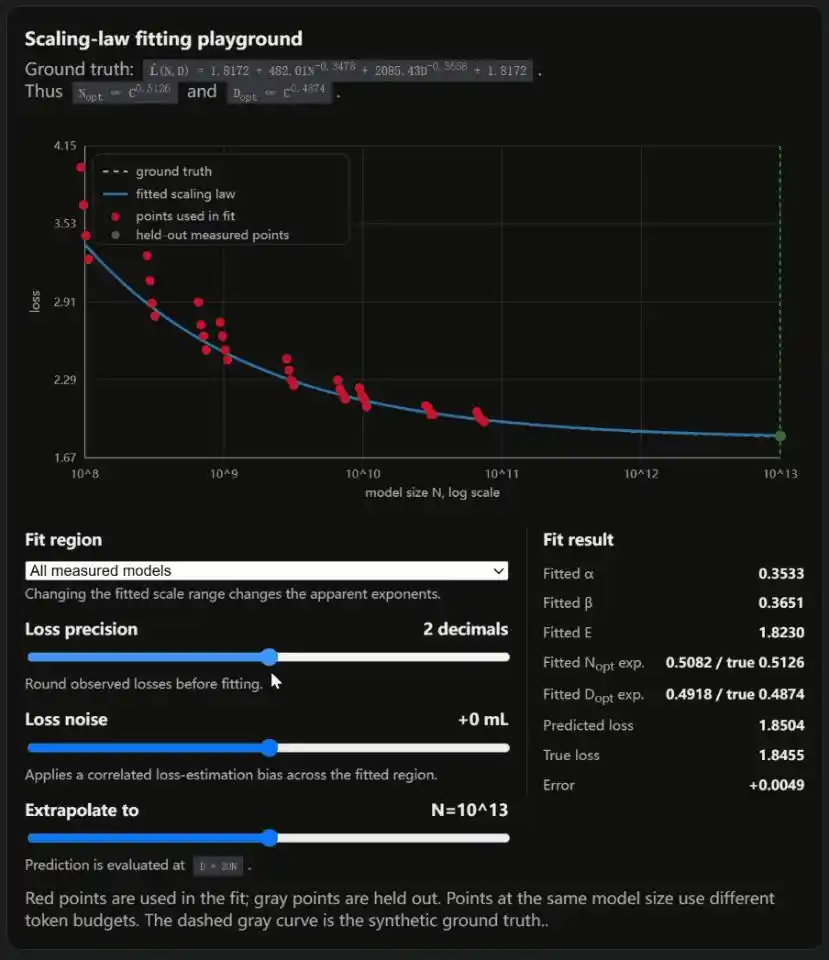
OpenAI's conclusion had local bias; DeepMind's conclusion had methodological flaws. In the AI industry's most important academic debate, both sides had cracks.
Data Is Running Out
The first three sections discussed problems with fitting methods—how to count parameters, how to calculate loss, how many decimal places to keep.
But even if all these problems were fixed, classic Scaling Laws have a more fundamental vulnerability—
They assume each training data point is unique, not repeated, not trained over multiple epochs, presuming you have infinite data.
Reality is, high-quality text data is projected to be exhausted by major labs between 2026 and 2028.
Repeated data training is inevitable; the premise of the classic formula is collapsing.
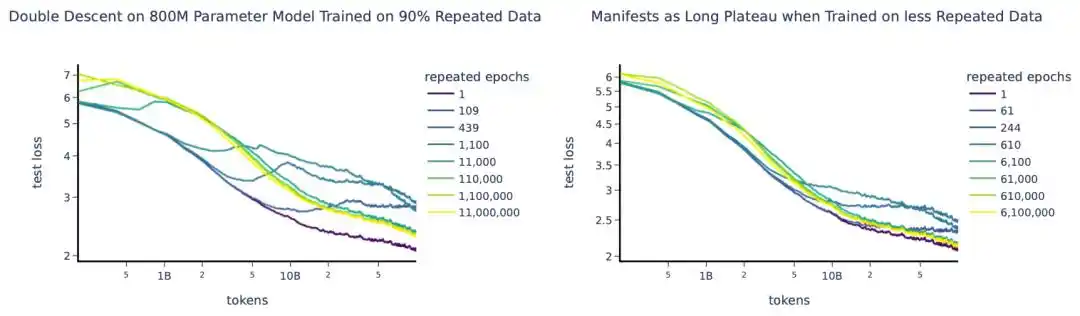
A large-scale experiment in 2023 trained about 400 models, from tens of millions to 9 billion parameters, with up to 1500 epochs of repeated training.
The core idea is to introduce the concept of "effective data volume" to replace actual data volume—
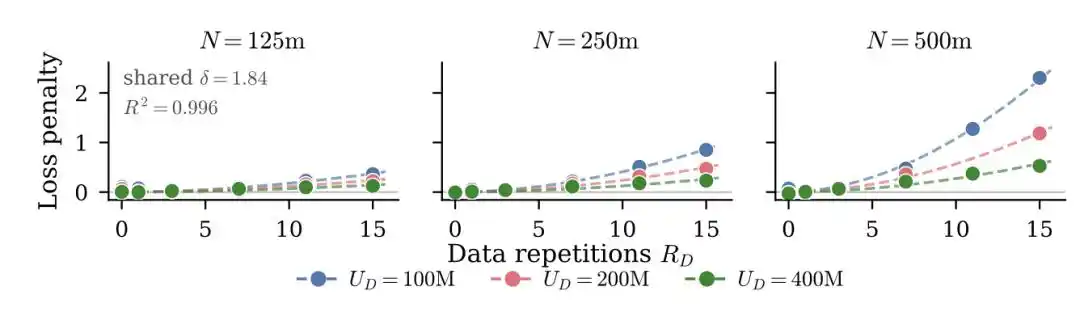
If you have U unique data points repeated R times, the effective data volume is not U×R, but converted via the exponential decay curve D_eff = U·(1 - e^(-R)). The first repetition still learns much new information; by the fifth, tenth repetition, marginal learning gains approach zero.
They also found a counterintuitive conclusion: excess parameters "depreciate" faster than repeated data. Meaning, with limited budget, running more training epochs is more cost-effective than enlarging the model.
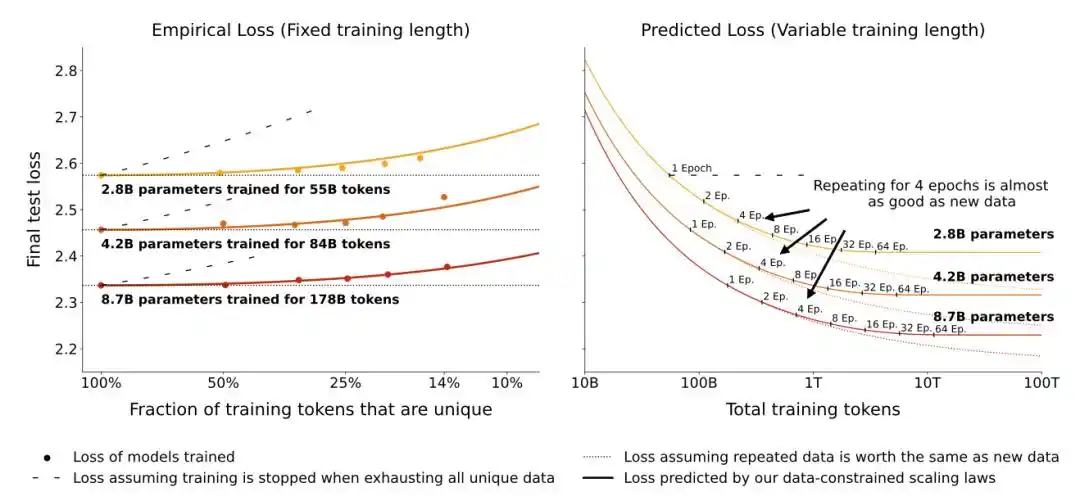
A new paper in May 2026 took a different approach.
They didn't convert to effective data volume; instead, they directly added an explicit overfitting penalty term to the classic loss formula—the more times a model sees the same data, the greater the penalty, and this penalty is tied to model size.
Their complete formula looks like this:
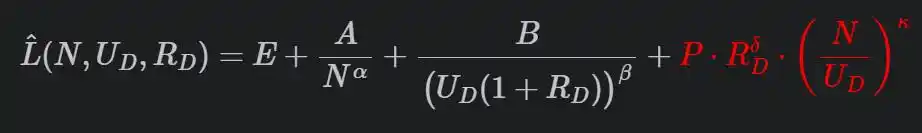
That last red penalty term is key.
R is repetition count, N/U is the ratio of model parameters to unique data volume (how "excessive" the model is relative to data), P, δ, κ are fitted from experiments. More repetitions, larger models, heavier penalty.
The paper's core finding: Large models are more sensitive to data repetition. Training the same data for 10 epochs, a 500M parameter model might still hold up, but a 5B parameter model's performance would degrade much more severely.
Another directly useful engineering finding: Increasing weight decay can significantly alleviate overfitting from repeated training.
This is also why from 2025 to 2026, the industry's attention collectively shifted to three paths to bypass the data wall—
Reinforcement learning: DeepSeek R1, OpenAI o-series, letting models self-play on verifiable tasks like math and programming to generate training signals.
Test-time computation: Not increasing training cost, letting models "think" a few more steps when answering questions to exchange for better performance.
Synthetic data: Using existing strong models to generate new data to train the next generation.
The subtext of all three paths is the same: The pure "scale-up" power law is no longer sufficient.
From Peking University to OpenAI to Her Own Company
Lilian Weng, undergraduate at Peking University, PhD from Indiana University Bloomington.
Interestingly, her PhD focus wasn't deep learning, but network science and complex systems, studying how information spreads in social networks.
After graduation, she first worked in data science at Dropbox, then at fintech company Affirm, before joining OpenAI in 2018.
At OpenAI, Weng's first project was robotics. She was a core contributor to Dactyl, the robotic hand that learned to solve a Rubik's Cube in two years.
Later, she moved to build the applied research team, and after GPT-4's release, was tasked with forming the Safety Systems team, which grew to over 80 scientists, engineers, and policy experts by the time she left.
In August 2024, her title was elevated to VP of Research and Safety; three months later, she announced her departure.

In 2017, soon after starting deep learning, Weng opened a personal blog called Lil'Log, initially just to organize her study notes.
She once said, "Explaining a concept clearly is the best way to test whether you truly understand it."
Nine years later, she's still writing—reinforcement learning, diffusion models, large model agents, each article starting from foundational principles, dozens of pages long with her own diagrams.
This blog later became one of the most cited personal technical blogs in AI, used directly as textbook material by many universities.
In February 2025, she and former OpenAI CTO Mira Murati founded Thinking Machines Lab, with co-founders including OpenAI co-founder John Schulman, former research VPs Barret Zoph and Luke Metz. a16z led a $2B seed round at a $12B valuation.
And while her company was advancing rapidly, she took time to finish this long-form article on Scaling Laws, delayed for three years.
The ChatGPT, Claude, and Gemini you use every day are all governed by these formulas deciding how to train the next generation.
How good the next-generation AI is won't depend on who has more GPUs, but on who handles these details with greater precision.
References:
https://x.com/lilianweng/status/2070237256070389897?s=20
https://lilianweng.github.io/posts/2026-06-24-scaling-laws/
This article is from WeChat public account "新智元" (New AI Era), author: ASI启示录, editor: Moses


![Assessing Sonic’s [S] 12% price drop and why more selling may be next](https://d1x7dwosqaosdj.cloudfront.net/images/2026-06/161e3d66eea4402796d2e6a66d93d453.jpg)





