在美国,争取现货Solana ETF监管批准的努力似乎陷入停滞,但资产管理公司VanEck表示,其计划中的基金“仍在进行中。”
巴西证券监管机构本周批准了第二只Solana交易所交易基金(ETF),这是八月份的第二次类似批准。尽管这种基于山寨币的投资工具在巴西逐渐获得关注,但在美国获得类似批准的路径仍不明朗。
根据监管机构的数据库显示,这只新批准的Solana ETF由巴西资产管理公司Hashdex提供,并于周二获得巴西证券委员会(CVM)的批准。数据显示,该基金目前处于运营前阶段。
本月早些时候,巴西证券委员会(CVM)批准了巴西首只专注于Solana的ETF,该基金由巴西资产管理公司QR Asset创建,由Vortx负责运营。
在美国,VanEck和21Shares在6月申请了现货Solana ETF,这是继以太坊ETF初步获批后的举措。VanEck的数字资产研究主管Matthew Sigel本月早些时候表示,随着巴西首只Solana ETF的批准,美国的批准也将是“不可避免的”。
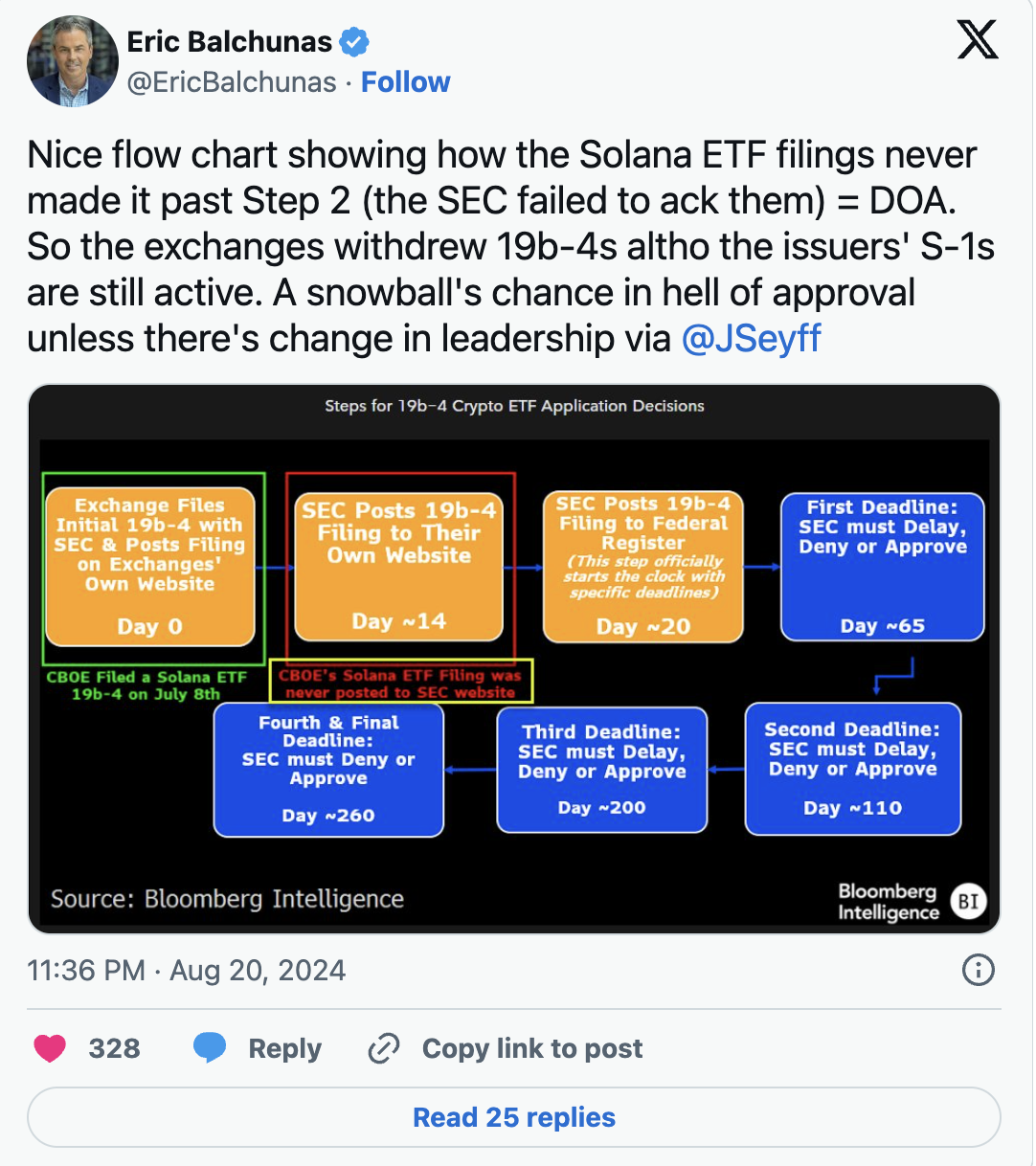
但目前尚无迹象表明这一批准何时会发生,而且可能会遇到阻碍。最近,这两份19b-4文件已从Cboe全球市场的网站上被移除,而这些文件最初是由Cboe代表相关发行人提交的。
彭博ETF分析师Eric Balchunas周二在Twitter(即X)上表示,这些文件从未在美国证券交易委员会(SEC)的网站上发布,这实际上使得这些文件一开始就注定无法获批。这导致Cboe撤回了这些上市申请,即便发行人自己可能仍然有针对拟议基金的S-1申请在进行。
Balchunas谈到由Gary Gensler领导的SEC对Solana ETF的态度时表示:“在没有领导层变动的情况下,批准的可能性微乎其微。”他在回复中暗示,总统选举也可能会影响Solana ETF在美国的未来。
他补充道:“2024年几乎没有机会,如果哈里斯获胜,2025年也可能几乎没有机会。唯一的希望[在我看来]是特朗普获胜。”
关于Solana ETF在美国的命运,以及SEC如何看待SOL的监管地位的猜测已经持续了多年。SEC没有立即回应Decrypt的置评请求。
尽管Cboe的文件缺失,VanEck数字资产研究主管Matthew Sigel周一晚间在推特上表示,该公司的Solana ETF计划仍在“进行中”。
“请记住,Nasdaq和CBOE等交易所提交规则更改(19b-4)以列出新的ETF。像VanEck这样的发行人负责招股说明书(S-1),”Sigel在周一的一条推特中说道。“我们的计划仍在进行中。”








