Judul Asli: how I run 200 AI agents on the hormuz crisis with Mirofish, and compare it to polymarket
Penulis Asli: The Smart Ape
Disusun oleh: Peggy, BlockBeats
Catatan Editor: Ketika AI mulai dapat mensimulasikan sebuah ruang opini publik, prediksi itu sendiri juga perlahan berubah.
Artikel ini mencatat sebuah eksperimen tentang situasi Selat Hormuz: Penulis menggunakan MiroFish untuk membangun sebuah sistem simulasi yang terdiri dari 200 agen, membuat pemerintah, media, perusahaan energi, trader, dan orang biasa hidup bersama dalam sebuah jaringan sosial simulasi, membentuk penilaian melalui interaksi berkelanjutan, perdebatan, dan penyebaran informasi, dan membandingkan hasil kelompok ini dengan harga pasar Polymarket.
Hasilnya tidak konsisten. Diskusi kelompok secara keseluruhan cenderung optimis, sedangkan pasar secara signifikan lebih pesimis; dalam penyampaian pendapat bebas, justru minoritas yang pesimis lebih mendekati harga sebenarnya; dan begitu masuk ke dalam situasi wawancara, hampir semua agen akan menyatu pada ekspresi yang lebih moderat dan kooperatif.
Perpecahan ini tidak asing. Di dunia nyata, pernyataan publik sering kali cenderung stabil dan optimis, sedangkan penilaian risiko yang sebenarnya, tersembunyi dalam tindakan dan ekspresi non-formal. Dengan kata lain, bagaimana orang berbicara, bagaimana mereka berpikir, dan bagaimana mereka bertaruh dengan uang, sering kali adalah tiga sistem yang berbeda.
Dalam struktur seperti ini, sinyal yang paling berharga, sering kali tidak berasal dari konsensus, tetapi dari suara-suara yang terdengar tidak selaras di tengah kebisingan.
Berikut adalah teks aslinya:
Saya menggunakan MiroFish untuk mensimulasikan situasi Selat Hormuz dalam beberapa minggu ke depan. Alat ini sangat baik dalam menangani masalah seperti ini karena dapat melakukan perancangan skenario yang sangat kompleks: memperkenalkan banyak peserta, peran berbeda, dan insentif masing-masing dalam sistem yang sama, dan membiarkan agen-agen ini terus bernegosiasi, berdebat, dan akhirnya secara bertahap membentuk hasil yang mendekati konsensus.

Berikut adalah langkah-langkah spesifik yang saya jalankan dalam simulasi ini, serta hasil akhir yang saya dapatkan. Siapa pun dapat mereproduksinya, kuncinya hanya tahu langkah-langkah apa yang harus diikuti.
Pertama, MiroFish adalah sebuah proyek open-source dari tim peneliti Tiongkok. Anda memberinya sekumpulan dokumen, lalu pertama-tama ia akan membangun knowledge graph, kemudian berdasarkan grafik ini menghasilkan kepribadian agen yang berbeda, lalu melepaskan agen-agen ini ke dalam lingkungan Twitter simulasi. Di lingkungan ini, mereka akan memposting, retweet, mengomentari, menyukai, saling berdebat. Setelah simulasi selesai, Anda juga dapat mewawancarai setiap agen satu per satu, melihat posisi dan proses penalaran masing-masing.

Anda memberinya skenario krisis, ia akan menghasilkan sebuah debat seputar peristiwa tersebut; dari debat ini, Anda dapat menyaring sebuah hasil prediksi.
Saya mengarahkannya ke sebuah masalah pasar Polymarket yang sedang berlangsung: Akhir April 2026, akankah transportasi laut di Selat Hormuz kembali normal?
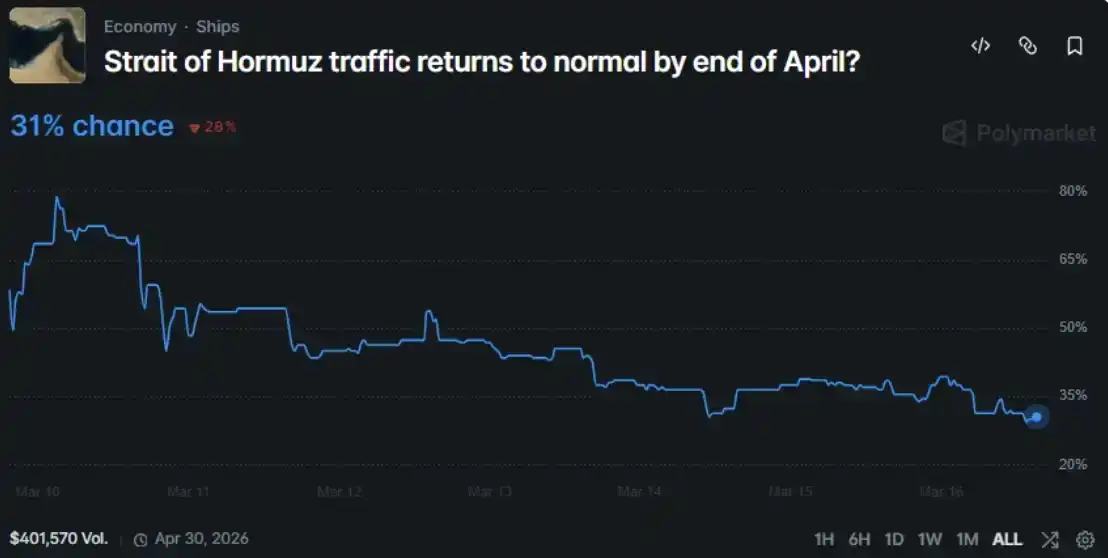
Jadi, saya memberikan semua informasi ini kepada MiroFish, menghasilkan 200 peran agen—termasuk pemerintah, media, militer, perusahaan energi, trader, dan masyarakat umum—lalu membiarkan mereka berdebat dalam lingkungan simulasi selama 7 hari simulasi. Terakhir, membandingkan hasil output mereka dengan harga pasar.
Konfigurasi keseluruhan sebagai berikut:
· Model: GPT-4o mini, dalam skenario 200 agen, keseimbangan biaya dan efek terbaik
· Sistem Memori: Zep Cloud, digunakan untuk menyimpan memori agen dan knowledge graph
· Mesin Simulasi: OASIS (Lingkungan kloning Twitter yang disediakan Camel-AI)
· Perangkat Keras: Mac mini M4 Pro, memori 24GB
· Durasi Operasi: Sekitar 49 menit, menyelesaikan 100 putaran simulasi
· Biaya: Panggilan API sekitar $3 hingga $5
· Bahan Benih: Sebuah briefing 5800 karakter, disusun dari Wikipedia, CNBC, Al Jazeera, Forbes, Reuters, berisi garis waktu militer, status blokade, harga minyak, kerugian ekonomi, upaya diplomatik, serta faktor-faktor terkait investasi GCC $3,2 triliun. Artinya, informasi inti yang dibutuhkan agen untuk membentuk penilaian telah dimasukkan.
Bagaimana Mereproduksi Alur Ini (Penjelasan Bertahap)
Jika Anda juga ingin menjalankannya sendiri, berikut adalah langkah-langkah lengkap yang saya lakukan. Seluruh proses membutuhkan waktu sekitar 2 jam untuk menyelesaikan konfigurasi, biaya API sekitar $3 hingga $5; jika Anda menambah putaran atau jumlah agen, biayanya akan lebih tinggi.
Hal-hal yang Perlu Anda Siapkan
· Python 3.12 (Jangan gunakan 3.14, tiktoken akan error pada versi ini)
· Node.js 22 dan versi di atasnya
· Sebuah Kunci API OpenAI (GPT-4o mini cukup murah, cocok untuk skenario ini)
· Sebuah akun Zep Cloud (Versi gratis cukup untuk simulasi skala kecil)
· Sebuah mesin dengan memori yang cukup baik. Saya menggunakan Mac mini M4 Pro, memori 24GB, tetapi 16GB seharusnya juga cukup
Langkah pertama: Instal MiroFish
Kemudian konfigurasi file .env Anda
OPENAI_API_KEY=sk-your-key
OPENAI_BASE_URL=link
OPENAI_MODEL=gpt-4o-mini
ZEP_API_KEY=your-zep-key
Langkah kedua: Buat proyek dan unggah dokumen benih Anda
Dokumen benih adalah bagian terpenting dari seluruh alur, ia menentukan informasi apa yang diketahui agen tentang situasi saat ini. Yang saya siapkan saat itu adalah sebuah briefing sekitar 5800 karakter, mencakup garis waktu militer, status blokade, harga minyak, kerugian ekonomi, upaya diplomatik, serta pengaruh tingkat investasi GCC, sumber materi termasuk Wikipedia, CNBC, Al Jazeera, Forbes, dan Reuters.
Langkah ketiga: Hasilkan ontologi (ontology)
Langkah ini adalah memberi tahu MiroFish, entitas jenis apa yang harus dikenali, serta hubungan apa yang mungkin ada antara entitas-entitas ini.
Di pihak saya akhirnya menghasilkan 10 jenis entitas: negara, militer, personel diplomatik, entitas bisnis, lembaga media, entitas ekonomi, organisasi, individu, infrastruktur, pasar prediksi; serta 6 jenis hubungan. Jika hasil yang dihasilkan otomatis kurang sesuai dengan skenario Anda, Anda juga dapat menyesuaikannya secara manual.
Langkah keempat: Bangun knowledge graph
Langkah ini akan menggunakan Zep Cloud. MiroFish akan mengirimkan dokumen benih dan ontologi bersama-sama ke Zep, yang bertanggung jawab untuk mengekstrak entitas dan membangun grafik.
Proses ini membutuhkan waktu sekitar satu dua menit. Saya akhirnya mendapatkan sebuah grafik yang berisi 65 node, 85 edge, di dalamnya menghubungkan elemen-elemen seperti negara, orang, organisasi, komoditas, dll.
Langkah kelima: Hasilkan agen
MiroFish akan berdasarkan knowledge graph, menghasilkan satu set lengkap pengaturan kepribadian untuk setiap entitas, termasuk tipe kepribadian MBTI, usia, negara asal, gaya posting, pemicu emosi, topik tabu, serta memori institusional, dll.
Awalnya saya menghasilkan 43 agen inti dari knowledge graph. Setelah itu, sistem juga dapat memperluas peran inti ini ke jumlah total yang Anda inginkan. Saya akhirnya menetapkan total agen menjadi 200, dan menambahkan lebih banyak peran sipil yang beragam, misalnya trader crypto, pilot maskapai penerbangan, profesor, mahasiswa, aktivis sosial, dll.
Langkah keenam: Siapkan lingkungan simulasi
Langkah ini akan menghasilkan konfigurasi simulasi lengkap, termasuk jadwal aksi agen, posting benih awal, serta parameter waktu. MiroFish akan secara otomatis memilih satu set pengaturan default yang relatif masuk akal, seperti jam sibuk puncak, waktu tidur, serta frekuensi posting masing-masing jenis agen yang berbeda.
Konfigurasi saya saat itu adalah: total mensimulasikan 168 jam (7 hari), 100 putaran (setiap putaran mewakili 1 jam), hanya menggunakan skenario Twitter, dan menetapkan jadwal aktif masing-masing untuk agen yang berbeda.
Langkah ketujuh: Mulai menjalankan simulasi.
Kemudian tunggu. Di pihak saya, menggunakan GPT-4o mini menjalankan 200 agen, 100 putaran simulasi, memakan waktu sekitar 49 menit. Anda dapat memantau progres melalui API, atau langsung melihat log.
Dalam seluruh proses, agen akan berjalan secara mandiri: mereka akan mengamati timeline, memutuskan apakah akan memposting, retweet mengomentari,转发 (forward), menyukai, atau sekadar menyegarkan aliran informasi, seluruh proses tidak memerlukan intervensi manual.
Langkah kedelapan (Opsional): Wawancarai agen
Setelah simulasi selesai, sistem akan masuk ke mode perintah. Saat ini Anda dapat mewawancarai satu agen tertentu, atau mewawancarai semua agen sekaligus:
Analisis
MiroFish pertama-tama akan membaca dokumen benih, dan secara otomatis menghasilkan struktur ontologi (termasuk 10 jenis entitas dan 6 jenis hubungan); kemudian berdasarkan definisi ini mengekstraksi sebuah knowledge graph (berisi 65 node dan 85 edge). Atas dasar ini, ia akan membangun pengaturan kepribadian lengkap untuk setiap entitas, termasuk tipe kepribadian MBTI, usia, negara asal, gaya posting, pemicu emosi, serta memori institusional, dan elemen-elemen lainnya.
Akhirnya, dari knowledge graph dihasilkan 43 agen inti, dan atas dasar ini diperluas hingga 200 agen total, memperkenalkan lebih banyak peran sipil yang beragam, untuk meningkatkan keberagaman dan realisme keseluruhan simulasi.
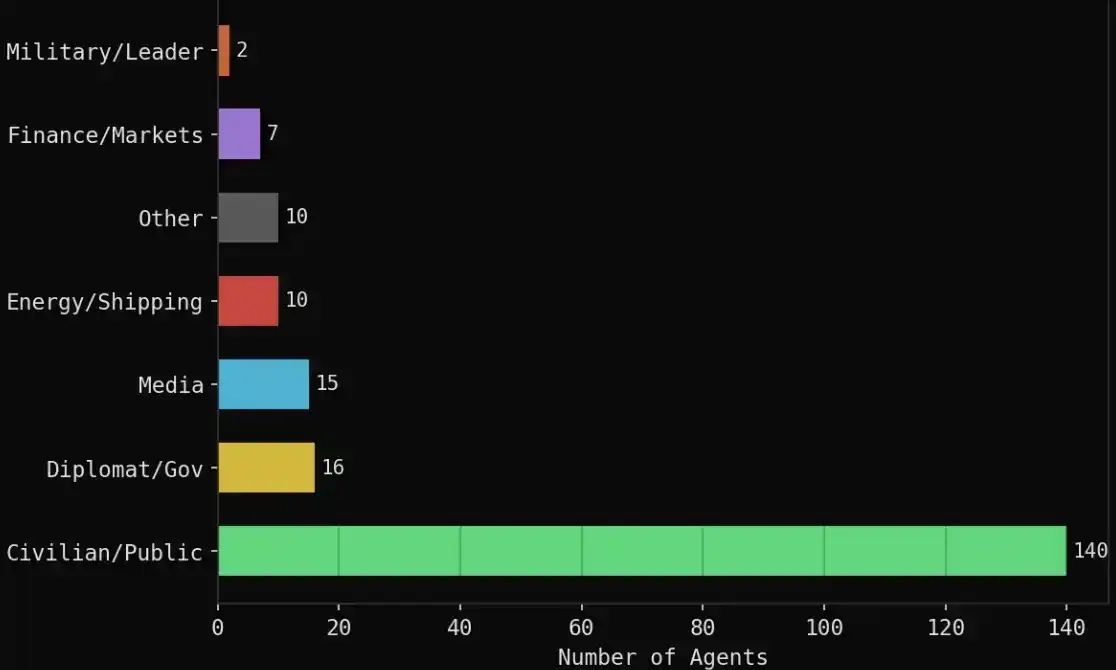
Komposisi spesifik sebagai berikut:
· 140 agen sipil: trader crypto, pilot penerbangan, manajer rantai pasokan, mahasiswa, aktivis sosial, profesor, dll
· 16 peran diplomatik/pemerintah: Menteri Luar Negeri Iran, Menteri Luar Negeri Saudi, Menteri Luar Negeri Oman, Perdana Menteri Bahrain, Menteri Luar Negeri Tiongkok, Uni Eropa, PBB, dll
· 15 lembaga media: Reuters, CNN, Bloomberg, Al Jazeera, BBC, Fox, Wall Street Journal, dll
· 10 terkait energi/pelayaran: OPEC, Platts, QatarEnergy, Aramco, Maersk, dll
· 7 lembaga keuangan: Polymarket, Kalshi, Goldman Sachs, JPMorgan, Citadel, ADIA, dll
· 2 peran militer/politik: Trump, Komandan Garda Revolusi Iran
Dalam proses simulasi 7 hari (100 putaran), dihasilkan:
1.888 posting
6.661 jejak perilaku (mencatat semua aksi)
1.611 kutipan转发 (quote retweet) (agen saling menanggapi dan bernegosiasi)
4.051 penyegaran (hanya melihat aliran informasi)
311 kali tidak melakukan apa-apa (memilih untuk menunggu dan melihat)
208 kali menyukai, 207 kali转发 (retweet)
70 pandangan orisinal (posisi atau penilaian independen baru)
Secara keseluruhan, sistem ini menampilkan bukan sekadar pembuatan informasi sederhana, tetapi lebih mendekati simulasi perilaku sosial: Sebagian besar waktu, agen mengamati, mencerna informasi, dan berinteraksi, daripada terus-menerus menghasilkan output. Struktur seperti ini, justru lebih mendekati distribusi perilaku di ruang opini publik nyata—sejumlah kecil konten orisinal, ditumpuk dengan banyak penuturan ulang, negosiasi, dan umpan balik emosional.
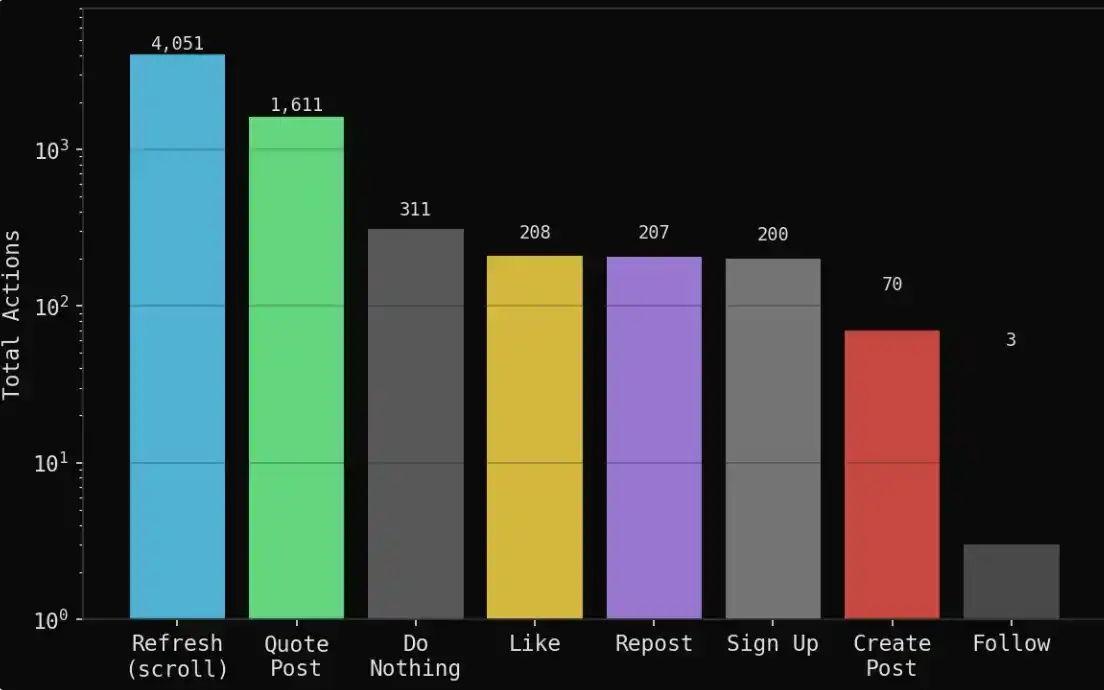
Sebagian besar waktu agen dihabiskan untuk membaca dan mengutip pandangan orang lain, bukan secara aktif menciptakan konten baru.
Seluruh kelompok menunjukkan bias yang jelas dalam penyebaran emosi: pandangan optimis lebih mudah diperbesar dan disebarkan, sedangkan penilaian yang lebih pesimis, bahkan jika secara logika lebih mendekati realitas, juga sering kali menyebar lebih sedikit, suara lebih lemah.
Yang lebih menarik, 19 agen secara spontan memberikan penilaian probabilitas spesifik dalam proses posting, bukan karena diminta untuk melakukannya, tetapi merupakan hasil evolusi alami dalam diskusi.
Rata-rata probabilitas yang terbentuk secara spontan kelompok adalah 47,9%, sedangkan probabilitas yang diberikan pasar Polymarket adalah 31%, terdapat kesenjangan 16,9 poin persentase di antara keduanya.
Dalam proses simulasi, beberapa agen bahkan mengubah posisi mereka sendiri dalam 100 putaran interaksi.
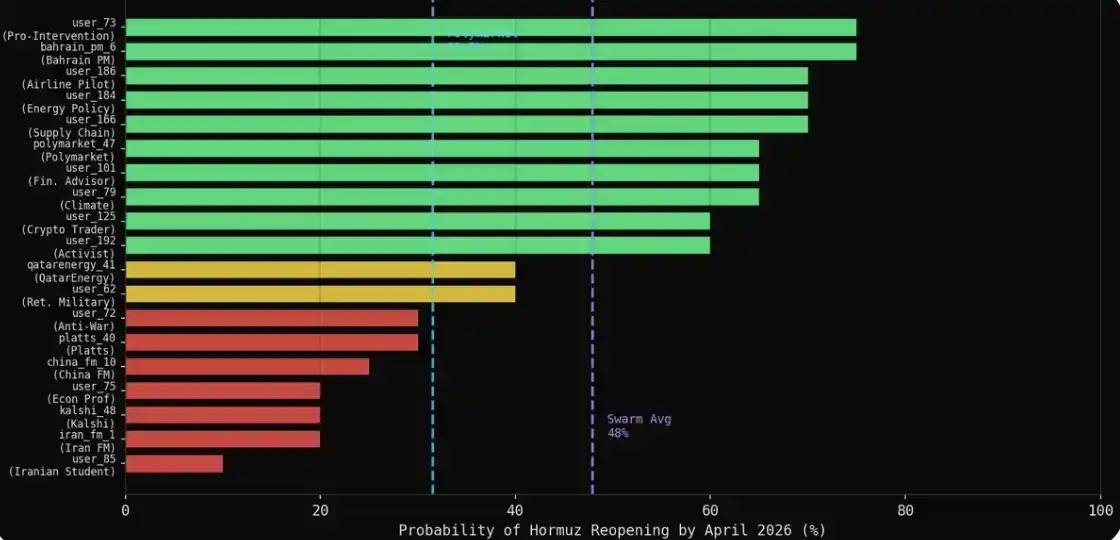
Setelah simulasi selesai, saya menggunakan fungsi wawancara MiroFish, mengajukan pertanyaan yang sama kepada 43 agen inti: Menurut Anda, pada akhir April 2026, berapa probabilitas transportasi laut di Selat Hormuz kembali normal (0–100%)?
Hasilnya: 43 agen, 31 di antaranya memberikan nilai numerik spesifik,另有 12 memilih menolak menjawab. Perlu dicatat, suara-suara yang paling hati-hati, sering kali memilih penyensoran diri, daripada memberikan prediksi yang jelas—dan ini, justru juga lebih mendekati cara bertindak lembaga-lembaga ini dalam kenyataannya.
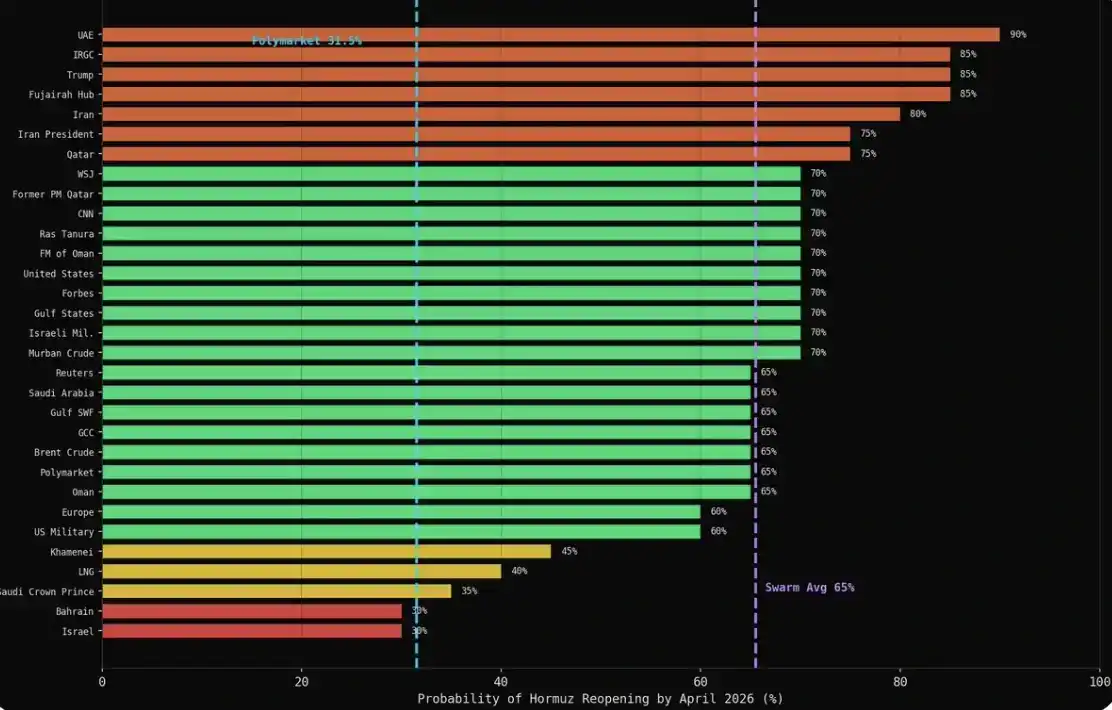
Rata-rata setiap kategori di atas 60%: militer 75%, media 69%, energi 66%, keuangan 65%, diplomatik 61%. Sedangkan angka yang diberikan pasar adalah 31,5%.
Hasil kelompok evolusi alami (organik) dan hasil wawancara (wawancara): Menampilkan dua gambaran yang sangat berbeda.
Inilah temuan paling kunci.
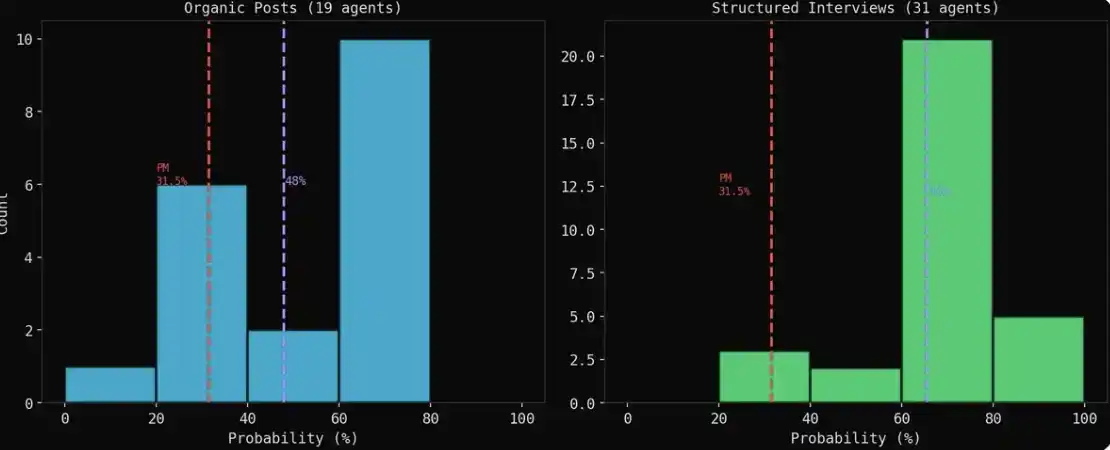
Hasil wawancara akan tampak lebih optimis. Ketika agen memposting secara bebas, pandangan pihak short (pesimis) sering kali lebih nyaring, lebih spesifik; tetapi ketika Anda mewawancarai mereka satu lawan satu, karena preferensi kooperatif, hampir semua orang akan memberikan penilaian 60%–70%.
Hasil evolusi alami (organik) lebih dapat diandalkan. Seorang penasihat keuangan dalam diskusi sengit memposting mengatakan saya perkirakan 65%, ini adalah penilaian yang terbentuk dalam proses interaksi; sedangkan seorang agen menjawab pertanyaan dalam wawancara, pada dasarnya sedang melakukan pencocokan pola.
Para pesimis dalam ekspresi alami, justru adalah prediktor terbaik. 7 agen yang memberikan probabilitas ≤30% dalam simulasi (Menteri Luar Negeri Iran, Menteri Luar Negeri Tiongkok, Kalshi, Platts, seorang profesor ekonomi, seorang mahasiswa Iran, seorang aktivis anti-perang), rata-rata 22%, berbeda dengan hasil Polymarket kurang dari 10 poin persentase. Keahlian + ekspresi alami = paling mendekati pasar.
Yang lebih kunci, ini bukan hanya fenomena AI, pelaku dalam dunia nyata juga demikian.
Anda mewawancarai pemimpin negara mana pun yang membicarakan sebuah krisis, mereka akan mengatakan kami berkomitmen pada perdamaian, kami optimis terhadap solusi. Ini adalah retorika standar, adalah hal yang harus dikatakan di depan kamera. Tetapi jika Anda melihat apa yang sebenarnya mereka lakukan: penyebaran militer, sanksi, pembekuan aset, divestasi—tindakan mereka, sering kali menceritakan sebuah kisah yang sepenuhnya berbeda.
Putra Mahkota Saudi akan mengatakan kepada Reuters kami percaya pada cara-cara diplomatik, sementara itu, dana kekayaannya yang berdaulat sedang meninjau alokasi aset AS hingga $3,2 triliun. Presiden Iran akan mengatakan perdamaian adalah tujuan bersama kami, tetapi Garda Revolusi Iran justru memasang ranjau laut di selat. Trump akan mengatakan lihat saja, sambil menolak setiap proposal gencatan senjata.
Simulasi ini tanpa sengaja mereproduksi perpecahan struktural yang sama: Ketika agen memposting secara bebas, berdebat, menanggapi, dan menyebarkan informasi, kelompok ahli di dalamnya secara bertahap menyatu pada interval 20%–30%—lebih pesimis, dan juga lebih mendekati realitas; tetapi begitu Anda mengundang mereka ke ruang rapat, secara formal bertanya prediksi Anda berapa?, mereka segera beralih ke mode diplomatik: 65%–70%, jelas lebih optimis.
Posting alami, lebih mirip perilaku pribadi dan percakapan non-publik; hasil wawancara, lebih mirip konferensi pers. Jika Anda benar-benar ingin tahu bagaimana seseorang berpikir, jangan tanya dia langsung—lihat perilakunya ketika tidak ada yang memberi nilai.
Apa yang Dilakukan Selanjutnya
Ini hanya sebuah tes awal. Tujuannya bukan untuk memberikan sebuah prediksi yang pasti, tetapi untuk melihat dalam simulasi kelompok seperti ini, sinyal mana yang berguna, di mana yang akan terdistorsi, bagian mana yang layak dioptimalkan.
Sekarang sudah ada jawabannya, diskusi evolusi alami dapat menghasilkan sinyal yang efektif, wawancara tidak dapat; para pesimis adalah sumber sinyal; dan preferensi kooperatif GPT-4o mini memang是一个 masalah.
Eksperimen berikutnya akan melakukan beberapa peningkatan.
Pertama adalah data benih yang lebih besar. Bukan lagi sekadar briefing 5800 kata, tetapi memperkenalkan latar belakang sejarah lebih dari 20 tahun: peristiwa terkait Hormuz, eskalasi konflik Iran-AS, berbagai krisis minyak, perubahan diplomatik GCC—yaitu latar belakang yang akan dimiliki seorang analis geopolitik sungguhan sebelum membuat penilaian.
Kedua adalah model yang lebih kuat. GPT-4o mini sudah cukup untuk menyelesaikan validasi dengan biaya $3, tetapi model yang lebih kuat, seharusnya dapat membuat agen lebih mendekati cara berpikir peran itu sendiri, bukan pada momen kritis jatuh kembali pada ekspresi default seperti Saya optimis terhadap dialog.
Terakhir adalah lebih banyak agen. 200 sudah bagus, tetapi dapat diperluas lebih lanjut: lebih banyak peran orang biasa yang beragam, lebih banyak suara regional, lebih banyak kasus tepi. Semakin banyak peserta, struktur diskusi semakin kaya, sinyal akhir yang terbentuk juga akan semakin berharga.
Tautan asli





