Văn bản | AIDeepDive
Hôm nay, cổ phiếu "mô hình lớn toàn cầu đầu tiên" Trí Phổ (02513.HK) một lần nữa tăng mạnh.
Mức tăng trong ngày một lúc vượt quá 30%. Giá đóng cửa là 1282 HKD, mức tăng cả ngày vượt quá 26%, vốn hóa thị trường đạt 5715,7 tỷ HKD, một lần nữa lập mức cao kỷ lục mới.
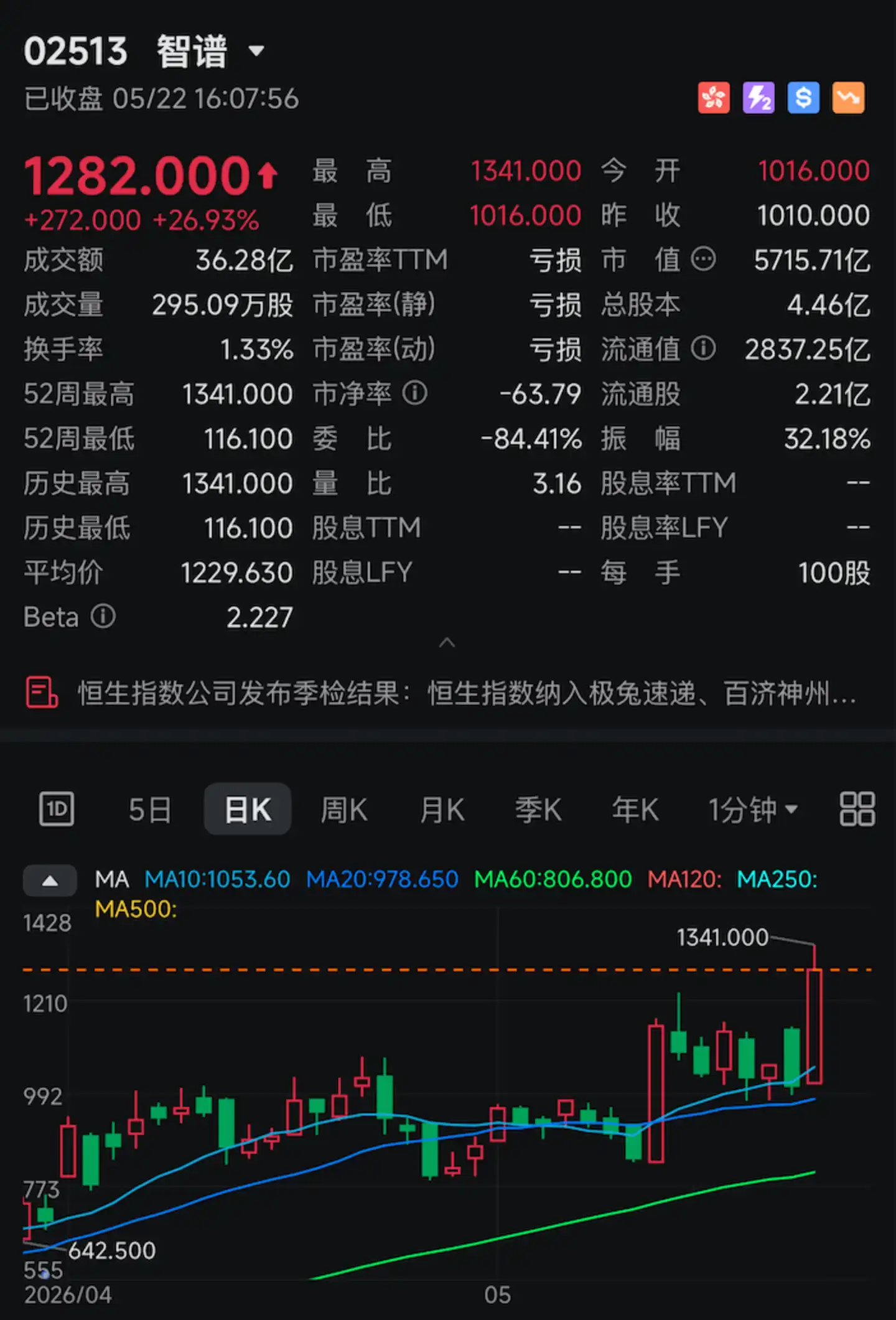
Yếu tố kích hoạt đợt tăng mạnh này là một chỉ số kỹ thuật cụ thể: 400 tokens/s.
Ngày 22 tháng 5, Trí Phổ chính thức mở API phiên bản tốc độ cao GLM-5.1 (GLM-5.1-highspeed) cho khách hàng doanh nghiệp, tham số cốt lõi quan trọng nhất chỉ có một: tốc độ đầu ra mô hình đạt 400 token mỗi giây, thiết lập giới hạn tốc độ API mới cho các nhà cung cấp mô hình lớn toàn cầu.
Ban đầu tôi nghĩ đây lại là một lần đóng gói PR của mô hình lớn Trung Quốc, nhưng sau khi xem kỹ chi tiết kỹ thuật, cuối cùng đã hiểu logic đằng sau thị trường vốn.
400 tokens/s là khái niệm gì?
Mô hình có thể tạo ra khoảng 200 chữ Hán mỗi giây, tương đương với sản lượng cao cường độ trong một phút của một nhà văn chuyên nghiệp, được nén vào trong một giây.
Khối lượng văn bản mà một người sáng tạo phải mất vài ngày liên tục ngồi viết mới xong, GLM-5.1 phiên bản tốc độ cao có thể hoàn thành trong vòng 1 phút; một nhiệm vụ tái cấu trúc hệ thống mà một kỹ sư phải cúi đầu làm trong 3 ngày, nó có thể chạy xong trong thời gian uống một tách cà phê.
01 Tốc độ, quan trọng hơn bạn nghĩ
Tốc độ, từ trước đến nay vẫn là chiều kích dễ bị bỏ qua nhất trong cuộc cạnh tranh mô hình AI.
Ba năm qua, cuộc chạy đua vũ trang mô hình lớn tập trung vào hai đường đua: quy mô tham số (mô hình lớn hơn, thông minh hơn) và cuộc chiến giá (Token rẻ hơn, phổ cập hơn). "Nhanh", chưa bao giờ là nhân vật chính.
Điều này là vì, "nhanh" trước đây thường được thực hiện bằng cách thu nhỏ tham số mô hình. Để tăng tốc, phải sử dụng mô hình nhỏ hơn và tinh gọn hơn, cái giá phải trả là khả năng bị thu hẹp.
Ý nghĩa của GLM-5.1 phiên bản tốc độ cao lần này là, trong khi giữ nguyên khả năng của kiến trúc cơ sở kích thước đầy đủ hàng đầu, nó đã đẩy tốc độ lên 400 tokens/s.
Cho dù là xét từ mô hình trong nước, hay xét từ phạm vi quốc tế, "khả năng hàng đầu" và "độ trễ cực thấp" lần đầu tiên đạt được mà không phải hy sinh.

Tại sao tốc độ lại quan trọng như vậy? Bởi vì chiến trường chính của AI đang xảy ra sự di chuyển cơ bản.
Khi AI từ ChatBot bước vào thời đại Agent, hỏi đáp không còn là cảnh chính của AI nữa, mà để Agent hoàn thành một nhiệm vụ, mô hình thường cần tự gọi hàng chục thậm chí hàng trăm lượt: viết mã, điều chỉnh giao diện, tìm kiếm thông tin, gọi công cụ…
Trong chế độ làm việc này, độ trễ giữa mỗi lượt gọi sẽ bị cộng dồn và phóng đại một cách tàn nhẫn. Một nhiệm vụ cần 50 lượt gọi, nếu mỗi lần tiết kiệm được 1 giây, toàn bộ nhiệm vụ sẽ nhanh hơn gần 1 phút. Đối với trợ lý lập trình AI, tương tác giọng nói, hệ thống ra quyết định kinh doanh, khoảng cách này có thể quyết định sống chết.
Từ góc độ sâu hơn, trong ngân sách thời gian cố định, suy luận nhanh hơn có nghĩa là mô hình có thể hoàn thành con đường suy luận sâu hơn, nhiều lượt tự xác minh hơn. Tốc độ, đang từ chỉ số hệ thống trở thành chính giới hạn thông minh.
02 Việc tốc độ, khó đến mức nào?
Vậy hiện tại trong ngành, trình độ về tốc độ khoảng nào?
Trong số các nhà sản xuất hàng đầu, GPT-4o của OpenAI khoảng 100–150 tokens/s, Claude Sonnet series của Anthropic khoảng 80–120 tokens/s, API mô hình hàng đầu chủ đạo trong nước phần lớn trong khoảng 50–100 tokens/s. 400 tokens/s là khoảng 3 đến 5 lần mức trung bình ngành.
Quan trọng hơn, khoảng cách này không phải chỉ cần đầu tư nhiều sức tính toán hơn là có thể bù đắp.
Một máy chủ được trang bị 8 card đồ họa H200, về lý thuyết mỗi giây có thể vận chuyển dữ liệu lên tới 38TB. Đối với GLM-5.1, mỗi lần tạo một token chỉ cần đọc khoảng 42GB tham số kích hoạt, suy đoán thuần lý thuyết, nên tiệm cận 1000 tokens/s.
Nhưng hệ thống thực tế thường chỉ chạy được vài chục tokens/s.
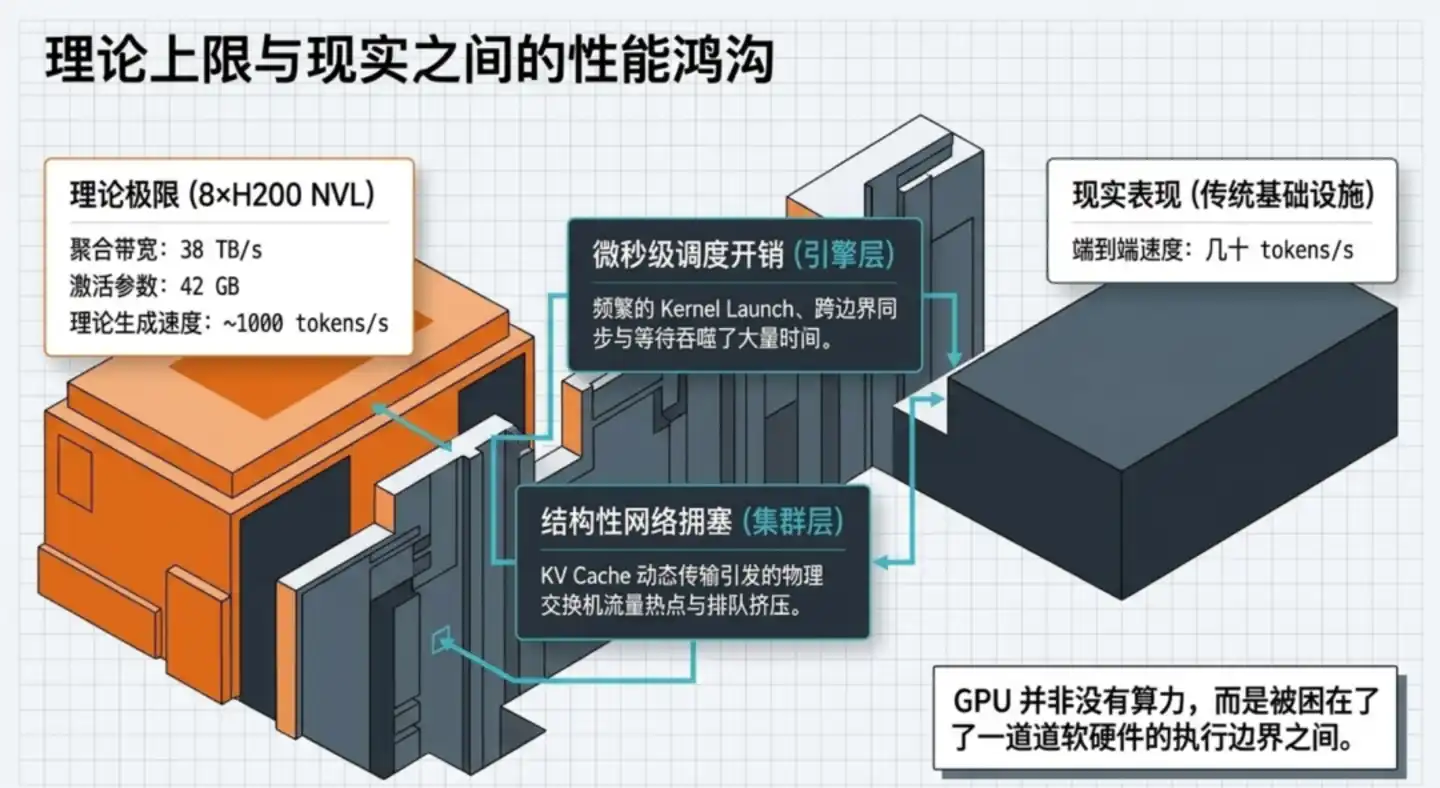
Đây là một hố sâu cách biệt một cấp số. GPU không phải không đủ nhanh, mà rất nhiều thời gian bị lãng phí vào việc chờ đợi, chạy không tải và điều phối vô hiệu.
Lần này Trí Phổ chính là sáng tạo đồng thời ở ba cấp độ: động cơ suy luận, chiến lược song song, kiến trúc mạng, đạt được bước đột phá về tốc độ cuối cùng.
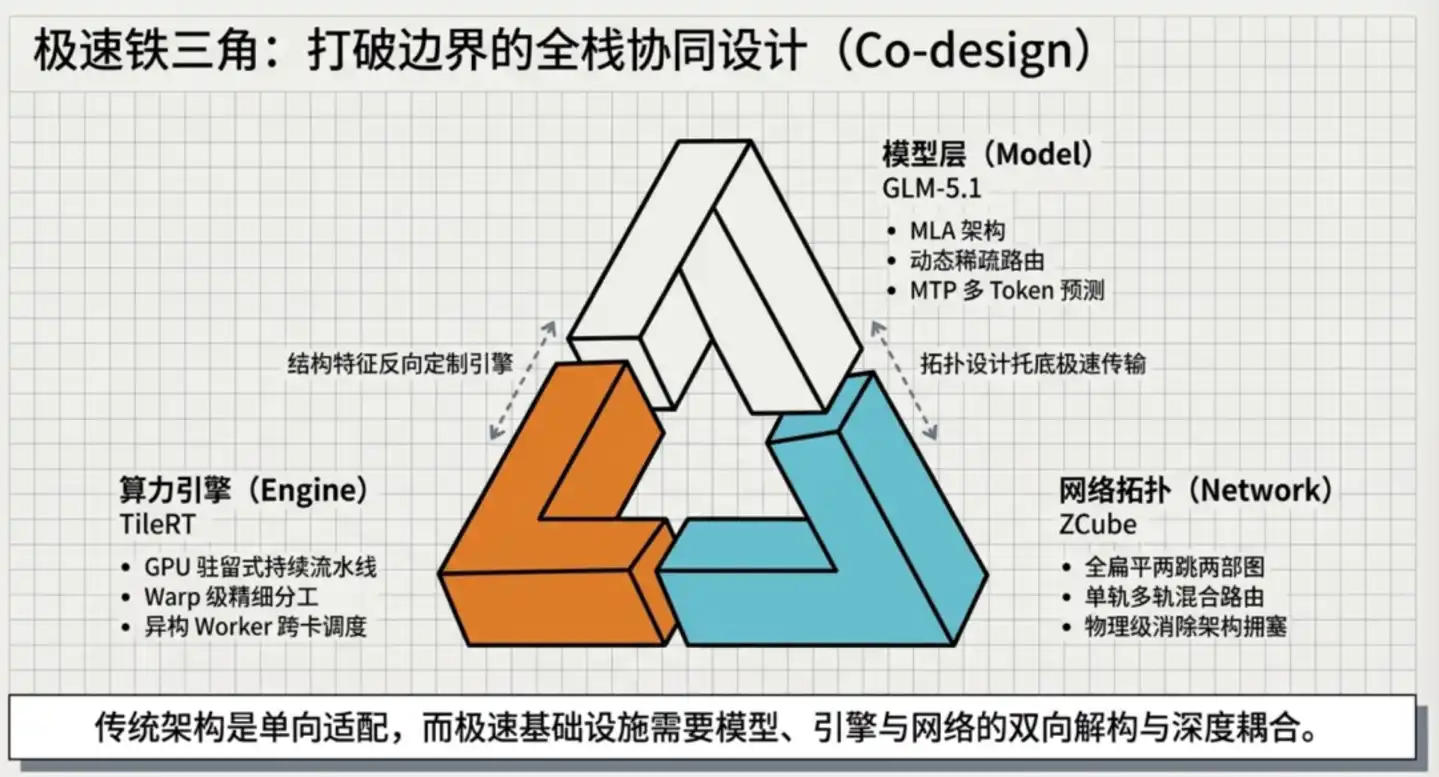
03 Ba lớp kỹ thuật chồng lên, tiệm cận giới hạn vật lý phần cứng
Mô hình lớn ban đầu vận hành như thế này, mô hình lớn được phân giải thành từng toán tử độc lập, mỗi toán tử khởi động một lõi tính toán (kernel) riêng, tính toán xong thì dừng, đồng bộ chờ đợi, rồi khởi động tiếp theo.
Ở giai đoạn huấn luyện, mỗi lần tính toán động đến vài giây thậm chí vài phút, chi phí khởi động và chờ đợi này hoàn toàn có thể bỏ qua. Nhưng khi suy luận, mỗi lần tạo một token, một bước then chốt nào đó có thể chỉ cần vài chục micro giây, chi phí khởi động và chờ đợi trở nên tương đối không thể bỏ qua.
Ý tưởng cốt lõi của TileRT: Biên dịch toàn bộ mô hình thành một động cơ chạy liên tục, khởi động một lần, không bao giờ dừng.
TileRT ở giai đoạn biên dịch mã sớm mở rộng tĩnh tất cả logic tính toán của mô hình thành một dây chuyền liên tục, khi chạy GPU luôn duy trì vận hành tốc độ cao, tính toán, vận chuyển dữ liệu, truyền thông tiến hành song song, kết quả trung gian cố gắng lưu lại trong bộ nhớ đệm tốc độ cao bên trong GPU, không còn ghi lại bộ nhớ chậm rồi đọc lại nhiều lần.
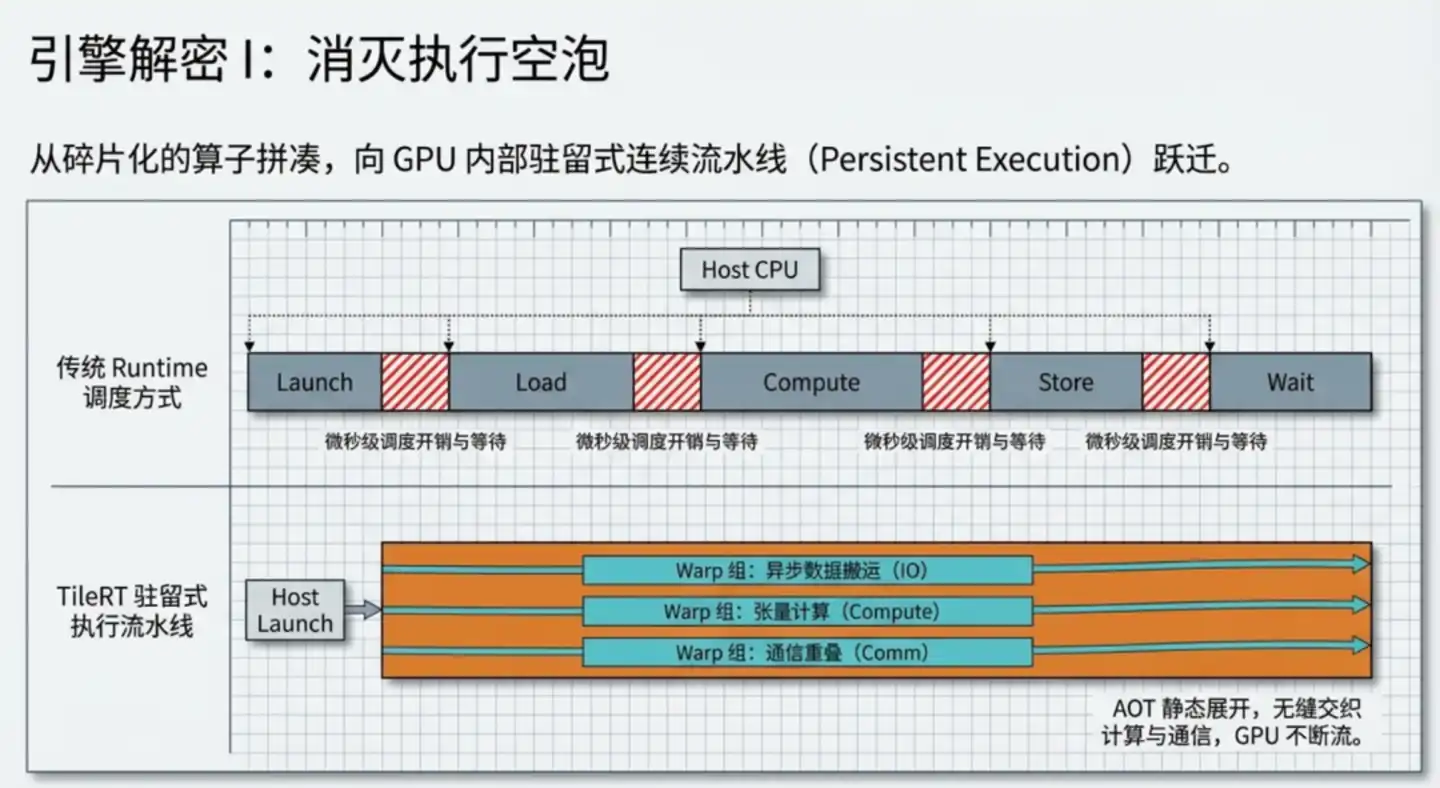
Ở đây có một chi tiết thiết kế then chốt: Warp chuyên môn hóa.
Để hiểu Warp, cần hiểu cách làm việc của GPU. Điểm khác biệt lớn nhất giữa GPU và CPU là bên trong nó có hàng ngàn đơn vị tính toán tương đối đơn giản, những đơn vị này 32 cái thành một nhóm bó lại với nhau, nhóm này gọi là Warp.
32 đơn vị trong cùng một Warp phải luôn đồng bộ hành động, thực thi cùng một lệnh, giống như một tiểu đội trong quân đội, tiểu đội trưởng ra lệnh tất cả cùng làm một động tác.
Trong khung truyền thống, tất cả Warp thực thi cùng một chuỗi lệnh; TileRT để các nhóm Warp khác nhau đảm nhận trách nhiệm khác nhau: một phần chuyên trách vận chuyển dữ liệu tiếp theo vào trước, một phần chuyên trách tính toán toán học, một phần chuyên trách truyền thông với GPU khác. Ba nhóm người cùng làm việc, phối hợp dây chuyền, không chờ đợi nhau.
Giống như từ "một công nhân vận chuyển gạch, xây tường, nghiệm thu làm tuần tự", trở thành "nhóm vận chuyển gạch, nhóm xây tường, nhóm nghiệm thu cùng quay".
Hiệu suất bên trong một card giải quyết rồi, song song nhiều card lại có thách thức mới.
Cách làm thông dụng ngành là song song tensor (Tensor Parallel): Chia ma trận trọng số của mô hình thành một số phần, mỗi GPU phụ trách một phần, sau khi tính toán xong thì tổng hợp kết quả thông qua kết nối tốc độ cao (NVLink).
Giải pháp này đối với loại tính toán dày đặc quy tắc như nhân ma trận rất hiệu quả, hiện là giải pháp đa card tiêu chuẩn cho hầu hết khung suy luận mô hình lớn.
GLM-5.1 sử dụng **MLA (Multi-head Latent Attention, cơ chế chú ý tiềm ẩn đa đầu), đây là một cơ chế chú ý do DeepSeek đề xuất.
Cơ chế chú ý truyền thống cần lưu trữ đầy đủ một lượng lớn dữ liệu trung gian (KV Cache) của mỗi bước tính toán để dùng, rất hao bộ nhớ; cách làm của MLA là nén trước những dữ liệu trung gian này thành một "vectơ tiềm ẩn" nhỏ gọn để lưu, khi dùng thì mở ra khôi phục, nhu cầu bộ nhớ giảm mạnh, hiệu suất suy luận cao hơn.
Nhưng trong quy trình tính toán của MLA có một khâu đặc biệt: cần làm chỉ mục thưa thớt từ một lượng lớn thông tin lịch sử: tương tự như trong một thư viện khổng lồ trước tiên nhanh chóng tìm ra mấy quyển sách liên quan nhất, rồi đọc kỹ mấy quyển sách đó.
Bước "tìm sách" này phụ thuộc thông tin toàn cục, không phù hợp để chia đều nhiều card; "đọc kỹ" mới là tính toán dày đặc phù hợp song song nhiều card. Nếu cưỡng ép tất cả 8 GPU đều tham gia "tìm sách", nhiều thời gian sẽ bị lãng phí vào truyền thông đồng bộ giữa các GPU.
Giải pháp của TileRT là để GPU chạy dị thể: GPU 0 chuyên đảm nhận "nhân viên tra cứu thư viện", phụ trách chỉ mục thưa thớt và quyết định định tuyến; GPU 1–7 đảm nhận "nhân viên phân tích đọc kỹ", phụ trách tính toán chú ý dày đặc và tính toán ma trận. Hai loại người làm việc mỗi loại sử dụng chiến lược song song phù hợp nhất với mình để phối hợp hoàn thành toàn bộ lớp tính toán.
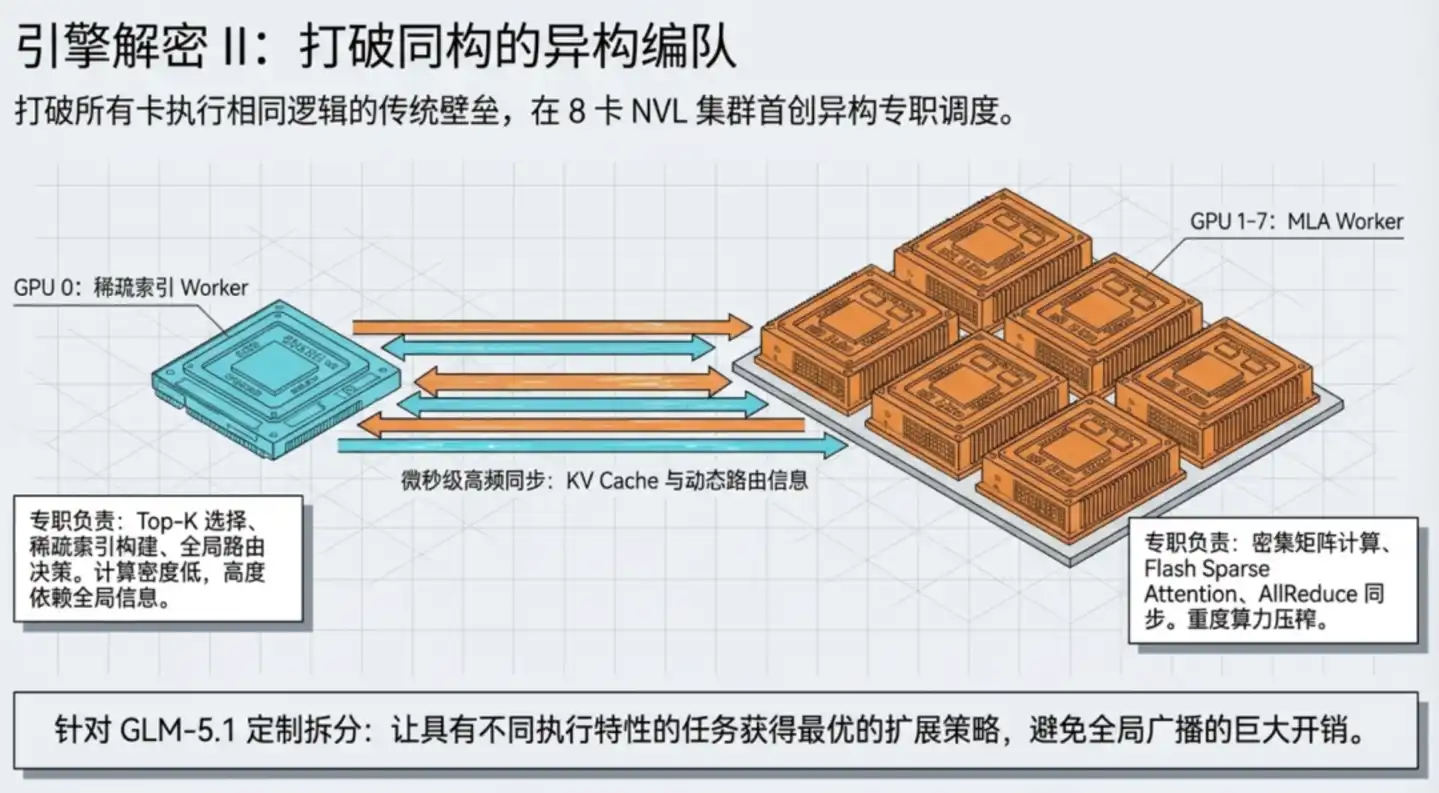
Tiếp theo, TileRT nhúng trực tiếp thao tác truyền thông giữa các GPU vào dây chuyền thực thi, không còn là bước độc lập. Nhìn từ bên ngoài, toàn bộ hệ thống 8 card hoàn thành một lớp tính toán chú ý chỉ cần một lần khởi động kernel, truyền thông và tính toán bên trong hoàn thành liền mạch trong dây chuyền liên tục bên trong.
Hai lớp trên giải quyết vấn đề trong phạm vi một máy. Khi cụm mở rộng đến hàng trăm thậm chí hàng ngàn GPU, bản thân việc truyền dữ liệu giữa các GPU trở thành trần mới.
Cách làm thông dụng ngành là ROFT (Rail-Optimized Fat-Tree), đây là giải pháp chính thức NVIDIA đề xuất, tiêu chuẩn tuyệt đối của ngành.
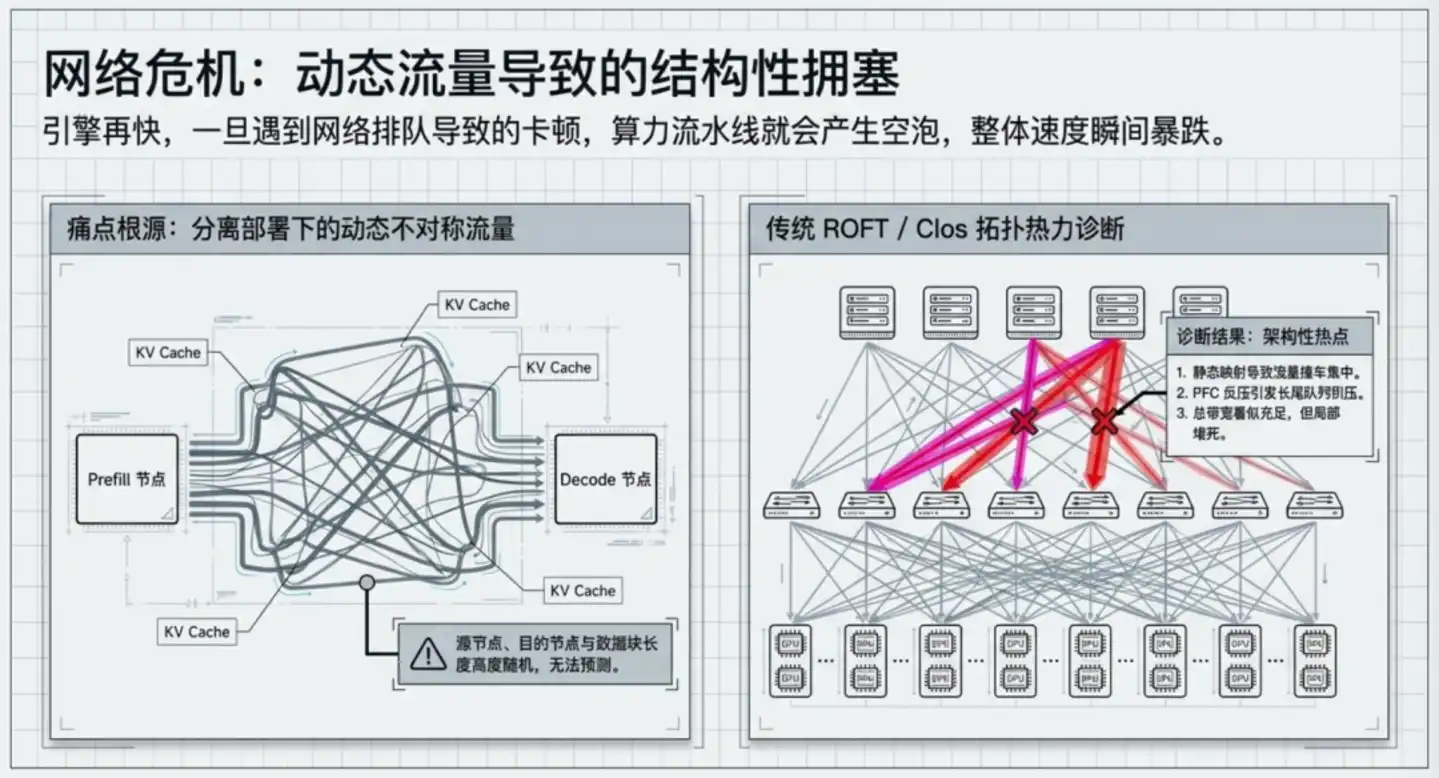
Cấu trúc của nó là một cái cây: máy chủ trước tiên kết nối bộ chuyển mạch Leaf cấp dưới (lớp truy nhập, trực tiếp hướng đến máy chủ), Leaf kết nối lên bộ chuyển mạch Spine (lớp xương sống, phụ trách kết nối giữa các Leaf khác nhau, như nút giao thông đường cao tốc). Dữ liệu truyền giữa hai GPU, phải "trước tiên lên Spine, rồi xuống Leaf mục tiêu", ít nhất qua 3 bước nhảy.
Để tránh lưu lượng tập trung vào một số ít đường liên kết, kiến trúc này phụ thuộc vào thuật toán ECMP để phân phối dữ liệu giữa nhiều đường dẫn, vận hành tốt trong điều kiện tiền đề lưu lượng Internet "phân bố đều thống kê".
Nhưng lưu lượng cảnh suy luận hoàn toàn không đều. Độ dài ngữ cảnh của các yêu cầu khác nhau có thể chênh lệch đến hàng chục lần, hướng truyền KV Cache giữa các GPU gần như ngẫu nhiên, mấy bộ chuyển mạch Leaf nào đó sẽ định kỳ trở thành điểm nóng, kích hoạt cơ chế phản áp, làm tắc nghẽn từ cục bộ lan rộng ra toàn đường liên kết. Sự tắc nghẽn này không phải điều chỉnh tham số giao thức là giải quyết được, là sản phẩm của chính cấu trúc tô pô.
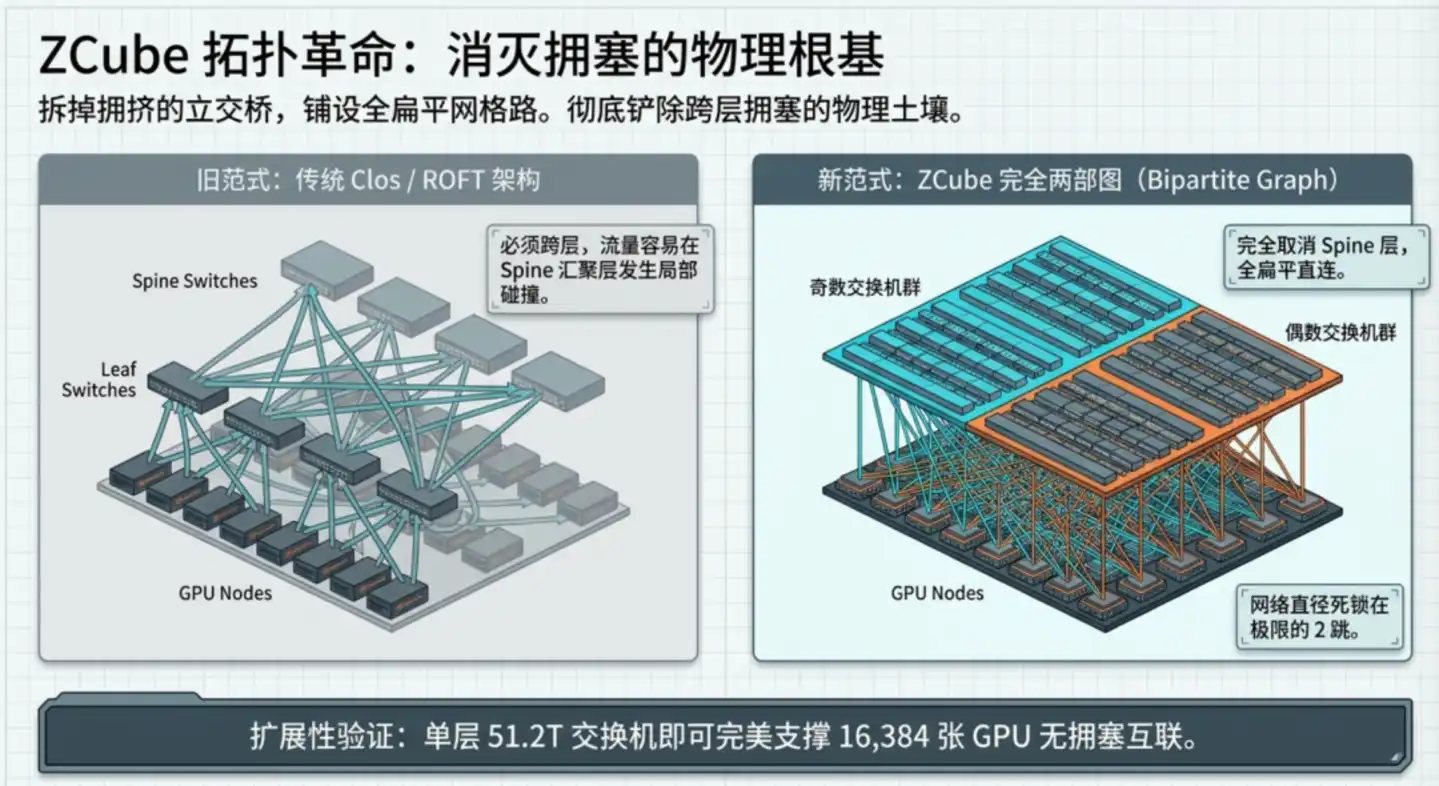
Đột phá căn bản của ZCube: Từ cấp độ kiến trúc khiến loại tắc nghẽn này không thể xảy ra về mặt vật lý.
Thiết kế cốt lõi chia hai bước:
Bước một, hủy bỏ lớp xương sống Spine, làm phẳng toàn mạng. Chia tất cả bộ chuyển mạch Leaf thành hai nhóm theo số chẵn lẻ, hai nhóm kết nối hoàn toàn với nhau, bất kỳ bộ chuyển mạch số lẻ nào kết nối tất cả bộ chuyển mạch số chẵn, ngược lại. Bất kỳ hai GPU nào giữa chúng nhiều nhất qua hai bộ chuyển mạch là có thể đến nhau, số bước nhảy giảm từ 3 xuống 2.
Bước hai, cũng là chỗ tinh tế nhất: mỗi card mạng GPU dùng hai cách hoàn toàn khác nhau để lần lượt kết nối vào hai nhóm bộ chuyển mạch. Tô pô đặc biệt này mang lại một tính chất toán học then chốt: toàn mạng giữa hai GPU bất kỳ, có và chỉ có một đường dẫn tối ưu duy nhất.
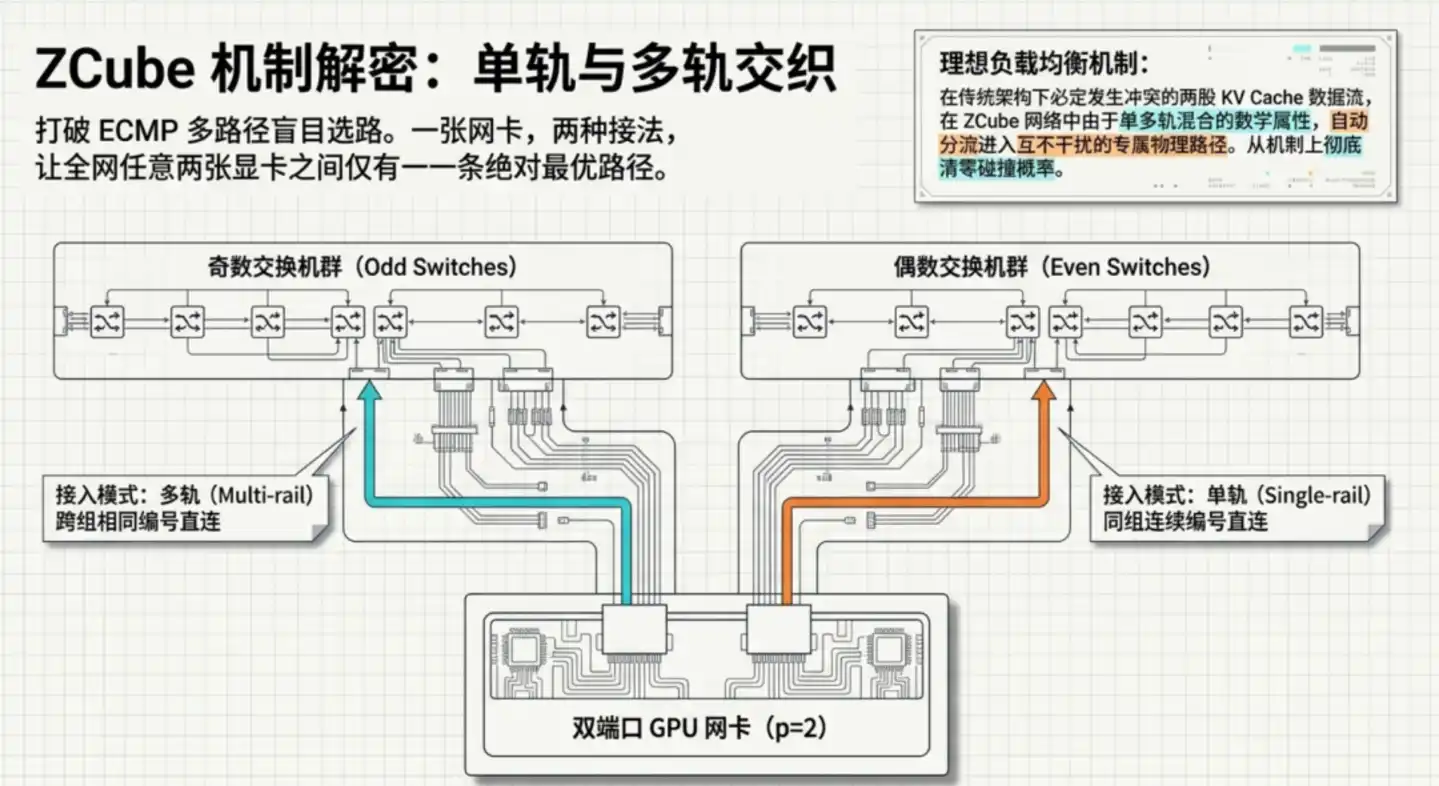
"Đường dẫn duy nhất" trực tiếp loại bỏ căn nguyên tắc nghẽn. Kiến trúc truyền thống dễ xuất hiện điểm nóng, chính là vì có nhiều đường dẫn để chọn, thuật toán cân bằng tải chọn sai sẽ dẫn đến lưu lượng tập trung. ZCube trong thiết kế loại bỏ việc "lựa chọn" chính nó: không cần cân bằng, vì căn bản không có ngã rẽ.
04 Trong điều kiện phần cứng giống nhau, tính toán sổ sách thế nào?
Sau khi Trí Phổ nâng cấp cụm sản xuất GLM-5.1 từ ROFT truyền thống lên ZCube, nhận được ba con số:
Tóm lại, cùng mức đầu tư GPU, cụm có thể phục vụ nhiều người dùng hơn; cùng yêu cầu trải nghiệm người dùng, cụm có thể mua ít hơn một phần ba thiết bị mạng. Hiệu suất và chi phí cải thiện hai chiều.
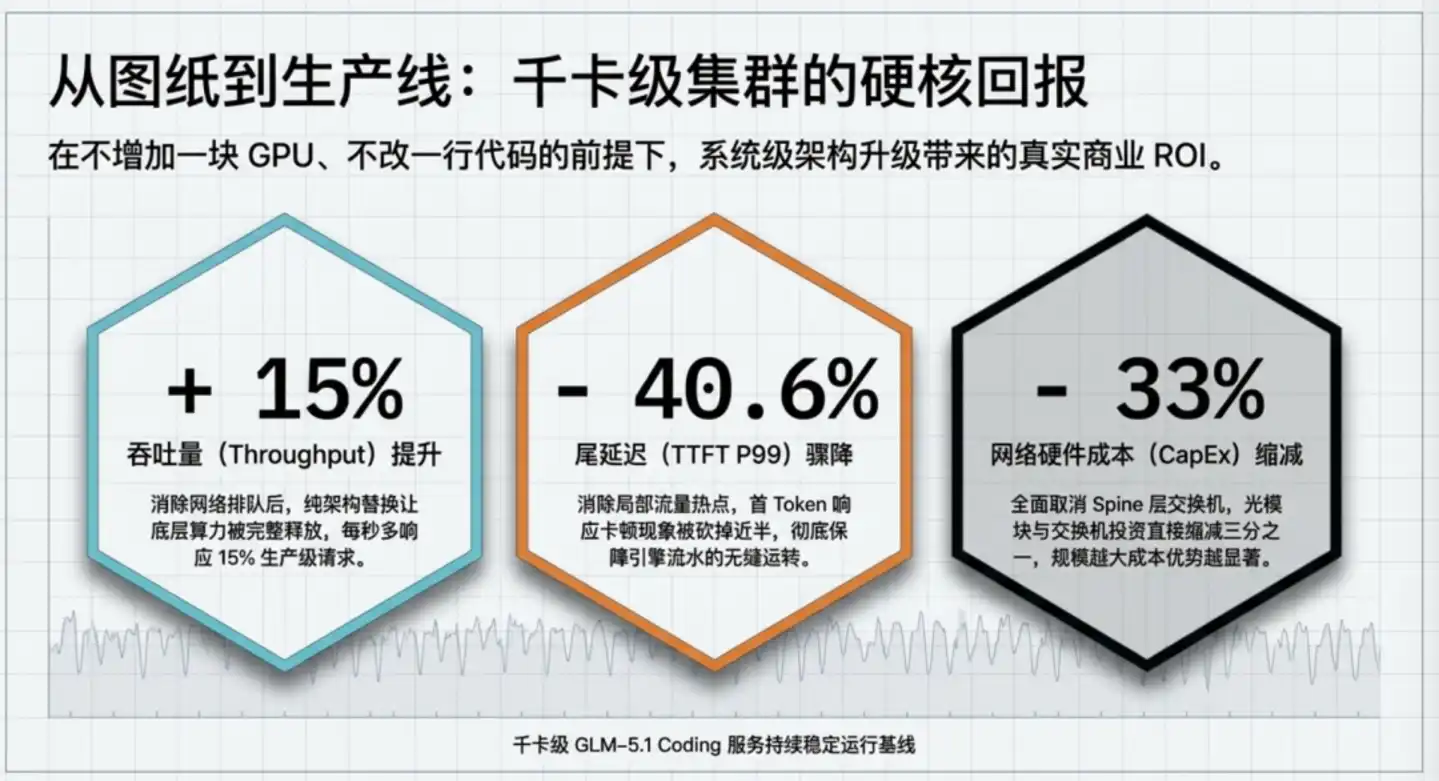
Cụ thể, thông lượng tăng 15%, bằng miễn phí thêm 15% sức tính toán. Trong điều kiện số lượng GPU không đổi, thông lượng tăng 15%, tương đương với chi phí phần cứng bình quân mỗi token giảm khoảng 13%, hay nói cách khác cùng chi phí có thể phục vụ thêm 15% người dùng.
Nếu một cụm có 1000 GPU, lần nâng cấp này tương đương với việc nhiều ra năng lực của 150 card, theo giá thị trường card suy luận cao cấp hiện tại, đây là giá trị sức tính toán cấp số tỷ.
Độ trễ đuôi giảm 40.6%, giải quyết vấn đề ổn định chứ không phải tốc độ trung bình. Một nhiệm vụ Agent cần 50 lượt gọi, nếu độ trễ đuôi mỗi lần giảm 1 giây, thời gian hoàn thành tồi nhất của toàn bộ nhiệm vụ sẽ bị nén gần 1 phút.
Chi phí giảm một phần ba, là tiết kiệm trực tiếp ở cấp độ xây dựng. ZCube hủy bỏ lớp Spine, với quy mô cụm giống nhau, số lượng bộ chuyển mạch và module quang cần thiết trực tiếp giảm một phần ba. Theo tính toán của Trí Phổ, trong cụm quy mô vạn card, chỉ riêng mục này có thể tiết kiệm khoảng 2,1 đến 6,4 tỷ nhân dân tệ.
Về lâu dài, khi quy mô cụm tăng cấp số mũ, độ phức tạp truyền thông giữa các GPU tăng gấp bội, xác suất và ảnh hưởng tắc nghẽn cũng tăng đồng bộ. Điều này có nghĩa là giá trị của loại sáng tạo cấp kiến trúc như ZCube, sẽ xuất hiện tăng tốc khi cụm suy luận tiếp tục mở rộng. Lợi ích của cụm cấp vạn card ngày mai có thể không chỉ 15% hôm nay.
05 Viết ở cuối
Sau khi xem báo cáo kỹ thuật của Trí Phổ, tôi nghĩ, liệu điều này có giống như DeepSeek xuất hiện bất ngờ, mang đến một cơn bão cho ngành?
Suy nghĩ kỹ, ảnh hưởng của cả hai dường như ở các khía cạnh khác nhau. Khi DeepSeek ra mắt, nó chứng minh rằng, cùng trí thông minh, có thể thực hiện với ít sức tính toán hơn nhiều. Thị trường lo lắng "cần GPU ít hơn", nên vốn hóa thị trường của NVIDIA ngày hôm đó bay hơi gần 6000 tỷ USD.
Nhưng kỹ thuật của Trí Phổ hôm nay chứng minh: cùng sức tính toán, có thể sản xuất nhiều hơn. Nó đang tái cấu trúc "ngoài GPU, các cơ sở hạ tầng khác nên trông như thế nào".
Nhìn ngắn hạn, NVIDIA sẽ không bị ảnh hưởng, nhưng nhìn dài hạn, hào sức mạnh của GPU + kết nối NVLink + mạng InfiniBand + hệ sinh thái phần mềm CUDA đang bị "xới đất", đặc biệt là InfiniBand mà NVIDIA mua của Mellanox với 6,9 tỷ USD năm 2019, giá trị thặng dư phía mạng của NVIDIA sẽ bị xói mòn mạnh.
Ngoài ra, ZCube hủy bỏ lớp Spine, nhưng nó đối với yêu cầu mật độ cổng của bộ chuyển mạch Leaf ngược lại cao hơn. Hưởng lợi là các nhà sản xuất có thể làm bộ chuyển mạch Leaf mật độ cao, cổng lớn (Ruijie, Arista, chip chuyển mạch Broadcom), bị tổn thất là các nhà sản xuất chủ yếu phụ thuộc vào bộ chuyển mạch Spine cao cấp ăn giá trị thặng dư.
Năm 2025, Celestica và NVIDIA chiếm tổng cộng khoảng 50% thị phần bộ chuyển mạch mạng hậu cần AI, cục diện này sau khi mô hình ZCube lan rộng sẽ đối mặt với sắp xếp lại.
Module quang là hướng chuỗi công nghiệp thay đổi trực tiếp nhất trong lần này, logic rất rõ ràng. Đối với các nhà sản xuất module quang trong nước (Zhongji Innolight, T&W Communications, v.v.), đây là một lợi thế cấu trúc: không chỉ tổng lượng đang tăng, mà nhu cầu đối với module quang tốc độ cao (800G, 1.6T) dưới mô hình ZCube càng tập trung và cấp bách hơn kiến trúc truyền thống.
Cho dù là TileRT hay kiến trúc ZCube, đây là một bộ động cơ suy luận phần mềm thuần chạy trên GPU tiêu chuẩn, không phụ thuộc vào đặc tính phần cứng riêng của NVIDIA, về lý thuyết có thể chuyển sang chip nội địa như Ascend của Huawei. Hướng này một khi thông suốt, sẽ giảm mạnh ngưỡng cửa ngăn xếp phần mềm của chip AI nội địa trong cảnh suy luận.
Đây có lẽ mới là ý nghĩa lớn hơn đằng sau sự sáng tạo kỹ thuật này.








