Selama lebih dari satu dekade terakhir, komputasi digital yang berpusat pada GPU telah mendominasi bidang AI. Klaster yang lebih besar, bandwidth yang lebih tinggi, GPU yang lebih kuat, dan pusat data yang lebih padat tampaknya menjadi jalur utama menuju AI generasi berikutnya.
Namun seiring dengan jumlah parameter model yang mendekati triliunan, industri mulai sering menyebut-nyebut kata "konsumsi energi". Bahkan, sebuah masalah yang lebih mendasar pun muncul: Jika AI terus berkembang dengan cara yang ada saat ini, dari mana sumber listriknya?
Tidak diragukan lagi, "tagihan listrik" AI dan konsumsi energi telah secara bertahap berkembang dari biaya operasional menjadi "hambatan struktural" yang membatasi perkembangan seluruh industri.
Menghadapi krisis energi yang mendesak ini, mantan Kepala AI Databricks dan pendiri startup legendaris Silicon Valley, Naveen Rao, membawa perusahaan rintisan hard-tech barunya, Unconventional AI, ke sorotan lampu.
Hari ini, Unconventional AI secara resmi mengumumkan peluncuran model pertamanya, Un-0, sebuah model generasi gambar yang digerakkan oleh "sistem osilator terkopel analog", yang dapat dianggap sebagai contoh dasar komputasi fisika yang baru muncul. Pada ImageNet 64×64, Un-0 mencapai FID 6.74, kualitasnya sudah mendekati level beberapa metode generasi gambar tradisional utama saat pertama kali dirilis.
Naveen Rao menyebutnya sebagai "model generatif skala besar pertama yang dibangun dengan fisika sebagai primitif komputasi".
"Ini menandai momen 'Hello World' bagi model berbasis fisika. Kami menggunakan perilaku alami sistem fisika yang berubah seiring waktu untuk melakukan perhitungan bagi kami. Hasil akhirnya adalah cara baru dalam membangun komputer, dan diharapkan dapat meningkatkan efisiensi energi secara signifikan."

Bahkan, dalam wawancara dengan media, Naveen Rao memberikan "target kecil" yang lebih berani: Di masa depan, kemungkinan dapat mengurangi konsumsi energi inferensi AI hingga seperseribu dari sistem yang ada saat ini.
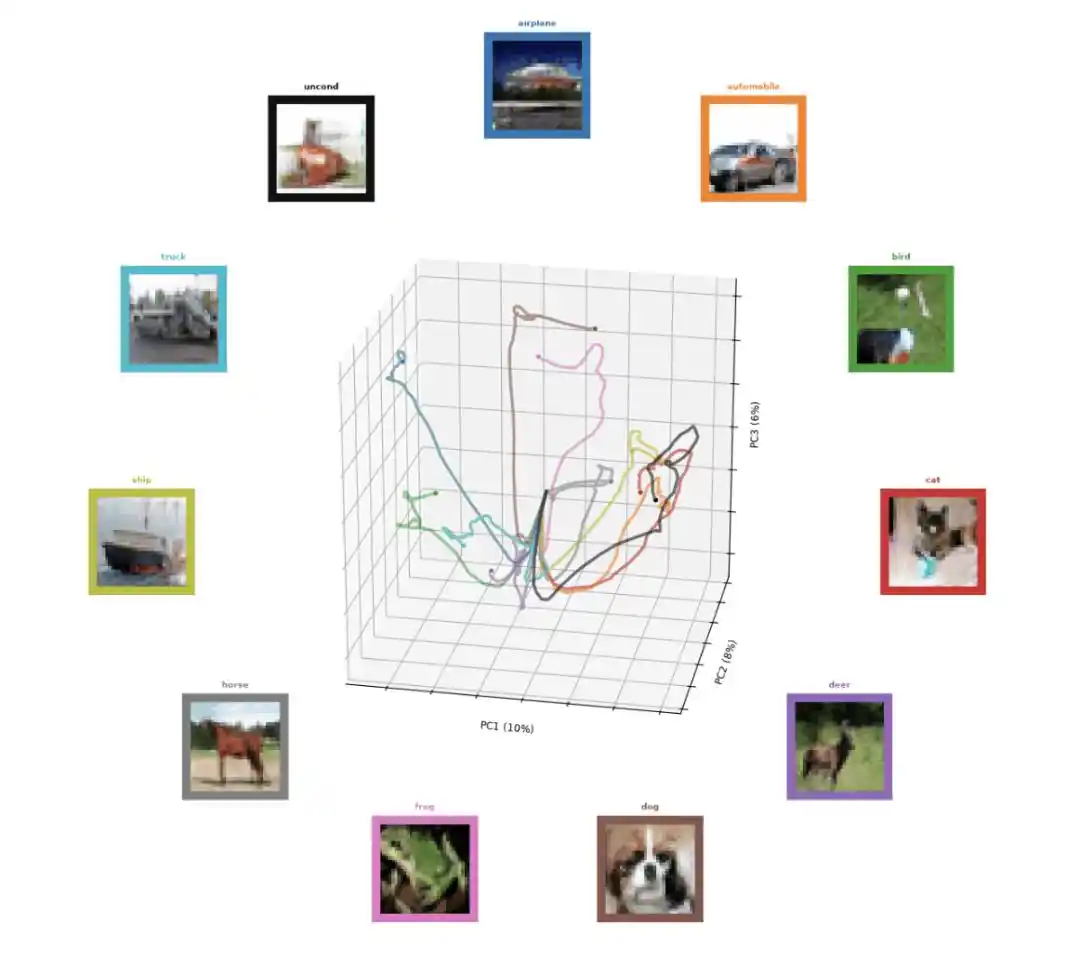
Sampel lintasan evolusi temporal dari proses generasi Un-0. Warna setiap garis sesuai dengan kotak dengan warna serupa, di mana kotak tersebut diberi label kelas dan menunjukkan proses pembuatan gambar kelas tersebut secara bertahap seiring waktu.
Resmi merilis sebuah blog untuk memperkenalkan Un-0. Mari kita pahami lebih lanjut.
Titik Awal Un-0: Melakukan Ulang Komputasi AI dengan Sistem Fisika
Unconventional AI menyatakan bahwa tujuan mereka adalah membangun sejenis komputer baru, yang memanfaatkan hukum fisika untuk melakukan perhitungan, dengan harapan AI modern dapat berjalan di masa depan dengan konsumsi energi mesin yang jauh lebih rendah daripada saat ini, dengan target sekitar pengurangan 1000 kali lipat.
Oleh karena itu, mereka mengajukan pertanyaan: Bisakah melatih sebuah sistem dinamis fisika untuk menghasilkan gambar pada tugas-tugas berskala besar?
Saat ini, model AI terkuat pada dasarnya adalah jaringan neural tradisional, terutama model dengan tulang punggung Transformer. Namun di luar jalur utama, telah lama ada banyak penelitian yang mencoba memanfaatkan perilaku dinamis sistem fisika untuk meningkatkan efisiensi energi, seperti noise, perubahan waktu, tegangan, dan arus dalam sirkuit analog. Metode ini tidak menggunakan komputasi nilai numerik digital tradisional, tetapi memanfaatkan proses evolusi alami sistem fisika itu sendiri.
Misalnya, komputasi neuromorfik, jaringan Hopfield, serta Reservoir Computing, dan yang lebih baru seperti Hamiltonian Networks, Liquid Networks, Neural Wave Machines, Thermodynamic Computing, serta Kuramoto Oscillators.
Un-0 adalah percobaan baru di jalur komputasi non-tradisional ini. Namun, kesulitan intinya adalah: untuk dapat memanfaatkan metode komputasi alternatif ini, tugas AI harus dipetakan secara efektif ke dalam proses dinamis sistem fisika. Yang ingin dibuktikan oleh Un-0 adalah apakah beban kerja AI modern dapat dijalankan di atas dasar fisik dan akhirnya lebih efisien daripada perangkat keras saat ini.
Prinsip Kerja Un-0
Menurut penjelasan resmi, bayangkan dua metronom yang berdetak bersebelahan, seperti yang ditunjukkan pada gambar di bawah ini.
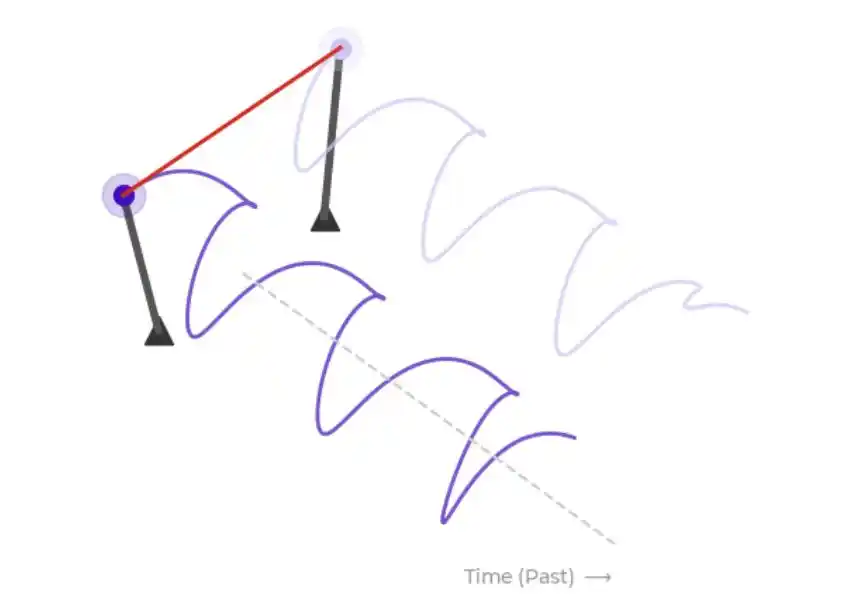
Setiap metronom memiliki "fase" pada waktu tertentu, yaitu posisi lengan pendulum saat ini dalam siklus ayunannya. Jika dua metronom diletakkan di atas meja yang sama, mereka akan saling mempengaruhi melalui permukaan meja. Bergantung pada kekuatan interaksi, yaitu kekuatan kopling, mereka mungkin secara bertahap tersinkronisasi, atau mungkin masuk ke keadaan sinkron fase berlawanan.
Ini adalah konsep dasar osilator: setiap osilator memiliki fasenya sendiri, dan cenderung berputar sesuai frekuensi alaminya, tetapi juga dipengaruhi oleh osilator tetangga.
Dan jika memperluas dua osilator menjadi ribuan osilator, seluruh sistem menjadi lebih menarik. Sejumlah besar osilator memiliki hubungan kopling dengan kekuatan yang berbeda, mereka akan mengorganisir diri menjadi pola tertentu melalui interaksi, seperti yang ditunjukkan pada gambar di bawah ini.

Mesin komputasi Un-0 adalah kumpulan osilator skala besar seperti ini, di mana kekuatan kopling antar osilator adalah parameter yang dapat dipelajari utama dari model.
Osilator terkopel ini biasanya dimodelkan sebagai "Osilator Kuramoto".
Secara spesifik, gerakan setiap osilator mengikuti aturan sederhana, dan aturan ini berlaku secara kontinu seiring waktu: di satu sisi, ia berputar sesuai frekuensi alaminya sendiri, di sisi lain, ia akan tergeser karena tarikan dari semua osilator lainnya.
Persamaan diferensial biasa (ODE) di bawah ini menggambarkan proses evolusi osilator-osilator ini seiring waktu:
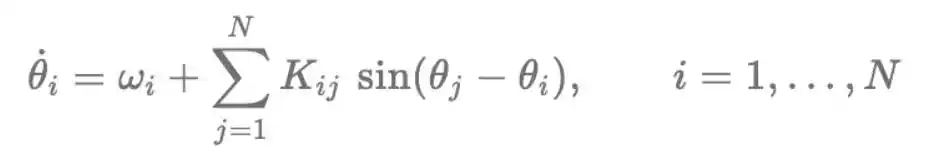
Setiap osilator i membawa fase
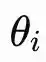
∈[0,2π), di mana
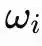
mewakili frekuensi alaminya. Matriks
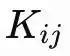
menentukan kekuatan kopling, yang digunakan untuk memutuskan seberapa kuat osilator j akan menarik osilator i ke keadaan sinkron, atau mendorongnya menjauh dari keadaan sinkron.
Yang perlu dipelajari Un-0 adalah matriks kopling K dan frekuensi alami ω, parameter-parameter ini bersama-sama mendefinisikan sistem fisik itu sendiri.
Alasan memilih osilator, Unconventional AI memberikan dua alasan:
- Alasan pertama berasal dari otak: Aktivitas ritmik dan fenomena sinkronisasi banyak ditemukan di otak, dan sejak lama, orang beranggapan bahwa fenomena ini mungkin terlibat dalam proses komputasi, seperti mengikat fitur-fitur yang terpisah menjadi persepsi yang koheren, mengontrol pertukaran informasi antar area otak, mengatur struktur waktu impuls saraf, dll. Osilator terkopel adalah salah satu model matematika paling sederhana untuk menggambarkan perilaku semacam ini, sehingga secara alami cocok sebagai unit dasar untuk model komputasi terinspirasi saraf.
- Alasan kedua lebih bersifat rekayasa: Osilator dapat diimplementasikan sebagai primitif sirkuit fisik. Unconventional AI percaya, sistem osilator terkopel dapat diimplementasikan langsung di atas CMOS atau dasar fisik lainnya, membiarkan perilaku fisik sistem itu sendiri menghitung evolusi dinamika.
Taruhan di balik Un-0 adalah: Jika hukum fisika dapat langsung menghitung beban kerja AI, maka dasar eksekusi di masa depan mungkin akan sangat berbeda dari GPU saat ini.
Arsitektur Model Un-0
Un-0 menghasilkan sebuah gambar, kira-kira dalam lima langkah:
- Inisialisasi Acak: Mengatur fase semua osilator ke sudut acak (mirip dengan noise acak dalam model difusi);
- Input Panduan Kelas: Menggunakan sekelompok kecil "osilator kondisional" untuk memasukkan label kelas (seperti "gunung berapi", "bunga aster"), memandu kumpulan osilator utama untuk berevolusi ke arah tertentu;
- Biarkan Fisika Berjalan Alami: Melepaskan sistem, membiarkan osilator saling menarik, berevolusi di bawah pengaruh dinamika fisik, dan akhirnya stabil;
- Mengambil Snapshot: Mencatat fase semua osilator pada waktu tertentu T, membentuk grid digital ruang laten (Latent);
- Merender Piksel: Melalui decoder tradisional yang hanya mengambil kurang dari 13% parameter model, mengubah grid fase menjadi piksel gambar akhir.
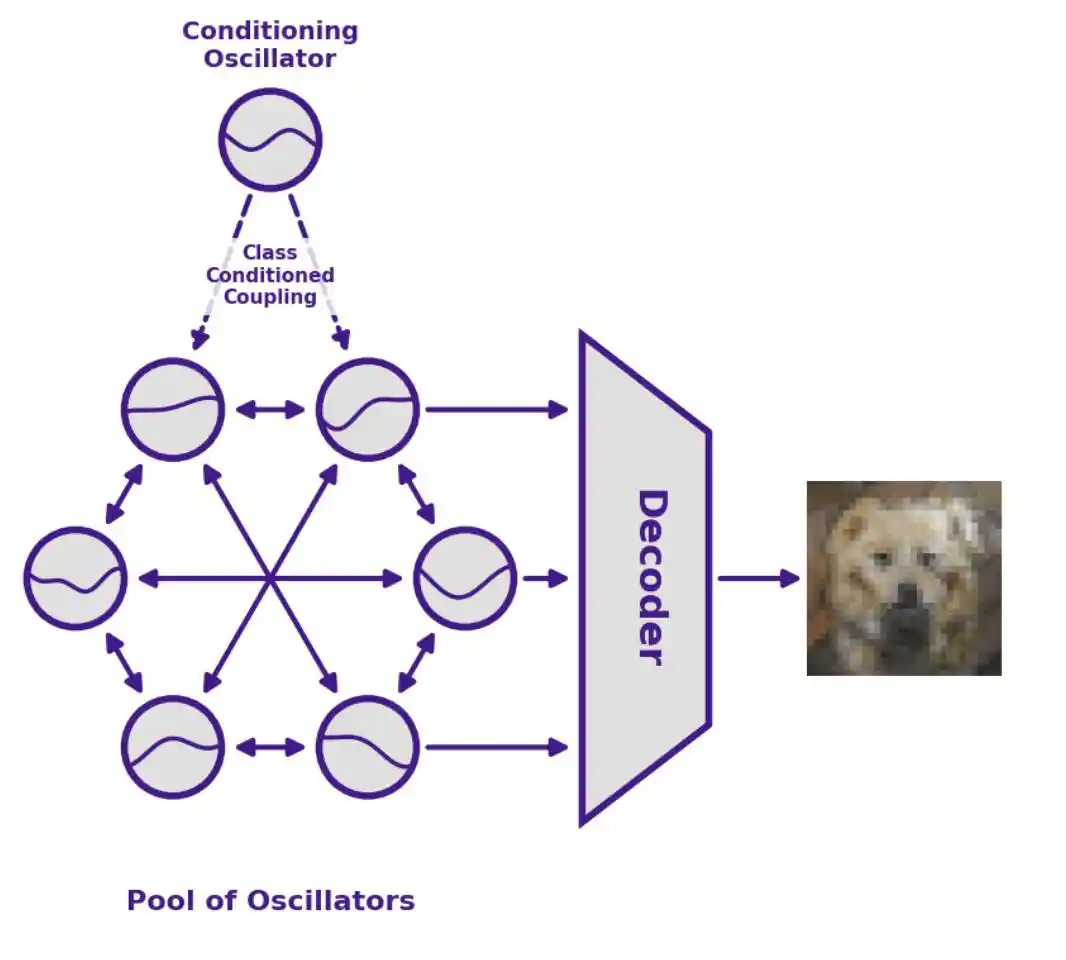
Osilator terkopel berevolusi seiring waktu di bawah pengaruh hubungan kopling yang diperoleh dari pelatihan. Di antara osilator kondisional dan kolam osilator utama terdapat matriks kondisi kelas satu-arah berperingkat rendah, digunakan untuk menyuntikkan informasi kelas. Pada titik waktu T, sistem membaca status osilator melalui sebuah decoder dan menghasilkan gambar. Dengan mengambil sampel berulang kondisi awal yang berbeda, distribusi gambar yang sesuai dapat dihasilkan.
Selama proses pelatihan, model terutama mempelajari tiga jenis parameter: bagaimana osilator saling berkopling, yaitu matriks K; frekuensi alami setiap osilator
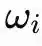
; serta bobot decoder. Secara keseluruhan, sistem osilator mengambil alih komputasi yang mungkin dilakukan oleh lapisan jaringan neural tradisional.
Unconventional AI menjelaskan, alasan memilih arsitektur ini adalah untuk memberi sistem dinamika itu sendiri kebebasan maksimum untuk melakukan perhitungan.
Dalam propagasi maju pelatihan, model hanya perlu mengatur matriks kopling, frekuensi osilator, dan fase awal, kemudian membiarkan sistem dinamika berevolusi, dan akhirnya membaca variabel laten gambar.
Ini berbeda dari metode generatif dinamis seperti model difusi dan Flow Matching. Difusi dan Flow Matching biasanya secara eksplisit membimbing bagaimana sistem dinamika berevolusi selama pelatihan, sedangkan metode Un-0 lebih seperti hanya melihat sampel hasil akhir, kemudian mengoptimalkan seluruh sistem dinamika melalui fungsi kerugian.
Konsekuensinya, metode ini memerlukan fungsi kerugian yang lebih kompleks, karena sinyal pelatihan terutama berasal dari sampel yang dihasilkan itu sendiri.
Bagaimana Melatih Un-0?
Unconventional AI melatih model dalam tiga skala masing-masing pada CIFAR-10 dan ImageNet 64×64, hasilnya sebagai berikut:

Hasil pelatihan pada CIFAR-10

Hasil pelatihan pada ImageNet 64×64
Dari hasil tersebut, seiring bertambahnya jumlah osilator, skor FID model terus membaik. Model ImageNet 64×64 terbesar menggunakan 16384 osilator, total parameter sekitar 322 juta, mencapai FID 6.74.
Dalam metode pelatihan, menggunakan fungsi kerugian baru yang diusulkan, "Drifting Loss" (Kerugian Hanyut), dikombinasikan dengan ekstraktor fitur DINOv2 dan pengoptimal AdamW untuk pelatihan ujung-ke-ujung.
Dalam evaluasi, CIFAR-10 menggunakan 50.000 sampel yang dihasilkan, dan dibandingkan dengan statistik referensi CIFAR-10 menggunakan paket dan proses evaluasi standar; ImageNet 64×64 juga menggunakan 50.000 sampel yang dihasilkan, dan menghitung FID melalui ADM evaluation suite.
Dalam hal daya komputasi, semua model CIFAR-10 dilatih pada 1 GPU B200, sedangkan semua model ImageNet 64×64 dilatih pada 8 GPU B200. Model CIFAR-10 terbesar mengkonsumsi 20 jam B200 untuk pelatihan, model ImageNet 64×64 terbesar mengkonsumsi 640 jam B200.
Menurut penjelasan resmi, hambatan pelatihan terutama berasal dari komputasi fungsi "Drifting Loss", karena memerlukan penggunaan ekstraktor fitur gambar tradisional, dan menghitung pada beberapa tampilan fitur.
Di Posisi Apa Un-0 Berada di Bidang Generasi Gambar?
Untuk lebih menunjukkan performa Un-0, Unconventional AI menempatkan Un-0 pada kurva "kualitas generasi vs jumlah parameter", dan membandingkannya dengan model tradisional dan non-tradisional.
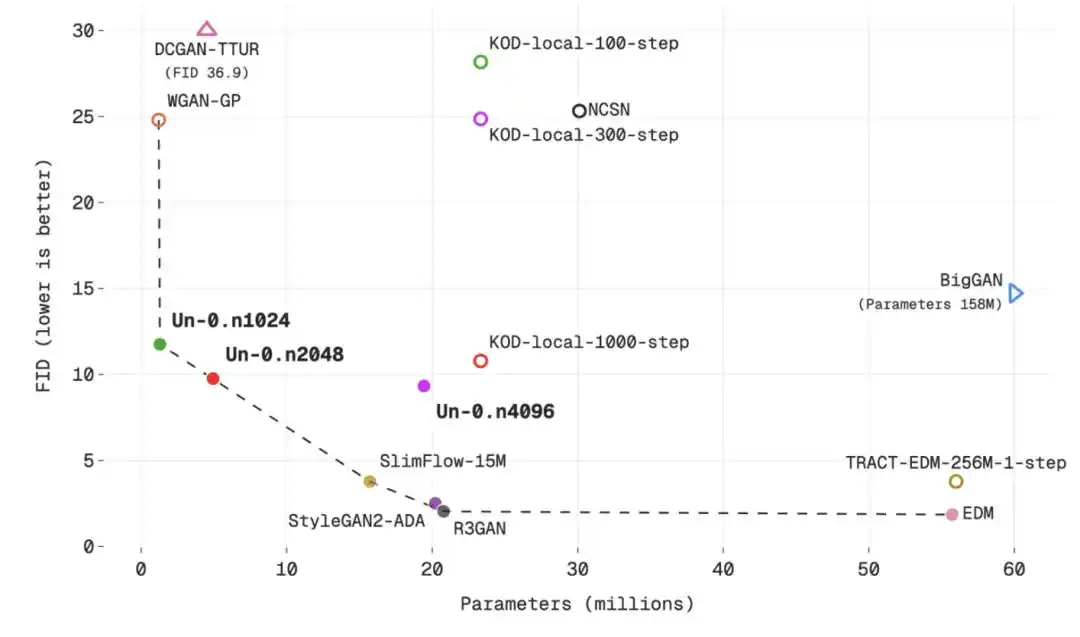
Hubungan antara jumlah parameter dan nilai FID dalam dataset CIFAR-10
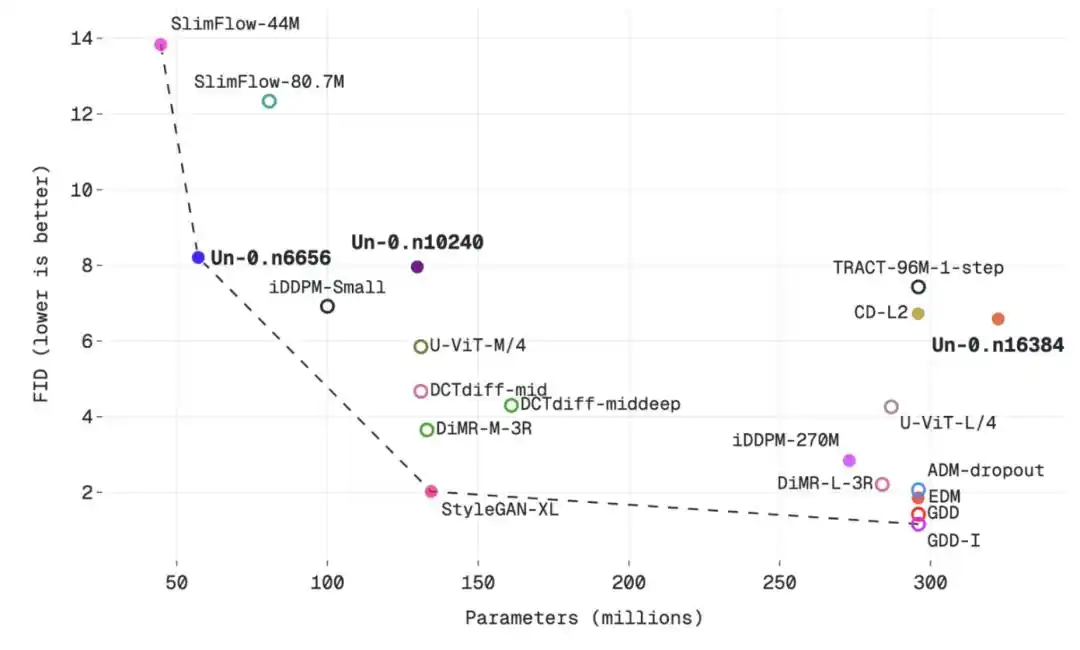
Pada gambar berukuran 64×64, hubungan antara jumlah parameter dan nilai FID
Kesimpulannya: Kualitas Un-0 sudah dapat disandingkan dengan beberapa generator tradisional awal, bahkan lebih baik dalam beberapa perbandingan, seperti NCSN, DCGAN-TTUR, WGAN-GP, BigGAN, iDDPM, Consistency Models, TRACT, dll. Tetapi masih tertinggal dari model tradisional berperforma tinggi yang lebih baru, seperti EDM dan GDD.
Dengan kata lain, Un-0 bukanlah model generasi gambar terkuat saat ini, ia lebih seperti titik awal dari jalur baru: Performanya sudah mendekati level banyak model generasi klasik saat pertama kali diusulkan, tetapi untuk mengejar teknologi terdepan terbaru dari jalur tradisional, masih diperlukan optimasi berkelanjutan pada tingkat algoritma, arsitektur, dan primitif fisik.
Secara keseluruhan, Un-0 membuktikan kelayakan menggunakan sistem dinamis fisika untuk generasi gambar skala besar AI modern. Meskipun saat ini performanya dalam simulasi perangkat lunak belum mencapai puncak AI konvensional, ia membuka jalan yang penuh harapan untuk perangkat keras "AI non-tradisional" dengan rasio efisiensi energi seribu kali lipat di masa depan......
Dan Naveen Rao juga menekankan, kehadiran Un-0 menunjukkan bahwa "komputasi bukanlah penemuan eksklusif manusia." Ia ada di setiap sudut alam dan dunia fisik. Semua proses fisik entitas fisik mengandung dimensi waktu, tetapi sistem komputasi saat ini belum benar-benar memanfaatkan hal ini.
"Apa yang kami kembangkan saat ini adalah dimensi waktu ini."
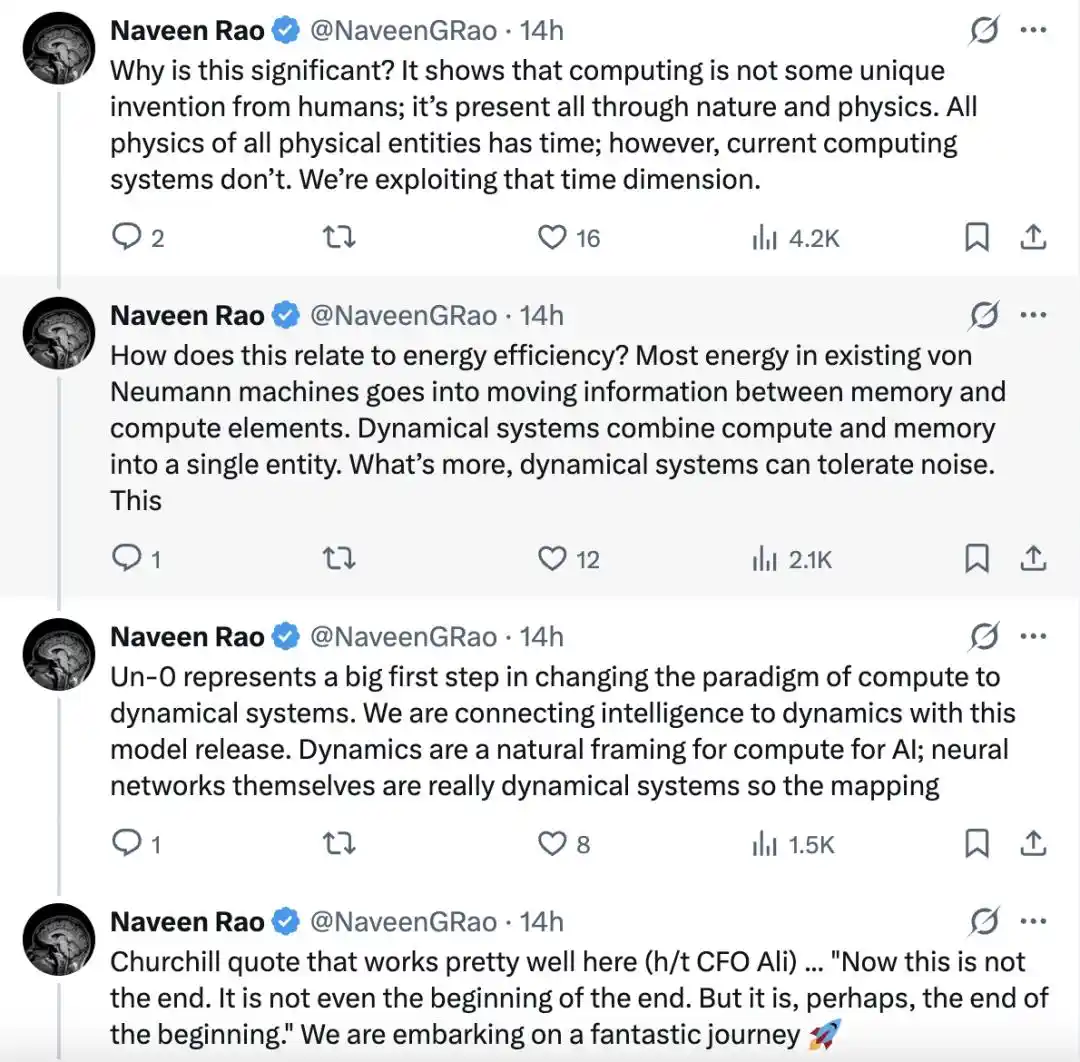
Dan hubungannya dengan efisiensi energi adalah, dalam mesin arsitektur von Neumann yang ada, sebagian besar energi dikonsumsi dalam pemindahan informasi antara memori dan unit komputasi, sedangkan sistem dinamika menggabungkan komputasi dan memori ke dalam entitas yang sama. Lebih penting lagi, sistem dinamika dapat mentoleransi noise, yang selanjutnya membuka peluang baru untuk menghemat energi komunikasi.
Un-0 mewakili langkah penting pertama dalam perubahan paradigma komputasi menuju sistem dinamika. "Melalui peluncuran model ini, kami sedang menghubungkan kecerdasan dengan dinamika." Bagi komputasi AI, dinamika adalah kerangka ekspresi alami, jaringan neural pada dasarnya juga dapat dilihat sebagai sistem dinamika, sehingga pemetaan di antara keduanya akan lebih langsung.
"Tidak ada abstraksi aljabar linier seperti ini di otak, jadi dalam arti tertentu, kami melewati perantara."
Dan di bawah postingan tersebut, banyak pengguna juga menyatakan harapan.
"Sebenarnya, peningkatan efisiensi performa ini sangat besar. Jika teknologi ini dapat diterapkan secara luas, maka banyak aplikasi yang berjalan secara lokal mungkin menjadi layak."

"Jika teknologi ini bisa sampai ke pasar, itu benar-benar teknologi otak yang sangat canggih."

Tautan Referensi:
https://x.com/NaveenGRao/status/2070184079199494583
https://unconv.ai/blog/introducing-un-0-generating-images-with-coupled-oscillators/
https://techcrunch.com/2026/06/25/databricks-former-ai-chief-thinks-he-can-cut-ais-power-bill-by-1000x/
Artikel ini dari akun WeChat resmi "Jiqizhixin" (ID:almosthuman2014), penulis: fokus pada AI