Akankah android bermimpi? Dan jika mereka bermimpi, apakah mereka memimpikan domba elektronik?

Cuplikan film "Blade Runner"
Pada tahun 1968, ketika penulis novel asli film fiksi ilmiah "Blade Runner", Philip K. Dick, mengetik pertanyaan abstrak dan futuristik ini di mesin tiknya, mungkin dia tidak menyangka bahwa setengah abad kemudian, raksasa teknologi Silicon Valley akan memberikan jawaban dengan wajah serius.
Ya, mereka tidak hanya bisa memimpikan domba elektronik, tetapi juga bisa memvisualisasikan mimpinya.
Kemarin, di konferensi pengembangnya di San Francisco, Anthropic merilis serangkaian fitur baru untuk platform pembangun agen cerdas Managed Agents, termasuk perluasan memori, keluaran hasil, kolaborasi multi-agen, serta "Dreaming" (bermimpi).
Menurut penjelasan Anthropic sendiri, "memory (ingatan) dan dreaming (mimpi) bersama-sama membentuk sistem memori agen yang tangguh dan mampu memperbaiki diri".

Mulai dari mimpi, hingga ingatan, teman-teman yang kurang mengikuti bidang AI mungkin akan dipenuhi tanda tanya, kapan kata-kata yang menjadi milik manusia ini mulai bisa dengan mulus diterapkan pada AI.
Sejak OpenAI meluncurkan seri o1 pada tahun 2024, "serangkaian model AI yang dirancang untuk berpikir lebih lama sebelum merespons", kata "berpikir" digunakan dengan sangat wajar, hingga tidak ada yang berhenti sejenak untuk bertanya, sebuah program yang hanya memprediksi token berikutnya secara statistik, atas dasar apa bisa disebut berpikir?
Kemudian menyusul reasoning (penalaran), memory (ingatan), reflection (refleksi), imagining (membayangkan), satu per satu kegiatan yang hanya dilakukan manusia, dipindahkan ke peluncuran produk.

Cuplikan film "Paprika" yang membahas mimpi
"Berpikir" masih bisa dijelaskan sebagai metafora, "ingatan" juga masih bisa dikatakan sebagai perluasan dari istilah teknis, tetapi "bermimpi" benar-benar sedikit berlebihan. Filsafat dan sejarah ribuan tahun belum sepenuhnya memahaminya, tetapi perusahaan AI bisa langsung berkata: kami tidak hanya membuat mesin yang bisa berpikir, kami juga membuat mesin yang bisa bermimpi.
Apa itu bermimpi? Selain bermimpi, tidak adakah istilah teknis lain yang lebih tepat untuk menggambarkan hal ini?
AI Bermimpi Juga Butuh Biaya
Sejak peristiwa kebocoran kode Claude Code, telah ditemukan oleh netizen bahwa Anthropic sedang mempersiapkan fitur bernama Auto Dreaming. Saat itu, semua orang bertanya-tanya, apakah AI juga seperti kita manusia, perlu tidur, mendapatkan istirahat yang cukup, agar menjadi lebih fokus dan lebih pintar?
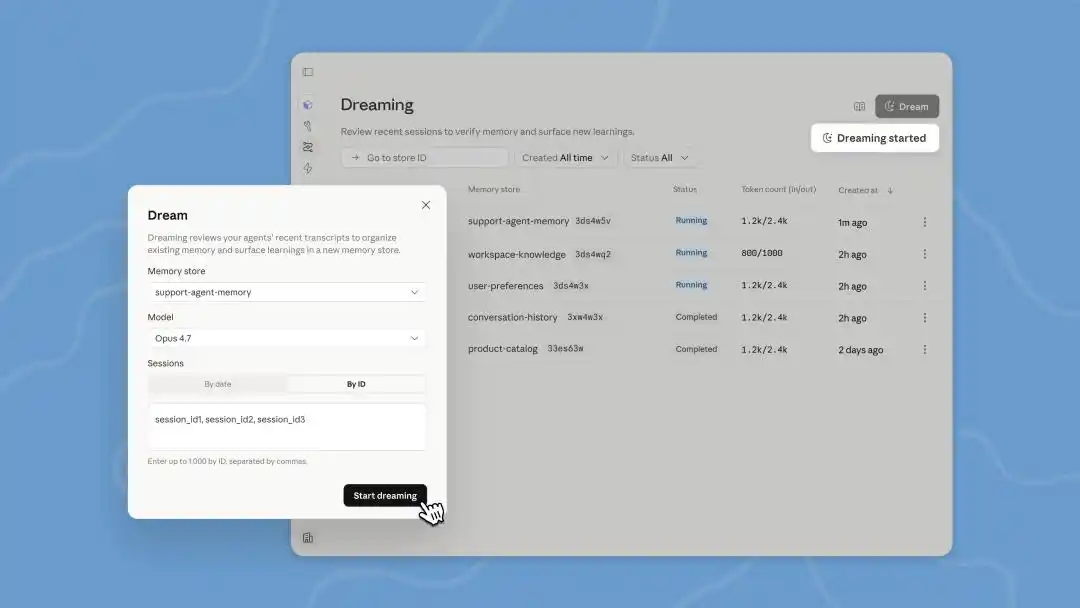
Namun, dengan memahami prinsip kerja AI Agent saat ini, akan ditemukan bahwa yang disebut "bermimpi" pada dasarnya hanyalah pemrosesan batch log offline yang otomatis.
AI Agent sekarang pandai menyelesaikan tugas-tugas kompleks berantai panjang. Misalnya, "tolong teliti lima laporan keuangan terbaru pesaing ini, dan susun menjadi tabel". Dalam proses ini, Agent perlu melompat di antara berbagai halaman web, membaca banyak dokumen, memanggil alat yang berbeda, dan bahkan mungkin gagal mencoba kembali karena bertemu mekanisme anti-penyusupan.
Setelah rangkaian tugas online yang panjang dan rumit ini berakhir, backend Agent akan meninggalkan sejumlah besar log eksekusi.
Gambar dihasilkan oleh AI
Fitur "bermimpi" Anthropic adalah membiarkan Agent, pada waktu menganggur, menyusun kembali catatan sejarah ini. Ia akan mencari pola di dalamnya, misalnya menemukan "setiap kali bertemu pop-up seperti ini, klik kanan atas untuk menutupnya", sehingga mengoptimalkan jalur operasi berikutnya.
"Memory" bertanggung jawab menangkap hal-hal yang dipelajari saat bekerja, sedangkan "dreaming" menyaring ingatan-ingatan ini di antara sesi, dan membagikannya di antara Agent yang berbeda.
Singkatnya, ini adalah mekanisme pembelajaran penguatan dan koreksi diri berbasis data historis.

Pengenalan mimpi: https://platform.claude.com/docs/en/managed-agents/dreams
Dreams yang diperbarui di Managed Agents dalam konferensi pengembang kali ini adalah tugas pemrosesan backend, yang perlu kita picu secara manual. Claude dapat membaca hingga 100 riwayat percakapan session sekaligus, kemudian menghasilkan memory baru, untuk kita tinjau sebelum memutuskan apakah akan digunakan.
Sedangkan AutoDream yang sebelumnya telah diluncurkan diam-diam di Claude Code, adalah setiap kali selesai berbicara dengan Agent satu putaran, Claude Code akan memeriksa di backend "apakah harus bermimpi", defaultnya dijalankan sekali setiap 24 jam.
Fitur serupa bermimpi juga dimiliki oleh Hermes Agent. Hermes Agent mengutamakan kemampuan belajar dan berevolusi mandiri, ia tidak hanya mendukung ringkasan otomatis pengalaman dari tugas-tugas sebelumnya, dan menyimpannya dalam file memori.

Salah satu fitur yang disebut Curator juga dapat secara otomatis mengatur panduan operasi yang disaring ini menjadi Skill.
Skill ini akan diberi skor, yang berulang digabungkan, yang tidak digunakan dalam waktu lama diarsipkan secara otomatis, bahkan memiliki siklus hidup seperti active, stale, archived. Kita juga dapat menyematkan Skill penting, agar tidak otomatis dibersihkan oleh sistem.
OpenClaw dalam beberapa pembaruan terakhirnya juga menambahkan mekanisme terkait, seperti memori persisten antar percakapan, penjadwalan tugas berkala, eksekusi terisolasi sub-Agent, serta fitur bermimpi yang langsung disebut Dreaming.
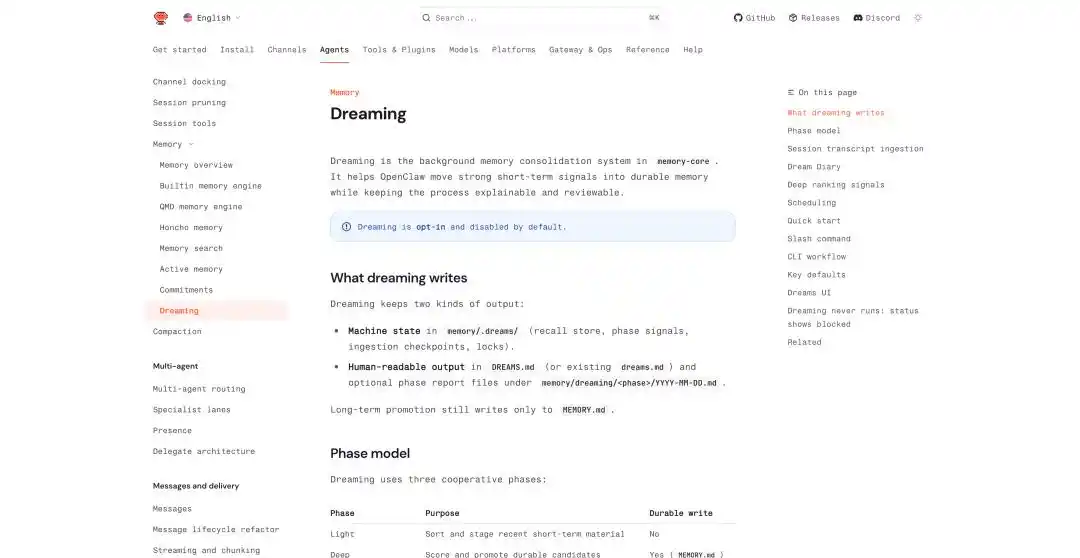
Mimpi OpenClaw: https://docs.openclaw.ai/concepts/dreaming
Dalam mekanisme bermimpi OpenClaw, perjalanan mimpi diringkas menjadi tiga tahap, light, REM, deep. Dua yang pertama bertanggung jawab menyusun, merefleksikan, dan mengkategorikan tema, deep baru benar-benar menulis konten ke memori jangka panjang MEMORY.md.
Sedangkan konsolidasi pada tahap tidur dalam, akan diputuskan oleh 6 sinyal tertimbang, apakah perlu ditulis ke memori jangka panjang. Keenam sinyal ini meliputi frekuensi, relevansi, keragaman kueri, ketepatan waktu, tingkat pengulangan antar hari, kekayaan konsep.

Gambar dihasilkan oleh AI
Menulis ke memori jangka panjang akan menghasilkan dua file, satu file status berorientasi mesin, ditempatkan di memory/.dreams/; yang lainnya adalah catatan yang dapat dibaca pengguna, ditulis ke DREAMS.md dan laporan yang dihasilkan per tahap.
Selain itu, Dreaming dapat dijalankan secara otomatis sesuai jadwal, defaultnya setiap hari pukul 3 pagi menjalankan proses lengkap, urutannya adalah light → REM → deep.
Selain output bermimpi, OpenClaw juga memelihara dokumen yang disebut Dream Diary, sistem secara otomatis menghasilkan "buku harian mimpi", menggunakan cara naratif untuk mencatat proses penyusunan memori, menekankan dapat dijelaskan, dapat ditinjau, bukan menulis ke perpustakaan kotak hitam.
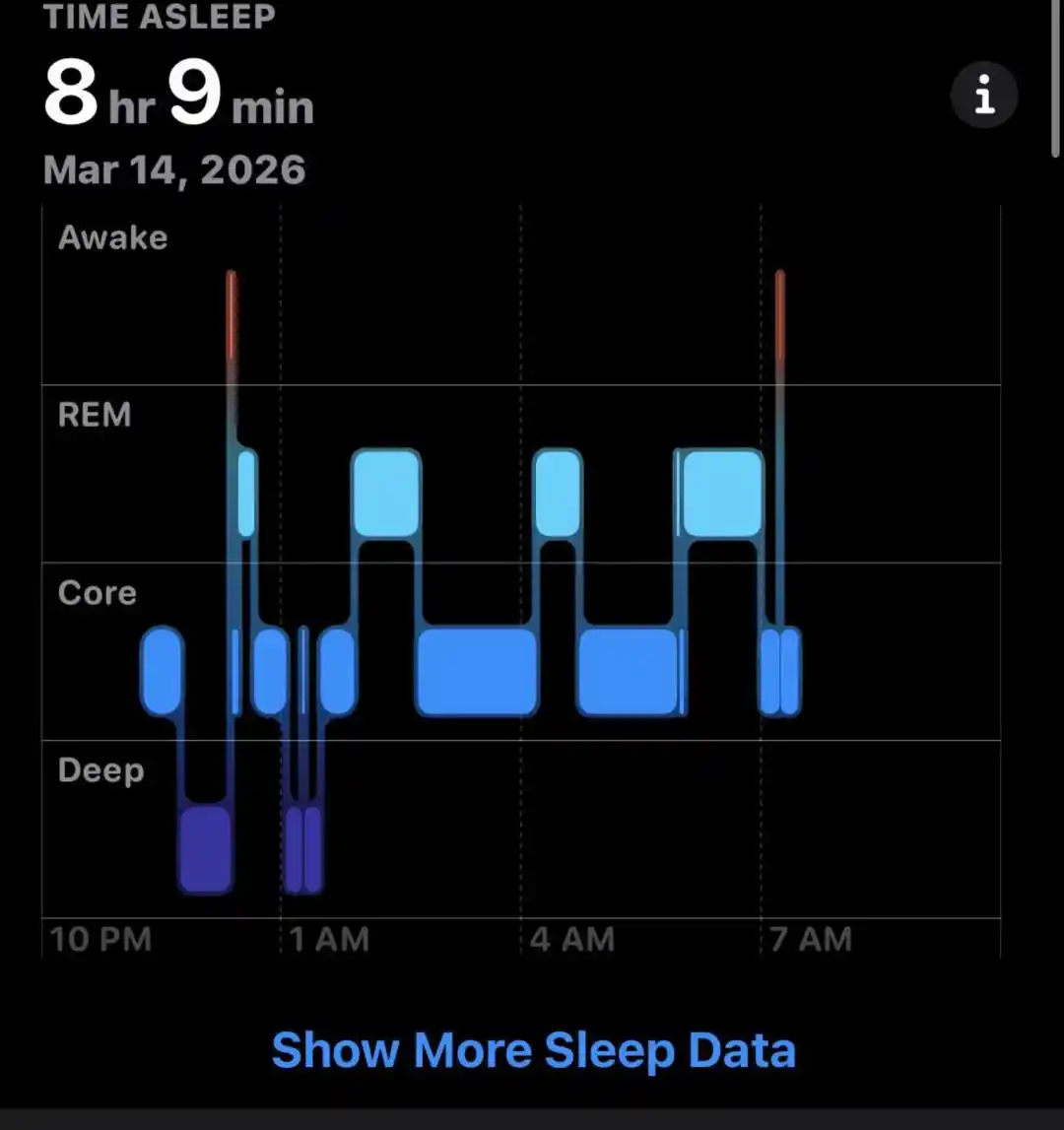
Dalam neurosains ada pemahaman yang sangat klasik: informasi yang diperoleh manusia di siang hari, pertama masuk ke sistem penyimpanan sementara; dan selama proses tidur, otak akan memutar ulang, mengkonsolidasi, dan membersihkan informasi ini, menyimpan yang penting, membuang yang tidak berarti.
Gambar dihasilkan oleh AI
Kita tidak akan mengingat warna setiap mobil di jalan ke kantor kemarin, tetapi akan ingat bagaimana pergi ke kantor.
Mimpi-mimpi ini, terdengar memang sama seperti mimpi kita manusia, jika harus mencari perbedaan, mungkin adalah saat Claude bermimpi, masih mengonsumsi Token kita.
Namun Anthropic, OpenClaw tidak memilih menyebutnya "optimasi berbasis sesi (session-based optimization)", atau nama-nama yang lebih condong ke teknik seperti "penyetelan pasca tugas (post-task tuning)".
Lagipula, ketika nama-nama rumit itu langsung diubah menjadi "bermimpi", apa yang kita rasakan bukan lagi fungsi perangkat lunak, melainkan seperti "kehidupan digital dengan aktivitas batin".
Ingatan AI, Adalah Konteks yang Rinci
Karena menyebutkan "bermimpi", tidak bisa tidak menyebutkan prasyaratnya, yaitu memori (Memory).
Beberapa waktu terakhir, kata paling populer di lingkaran AI berubah dari rekayasa prompt, menjadi rekayasa konteks, rekayasa Skill, rekayasa Harness, tetapi bagaimanapun perubahannya, yang paling berharga saat ini masih rekayasa konteks.
Prompt sistem, input pengguna, percakapan jangka pendek, memori jangka panjang, dokumen yang diambil kembali, output pemanggilan alat dan Skill, status pengguna saat ini, lapisan-lapisan ini ditumpuk, itulah "konteks" yang benar-benar digunakan oleh agent.
Membuat Agent dapat mengingat lebih banyak, mencatat konten yang lebih berguna, telah lama menjadi tantangan dalam waktu yang cukup lama.
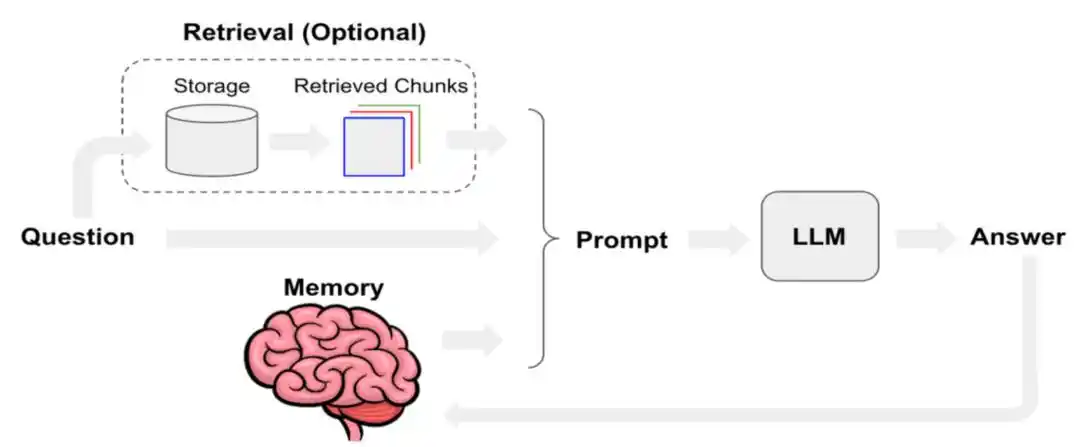
Manus tahun lalu menerbitkan blog teknis, khusus membahas bagaimana Manus mengoptimalkan rekayasa konteks. Disebutkan di dalamnya bahwa tingkat hit cache KV-Cache didefinisikan sebagai salah satu indikator tunggal terpenting AI Agent di lingkungan produksi. Sementara di tingkat pemanggilan alat, prioritas melakukan "pemblokiran" daripada "penghapusan"; serta menggunakan sistem file sebagai konteks utama.
Untuk memahami yang disebut KV Cache (cache pasangan kunci-nilai), kita dapat membayangkan model besar sebagai seorang penderita OCD ekstrem yang hanya dapat membaca satu kata setiap kali.
Saat memproses sebuah kalimat, ia akan menghitung sebuah vektor Key (kunci) dan sebuah vektor Value (nilai) untuk setiap Token yang dihasilkan. Agar tidak setiap kali menghitung ulang dari awal, ia akan menyimpan pasangan (K, V) ini, inilah KV Cache.
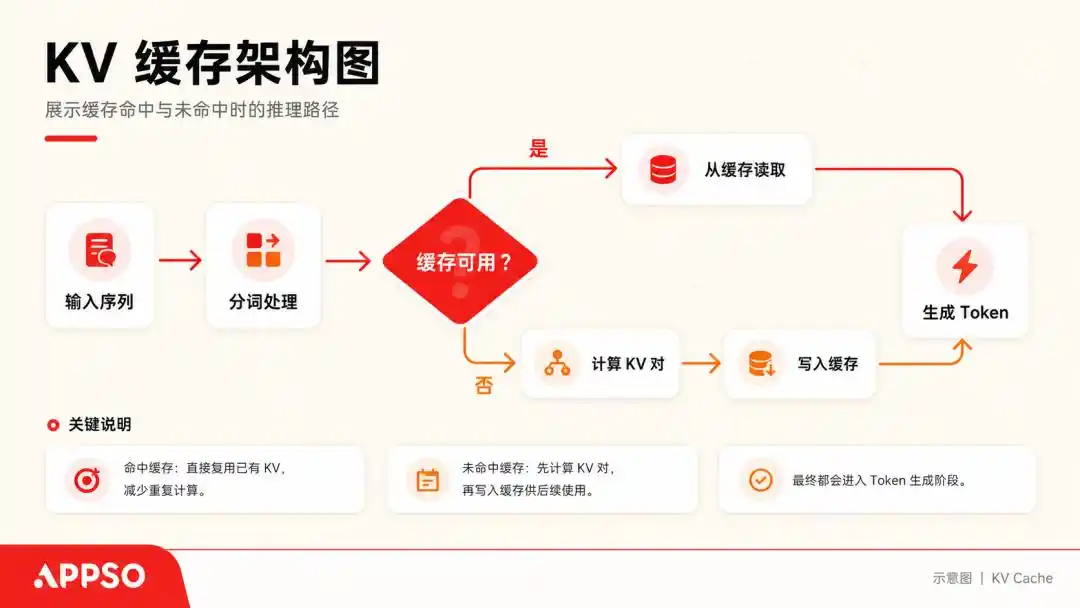
KV Cache (cache pasangan kunci-nilai) adalah teknologi percepatan dasar yang digunakan model besar dalam menghasilkan teks, untuk "menukar ruang dengan waktu". Cache memungkinkan model dalam memprediksi kata berikutnya, tidak perlu menghitung ulang semua kata sebelumnya. Gambar dihasilkan oleh AI.
Selama percakapan berlanjut, KV Cache akan terus disimpan. Umumnya, ketika menghadapi model besar dengan konteks hingga 128k, sebuah model dengan parameter 70B yang menjalankan konteks penuh 128k, hanya KV Cache saja dapat menelan 64 GB memori GPU.
Inilah mengapa jendela konteks kebanyakan model saat ini, paling banyak hanya jutaan token.
Kemarin, sebuah perusahaan baru yang mendapat pendanaan seed round 29 juta dolar, Subquadratic, merilis model baru SubQ di X, mengutamakan konteks yang lebih panjang.

SubQ mengklaim dapat mendukung jendela konteks tertinggi hingga 12 juta token, ini adalah jendela konteks terbesar di antara semua model besar saat ini.
Meskipun belum ada makalah teknis atau dokumen penjelasan model, video pengantar menyebutkan, rute teknologi inti SubQ adalah dari "perhatian padat" Transformer tradisional, beralih ke arsitektur "ekspansi subkuadrat / linear" dengan perhatian jarang. Arsitektur baru diharapkan dapat menyelesaikan masalah semakin panjang konteks, semakin meledak biaya komputasi.

Hasil tes yang diberikan juga cukup radikal, pada 1 juta token, kecepatan meningkat lebih dari 50 kali lipat, biaya turun lebih dari 50 kali lipat; pada 12 juta token, kebutuhan daya komputasi dibandingkan model terdepan dapat dikurangi hampir 1000 kali lipat.
Dan pada tolok ukur konteks panjang RULER 128K, Subquadratic menyebut SubQ dengan akurasi 95%, biaya 8 dolar, dibandingkan Claude Opus dengan akurasi 94%, biaya sekitar 2600 dolar, biaya turun sekitar 300 kali lipat.
Entah memperluas jendela konteks, atau membuat model belajar bermimpi, membuang beberapa hal sendiri.
Inilah mengapa produk Agent seperti Anthropic dkk, sekarang harus meluncurkan Dreaming. Dalam kondisi jendela konteks terbatas, AI yang lebih cerdas tidak bisa hanya mengandalkan memasukkan lebih banyak konten, tetapi juga perlu selektif.
Mengakui Mesin Hanyalah Mesin, Lebih Sulit dari yang Dibayangkan
Dengan memahami mekanisme mimpi dan ingatan AI, kita mungkin dapat mengetahui hubungannya dengan aktivitas manusia.
Namun dengan menyatukan semua kata yang dibuat oleh perusahaan AI ini untuk digunakan pada mesin, thinking (berpikir) OpenAI, memory (ingatan) dan hallucination (halusinasi) yang umum di industri, dreaming (bermimpi) Anthropic kali ini, serta kebajikan dan kebijaksanaan dalam konstitusi Anthropic itu.
Kita dapat melihat, perusahaan AI tidak hanya menjual produk, mereka sedang mendistribusikan kembali kepemilikan kata-kata dalam konsep "manusia". Setiap kata yang dipinjam, batas antara mesin dan manusia menjadi kabur satu inci.

Bahasa akan membentuk ekspektasi, ekspektasi membentuk toleransi, toleransi menentukan seberapa banyak hal yang bersedia kita serahkan kepadanya. Ini adalah rantai yang panjang, tetapi titik awalnya adalah kata-kata yang tidak berbahaya di peluncuran produk itu.
Pengaruh yang lebih tersembunyi adalah alokasi tanggung jawab. Ketika alat digambarkan sebagai entitas yang memiliki "pemikiran", "ingatan", "nilai-nilai", ketika bermasalah, kita secara alami akan menuntutnya sebagai "subjek tindakan" yang independen, AI ini yang perlu "dididik", "di-debug", "dikalibrasi".
Namun yang seharusnya ditanyakan, adalah perusahaan yang menerapkan program ini ke alur kerja kita, dan tim produk yang menulis kata "dreaming" itu. Ganti kata, orang yang duduk di "kursi terdakwa" juga berganti.
Dan kita melihat mesin yang bisa "berpikir", bisa "mengingat", sekarang juga bisa "bermimpi", mulai secara tidak sadar percaya ada sesuatu di dalamnya. Karena mengakui ini hanyalah sebuah mesin, pengalaman "saya sedang berbicara dengan makhluk yang bisa berpikir" itu akan menghilang, kembali ke hubungan alat yang dingin.

Pengenalan fitur mimpi siang | Gambar dihasilkan oleh AI
Saya sudah memikirkan, Dreaming bermimpi adalah memproses konten masa lalu, selanjutnya perusahaan AI akan meluncurkan Daydreaming, mimpi siang, untuk memprakirakan masa depan.
Pengantar adalah, mimpi siang atau melamun, dapat membuat Agent dalam keadaan aktif, menggunakan sebagian kecil daya komputasi yang menganggur, menggabungkan proyek yang sedang berjalan, sekaligus melakukan generasi eksploratif, mempersiapkan tugas yang mungkin di masa depan.
Artikel ini berasal dari akun WeChat "APPSO", penulis: APPSO yang menemukan produk masa depan