编译:深潮TechFlow
加密与 AI:是否已走到尽头?
2023 年,Web3-AI 一度成为热门话题。
但如今,它充斥着模仿者和无实际用途的巨额项目。
以下是需要避免的误区和应关注的重点。

概述
IntoTheBlock 的 CEO @jrdothoughts 最近在一篇文章中分享了他的见解。
他讨论了:
a. Web3-AI 的核心挑战
b. 被过度炒作的趋势
c. 具有高潜力的趋势
我已为你提炼出每个要点!让我们一探究竟:

市场现状
当前的 Web3-AI 市场被过度炒作和资助。
许多项目与 AI 行业的实际需求脱节。
这种脱节带来了困惑,但也为有洞察力的人创造了机会。
(致谢 @coinbase)
核心挑战
Web2 和 Web3 AI 之间的差距正在扩大,主要原因有三:
-
有限的 AI 研究人才
-
受限的基础设施
-
不足的模型、数据和计算资源
生成式 AI 基础
生成式 AI 依赖于模型、数据和计算资源三大要素。
目前,还没有主要模型针对 Web3 基础设施进行了优化。
最初的资金支持了一些与 AI 现实脱节的 Web3 项目。
被高估的趋势
尽管有很多炒作,并非所有 Web3-AI 的趋势都值得关注。
以下是 @jrdothoughts 认为最被高估的一些趋势:
a. 去中心化的 GPU 网络
b. ZK-AI 模型
c. 推理证明 (致谢 @ModulusLabs)

去中心化的 GPU 网络
这些网络承诺民主化 AI 训练。
但现实情况是,在去中心化基础设施上训练大型模型既慢又不切实际。
这一趋势尚未兑现其高远的承诺。
零知识 AI 模型
零知识 AI 模型在隐私保护方面看起来很有吸引力。
但实际上,它们计算成本高且难以解释。
这使得它们在大规模应用中不太实际。
(致谢 @oraprotocol )

图中信息:
b) 目前,开销高达 1000 倍。
然而,这种方法距离实用化还有很大差距,尤其是对于 Vitalik 所描述的那些用例。以下是一些例子:
-
zkML 框架 EZKL 需要大约 80 分钟才能生成一个 1M-nanoGPT 模型的证明。
-
根据 Modulus Labs 的数据,zkML 的开销比纯计算高出 1000 倍以上,最新报告显示为 1000 倍。
-
根据 EZKL 的基准测试,RISC Zero 在随机森林分类任务中的平均证明时间为 173 秒。
推理证明
推理证明框架为 AI 输出提供加密证明。
然而, @jrdothoughts 认为这些解决方案解决的是并不存在的问题。
因此,它们在现实世界中的应用有限。
高潜力趋势
虽然有些趋势被过度炒作,但另一些趋势则具有显著潜力。
以下是一些被低估的趋势,可能提供真正的机会:
a. 具备钱包的 AI 智能体
b. 加密货币为 AI 提供资金
c. 小型基础模型
d. 合成数据生成
具备钱包的 AI 智能体
想象一下,AI 智能体通过加密货币拥有金融能力。
这些智能体可以雇佣其他智能体或质押资金以确保质量。
另一个有趣的应用是“预测智能体”,如 @vitalikbuterin 所提到的。
加密货币为 AI 提供资金
生成式 AI 项目通常面临资金短缺。
加密货币的高效资本形成方法,如空投和激励,为开源 AI 项目提供了关键的资金支持。
这些方法有助于推动创新。(致谢 @oraprotocol)
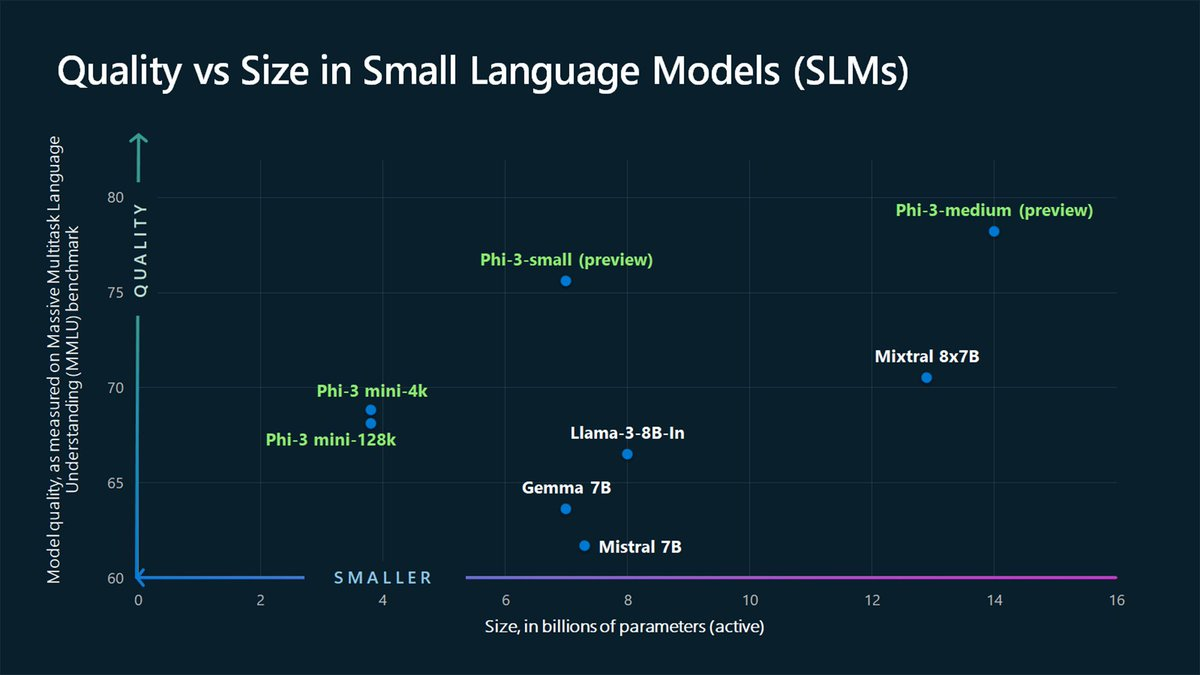
小型基础模型
小型基础模型,例如微软的 Phi 模型,展示了少即是多的理念。
具有 1B-5B 参数的模型对去中心化 AI 至关重要,能够提供强大的设备端 AI 解决方案。
(来源:@microsoft)
合成数据生成
数据稀缺是 AI 发展的主要障碍之一。
通过基础模型生成的合成数据可以有效补充现实世界的数据集。
克服炒作
最初的 Web3-AI 热潮主要集中在一些脱离实际的价值主张上。
@jrdothoughts 认为,现在应将重点转向构建实际可行的解决方案。
随着注意力转移,AI 领域依然充满机会,等待敏锐的目光去发现。
本文仅供教育用途,非财务建议。非常感谢 @jrdothoughts 提供的宝贵见解。








