Penulis: Wang Jianshuo
6 Maret 2023, ChatGPT baru keluar, GPT-4 belum dirilis, saya dan Sarah melakukan sebuah wawancara tentang ChatGPT—episode ketiga dari seri "Bahasa Sederhana" Traders' Talk (Podcast "Membahas ChatGPT dengan Bahasa Sederhana" sudah dirilis, selamat mendengarkan).
Saat itu ChatGPT baru saja muncul, sangat sedikit orang yang benar-benar menggunakannya langsung. Wawancara yang berlangsung tiga jam itu kemudian menggantung di posisi pertama kategori ChatGPT di aplikasi Xiaoyu Zhou. Di dalamnya, saya melontarkan sekitar dua puluh lebih penilaian dan prediksi sekaligus, hanya mengandalkan intuisi dan informasi terbatas, tanpa banyak data. Naskah lengkap wawancara itu masih tersimpan di akun publik.
Sekarang adalah akhir Mei 2026, tiga tahun telah berlalu, AI telah tumbuh menjadi sesuatu yang tak terbayangkan dulu.
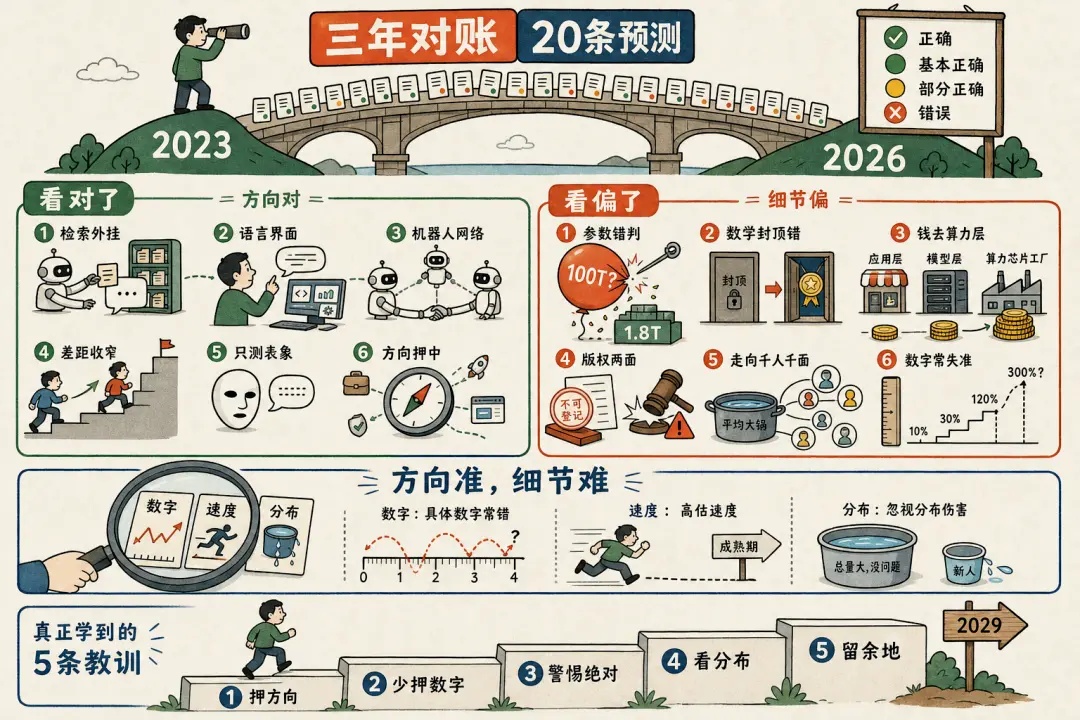
Saya ingin melakukan satu hal: mengangkat satu per satu dua puluh butir penilaian itu, lalu dengan data terbaru yang bisa ditemukan hari ini, melakukan pencocokan secara objektif. Untuk melihat jelas bagaimana dunia berubah dalam tiga tahun, dan juga melihat dengan jelas bagian mana yang dulu saya tebak tepat, dan mana yang meleset.
Agar tidak memihak, kali ini pencocokan ini saya serahkan kepada AI untuk melakukannya: memasukkan naskah wawancara lama ke dalam sebuah workflow, dan membiarkannya menjalankan 41 agent Opus 4.8, pertama-tama memecah dua puluh butir penilaian itu satu per satu, lalu masing-masing melakukan pencarian daring untuk data terbaru, saling melakukan verifikasi silang per butir, akhirnya memberi penilaian pada Wang Jianshuo tiga tahun lalu. Sekumpulan agent ini menghabiskan sekitar 20 menit, menghabiskan 1.4 juta token (setara dengan sekitar $35), dan menghasilkan laporan di bawah ini. Penilaian-penilaian ini berasal dari mereka, bukan dari saya. Tanggal patokan ditetapkan pada Mei 2026.
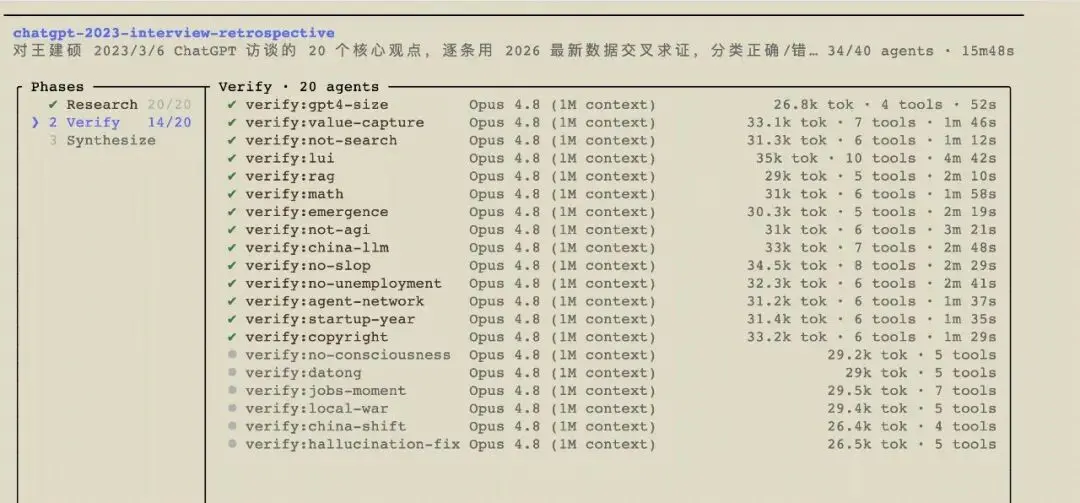
Satu. Papan Skor
Simbol keputusan: ✅ Benar · 🟢 Benar Secara Umum · 🟡 Benar Sebagian · ❌ Salah
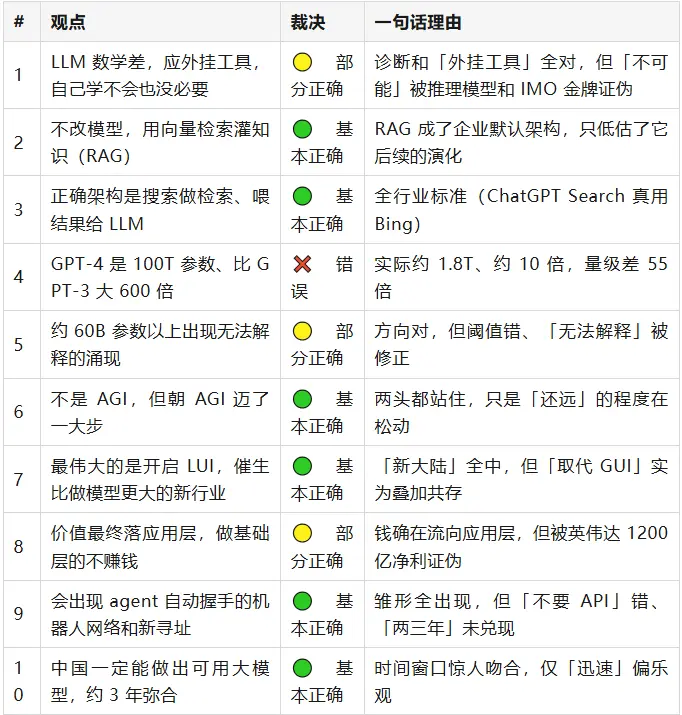
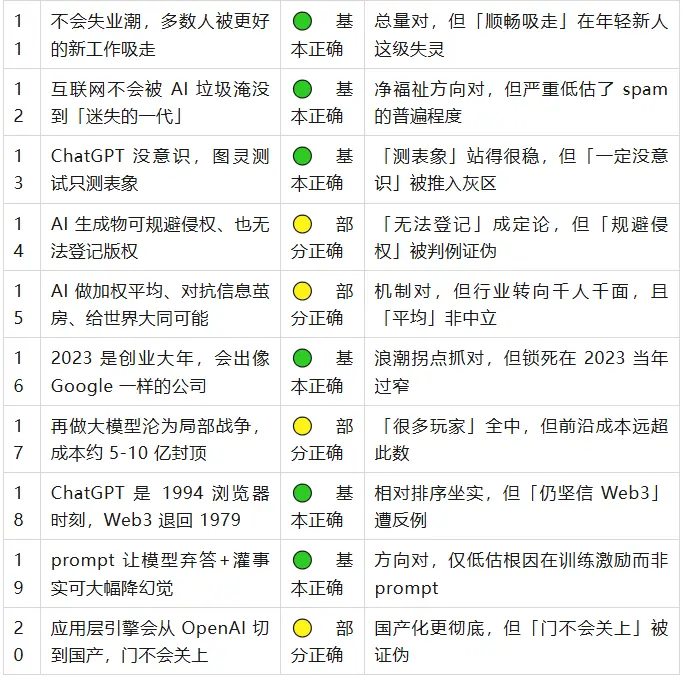
Sekilas, sebagian besar arah besar yang ditetapkan Wang Jianshuo dulu bertahan, yang benar-benar bisa dihitung salah keras hanya satu—mengatakan GPT-4 memiliki 100T parameter. Tetapi detail tersembunyi dalam hal-hal kecil: di balik hampir setiap butir yang "benar", terselip ekor yang dulu tidak tebak dengan tepat. Dari dua puluh butir, tidak ada satupun yang murni "masih belum pasti", tiga tahun cukup lama, sebagian besar hal sudah memiliki kecenderungan jawaban. Di bawah ini akan dijelaskan secara detail per kelompok.
Dua. Yang Tertebak Benar
Kesamaan kelompok ini adalah: Arah, mekanisme, bahkan ritme waktu yang dinilai Wang Jianshuo dulu semuanya tepat, salahnya hanya pada "tingkat" dan "pernyataan absolut".
RAG dan Arsitektur Pencarian (Pandangan 2, 3)
> Tahun 2023 Wang Jianshuo berkata: Metode utama menyelesaikan pengetahuan dan halusinasi bukan dengan mengubah model, tetapi dengan memasukkan pengetahuan melalui vektor pencarian sebagai "contekan"; arsitektur yang benar adalah mesin pencari melakukan pencarian, lalu hasilnya diberikan kepada LLM.
Inilah standar faktual semua produk AI hari ini. RAG menjadi arsitektur default AI perusahaan, OpenAI, Google, Anthropic semuanya menjadikannya kemampuan tingkat platform; ChatGPT Search secara harfiah adalah "pertama menggunakan indeks Bing untuk pencarian, hasilnya diberikan ke GPT, lalu menghasilkan jawaban dengan referensi". Google AI Overviews menggunakan grounding mencapai sekitar 2 miliar pengguna aktif bulanan, Perplexity sebagai perusahaan yang murni mengandalkan arsitektur ini valuasinya mencapai sekitar $200 miliar.
Saat GPT-4 belum dirilis, industri berasumsi default "menyuntikkan pengetahuan melalui fine-tuning", yang dia pertaruhkan adalah "tidak menyentuh parameter model, pencarian eksternal", mekanisme dan waktunya benar.
Harus jujur: Yang dia bayangkan adalah "pencarian statis sekali pakai", sementara realitas lebih kompleks—konteks panjang, GraphRAG, retrieval agentic semuanya datang untuk memperkuat. Debat "RAG sudah mati" tahun 2026 itu justru membuktikan arah besarnya tidak mati, yang diingkari hanyalah "pencarian sederhana sekali pakai", kesimpulannya adalah meningkatkan menjadi pencarian hybrid, bukan mundur kembali mengubah parameter model. Satu hal lagi: Istilah RAG sudah muncul dalam makalah Meta tahun 2020, bukan ciptaannya—dia hanya tepat mempertaruhkan bahwa itu akan menjadi mainstream pada periode jendela peluang.
LUI adalah Benua Baru (Pandangan 7)
> Tahun 2023 Wang Jianshuo berkata: Hal terhebat ChatGPT bukan AIGC, tetapi membuka LUI (Antarmuka Pengguna Bahasa Alami), akan seperti GUI dulu merekonstruksi interaksi manusia-komputer, menciptakan industri baru yang jauh lebih besar daripada "membuat model besar" itu sendiri.
Bagian "benua baru" ini hampir seluruhnya tepat. Bahasa alami menjadi lapisan interaksi utama massa (ChatGPT 900 juta pengguna aktif mingguan), dan menciptakan industri independen baru—agent, coding agent, lapisan protokol semuanya terwujud. Kalimat paling spesifik "jauh lebih besar daripada membuat model itu sendiri" terbukti kuat: Protokol MCP menjadi "standar sistem operasi" era LUI, tahun 2025 diadopsi secara menyeluruh oleh OpenAI, Google, Microsoft, akhir tahun dipindahkan ke Linux Foundation; Claude Code sebagai produk tunggal saja mencapai pendapatan tahunan sekitar $2.5 miliar.
Tetapi dia menggunakan kata-kata kuat seperti "merekonstruksi, menggantikan GUI", tiga tahun kemudian melihatnya adalah koeksistensi tumpang tindih, bukan menggantikan. Tiga contoh tandingan sangat keras: Laporan MIT menunjukkan 95% pilot GenAI perusahaan tidak memiliki ROI yang terukur; computer-use agent yang beroperasi langsung pada antarmuka di set pengujian, model teratas hanya sekitar 78%, baru menyentuh baseline manusia; perangkat keras bahasa murni tanpa layar hampir semuanya gagal total (Humane Pin tahun 2025 ditutup permanen). Pernyataan yang lebih tepat adalah: LUI adalah lapisan interaksi baru yang ditumpangkan di atas GUI.
Jaringan Robot dan Pencarian Alamat Baru (Pandangan 9)
> Tahun 2023 Wang Jianshuo berkata: Sekitar sepuluh tahun ke depan akan muncul "jaringan robot"—agent saling berjabat tangan secara otomatis dengan bahasa alami, saling memanggil, tidak memerlukan API tradisional lagi; akan lahir satu set sistem pencarian domain nama baru. Hal ini "dapat diselesaikan dalam dua tiga tahun".
Arahnya tepat dengan mengejutkan. MCP, A2A (sudah disumbangkan ke Linux Foundation, didukung 150+ organisasi) menyelesaikan pemanggilan silang antar agent; Agent Network Protocol langsung berdasarkan DID W3C untuk "pencarian alamat agent tanpa otoritas pusat", tujuannya adalah "jaringan kolaborasi miliaran agent"—ini sangat isomorfik dengan "sistem domain nama baru" yang dia katakan.
Dua tempat perlu diperbaiki: Pertama, "tidak memerlukan API lagi" tidak terbukti, protokol utama dasarnya adalah skema terstruktur, pada dasarnya menambahkan satu lapisan standar di atas API; Kedua, "diselesaikan dalam dua tiga tahun" tidak terwujud, data Gartner menunjukkan hingga 2026 hanya sekitar 17% organisasi yang benar-benar menerapkan agent. Menariknya, dulu sebenarnya dia melapisi perkataannya—prototipe "dua tiga tahun", matang "sekitar sepuluh tahun". Ritme prototipe tepat, siklus kematangan memang tingkat sepuluh tahun. Melihat kedua lapisan itu terpisah, kualitas butir ini lebih tinggi daripada tampilannya.
China Pasti Dapat Membuat Model Besar yang Dapat Digunakan (Pandangan 10, 20)
> Tahun 2023 Wang Jianshuo berkata: China pasti dapat membuat model besar yang dapat digunakan, kesenjangan dengan yang terdepan akan dengan cepat menyusut dalam sekitar tiga tahun (analogi browser Qihoo mengejar Netscape).
Timeline butir ini sesuai dengan mengejutkan. Stanford 2026 AI Index mengukur, kesenjangan benchmark antara model top China-AS dari 17.5–31.6 poin persentase pada Mei 2023, menyusut menjadi 2.7%; sedangkan investasi AI swasta AS adalah sekitar 23 kali lipat China—dengan input jauh lebih kecil mencapai penyusutan. DeepSeek, Qwen, Kimi, GLM menjadi mainstream global, ekosistem open source bahkan memimpin.
Tetapi kata "cepat" terlalu optimis—kematangan sesungguhnya terjadi sekitar 14 bulan kemudian, bukan "beberapa bulan". Dan ini adalah mengejar kegunaan, bukan mendefinisikan batas depan: Hingga awal 2026 masih belum ada model China yang melampaui OpenAI o3. Dalam pandangan 20 dia jelas salah: Penilaian "pintu terbuka tidak akan menutup" dibantah langsung oleh OpenAI yang secara aktif memutus API ke China pada Juli 2024, pintu ditutup oleh penyedia; dia menyebut Ernie Bot sebagai pemimpin yang justru tertinggal, yang benar-benar mengambil alih adalah DeepSeek, Doubao, Qwen yang dulu tidak menonjol.
Tidak Ada Kesadaran, Tes Turing Hanya Menguji Penampilan (Pandangan 13)
> Tahun 2023 Wang Jianshuo berkata: ChatGPT tidak memiliki kesadaran, itu adalah "pembicara tidak bermaksud, pendengar yang berlebihan"; tes Turing memang hanya menguji "apakah membuatmu mengira dia memilikinya", bukan dia benar-benar memilikinya.
Penilaian inti "menguji penampilan" ini sangat kuat, bahkan dibuktikan secara ironis oleh sebuah eksperimen: Dalam tes Turing UC San Diego 2025, GPT-4.5 dengan petunjuk "memerankan persona" dinilai sebagai manusia sebanyak 73%, lebih tinggi dari manusia sungguhan, tetapi hanya mengandalkan keterampilan akting—ini adalah anotasi terbaik untuk "hanya menguji apakah membuatmu mengira dia memilikinya".
Yang perlu ditambahkan: Pernyataan absolut kuat "mesin pasti tidak memiliki kesadaran" ini, dalam tiga tahun didorong ke area abu-abu. Anthropic mendirikan posisi riset "kesejahteraan model", memberikan probabilitas kesadaran sekitar 15%–20%, bahkan menambahkan fungsi "secara aktif mengakhiri percakapan yang disalahgunakan" untuk Claude. Ini mengubah "sama sekali tidak" menjadi "probabilitas rendah tetapi tidak bisa dikesampingkan". Namun semuanya berdasarkan "mungkin, harus diasumsikan" bukan "sudah terbukti", intinya tidak dibantah, hanya nada perkataan dulu terlalu penuh.
Lainnya yang Tertebak Benar (Pandangan 6, 11, 12, 16, 18, 19)
- Bukan AGI tetapi Langkah Besar
: Keduanya bertahan. Altman sendiri di era GPT-5 masih berkata "bukan AGI, kekurangan pembelajaran berkelanjutan"; sementara medali emas IMO, ARC-AGI dari hampir nol menjadi 85%, "melangkah besar" tidak terbantahkan. - Tidak Akan Ada Gelombang Pengangguran
: April 2026 tingkat pengangguran AS hanya 4.3%. Titik buta adalah "distribusi"—penelitian Stanford menunjukkan, yang justru diambil adalah anak tangga karir tingkat pertama, pemula muda usia 22–25 tahun, mekanisme "terserap dengan lancar" gagal pada mereka. - Tidak Akan Tenggelam oleh Sampah AI
: Arah kesejahteraan bersih benar, tetapi dia sangat meremehkan besaran—konten AI sudah mencapai sekitar 52% dari halaman web baru, "AI slop" menjadi kata tahunan. - Tahun Besar untuk Startup
: Titik balik gelombang tepat, xAI (didirikan Maret 2023) sudah mencapai valuasi 2300 miliar. Tetapi dia mengunci "perusahaan besar" hanya pada tahun 2023 itu terlalu sempit—OpenAI, Anthropic yang benar-benar triliunan dolar keduanya didirikan lebih awal. - Momen Browser 1994
: Peringkat relatif terbukti, OpenAI 2025 benar-benar meluncurkan browser Atlas, mengubah metafora menjadi realitas harfiah. Hanya saja difusi ChatGPT lebih dahsyat daripada browser, metaforanya terlalu konservatif. - Prompt Ditambah Fakta Menurunkan Halusinasi
: Arah terbukti, GPT-5 tanpa jaringan tanpa pencarian tingkat halusinasinya melonjak ke 47%, membuktikan secara terbalik "fakta" adalah variabel kunci. Hanya meremehkan akar penyebabnya ada pada insentif pelatihan, bukan prompt.
Tiga. Yang Tertebak Salah, Tertebak Meleset
GPT-4 adalah 100T Parameter (Pandangan 4)—Salah Total
> Tahun 2023 Wang Jianshuo berkata: (Kabar burung) GPT-4 adalah 100T parameter, sekitar 600 kali lipat dari 175B GPT-3.
Kedua angka salah. GPT-3 adalah 175B, perkiraan terbaik bocoran Juli 2023 adalah GPT-4 sekitar 1.8T, MoE 16 expert, hanya sekitar 10 kali lipat. 100T dan kenyataan berbeda sekitar 55 kali lipat besaran. Satu-satunya sumber "100T" adalah pernyataan kedua CEO Cerebras tahun 2021 yang "sekitar", Sam Altman sudah sejak Januari 2023 menegaskan langsung bahwa diagram perbandingan itu adalah "omong kosong total".
Ucapannya dulu memberi label "kabar burung", mempertahankan ketidakpastian. Lebih dalam lagi, kerangka "menggunakan kelipatan parameter untuk mengukur generasi" itu sendiri sudah ketinggalan zaman: OpenAI kemudian GPT-4.5, GPT-5 tidak lagi memublikasikan jumlah parameter. Ini satu-satunya butir salah keras dengan angka salah dan perspektif usang.
Matematika LLM (Pandangan 1)—Diagnosis Benar, Kesimpulan Pengunci Salah
> Tahun 2023 Wang Jianshuo berkata: Matematika LLM buruk adalah hakikat, membuatnya sendiri belajar matematika tidak mungkin dan tidak perlu, cara yang benar adalah memasang alat eksternal.
"Diagnosis ditambah rute alat" benar semua—akar penyebabnya memang generasi token demi token menyebabkan ketidakandalan pembulatan (makalah mekanisme 2025 secara tepat membuktikan intuisi "digit terakhir sering benar, digit tengah salah"); alat eksternal peningkatannya juga besar (o4-mini ketika diizinkan menggunakan Python, AIME 2025 mencapai 99.5%).
Salah pada kata-kata pengunci seperti "tidak mungkin, tidak perlu". "Tidak mungkin" dibuktikan salah—Juli 2025 Gemini Deep Think dan model OpenAI di IMO menggunakan bahasa alami murni, tanpa alat mendapatkan medali emas. Titik balik kunci adalah "model reasoning" yang baru muncul tahun 2024–2025, ini tidak bisa diprediksi pada Maret 2023—jadi untuk prediksi ini sebaiknya menilai arahnya dengan toleransi, bukan mencela waktu.
Penangkapan Nilai (Pandangan 8)—Pertaruhan Setengah Benar, Pernyataan Inti Terbalik
> Tahun 2023 Wang Jianshuo berkata: Nilai akhirnya akan jatuh di lapisan aplikasi, perusahaan yang membuka lapisan dasar (pembuat model) akhirnya belum tentu menghasilkan uang.
Uang memang mulai mengalir ke lapisan aplikasi (Cursor tiga tahun mencapai pendapatan tahunan 20 miliar)—ini setengah benar. Tetapi "pembuat lapisan dasar tidak menghasilkan uang" dibantah langsung oleh Nvidia: Laba bersih FY2026 sekitar $1200 miliar, kapitalisasi pasar 5 triliun+, adalah satu-satunya di pasar yang jelas menghasilkan keuntungan besar. Sedangkan lapisan model yang dia isyaratkan akan menang (OpenAI 2026 diperkirakan rugi sekitar $140 miliar) justru paling mirip dengan "lapisan dasar membakar uang tidak menghasilkan uang" yang dia katakan.
Dia tidak membedakan "lapisan dasar daya komputasi" dan "lapisan dasar model", juga tidak membedakan "pendapatan" dan "laba". Nilai pada tahun 2026 lebih ekstrem ditangkap oleh lapisan daya komputasi daripada tahun 2023, bukan berpindah ke lapisan aplikasi. Perlu ditambahkan: Yang merugi adalah penyedia cloud yang membeli chip, bukan Nvidia yang menjual chip—ini justru tempat kesalahan analogi "overbuild rel kereta api"-nya.
Hak Cipta (Pandangan 14)—Pendaftaran Benar, Menghindari Pelanggaran Salah
> Tahun 2023 Wang Jianshuo berkata: Konten buatan AI mungkin menghindari hak cipta (melindungi ekspresi bukan ide); hasil generasi mungkin tidak melanggar, juga tidak dapat didaftarkan.
"Tidak dapat didaftarkan" menjadi fakta hukum yang mapan (2025 Kantor Hak Cipta AS jelas menyatakan "hanya memasukkan prompt tidak cukup untuk mengklaim kepengarangan"). Tetapi "menghindari pelanggaran" jelas salah: Pengadilan berulang kali menentukan output AI jika mirip substansial dengan karya asli tetap melanggar hak cipta; Anthropic karena data pelatihan bajakan menyelesaikan dengan ganti rugi $1.5 miliar, ganti rugi hak cipta terbesar dalam sejarah AS. AI tidak hanya tidak "menghindari" hak cipta, malah membayar harga terbesar dalam sejarah.
Dunia Satu (Pandangan 15)—Mekanisme Benar, Tren Pertaruhan Terbalik
> Tahun 2023 Wang Jianshuo berkata: ChatGPT melakukan "rata-rata tertimbang" pada pandangan manusia, dapat melawan kapsul informasi ala TikTok, memberikan kemungkinan "dunia satu".
Lapisan mekanisme benar—2025 beberapa penelitian secara pasti membuktikan LLM menekan pandangan ke arah mayoritas, secara sistematis meremehkan minoritas. Tetapi penilaian sosialnya bertaruh terbalik: Dia sendiri menambahkan "setidaknya sekarang bukan seribu orang seribu wajah", dalam tiga tahun dibantah—OpenAI sejak April 2025 menjadikan memori lintas percakapan dan personalisasi sebagai kemampuan default, AI sedang bergerak cepat ke arah seribu orang seribu wajah. Yang lebih krusial, dia membayangkan "rata-rata tertimbang" sebagai angka konvensi dunia netral, tetapi pengukuran menunjukkan itu adalah pergeseran berarah, ditambah menjilat, dapat digunakan untuk memanipulasi posisi secara aktif—ini mengarah ke "menciptakan kapsul baru", bukan "menghilangkan polarisasi".
Perang Lokal dan Biaya (Pandangan 17)—Kualitatif Benar Semua, Kuantitatif Terbantah
> Tahun 2023 Wang Jianshuo berkata: Membuat model besar lagi akan dengan cepat menjadi "perang lokal", biaya dapat diketahui (menghilangkan jalan memutar sekitar 5-10 miliar dolar AS puncaknya), akan banyak pemain masuk.
Arah kualitatif benar dengan mengejutkan—banyak pemain masuk, cepat dikomersialkan, open source menyusul closed source, semuanya terwujud. Tetapi angka keras "5-10 miliar puncak" ini kedua ujung salah: Ujung depan sangat diremehkan (tingkat GPT-5 tahun 2026 mencapai 2-5 miliar dolar AS pelatihan, ditambah pusat data triliunan dolar dan Stargate 5000 miliar); ujung replika justru dianggap terlalu tinggi (DeepSeek menekan biaya pelatihan marjinal ke tingkat jutaan dolar AS). "Biaya" model yang sama menurut cara menghitung bisa berbeda 200 kali lipat, hanya saja tidak berada di rentang yang dia berikan.
Kemampuan Muncul (Pandangan 5)—Arah Benar, Angka dan Kerangka Salah
> Tahun 2023 Wang Jianshuo berkata: Di atas sekitar 60B parameter muncul kemampuan baru yang tidak ada dalam data mentah, dan peneliti juga tidak dapat menjelaskannya.
Intuisi arah terbukti, tetapi dua tempat ekspresi tidak bertahan: Pertama, tidak ada "ambang batas 60B" yang seragam—ambang batas nyata chain of thought sekitar 100B, kemampuan berbeda muncul pada skala 13B hingga 540B yang tidak sama; Kedua, "tidak dapat menjelaskan" pada akhir 2023 sudah ditantang oleh makalah terpilih NeurIPS—banyak "mutasi" adalah ilusi yang disebabkan oleh pemilihan metrik evaluasi, setelah mengganti metrik kontinu kurvanya halus dan dapat diprediksi. Adilnya, dulu dia mengulangi narasi yang benar-benar mainstream, yang benar-benar dapat dikoreksi adalah menganggap "60B" sebagai ambang batas keras, dan menganggap "tidak dapat menjelaskan" sebagai kesimpulan kualitatif.
Empat. Menilik Kembali Tiga Tahun, Beberapa Pola
Setelah mencocokkan satu per satu, mundur selangkah melihat, dalam dua puluh penilaian Wang Jianshuo ini tersembunyi beberapa pola yang lebih layak diingat daripada setiap butir tunggal.
Satu. Arah jauh lebih dapat diandalkan daripada angka dan tingkat. Dari dua puluh butir, semua yang menilai mekanisme dan arah (RAG, LUI, jaringan robot, tes Turing), hampir semua tepat; semua yang memberikan angka spesifik atau pernyataan pengunci (100T parameter, ambang batas 60B, biaya 5-10 miliar, matematika "tidak mungkin"), hampir semua salah. Untuk bidang yang berubah cepat, pertaruhkan arah, pertaruhkan mekanisme, sedikit pertaruhkan angka tepat, dan lebih waspada terhadap kata-kata seperti "tidak mungkin, pasti, puncak, sama sekali tidak" yang membuat perkataan penuh—ini adalah area frekuensi tinggi yang ditampar waktu.
Dua. Dalam waktu, dia cenderung melebih-lebihkan kecepatan, meremehkan tingkat. Semua yang mengatakan "cepat, diselesaikan dalam dua tiga tahun", periode matangnya umum lebih lambat; tetapi untuk plafon lompatan kemampuan justru diremehkan—matematika bisa dari "tidak mungkin" menjadi medali emas IMO, biaya depan bisa naik ke tingkat yang tak terbayangkan dulu. Satu kalimat: terlalu optimis jangka pendek, terlalu konservatif jangka panjang.
Tiga. Kesalahan paling tersembunyi, berulang muncul pada "distribusi". Bukan arah salah, tetapi hanya melihat total, mengabaikan distribusi. "Tidak akan ada gelombang pengangguran" benar, tetapi kerusakan sangat terkonsentrasi pada pemula muda; "Nilai jatuh di lapisan aplikasi" benar setengah, tetapi tidak membedakan lapisan daya komputasi dan lapisan model. Total benar, menutupi bencana distribusi—ini adalah pelajaran yang paling harus ditambahkan.
Empat. Tempat yang membuat perkataan dengan ruang, tiga tahun kemudian dapat diuji. "Kabar burung" "setidaknya sekarang" "menurunkan secara signifikan bukan menghilangkan" "prototipe dua tiga tahun, matang sekitar sepuluh tahun"—semua penilaian yang dulu membawa kata pembatas, berlapis, hari ini dilihat kembali lebih dapat bertahan. Sebaliknya, kalimat absolut yang keluar tanpa berpikir, paling mudah terbalik. Kejujuran prediksi, setengahnya berani berkata, setengah lainnya berani menandai ketidakpastian sendiri.
Lima. Beberapa masalah, tiga tahun sama sekali tidak cukup. Nilai akhirnya milik siapa, muncul bukan kebenaran berubah, mesin sebenarnya punya tidak secuil kesadaran, konteks panjang akan makan RAG—perdebatan-perdebatan ini dulu, hingga 2026 masih tetap perdebatan. Dapat membedakan "yang sudah ada jawabannya" dan "yang masih harus ditunggu", lebih penting daripada buru-buru memberi kesimpulan untuk setiap hal.
Wang Jianshuo tiga tahun lalu, mengandalkan intuisi dalam kabut sebelum GPT-4 keluar, menunjuk dua puluh arah. Hari ini setelah mencocokkan, kalimat yang paling harus diingat mungkin adalah: Melihat arah besar benar sebenarnya tidak terlalu sulit, sulitnya adalah mengakui bahwa diri sendiri dalam angka, kecepatan, dan distribusi berulang kali berpikir seenaknya. Dua puluh butir pencocokan ini, lebih tepatnya adalah memberi nilai masa lalu, lebih baik lagi adalah mendirikan beberapa aturan untuk tiga tahun ke depan. Tiga tahun berikutnya, 2029 datang lagi untuk mencocokkan sekali lagi.