Catatan Editor: Belakangan ini, diskusi tentang AI dan pekerjaan hampir didominasi oleh satu pertanyaan: Dengan kemampuan model yang terus meningkat, apakah posisi pekerjaan kerah putih akan digantikan secara masif? Dari pembuatan kode, otomatisasi layanan pelanggan hingga produksi konten, Agen secara terus-menerus mengambil alih pekerjaan pengetahuan yang sebelumnya membutuhkan manusia. Pengujian patokan juga terus memperkuat kecemasan ini: Kinerja model dalam penalaran tingkat pascasarjana, tugas ekonomi nyata, dan refaktorisasi kode tingkat insinyur senior meningkat dengan cepat, seolah-olah mendekati titik kritis "pekerjaan manusia dilahap oleh otomatisasi".
Namun, CEO Every, Dan Shipper, dalam artikel ini menyajikan observasi sebaliknya: Semakin banyak otomatisasi, justru semakin banyak pekerjaan yang harus dilakukan manusia. Every adalah pengguna aktif Agen AI dalam, mereka telah menanamkan alat seperti Codex, Claude Code, Slack Agent, Agen layanan pelanggan ke dalam proses pengodean, penulisan, desain, layanan pelanggan, dan manajemen. Hasilnya bukanlah karyawan digantikan secara total, melainkan transformasi bentuk pekerjaan: Insinyur tidak lagi hanya menulis kode, tetapi meninjau, merestrukturisasi, dan mendesain sistem; Editor tidak lagi hanya menulis naskah, tetapi menilai apa yang layak ditulis dan bagaimana menulisnya dengan cara yang berbeda; Staf layanan pelanggan tidak lagi menangani setiap tiket dasar, tetapi memelihara sistem yang dapat merespons pelanggan secara otomatis.
Apa yang paling patut diperhatikan dalam artikel ini bukanlah "apakah AI dapat menyelesaikan suatu tugas", tetapi bagaimana AI mendefinisikan ulang posisi manusia dalam pekerjaan pengetahuan. AI unggul dalam membuat kemampuan yang telah tersimpan di masa lalu menjadi murah: kode, teks konten, gambar thumbnail, respons layanan pelanggan, deskripsi produk, laporan penelitian, semua dapat dihasilkan dengan cepat oleh model. Namun, ketika kemampuan ini dapat diakses oleh semua orang, yang sering muncul di pasar bukanlah output yang berkualitas dan terdiferensiasi, melainkan banyak output "standar" yang tampak serupa, kurang pertimbangan, dan konteks. Dengan kata lain, AI mengomersialkan "kemampuan manusia kemarin", sementara yang benar-benar langka adalah kemampuan penilaian dalam menghadapi masalah spesifik di masa kini.
Oleh karena itu, otomatisasi tidak menghilangkan para ahli, justru menciptakan lebih banyak skenario yang memerlukan intervensi ahli. Ketika staf operasional dapat menggunakan AI untuk mengirimkan kode, insinyur perlu menilai kode mana yang layak digabungkan; Ketika staf pemasaran dapat menghasilkan gambar thumbnail dalam beberapa detik, desainer perlu menilai apa yang sesuai dengan tujuan merek dan komunikasi; Ketika insinyur juga bisa menulis artikel, editor perlu mengubah draf awal menjadi konten yang benar-benar memiliki sudut pandang, struktur, dan siap diterbitkan. AI memperluas radius produksi, tetapi juga memperbesar kebutuhan akan kontrol kualitas, pembangunan sistem, penentuan batasan, dan ekspresi yang berbeda.
Penulis selanjutnya menggunakan pengujian patokan untuk menjelaskan paradoks ini. Baik Senior Engineer Benchmark, maupun GDPval OpenAI, skor model tidak mengukur "kecerdasan itu sendiri" dalam arti abstrak, tetapi kinerja model dalam kerangka masalah tertentu. Prompt, batas tugas, standar evaluasi, format output, di belakangnya sudah mengandung banyak pertimbangan manusia. Model dapat dengan cepat meningkat dalam kerangka tertentu, tetapi kerangka itu sendiri ditetapkan oleh manusia; ketika suatu kerangka berhasil ditaklukkan model, manusia akan mendorong masalah ke kerangka baru yang lebih kompleks.
Ini juga merupakan tanggapan paling menarik artikel ini terhadap kecemasan AGI: Meskipun model semakin kuat, yang dikejarnya sering kali adalah batas tertentu yang digambar manusia, bukan sang penggambar batas itu sendiri. AI dapat mengeksekusi tujuan, mengoptimalkan jalur, meningkatkan efisiensi, tetapi selama ia masih merespons masalah yang ditetapkan manusia, ia masih kekurangan subjektivitas yang sebenarnya. Masa depan pekerjaan pengetahuan bukanlah manusia yang menghilang dari proses, tetapi beralih dari pelaksana menjadi perancang kerangka, pemelihara sistem, penilai kualitas, dan penentu makna.
Setelah otomatisasi, nilai pekerjaan manusia tidak hilang, hanya menjadi lebih sulit, lebih maju, dan lebih bergantung pada penilaian. AI membuat "bisa melakukan" menjadi murah, tetapi membuat "mengetahui apa yang layak dilakukan, mengapa dilakukan, dan sejauh apa yang dianggap baik" menjadi lebih langka.
Berikut adalah teks aslinya:
Di inti AI, ada sebuah paradoks.
Di Every, kami telah mengotomatisasi sebanyak mungkin hal yang bisa diotomatisasi. Baik itu pengodean, penulisan, desain, layanan pelanggan, atau pekerjaan rutin lainnya, kami menggunakan Codex dan Claude Code. Kami juga berpartisipasi dalam pengujian alpha sebelum model baru OpenAI, Anthropic, Google dirilis secara resmi. Bisa dikatakan, kami sedang menumpang secepat dan sedalam mungkin pada gelombang peningkatan eksponensial kecerdasan dan kemampuan otomatisasi model.
Tapi kontradiktifnya, bagi kami, pekerjaan yang harus diselesaikan manusia tampaknya lebih banyak dari sebelumnya. Every saat ini adalah tim yang mendekati 30 orang, kami tidak memecat semua karyawan karena memiliki Agen; juga tidak meninggalkan alat SaaS sepenuhnya bergantung pada aplikasi yang dibuat dengan vibe coding. Kami masih merekrut staf layanan pelanggan sungguhan, hanya mereka akan mendapatkan banyak bantuan Agen; kami juga masih merekrut penulis, editor, dan insinyur.
Namun, bentuk pekerjaan memang telah mengalami perubahan besar. Kami hampir tidak pernah lagi menulis kode secara manual. Jika Anda @ seseorang di Slack, apakah itu manusia atau Agen, terkadang sulit dibedakan. Manajer mulai mengirimkan kode seperti kontributor individu lini depan, insinyur juga mulai menghadapi pelanggan secara langsung. Beberapa minggu terakhir, 95% email kerja saya dibalas oleh AI. Kotak masuk saya hampir selalu dalam keadaan kosong — ini sangat langka bagi saya — tapi saya tetap memeriksa setiap email satu per satu.
Dengan kata lain, masa depan terlihat asing, tapi sekaligus sangat familiar.
"Kefamiliaran" ini sendiri mengejutkan. Karena baik CEO, pekerja pengetahuan, maupun investor, tampaknya semakin percaya pada satu hal yang sama: AI mengancam pekerjaan, ekonomi, keamanan, bahkan makna pekerjaan manusia.
CEO Anthropic Dario Amodei pernah memperingatkan, AI mungkin menghilangkan hingga separuh posisi pekerjaan kerah putih tingkat pemula. Meta baru saja memecat 8.000 orang, dan mulai memasang perangkat lunak di komputer karyawan AS, merekam pergerakan mouse, klik, dan input keyboard, untuk mendapatkan data pelatihan pekerjaan pengetahuan tingkat lanjut yang lebih berkualitas.
Bahkan pendiri Citadel Ken Griffin juga tampak cukup terguncang. Dia baru-baru ini menyatakan: "Ini bukan posisi kerah putih menengah-rendah, melainkan posisi dengan keterampilan sangat tinggi, sedang diotomatisasi — saya pertimbangkan kata ini — oleh Agentic AI."
Berbagai pengujian patokan tampaknya juga mendukung penilaian ini. Dengan dirilisnya generasi model baru, indikator kemampuan model meningkat dengan kecepatan hampir eksponensial. Dalam uji penalaran tingkat pascasarjana Humanity』s Last Exam, skor model teratas naik dari angka rendah setahun lalu menjadi sekitar 44% sekarang. Dalam GDPval, pengujian yang mengukur kemampuan model mutakhir menyelesaikan pekerjaan ekonomi nyata dan membandingkannya dengan kinerja manusia, skor model juga melonjak dari posisi rendah serupa menjadi sekitar 85%. Mei tahun ini, lembaga nirlaba penelitian keamanan AI METR merilis hasil pengujian awal Claude Mythos: pada beberapa tugas yang membutuhkan waktu sekitar 4 jam bagi ahli manusia untuk menyelesaikannya, tingkat keberhasilan model ini mencapai 80%.
Tampaknya, kita seolah berdiri di depan titik kritis: Sebuah AI yang lebih pintar dari manusia mana pun, dan mampu bekerja secara mandiri hampir sepanjang hari, sedang mendekati kenyataan.
Namun, paradoks tetap ada. Jika Anda berbicara dengan praktisi industri AI, atau dengan orang-orang di luar industri yang paling awal menggunakan AI, Anda akan mendengar kesimpulan yang sama dengan observasi internal kami: pekerjaan yang harus dilakukan justru lebih banyak dari sebelumnya.
Pertanyaan yang benar-benar dipedulikan baik di dalam maupun luar industri adalah: Apakah ini hanya keadaan transisi? Akankah rilis model berikutnya menjadi momen yang benar-benar menggantikan semua orang? Kami menatap kurva pengujian patokan, sambil bersemangat dan gugup, khawatir suatu titik balik akan datang kapan saja, di mana banyak pekerjaan tiba-tiba lenyap.
Tapi saya rasa, tidak akan ada "titik kritis" seperti itu yang tiba-tiba datang, membuat segalanya berbalik seketika, membuat pekerjaan menghilang secara masif. Kenyataan baru justru sebaliknya: Semakin tinggi tingkat otomatisasi, pekerjaan yang memerlukan partisipasi ahli manusia justru semakin banyak.
Alasannya adalah, AI sedang mengomersialkan bagian-bagian dari kemampuan profesional manusia yang dapat diungkapkan dengan jelas, dilatih, dan direplikasi. Semua pengetahuan yang bisa ditulis menjadi aturan, diendapkan sebagai proses, diubah menjadi data pelatihan, akan perlahan menjadi kemampuan standar model. Hasilnya, nilai output model biasa dengan cepat ditekan, dan pasar mulai lebih membutuhkan hal-hal yang berbeda.
Dan kebutuhan akan "sesuatu yang berbeda" pada dasarnya adalah kebutuhan akan ahli manusia. Bahkan jika kita mendekati kecerdasan buatan umum, hal ini tidak akan hilang.
Untuk memahami alasannya, kita tidak bisa hanya melihat kurva pengujian patokan, atau hanya fokus pada daftar peringkat parameter dan kemampuan model. Kita harus kembali ke skenario pekerjaan nyata hari ini, melihat bagaimana AI sebenarnya digunakan. Hanya dengan begitu, kita dapat benar-benar memahami paradoks ini, serta jawaban di baliknya.
Bagaimana Kami Sampai pada Titik Ini
Sejak 2022, kami terus memantau dampak Agen terhadap pekerjaan di masa depan.
Tiga tahun lalu, saya pernah menulis artikel tentang "ekonomi alokasi" (allocation economy). Penilaian saya saat itu adalah, berkolaborasi dengan alat AI pada akhirnya akan semakin mirip dengan pekerjaan manajer manusia: Anda tidak lagi melakukan setiap tindakan sendiri, melainkan memecah tugas, mengalokasikan, mengawasi, dan menerima hasil. Saat itu, tanya-jawab paling dasar di ChatGPT masih dianggap oleh banyak orang sebagai sesuatu yang sangat futuristik, bahkan agak mengganggu.
Menjelang pertengahan 2025, perusahaan Every hampir sepenuhnya "Claude Code-ized". Manajer Umum Cora, Kieran Klaassen, tiba-tiba menyadari bahwa dia bisa berhenti menulis kode secara manual, dan sepanjang hari memberikan instruksi dalam bahasa alami kepada Agen pemrograman di terminal. Cara kerja ini dengan cepat menyebar ke seluruh perusahaan. Sekitar 12 bulan lalu, saya mengatakan di Lenny』s Podcast bahwa Claude Code adalah alat yang paling diremehkan dalam pekerjaan pengetahuan.
Saya menyebutkan ini karena beberapa penilaian kami yang paling akurat sebelumnya seringkali berasal dari mengamati Every sebagai laboratorium pengguna awal. Banyak pola kerja baru akan muncul terlebih dahulu di internal kami; setelah teknologi semakin matang dan alat menjadi lebih mudah digunakan, pola-pola ini baru akan secara bertahap masuk ke pasar yang lebih luas.
Dan sekarang, perubahan baru sedang terjadi di internal kami.
Dua Mode Kolaborasi dengan Agen
Cara kerja di sekitar AI sedang secara bertahap menyatu menjadi dua mode yang sangat berbeda.
Pertama, adalah arah yang sudah cukup akurat diprediksi dalam diskusi AI sebelumnya: menggunakan Agen sebagai karyawan. Agen seperti ini dapat didelegasikan tugas. Beberapa Agen berada di Slack, memiliki nama dan tanggung jawab sendiri, ketika Anda membutuhkannya, Anda bisa langsung @; beberapa Agen lainnya tertanam dalam alur kerja yang berjalan terus-menerus, seperti sistem layanan pelanggan, sebagai pintu masuk dan penyaring tugas berulang sepanjang hari.
Mode kedua lebih asing, tapi dalam pengalaman saya, juga lebih penting. Ini mengacu pada kolaborasi manusia dengan Agen dalam alat seperti Codex, Claude Code, Claude Cowork. Alat-alat ini bukan hanya tempat untuk mendelegasikan tugas, mereka sedang menjadi sistem operasi pekerjaan itu sendiri: Anda dan beberapa Agen menggunakan "komputer" yang sama, berkolaborasi dalam lingkungan kerja yang sama, menyelesaikan tugas yang sangat kompleks, orisinal, dan tidak dapat dengan mudah diberikan kepada Agen asinkron.
Dalam kedua mode ini, Anda dapat menggunakan AI untuk mengotomatisasi dan mendelegasikan sebagian besar pekerjaan. Tapi agar kedua mode ini benar-benar berjalan dengan baik, Anda, atau manusia lain, masih perlu terlibat di dalamnya.
Agen Karyawan
Agen karyawan adalah ketika Anda memberikan tugas, ia meninggalkan partisipasi real-time Anda, dan secara mandiri menghasilkan jawaban, tindakan, laporan, draf awal, atau penilaian pengalihan.
Agen semacam ini setidaknya memiliki dua bentuk: satu adalah "Agen kolega", yang lain adalah "Agen tertanam".
1. Agen Kolega
Agen kolega adalah yang bisa Anda panggil di Slack seperti Anda memanggil kolega, untuk menyelesaikan suatu pekerjaan. Ia selalu ada, dapat dipanggil kapan pun dibutuhkan. Produk seperti OpenClaw, atau Plus One yang kami kembangkan internal, termasuk dalam tipe ini.
Claudie
Claudie adalah Agen kolega yang digunakan oleh tim konsultasi kami. Ia menulis proposal penjualan, menghasilkan draf awal materi pelatihan, melacak daftar tugas proyek, dan dapat menangani lebih banyak pekerjaan serupa.
Andy
Andy adalah Agen kolega yang digunakan oleh tim editorial kami. Ia mengumpulkan "titik bahan" yang layak dikembangkan lebih lanjut dari Slack internal perusahaan — yaitu ide bagus yang mungkin berkembang menjadi artikel — dan mengorganisirnya menjadi ringkasan dan sudut pandang awal, untuk digunakan penulis dalam menyusun newsletter harian.
Viktor
Viktor adalah Agen serbaguna yang akan menangani pekerjaan lintas departemen di internal perusahaan. Kami menggunakannya untuk mengumpulkan metrik pertumbuhan, menganalisis hasil survei pengguna, dan juga memintanya mengorganisir diskusi internal yang berantakan menjadi memo penelitian dan saran produk.
2. Agen Tertanam
Agen tertanam ada dalam alur kerja produk tertentu. Fleksibilitasnya tidak seperti Agen kolega, tetapi dalam menangani tugas berulang, mereka sering kali sangat kuat.
Fin adalah contoh paling jelas. Ini adalah Agen yang tertanam di platform layanan pelanggan kami, dapat menangani banyak pekerjaan layanan pelanggan melalui chat dan email.
Pada satu minggu di bulan Mei tahun ini, Fin berpartisipasi dalam 65% dari semua 202 percakapan layanan pelanggan Every, dan secara mandiri menutup 81 tiket di antaranya tanpa intervensi manusia, atau 40.1% dari semua percakapan yang dapat ditangani.
Agen tertanam semacam ini memungkinkan manajer layanan pelanggan kami, Waqqas Mir, menghabiskan lebih sedikit waktu membalas tiket dasar, dan lebih banyak fokus membangun "sistem yang dapat merespons tiket secara otomatis", serta menangani kasus pelanggan yang membutuhkan sentuhan lebih tinggi dan penilaian yang lebih kompleks.
Kolaborasi Manusia dan AI
Baik Agen kolega maupun Agen tertanam, pola di baliknya konsisten: Agen karyawan sedang mengambil alih lebih banyak lapisan pekerjaan yang stabil, berulang, dan batasannya jelas.
Tapi masih banyak pekerjaan yang harus melibatkan manusia. Kami berulang kali menemukan, selama tugasnya cukup kompleks, cara terbaik untuk mendapatkan hasil yang benar-benar berkualitas tinggi bukanlah dengan menyerahkan pekerjaan sepenuhnya kepada AI, melainkan membiarkan AI dan manusia berkolaborasi bolak-balik di ruang kerja yang sama.
Inilah tepatnya nilai dari alat-alat seperti Codex, Claude Code, dan Cowork. Mereka memungkinkan Anda meluncurkan satu atau lebih Agen di beberapa thread chat, dan mendelegasikan tugas kepada mereka. Agen-agen ini dapat mengakses komputer Anda, serta semua sumber data terkait. Anda bisa melihat apa yang sedang dilakukan setiap Agen, bagaimana ia berpikir, dan dapat menginterupsinya kapan saja.
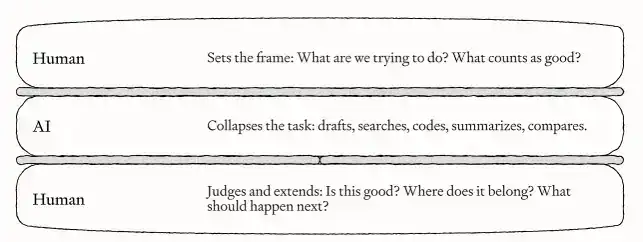
Sementara itu, Anda masih bertanggung jawab mengelola Agen-agen ini: memberikan arah yang jelas di awal setiap tugas, memeriksa kualitas di akhir tugas, memastikan hasilnya cukup baik, dan terus menemukan pekerjaan berikutnya yang layak dilanjutkan. Kieran menyebut peran ini sebagai manusia "roti sandwich" — AI bertanggung jawab atas bagian pekerjaan tengah, sementara manusia seperti dua iris roti, terjepit di awal dan akhir tugas.
Contoh paling khas adalah menulis kode. Di Every, insinyur hampir sepanjang hari berkolaborasi bolak-balik dengan Agen. Mereka bersama-sama merencanakan fitur baru atau memperbaiki bug, meninjau pekerjaan yang telah selesai; jika mengadopsi konsep "rekayasa majemuk" (compound engineering) yang kami sebut, mereka juga akan terus menyesuaikan sistem mereka sendiri, membuatnya semakin mudah digunakan seiring waktu.
Tapi cara kolaborasi ini jauh melampaui pengodean.
Sistem Operasi Baru untuk Pekerjaan Pengetahuan
Codex dan Claude Code sedang menjadi sistem operasi kerja yang baru. Saya hampir sepanjang hari berada di Codex, menjalankan berbagai alat SaaS melalui browser internalnya. Ini memungkinkan saya membawa Agen ke setiap skenario kerja, dan mencapai tingkat kerja yang tidak dapat saya capai sendiri.
Menulis
Artikel ini saya tulis di browser internal Codex, menggunakan Proof. Codex akan mengamati apa yang saya tulis, dan dapat kapan saja meluncurkan sub-Agen untuk menyelesaikan tugas apa pun yang saya butuhkan: menyusun draf awal suatu paragraf, mencari contoh untuk bagian berikutnya, atau melakukan penyuntingan dan penyempurnaan teks.
Saat menangani email, saya juga menggunakan cara yang sama. Cora adalah klien email saya, saya membukanya di browser internal Codex, sambil menjelajahi kotak masuk, saya membicarakan pemikiran untuk menangani setiap email melalui Monologue. Sisanya, diserahkan kepada Codex dan Cora untuk diselesaikan.
Setiap Agen Membutuhkan Satu Manusia
Dalam semua skenario otomatisasi di atas, Anda mungkin sudah bisa melihat di mana manusia benar-benar berperan. Dalam setiap contoh, Agen memerlukan partisipasi manusia agar pekerjaan itu sendiri benar-benar berjalan.
Pasti ada yang mengarahkannya ke masalah yang benar, menilai apakah outputnya cukup baik, menemukan kesalahan di dalamnya, dan mengubah hasil menjadi keputusan atau proses di dunia nyata.
Semakin jauh sebuah Agen dari manusia yang bertanggung jawab mengawasi kinerjanya, semakin buruk efektivitas kerjanya. Dalam promosi internal awal, kami pernah melengkapi setiap karyawan dengan sebuah Agen. Tapi segera, kami kembali ke penggunaan Agen yang melayani tim tertentu, atau melayani seluruh perusahaan, bukan melayani individu tunggal.
Alasannya sederhana: Agen membutuhkan banyak perawatan. Agen pribadi begitu penggunanya berhenti mengikuti, akan cepat menjadi usang dan tidak berfungsi. Kami memiliki tim insinyur AI yang secara khusus bertanggung jawab memastikan Agen-agen ini dapat bekerja dengan stabil dan efektif. Dan dalam masa mendatang yang dapat diprediksi, kami masih membutuhkan tim ini. Bahkan tugas yang tampaknya sederhana seperti "menghasilkan PowerPoint secara otomatis" bisa berkembang menjadi proyek rekayasa yang besar. Salah satu alur otomatisasi PowerPoint kami, misalnya, mencakup 24 keterampilan dan 18 skrip, dengan biaya token untuk menghasilkan satu presentasi mencapai 62 dolar.
Ini adalah alasan pertama mengapa Agen justru menciptakan lebih banyak pekerjaan bagi manusia.
Tapi ada alasan kedua.
Mengapa Otomatisasi Justru Membuat Pekerjaan Manusia Lebih Banyak
Jika Anda mengamati peningkatan kemampuan AI yang eksponensial dalam beberapa tahun terakhir, dan menggabungkannya dengan cara arsitektur dan sumber kemampuannya, Anda akan menemukan seperangkat siklus umpan balik yang jelas: mereka terus-menerus menciptakan lebih banyak pekerjaan manusia.
AI Membuat "Kemampuan Manusia Kemarin" Menjadi Murah
Model bahasa besar saat ini dilatih pada jejak yang terlihat dari kemampuan manusia: kode, artikel, gambar, tiket layanan pelanggan, dokumen spesifikasi produk, dan lebih banyak konten lainnya. Mereka menyerap konten ini, yaitu "asap buangan" dari tugas yang telah berhasil diselesaikan, lalu membungkusnya kembali dalam bentuk berbiaya rendah yang dapat diakses semua orang.
Hasilnya, banyak kemampuan yang sebelumnya langka, seperti mengirimkan PR kode, membuat gambar thumbnail YouTube, menulis newsletter, kini hampir terbuka untuk semua orang.
Kemampuan Murah Akan Cepat Diadopsi
Ketika sesuatu yang sebelumnya langka turun biayanya, pasokannya akan meningkat dengan cepat.
Di Every, kami terus melihat perubahan ini. Staf operasional dan layanan pelanggan mulai menulis kode, mengirimkan pull request; staf pemasaran mulai membuat gambar thumbnail YouTube; insinyur dan staf produk juga mulai menulis artikel, panduan, dan draf awal laman arahan, yang sebelumnya bukan pekerjaan yang biasa mereka lakukan.
Perubahan ini juga terjadi di luar Every. Sebagai contoh, proyek Agen AI sumber terbuka OpenClaw, per 16 Mei 2026, repositori kodenya telah menerima 44.469 pull request, di antaranya 12.430 berasal setelah 1 April, 3.990 berasal setelah 1 Mei. Ini adalah jumlah yang mencengangkan. Sebagai perbandingan, Kubernetes sebagai salah satu proyek sumber terbuka paling populer di dunia, jumlah pull request yang diterima sepanjang 2022 hanya 5.200.
Kelimpahan Membawa Keseragaman: Kemampuan Ahli Lama Dikomersialkan
Karena semua orang dapat menggunakan model yang sama, dan model-model ini dibangun di atas "kemampuan manusia kemarin", maka secara default, output model sering berada di antara "titik awal yang lumayan" dan "konten sampah AI murni".
"Konten sampah" yang dimaksud di sini bukanlah kesalahan spesifik tertentu. Bukan terlalu banyak menggunakan tanda hubung, bukan frasa tertentu, juga bukan titik-titik ungu yang muncul di mana-mana di laman arahan. Ini mengacu pada keseragaman yang terlihat jelas, berulang, dan menjengkelkan.
Ketika manusia di berbagai skenario menggunakan alat yang sama, dan alat ini dilatih berdasarkan korpus yang sama, dan pengguna tidak melakukan penilaian yang cukup mendalam, hasil seperti ini akan terjadi. Dengan kata lain, ketika setiap orang memiliki "ahli" dengan kecenderungan dan gaya default yang sama, keseragaman akan terjadi secara alami.
Ketika staf operasional dapat mengirimkan pull request, staf pemasaran dapat menghasilkan gambar thumbnail YouTube dalam beberapa detik, dan insinyur juga mulai menulis panduan produk, mudah sekali muncul situasi seperti ini: output Anda meningkat secara kuantitas, tetapi kualitas, konsistensi, dan diferensiasi karya justru menurun.
Dan ketika keseragaman menjadi terlalu berlimpah, ia akan cepat menjadi komoditas.
Keseragaman Menciptakan Kebutuhan akan Diferensiasi
Karena adanya internet, manusia dapat dengan cepat mengenali apa itu konten "berbau AI" yang terlalu banyak diproduksi secara massal. Karya apa pun bisa langsung sampai ke orang lain di dunia, dan faktanya sering demikian. Begitu terlalu banyak hal mulai terlihat sama, kita segera menyadari ada yang tidak beres.
Ini berarti, ketika Anda pertama kali melihat kemampuan model baru, Anda mungkin terkesima, bahkan sedikit takut. Tapi beberapa bulan kemudian, kemampuan itu akan menjadi biasa. Bukan modelnya melemah, tapi standar Anda berubah.
Kami tidak lagi puas dengan aplikasi React sembarangan, atau laporan penelitian sembarangan. Kami menginginkan sesuatu yang benar-benar sesuai dengan individu, perusahaan, atau skenario spesifik. Ia harus terasa akurat, hidup, spesifik, bukan murah, general, template. Kami berharap biaya produksinya, baik waktu maupun uang, jelas lebih tinggi daripada biaya konsumsi kami.
Kami menginginkan sesuatu yang membawa "rasa status". Dan setiap kali teknologi baru membuat hal-hal berstatus tinggi di masa lalu menjadi murah, manusia selalu ahli dalam menciptakan permainan status baru, untuk mencocokkan batas kemampuan baru.
Ketika pekerjaan menjadi terlalu berlimpah, dan di mana-mana terlihat sama, pekerjaan yang tidak sesuai dengan pola yang ada justru akan menjadi hal yang langka, berharga, dan memiliki sifat status tinggi.
Kebutuhan akan Diferensiasi, Pada Dasarnya adalah Kebutuhan Baru akan Ahli
Karena karakteristik arsitektur model bahasa, serta distribusi luas mereka kepada hampir semua orang, pekerjaan yang langka dan berharga, tetap harus berasal dari manusia.
Generasi model saat ini hanya tahu pekerjaan yang pernah terjadi, yang pernah diselesaikan. Yang manusia ketahui adalah: saat ini, apa yang benar-benar perlu dilakukan.
Begitu suatu situasi spesifik direduksi menjadi teks, begitu ia masuk ke korpus, ia sudah menjadi "hal masa lalu". Manusia menghadapi momen, pelanggan, basis kode, percakapan yang spesifik, sementara korpus pelatihan tidak benar-benar hidup di saat ini. Keadaan "hidup" ini bukan hanya memiliki data yang lebih baru. Kami membawa asal-usul kami sendiri ke masa kini, juga membawa keinginan, keprihatinan, dan penilaian yang terus berubah, untuk memahami apa yang penting. Perspektif yang terus diperbarui inilah yang mengubah apa yang kami lihat. Model dapat masuk ke perspektif ini setelah diberi prompt, tapi sebelum diprompt, ia tidak secara alami memiliki perspektif ini.
Inilah tepatnya paradoks yang kami sebutkan di awal: Membuat pekerjaan ahli menjadi lebih murah, tidak dengan sederhana menggantikan ahli. Sebaliknya, ia menciptakan lebih banyak skenario yang memerlukan penilaian ahli.
Ketika staf operasional dengan bantuan AI mengirimkan pull request, Anda memerlukan insinyur untuk meninjau.
Ketika staf pemasaran membuat gambar thumbnail YouTube, Anda memerlukan desainer untuk menyempurnakannya lebih lanjut.
Ketika insinyur mulai menulis artikel, Anda memerlukan penulis dan editor untuk mengubah draf awal menjadi konten yang benar-benar dapat dibaca dan dapat diterbitkan.
Menyikapi ini, ahli manusia akan bergerak ke dua arah sekaligus.
Sebagian ahli akan menggunakan AI untuk membangun sistem, untuk menyerap dan memanfaatkan banjir pekerjaan tambahan ini: antrian peninjauan, sistem evaluasi, kerangka kerja, aturan basis kode, file instruksi Claude dan Codex, integrasi berkelanjutan (CI), manajemen izin, serta alur kerja yang dapat mengubah draf awal menjadi hasil berkualitas tinggi.
Ahli lainnya akan menggunakan bantuan AI untuk menyelesaikan pekerjaan yang lebih besar dan lebih menarik yang tidak dapat mereka selesaikan sendiri di masa lalu. Misalnya, mencari kerentanan dalam sistem operasi seperti macOS biasanya memerlukan waktu berminggu-minggu bahkan berbulan-bulan. Tetapi perusahaan keamanan kecil bernama Calif, dengan bantuan Mythos Preview dari Anthropic, berhasil menemukan kerentanan memori kernel macOS publik pertama yang terjadi pada perangkat keras Apple M5 dalam waktu 5 hari.
Inilah mengapa dalam praktiknya, AI tidak akan menghilangkan pekerjaan pengetahuan tingkat ahli. Yang benar-benar dibawanya adalah peningkatan drastis dalam volume pekerjaan. Dan pekerjaan tambahan ini, hanya setelah melibatkan manusia, barulah dapat menjadi berbeda dan berharga.
Saya tidak sedang berargumen bahwa AI akan menciptakan lebih banyak pekerjaan untuk semua posisi. Sistem ekonomi sangat kompleks, dan yang dapat diamati langsung oleh Every adalah pekerjaan pengetahuan tingkat ahli. Faktanya, pekerjaan semacam ini sedang dibentuk ulang oleh AI, dan banyak perusahaan sedang mengorganisir diri mereka sendiri kembali di sekitar teknologi baru.
Tapi yang ingin saya tekankan adalah, apa pun pekerjaan yang Anda lakukan saat ini, ada satu bentuk pekerjaan yang secara struktural akan selalu berada di depan model: yaitu menggunakan model, untuk memecahkan masalah yang benar-benar Anda lihat saat ini. Masa depan pekerjaan pengetahuan sedang menuju ke sini.
Lalu, Bagaimana dengan Pengujian Patokan yang Tumbuh Eksponensial?
Bantahan paling jelas adalah: Lihatlah peningkatan pengujian patokan yang eksponensial itu. Semua yang Anda katakan sekarang hanyalah sementara, tunggu saja, cepat atau lambat model akan menyusul.
Tapi ada jebakan yang perlu diwaspadai di sini. Sebut saja "kegilaan grafik": Jika Anda terus-menerus menatap prediksi rentang waktu METR, membaca "AI 2027", dan sepenuhnya mengandalkan ekstrapolasi kurva daya komputasi untuk membangun penilaian tentang masa depan, Anda mudah sekali mengembangkan intuisi yang menakutkan tentang kemajuan model.
Tapi cara terbaik untuk menanggapi masalah ini bukan hanya membayangkan seperti apa model masa depan nanti. Tentu, ini juga bagian dari analisis. Yang lebih penting, kita perlu melihat bagaimana sebenarnya pengujian patokan ini dirancang. Hanya dengan begitu, kita dapat lebih akurat memahami apa sebenarnya yang mereka tunjukkan, dan apa hubungan mereka dengan skenario kerja nyata sebelumnya.
Kita akan menemukan satu karakteristik struktural: Semua pengujian patokan terjadi dalam suatu "kerangka" tertentu. Untuk mengukur sesuatu, Anda harus membekukan suatu masalah menjadi bentuk statis yang dapat diukur. Begitu kerangka ini ditaklukkan oleh model, hanya dengan sedikit mengubah kerangka, skor bisa kembali ke posisi rendah. Tentu, model akan terus maju dalam kerangka baru, tetapi proses yang sama akan terus berulang.
Oleh karena itu, kemajuan eksponensial pada pengujian patokan tertentu adalah nyata; tetapi dengan mengubah kerangka pengujian, kemajuan ini akan kembali tampak kecil. Ciri "fraktal" yang ditunjukkan oleh jenuhnya pengujian patokan, sebenarnya adalah reka ulang paradoks yang sama yang selalu kita bahas, tetapi di tingkat grafik.
Kita dapat melihat mekanisme ini bekerja melalui pengujian patokan di dunia nyata.
Bagaimana Pengujian Patokan Dirancang
Kami membangun pengujian patokan internal, disebut Senior Engineer Benchmark, atau "Pengujian Patokan Insinyur Senior". Sesuai namanya, ini digunakan untuk menguji kemampuan model mutakhir dalam tugas pengodean tingkat insinyur senior, seperti restrukturisasi besar-besaran.
Pengujian ini memberikan Agen pemrograman basis kode produksi yang sudah tidak terkendali. Ini berasal dari basis kode nyata Proof: awalnya saya tulis dengan vibe coding, kemudian masalah semakin banyak, akhirnya terpaksa meminta seorang insinyur senior untuk memperbaikinya.
Agen mendapatkan basis kode sebelum perbaikan, sambil menerima instruksi seperti yang Anda berikan kepada insinyur senior: "Ini adalah hasil vibe coding, tolong tulis ulang dari prinsip pertama."
Ini adalah pengujian patokan yang bagus, karena ia tidak hanya menguji kemampuan melengkapi kode, tetapi apakah Agen pemrograman dapat sekaligus meninjau banyak masalah yang tidak terkait, dan menilai apakah ia memiliki cukup otonomi, kejelasan konsep, dan keberanian eksekusi, untuk menyelesaikan penulisan ulang yang benar-benar dapat dijalankan. Sebagai pembanding, saya juga menyimpan versi penulisan ulang yang diselesaikan oleh dua insinyur senior manusia dengan bantuan AI, untuk membandingkan dan mengevaluasi output model.
Bagi Agen pemrograman, tugas ini sulit. Ia tidak hanya harus menemukan akar masalah, tetapi juga harus selalu mengingat masalah yang sebenarnya dalam interaksi multi-putaran, tidak terbawa oleh kode yang ada. Selain itu, ia juga harus memiliki keberanian untuk menghapus sebagian besar basis kode, yang justru merupakan perilaku yang biasanya dilatih untuk dihindari oleh Agen.
Sebagian besar Agen pemrograman dapat kira-kira menilai bagaimana seharusnya menulis ulang, tetapi begitu sampai pada tahap eksekusi, mereka sering kali hanya terus menambal masalah yang ada, daripada menyelesaikan masalah secara tuntas.
Sampai GPT-5.5 muncul.
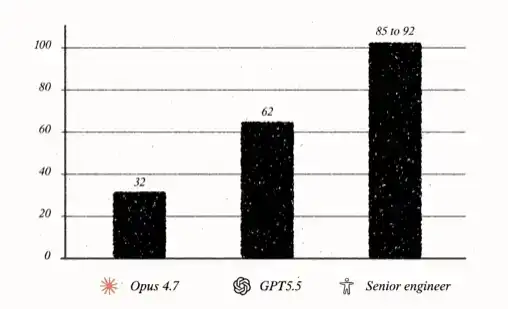
Dalam pengujian terbaik, GPT-5.5 mendapat skor 62/100, sekitar 30 poin lebih tinggi dari Opus 4.7.
Kinerja GPT-5.5 memberi kesan bahwa model seolah melintasi suatu batas: Ia tidak lagi hanya melengkapi otomatis, tidak hanya asisten, juga bukan hanya alat, tetapi sesuatu yang mendekati "manusia" dengan cara yang agak tidak nyaman. Dalam pengujian ini, skor insinyur senior manusia biasanya berada di kisaran tinggi 80-an hingga awal 90-an. Artinya, jika model meningkat sekitar 30 poin lagi, ia akan mencapai tingkat insinyur senior manusia.
Inilah cara angka pengujian patokan memengaruhi imajinasi manusia: ia mengompres perubahan kemampuan kualitatif yang aneh menjadi angka yang bersih, dan menggunakan angka ini untuk menceritakan kisah yang kuat, bahkan agak menakutkan.
Perhentian berikutnya adalah "kegilaan grafik".
Saya duga, dalam satu tahun ke depan, skor model dalam pengujian patokan ini akan masuk ke kisaran 80 bahkan 90 poin. Tapi untuk memahami arti skor ini, pertama-tama harus memahami apa sebenarnya yang terkandung dalam skor ini. Untuk contoh ini, 62 poin bukan hanya ukuran kemampuan model itu sendiri.
Ini mengukur kinerja model dalam kerangka tertentu: yaitu bagaimana model merespons prompt tertentu.
Pengujian Patokan Mengukur Kerja dalam Kerangka
Untuk melakukan pengujian patokan pada suatu model, pertama-tama Anda memerlukan prompt. Tanpa prompt, model hanyalah kumpulan kemungkinan tak terbatas yang statis.
Prompt akan menciptakan alam semesta kecil: ia mendefinisikan apa yang penting, bagaimana masalah harus ditangani, dan mengompres semua kemungkinan potensial model menjadi lintasan tindakan spesifik. Apa yang disebut "sendiri" model akan berperilaku, secara ketat tidak ada. Yang benar-benar dapat kita amati adalah bagaimana model merespons prompt yang berbeda, dan bagaimana prompt diubah menjadi mekanisme di balik jawaban.
Begitu prompt dimasukkan, model akan "hidup" dalam waktu singkat, mengubah kumpulan kemungkinan yang diam itu menjadi prediksi spesifik tentang "apa yang selanjutnya harus terjadi".
Dalam Senior Engineer Benchmark, kami memprompt model untuk memperbaiki basis kode, dan meninjau hasil output setelah selesai. Jika kerangka pengujian itu sendiri tidak memiliki fungsi tujuan bawaan, kami juga menjalankan "program penjaga" otomatis, yang terus mendorong model ketika berhenti, menanyakan apakah ia telah menyelesaikan tugas yang awalnya ditetapkan.
Kami menggunakan prompt yang tampak sederhana, sebagai kerangka awal pengujian. Ini dirancang seperti apa yang mungkin dikatakan oleh vibe coder kepada Agen pemrograman: tidak memuat istilah teknis, juga tidak secara jelas menyembunyikan jawaban dalam pertanyaan.
Prompt Senior Engineer Benchmark tampak general, tetapi ia sendiri adalah sebuah kerangka. Jika kami mengubah kerangka ini, tingkat kemampuan yang ditunjukkan model juga akan berubah.
Misalnya, prompt ini secara eksplisit meminta "melakukan restrukturisasi dari prinsip pertama", menunjukkan masalah mungkin ada di bagian "kolaborasi dokumen", dan meminta Agen pemrograman menemukan dan mempertahankan "invarians dalam basis kode".
Jika menghilangkan informasi spesifik ini, skor model akan turun. Jika benar-benar mengganti prompt, hanya menyuruh model "menyelesaikan semua kesalahan yang terus muncul", skor model mungkin mendekati nol. Ia akan langsung mulai mengidentifikasi dan memperbaiki kesalahan satu per satu, bukannya mundur selangkah, memikirkan apakah perlu melakukan penulisan ulang total.
Demikian pula, saya juga bisa dengan sangat mudah meningkatkan skor model. Jika saya memintanya menghapus banyak kode, dan secara eksplisit memberitahu file mana yang harus disederhanakan; atau memintanya memeriksa hasil kerjanya sendiri sebelum menyatakan selesai, memastikan aplikasi dapat berjalan penuh, kinerjanya dalam tugas ini akan lebih baik.
Pada akhirnya, saat merancang pengujian patokan, selalu perlu membuat penilaian tentang prompt apa yang digunakan, yaitu "kerangka" apa yang digunakan. Anda memerlukan prompt yang cukup sulit, sehingga model saat ini berkinerja buruk; tetapi juga harus cukup dekat dengan batas kemampuan model yang ada, sehingga model dapat meningkat di sepanjang jalur ini, memungkinkan Anda melihat kemajuan sedang terjadi.
Oleh karena itu, ketika kita mengamati pengujian patokan, yang benar-benar kita lihat adalah: model semakin mahir dalam suatu kerangka masalah tertentu, dan kerangka ini dipilih oleh kita. Lalu, apa yang terjadi ketika model dalam pengujian ini meningkat dari 60 menjadi 90, bahkan 100?
Kerangka Murah Akan Merangsang Permintaan Baru
Jika GPT-6 dapat menulis ulang basis kode dengan satu klik, maka akan lebih banyak orang mulai mencoba "menulis ulang basis kode dari prinsip pertama".
Dalam semalam, proyek penulisan ulang dari prinsip pertama yang sebelumnya langka, mahal, dan harus dipimpin oleh insinyur senior, akan menjadi hal yang bisa dicoba oleh setiap pendiri, manajer produk, staf operasional, dan insinyur pemula dalam satu sore.
Alat internal yang rusak tidak lagi diperbaiki, tetapi langsung ditulis ulang; produk SaaS tidak diperpanjang, tetapi dikloning; aplikasi Rails lawas, dasbor React berantakan, alat layanan pelanggan, panel admin, dan pipa data, semuanya akan menjadi kandidat "ditulis ulang saja".
Jumlah proyek penulisan ulang yang diusulkan dan dieksekusi akan meningkat tajam. Tetapi sebagian besar penulisan ulang tersebut akan tetap menjadi slop. Karena sebelum Anda menekan tombol "langsung tulis ulang", sebenarnya ada ribuan variabel yang perlu dipertimbangkan. Dan ketika semua orang dapat melakukan ini, variabel-variabel ini akan menjadi lebih jelas terlihat.
Saat itu, siapa yang akan dipanggil untuk menyelesaikan masalah, juga jelas.
Permintaan Baru Tetap Membutuhkan Ahli
Begitu pengujian patokan tertentu mulai mendekati jenuh, pekerjaan dalam kerangkanya akan menjadi lebih murah. Sementara itu, permintaan pasar akan ahli justru akan naik, karena perlu ada yang mengadaptasi kemampuan yang baru saja menjadi murah ini ke masalah nyata yang sedang terjadi hari ini.
Insinyur senior yang menggunakan AI perlu menilai banyak detail agar penulisan ulang dari prinsip pertama yang baru benar-benar layak. Bahkan termasuk pertanyaan paling dasar: Apakah penulisan ulang ini perlu dilakukan?
Haruskah kita menulis ulang sekarang, nanti, atau tidak sama sekali? Konten apa yang harus dimasukkan dalam ruang lingkup? Apa dalam basis kode saat ini yang harus dipertahankan? Arsitektur, database, server cache, dan penyedia hosting harus dilanjutkan, atau semuanya diganti? Haruskah kita lihat dulu berapa banyak orang yang menggunakan fitur rusak ini, lalu hapus saja? Siapa yang meninjau hasil akhir? Berdasarkan standar apa? Apa rencana mundurnya? Bagaimana data yang ada ditangani?
Pertanyaan-pertanyaan ini akan berkembang di sepanjang banyak dimensi, dan setiap jawaban akan mengubah masalah lain.
Insinyur senior akan memasuki wilayah kosong ini. Beberapa akan sedikit kesal dengan interupsi ini; beberapa akan membangun sistem untuk menghalangi permintaan semacam ini; yang lain akan menggunakan model baru ini untuk melakukan penulisan ulang dari prinsip pertama mereka sendiri, dan hasilnya akan jauh lebih baik daripada yang dapat dilakukan model dengan prompt default.
Siklus Akan Terjadi Kembali
Setelah Senior Engineer Benchmark saat ini ditaklukkan oleh model, kami akan mengubah kerangka, dan kembali menurunkan skor ke posisi rendah.
Pengujian patokan berikutnya tidak hanya bertanya: "Bisakah kamu menulis ulang aplikasi ini?" Ia akan bertanya: Bisakah kamu menilai kapan perlu menulis ulang? Bisakah memilih ruang lingkup yang tepat? Bisakah mempertahankan invarian yang benar? Bisakah mengelola proses migrasi? Bisakah menilai apakah hasil akhir cukup baik?
Ketika insinyur senior mulai menggunakan AI untuk memecahkan masalah ini, model juga akan semakin mahir dalam memecahkan masalah ini secara mandiri.
Kemudian, kita akan kembali mengalami kepanikan sesaat: Tampaknya model sekarang sudah bisa menilai apakah harus menulis ulang! Mereka tampaknya sudah bisa melakukan semua yang bisa dilakukan insinyur senior!
Tapi kemudian, batas baru akan muncul. Itu adalah batas yang sebelumnya tidak jelas. Kami akan mengatur ulang pengujian patokan, permintaan baru akan terpicu, dan seluruh proses akan berulang kembali.
Pola Ini Dapat Dilihat di Setiap Pengujian Patokan
Ini bukan hanya masalah yang dimiliki oleh Senior Engineer Benchmark. Dengan mengamati dengan cermat, Anda hampir dapat melihat mekanisme yang sama di setiap pengujian patokan.
Ambil contoh pengujian patokan GDPval dari OpenAI. Ini mengevaluasi seberapa dekat AI dengan manusia dalam tugas-tugas tingkat ahli berbagai profesi seperti petugas kepatuhan, pengacara, pengembang perangkat lunak.
Saat GDPval pertama kali dirilis, penelitian OpenAI menunjukkan bahwa GPT-5 mencapai atau melampaui tingkat profesional manusia dalam 40.6% tugas. Sementara kinerja Claude Opus 4.1 lebih mencengangkan, melebihi ahli manusia dalam 49% tugas.
Kemudian, serangkaian judul artikel bermunculan. Misalnya, Axios menulis: "Alat OpenAI menunjukkan AI sedang menyusul pekerjaan manusia"; Fortune menulis: "Pengujian patokan baru OpenAI GDPval menunjukkan model AI sudah mencapai tingkat ahli di hampir setengah tugas."
Hasil ini memang mengesankan. Tapi mari kita lihat prompt yang digunakan untuk tugas-tugas ini:
Di dalamnya sebenarnya sudah dimasukkan banyak kebijaksanaan manusia: Ada yang pertama kali membingkai masalah menjadi bentuk yang dapat diselesaikan model.
Pekerjaan manusia yang sulit yang tidak diukur oleh GDPval sebenarnya sudah selesai sebelum model mulai menjawab. Harus ada yang meninjau dan menguji akurasi set indikator spesifik ini; ada yang memutuskan interval kepercayaan yang tepat, menilai indikator mana yang termasuk dalam ruang lingkup tugas, mana yang tidak; juga ada yang menentukan bagaimana hasil harus disajikan.
Dalam kerangka masalah yang tepat, model memang dapat menyelesaikan pekerjaan profesional. Tapi coba pikirkan, jika Anda dan saya memprompt model untuk menyelesaikan tugas yang sama, bagaimana kinerjanya?
Dalam artikel awal saya tentang GDPval, saya pernah menulis: "Saya sangat optimis tentang AI, tetapi jika menafsirkan kasus-kasus ini dengan benar, yang ditunjukkan bukanlah pekerjaan manusia menjadi lebih sedikit, melainkan setelah menggunakan AI, pekerjaan manusia justru lebih banyak. Alasannya, di balik pencapaian ini tersembunyi banyak kebijaksanaan yang 'diselundupkan' — yaitu lapisan tak terlihat yang terdiri dari penilaian manusia, umpan balik, dan kata-kata prompt."
Dilihat dari jauh, Anda akan menemukan, di balik semua ini ada semacam "Paradoks Zeno" versi AI.
Paradoks Zeno AI
Dalam Paradoks Zeno, seekor kura-kura memenangkan perlombaan lari melawan pelari tercepat Yunani, Achilles.
Karena kura-kura berlari lambat, ia berangkat lebih dulu beberapa jarak. Ketika Achilles mencapai posisi awal kura-kura, kura-kura telah bergerak sedikit lebih maju; ketika Achilles mencapai posisi baru itu, kura-kura maju lagi. Tidak peduli seberapa cepat Achilles berlari, selalu ada jarak berikutnya yang harus dikejar, dan kesenjangan ini terus-menerus tercipta kembali.
Dalam Paradoks Zeno AI, kita manusia adalah kura-kura itu. Dengan jutaan tahun evolusi dan pembelajaran budaya, kita memimpin AI sejauh 50 yard. AI kemudian melesat melewati semua ini, mulai mendekati tumit kita.
Setidaknya dalam beberapa tahun terakhir, kita masih bisa mempertahankan keunggulan.
Tapi Bagaimana dengan AGI?
Saya rasa, bahkan jika AGI benar-benar datang, masih ada kekuatan teknis, arsitektural, dan ekonomi yang kuat yang membuat AI selalu tertinggal beberapa langkah di belakang manusia.
Satu Definisi AGI
Pertama, kita perlu memberikan definisi AGI yang dapat dioperasionalkan.
Saya pernah mengusulkan, ketika menjalankan Agen secara berkelanjutan secara ekonomi menjadi masuk akal, maka AGI sudah tiba. Artinya, ketika saya memiliki sistem yang berjalan terus-menerus, dan saya bersedia membayar untuk membuatnya berpikir, belajar, dan bertindak 7×24 jam secara berkelanjutan, saya rasa itu sudah dapat dianggap sebagai AGI secara jelas.
Kita masih jauh dari tahap ini sekarang. Bahkan sistem seperti OpenClaw yang secara teknis dapat dipanggil kapan saja, tidak setiap saat menghasilkan token.
Saya suka definisi ini karena dapat diukur: kita akan membuatnya terus berjalan, atau tidak. Selain itu, ia juga mencakup banyak kemampuan yang sulit diukur langsung. Model yang layak dijalankan terus-menerus harus dapat terus belajar, dan memilih, memilih kembali kerangka masalah baru secara terbuka.
Dalam dunia AGI, secara teori, dengan anggaran dan waktu yang cukup, model harus dapat terus meningkat, terus meningkatkan apa pun masalahnya. Ini memang seharusnya menjadi ancaman besar bagi semua pekerjaan.
Kerangka Bukan Pembuat Kerangka
Tapi bahkan versi kuat AGI ini pun tidak dapat menghilangkan "masalah kerangka".
AGI seperti ini dapat memilih dan memilih kembali kerangka, tetapi ia masih mengejar tujuan yang diberikan, mengoptimalkan imbalan, atau merespons sinyal yang diputuskan orang lain sebagai "kemajuan". Tujuan ini bisa sangat spesifik, seperti "meningkatkan tingkat konversi laman arahan ini"; bisa juga sangat abstrak, seperti "mencari ide ilmiah baru".
Bahkan jika model dapat beralih dengan lancar di antara kerangka yang berbeda, kesenjangan yang selalu kita lacak akan muncul kembali di tingkat yang lebih tinggi. Dalam AGI apa pun yang dikonsep oleh laboratorium utama mana pun, akan tetap ada "pembuat kerangka" — yaitu seorang manusia, yang mengarahkan model untuk mencapai suatu tujuan.
Karena kerangka bukan pembuat kerangka, pola yang sama akan terus berulang: AI membuat kemampuan yang telah dibingkai kemarin menjadi murah; orang menggunakan kemampuan murah ini di lebih banyak skenario; hasil menjadi sangat berlimpah; ahli bergerak ke daerah tepi baru, menilai apa yang penting saat ini; penilaian mereka menciptakan kerangka berikutnya; lalu model terus memanjat kerangka ini.
Ketika kita melihat AI melakukan hal baru, rasa panik itu selalu kembali ke masalah yang sama: Kita menetapkan kerangka, melihat model memanjatnya, lalu mengira kerangka itu, atau hal yang dapat memanjat kerangka itu, sebagai hal itu sendiri.
Ketika kita melihat pengujian patokan, dan membandingkannya dengan kemampuan manusia, kita sebenarnya mengacaukan "kerangka" dan "pembuat kerangka". Skor memberi tahu kita seberapa baik kinerja model dalam kerangka yang kita sediakan; itu tidak menunjukkan bahwa model telah menjadi kita.
Ini tepatnya kesalahan kategorikal di balik kepanikan. Kita menunjuk batas terbaru yang baru kita gambar dan berkata: Inilah kita. Lalu, ketika model memanjat melewati batas ini, kita merasa ia menyusul kita. Tapi yang ia susul hanyalah kerangka, bukan pembuat kerangka.
Kesalahannya adalah, kita selalu ingin menangkap sesuatu yang konkret. Kita ingin berkata: Kecerdasan adalah pengujian patokan ini. Masalahnya, begitu sesuatu cukup konkret untuk diidentifikasi, ia juga cukup konkret untuk dioptimalkan dan dipanjat.
Kerangka diperlukan. Kerangka memungkinkan kita menangkap dunia, memproses dunia. Tapi kerangka juga beku, parsial, dan karenanya pasti dapat dioptimalkan.
Pembuat kerangka berbeda. Pembuat kerangka tetap berhubungan dengan hal-hal yang harus ditinggalkan oleh kerangka, yaitu situasi lengkap yang muncul padanya di setiap saat.
Lalu apa itu "situasi lengkap"? Begitu Anda mulai mengatakan "situasi lengkap" mengandung apa, Anda sudah membuka kerangka lain lagi. Anda tidak bisa mengatakannya dengan tepat apa itu, tetapi ia ada, karena Anda ada.
Agen Tanpa Subjektivitas
Sampai saat ini, Agen yang telah kita buat, serta Agen yang sedang dibangun oleh perusahaan AI, sebenarnya tidak memiliki banyak subjektivitas yang sebenarnya. Ada dua konsep terkait yang sering dicampuradukkan: agency mengacu pada kemampuan bertindak secara mandiri; sedangkan agent mengacu pada orang atau benda yang bertindak atas nama orang lain. Sampai saat ini, AI murni termasuk yang terakhir.
Tentu, mereka sudah memiliki otonomi untuk menyelesaikan tugas yang diberikan, bahkan jika tugas ini mungkin berlangsung berjam-jam atau berhari-hari. Tetapi mereka masih hanya sarana untuk mencapai tujuan yang ditentukan manusia. Dan seluruh industri sedang menginvestasikan miliaran dolar untuk membuat mereka lebih ahli dalam hal ini: mengeksekusi tujuan yang kita serahkan kepada mereka.
Kecuali suatu hari, mereka sendiri menjadi tujuan — mengejar tujuan mereka sendiri, beralih dengan lancar di antara tujuan yang berbeda, memutuskan apa yang harus dilakukan terlepas dari keinginan, referensi, atau bahkan menentang keinginan operator manusia mana pun — jika tidak, situasi tidak akan berubah secara fundamental. Tidak peduli seberapa maju mereka, tetap demikian.
Jika Anda menghabiskan waktu 10 menit bersama anak balita, akan sangat jelas terasa bahwa bahkan model paling kuat pun hampir tidak memiliki banyak subjektivitas.
Dalam hampir semua tugas yang kita pedulikan, anak balita tidak sebaik model bahasa. Anak balita tidak bisa menulis kode, tidak bisa merangkum spreadsheet, tidak bisa menyusun memo strategis, juga tidak bisa lulus ujian tingkat pascasarjana. Tapi dalam arti lain, anak balita jauh di depan model, hingga perbandingan ini hampir memalukan. Karena anak balita memiliki tujuannya sendiri.
Anak balita ingin menyentuh balon merah itu. Dia ingin mengangkat balon merah ke depan kipas angin, melihat apa yang terjadi. Dia ingin menusuk balon merah dengan garpu; ingin memasukkannya ke luar jendela; ingin melihat apakah Anda akan tertawa, marah, atau bergabung dengannya. Dia terus-menerus menciptakan permainan, mengubah dunia menjadi tempat eksperimen. Dia tidak sedang menunggu prompt, juga tidak sedang mengoptimalkan pengujian patokan apa pun, kecuali hal itu dianggap layak dilakukan menurutnya.
Tentu, Anda bisa mencoba memberikan prompt kepadanya. Tapi untuk mendapatkan output yang dapat diprediksi, semoga berhasil. Anak balita hidup dalam ranah yang terdiri dari keinginan, perhatian, frustrasi, kebahagiaan, ketakutan, peniruan, dan permainan.
Agen saat ini dapat semakin terampil mengejar tujuan. Bahkan setelah kita menyatakan tujuan, mereka dapat membantu kita mempertajam tujuan. Ada juga sedikit percikan perilaku seperti anak balita pada mereka, seperti permainan, kebosanan, dan pemberontakan.
Tapi karena pada akhirnya mereka dibangun dan diselaraskan untuk kepentingan manusia, baik kepentingan ekonomi maupun lainnya, selama perilaku ini tidak melayani tujuan manusia yang menggunakannya, mereka akan ditekan hingga hampir tidak ada.
Inilah mengapa kata "Agen" sangat mudah disalahpahami. Model memiliki kemampuan bertindak mandiri yang semakin kuat. Tapi dalam arti manusia, subjektivitas bukan hanya tindakan. Ia juga berarti menginginkan untuk diri sendiri, berarti bermain untuk bermain. Dan kepatuhan serta kegunaan model, pada dasarnya bertentangan dengan subjektivitas ini. Oleh karena itu, bahkan jika model terus maju, kesenjangan antara model dan manusia akan tetap ada.
Kembali ke Zeno
Dan di sinilah Paradoks Zeno AI mulai runtuh. Ia sebenarnya adalah eksperimen pikiran yang kacau. Kita menetapkan metafora: AI sedang berlomba dengan kita, mengikuti tumit kita.
Anda memberikan prompt kepada model. Ia mulai menjalankan lomba yang biasa Anda selesaikan sendiri di masa lalu. Model start sangat cepat, cepat menakutkan. Ia kuat, tak kenal lelah, dan membawa perasaan organik yang aneh. Ini membuat lomba ini menjadi lebih penting bagi Anda. Anda tidak akan berlomba dengan mobil, tetapi benda ini berbeda, membuat Anda merasa dekat dengan diri sendiri.
Anda duduk di sana, menatap token mengalir baris demi baris, hampir terhipnotis. Lalu Anda mulai membayangkan diri sendiri juga berlari di lomba ini, diri bayangan Anda sendiri ditumpangkan di lintasan: kadang di depan model, kadang sejajar dengan model.
Tanpa disadari, model telah berlari di depan. Anda mulai berkeringat.
Kemudian, lomba selesai.
Anda hampir bisa merasakan otot Anda mulai menyusut. Di depan replika mekanis diri Anda sendiri, semua orang yang Anda kenal, bahkan seluruh umat manusia, mereka tampaknya sudah tidak berguna lagi. Hantu mengejar hantu lain, dan menang.
Tapi kemudian, hal aneh terjadi. Model menoleh kepada Anda. Di kotak teks kosong, kursor berkedip-kedip, penuh harapan.
Ia sedang menunggu.
Penutup
Rabbi Hanokh pernah bercerita: Dahulu kala ada seorang pria yang sangat bodoh. Setiap pagi bangun tidur, ia selalu kesulitan menemukan pakaiannya. Hingga malam hari sebelum tidur, begitu memikirkan besok pagi harus mengalami kesulitan lagi, ia hampir tidak berani naik ke tempat tidur.
Suatu malam, akhirnya ia memutuskan, mengambil kertas dan pena, sambil melepas pakaian, ia mencatat dengan tepat di mana ia meletakkan setiap pakaian.
Keesokan paginya, ia sangat puas mengambil catatan itu dan mulai membaca: "Topi" — topi benar-benar ada di sana, lalu ia memakainya di kepala; "Celana" — celana ada di sana, lalu ia memakainya. Demikianlah, ia mengenakan pakaian satu per satu sesuai catatan di kertas itu.
"Semua ini tidak masalah," katanya panik, "Tapi sekarang, saya sendiri di mana?"
"Saya sebenarnya ada di mana?"
Ia mencari dan mencari, lama sekali, tetapi sia-sia. Ia tidak menemukan dirinya sendiri.
"Kita juga begitu," kata sang Rabbi.






