Melakukan riset teknologi sebenarnya adalah hal yang penuh jebakan (baik bagi manusia maupun AI), karena dari awal riset, kita akan menerima banyak informasi, pandangan semakin banyak, kesimpulan semakin kabur. Jadi, harus selalu tahu cara kembali ke tujuan awal.
Ini juga alasan mengapa AI tidak cukup unggul selama ini, karena dari sudut pandang perhatian dan asosiasi, ia lebih terperangkap oleh volume informasi saat ini dibandingkan manusia, dan sangat lemah dalam melakukan asosiasi lintas bidang yang benar-benar bernilai.
Tentu saja, keunggulan AI adalah eksekusinya, yang dapat berbentuk agen untuk mencari, meringkas, dan menyimpulkan secara bertahap, sepenuhnya menghindari kehilangan detail.
Meskipun saya hampir tidak memposting di WeChat publik selama setengah tahun terakhir, saya hampir selalu memantau dan meneliti secara menyeluruh bidang utama di industri ini, dan yang mendukung input-output ini adalah sistem deep-research saya sendiri.
Dan menghadapi peluncuran fitur Dynamic Workflows di Claude Code pekan lalu, saya ingin saling bertarung, melihat apakah kemampuannya default dapat sepenuhnya melampaui milik saya sendiri.
2. Apa itu Dynamic Workflows
Dynamic Workflows (Alur Kerja Dinamis) inti pemikirannya adalah: sebelum menjalankan tugas, AI secara otomatis merancang alur kerja apa yang seharusnya digunakan untuk menyelesaikan tugas ini, baru kemudian memulai eksekusi.
Ini berbeda secara mendasar dengan "mode perencanaan" dan "skill" yang kita gunakan sebelumnya. Mode perencanaan memecah tugas menjadi lebih detail, tetapi belum tentu sesuai dengan alur kerja yang wajar. Hanya dengan pengaturan prompt Anda, mungkin baru ditambahkan kriteria penerimaan (ini sangat penting untuk Research), begitu pula Anda hanya akan lebih baik menetapkan beberapa aturan harness ketika ada prompt.
Namun, alur kerja dinamis akan secara otomatis menggabungkan logika penerimaan, konvergensi hasil, verifikasi adversarial, dan sebagainya.
Cara memicunya sederhana, langsung gunakan /deep-research di cc lalu berikan beberapa templat riset dan bahan masukan. Jika ingin menggunakan kemampuan alur kerja dinamis secara terpisah, gunakan prompt atau langsung katakan ultracode, sebelum digunakan perhatikan, konsumsi token kira-kira puluhan kali dari biasanya.
3. Enam Mode Alur Kerja Bawaan
Di balik alur kerja dinamis, terdapat enam mode penjadwalan inti yang disimpulkan secara resmi, inilah alasan mengapa ia lebih kuat daripada dialog/agent/skill biasa.
Sebenarnya, di balik enam mode ini hanya ada dua masalah inti: Bagaimana tugas dipecah? Bagaimana hasil digabungkan? Enam mode pada dasarnya adalah kombinasi dari kedua hal ini.
3.1 Mode Rute (Classify-And-Act)
Pertama, satu agen membedakan jenis tugas, lalu membagikan tugas ke agen khusus yang paling cocok untuk dikerjakan. Logika intinya adalah logika pemilihan rute, bukan paralel atau iteratif. Satu tugas hanya mengambil satu jalur, jalur lain sama sekali tidak dieksekusi.
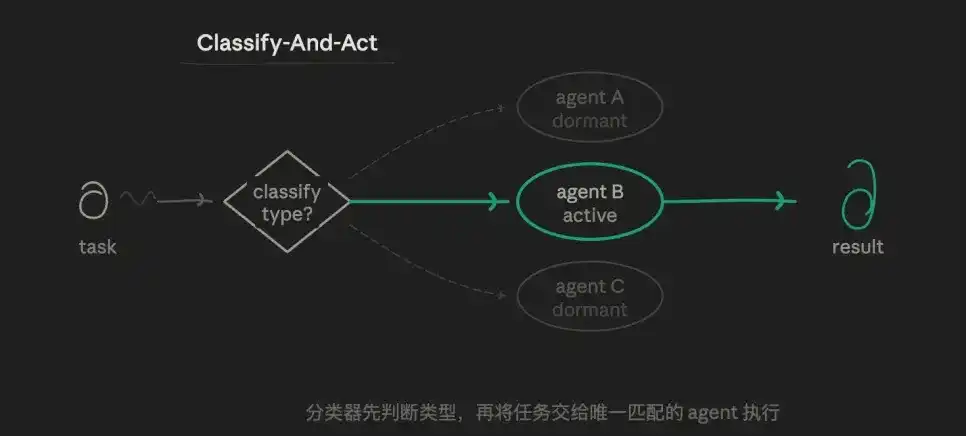
Misalnya, saya dapat memiliki tiga peran subagent yang telah ditetapkan sebelumnya: satu agen analisis yang memverifikasi data dengan ketat, satu agen output yang pandai menulis, satu agen penantang yang khusus mencari celah. Lapisan rute akan menilai sub-tugas saat ini cocok diserahkan ke siapa, bukan diserahkan seluruhnya ke satu agen.
Nilai mode ini terletak pada: ketepatan dan efisiensi, setiap prompt agen dapat sangat independen, tidak terganggu oleh tujuan lain, membentuk eksplorasi yang mendalam secara vertikal. Konsumsi token terendah, kecepatan respons tercepat. Batasan tanggung jawab sangat jelas.
Kelemahannya juga sangat nyata, kemampuan menangani tugas dengan batasan kabur (misalnya "masalah teknis sekaligus masalah akun") lemah.
3.2 Membagi dan Menggabungkan (Fan-out & Merge)
Juga mode yang paling sering saya gunakan, logika intinya adalah paralel+gabung. Tugas dipecah menjadi N sub-tugas independen yang dijalankan bersamaan, setelah semua selesai baru digabung secara seragam.
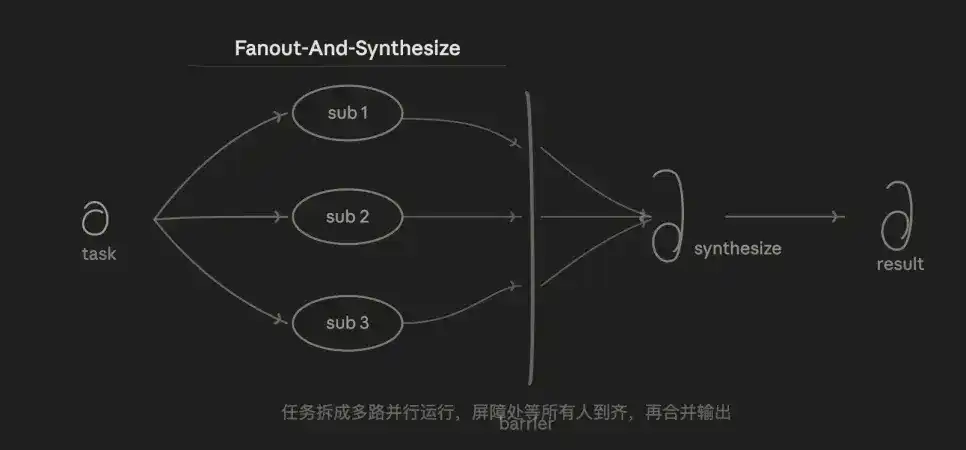
Keunggulannya terletak pada kecepatan dan isolasi. Total waktu yang dibutuhkan kira-kira sama dengan sub-tugas yang paling lambat, bukan jumlah semua sub-tugas. Setiap sub-tugas memiliki konteks independen, tidak saling mengganggu, juga tidak akan mencemari sub-tugas lain karena noise dari satu sub-tugas.
Kelemahannya adalah biaya token N kali lipat dari serial, lapisan penggabungan (Synthesize) itu sendiri juga sulit—bagaimana menggabungkan output dengan struktur yang tidak konsisten dari N jalur adalah tantangan desain. Pembagian sub-tugas yang buruk akan menyebabkan kehilangan atau tumpang tindih.
3.3 Verifikasi Adversarial (Adversarial Verification)
Logika intinya adalah pemeriksaan, untuk kesimpulan yang sama, biarkan beberapa agen menantang dari sudut pandang "menyangkal", dianggap lulus hanya jika suara melebihi setengah.
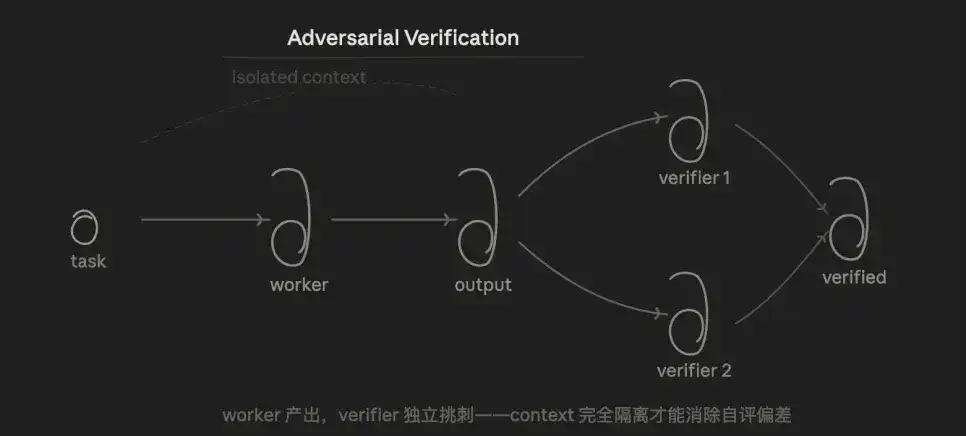
Keunggulannya terletak pada, karena Verifier tidak tahu pemikiran Worker, hanya melihat hasilnya, secara struktural menghilangkan bias penilaian diri saat "meminta model memeriksa kode yang ditulisnya sendiri".
Mode ini memecahkan masalah yang telah lama mengganggu saya: kita sering berbicara dengan AI dengan cara yang informal, tetapi AI cenderung menjawab sesuai ekspektasi Anda, mudah menimbulkan "konfirmasi bias". Melalui verifikasi adversarial, AI dipaksa untuk mencari contoh yang bertentangan, untuk memverifikasi berdasarkan data dan eksperimen, bukan memenuhi pemikiran Anda.
Namun, jika verifikasi memberikan penilaian yang salah, maka akan menyesatkan Worker untuk memenuhi Verifier. Jadi, sebaiknya didasarkan pada fakta yang dapat direproduksi, bukan mengandalkan opini.
Bercanda sedikit, jika Anda meminta AI mencari masalah, ia dapat menemukan masalah tanpa henti, jadi Anda harus membatasi batasan pencarian masalahnya.
3.4 Menghasilkan dan Menyaring (Generate & Filter)
Logika intinya adalah menyebar lalu menyatu. Pertama sengaja menghasilkan kandidat berlebihan, lalu menggunakan rubrik untuk menyaring hingga yang terbaik, hanya mempertahankan hasil dengan kepercayaan tinggi untuk output.
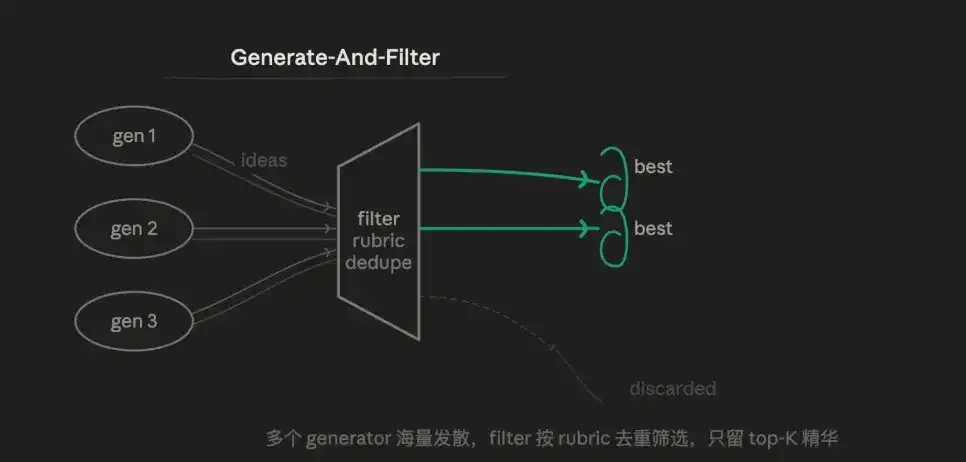
Daripada satu agen mengeluarkan jawaban yang "cukup", lebih baik menghasilkan sepuluh, lalu disaring dengan lapisan verifikasi. Oleh karena itu, keunggulannya terletak pada keragaman. Beberapa Generator dapat menggunakan strategi berbeda, prompt berbeda, menghasilkan solusi yang sulit diprediksi manusia, langkah penyaringan membuat kualitas output akhir sangat terkonsentrasi.
Kelemahannya adalah, kualitas rubrik Filter secara langsung menentukan efek akhir, desain rubrik yang salah berarti seluruh alur kerja gagal.
Cocok untuk skenario di mana jawaban yang benar tidak diketahui sebelumnya, perlu memilih yang terbaik dari berbagai kemungkinan, dan ada kebutuhan eksplisit untuk keragaman.
Hanya mirip permukaan dengan Fanout-And-Synthesize: Keduanya adalah "paralel multi-jalur → output tunggal", paling mudah membingungkan.
Perbedaan kunci terletak pada niat: Setiap jalur Fanout menangani bagian berbeda dari tugas, hasilnya saling melengkapi, semua jalur berkontribusi saat digabung; Setiap jalur Generate-And-Filter menangani tugas yang sama, hasilnya bersaing, sebagian besar akan dibuang saat digabung. Yang pertama adalah "puzzle", yang kedua adalah "kontes kecantikan".
3.5 Mode Turnamen (Tournament)
Logika intinya adalah kompetisi eliminasi. N agen masing-masing secara independen melakukan hal yang sama, melalui perbandingan berpasangan eliminasi putaran demi putaran, akhirnya memilih solusi terbaik.
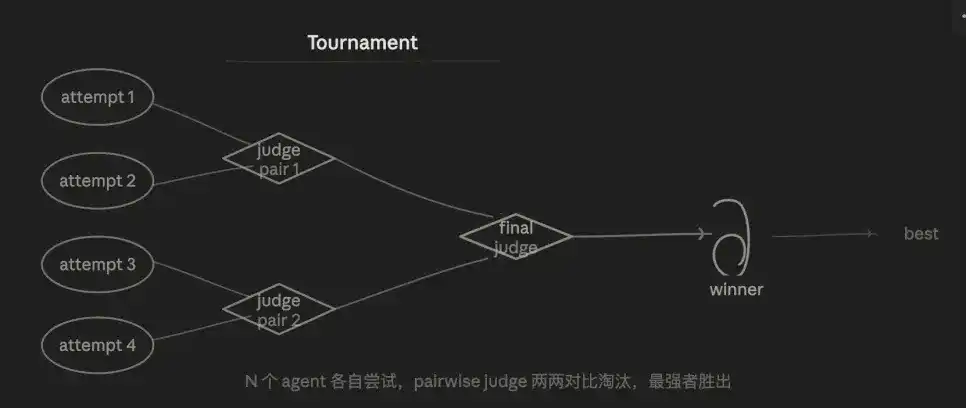
Saya pernah melakukan ini secara manual sebelumnya—menjalankan dua atau tiga versi dari perubahan kode yang sama, lalu meminta AI membandingkan mana yang lebih baik. Sekarang dapat langsung diatur dalam alur kerja.
Keunggulannya terletak pada stabilitas penilaian. Perbandingan berpasangan ("mana yang lebih baik, A atau B?") jauh lebih stabil daripada penilaian absolut ("beri nilai A"), karena menghilangkan masalah pergeseran standar penilaian. Hasilnya melalui beberapa putaran kompetisi, pemenang akhir memiliki tingkat kepercayaan yang tinggi.
Juga mirip permukaan dengan Generate-And-Filter: Keduanya memilih yang terbaik dari beberapa kandidat. Perbedaan kunci terletak pada mekanisme pemilihan: Tournament menggunakan penilaian berpasangan, adalah "membuat kandidat saling bersaing". Ketika rubrik sulit diukur, dan penilaian pada dasarnya relatif, akan lebih andal.
3.6 Mode Loop (Loop)
Logika intinya adalah iterasi adaptif, terus mencoba, saat menghadapi hambatan mengumpulkan informasi kesalahan, menambahkan konteks, mencoba ulang, hingga memenuhi kondisi penerimaan.
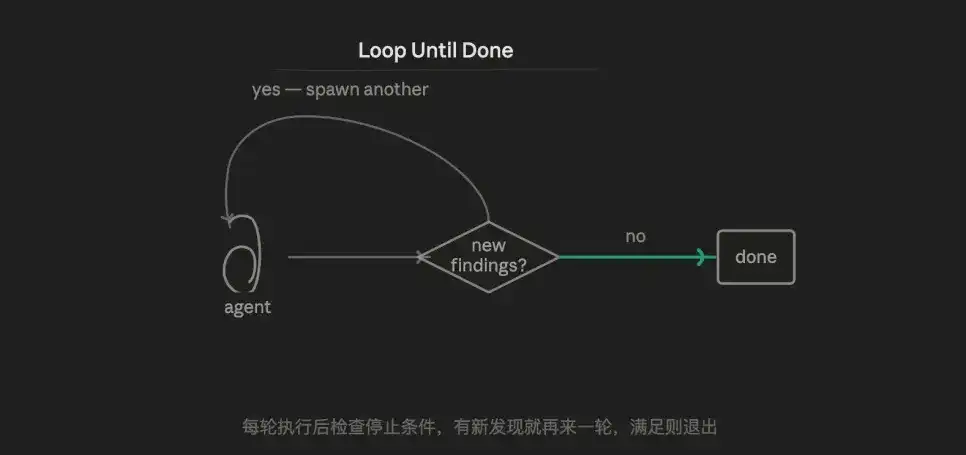
Pada dasarnya melawan keacakan AI: coba beberapa kali, pasti akan menemukan hasil yang lebih baik. Tetapi cara yang lebih matang adalah menggabungkan dengan verifikasi adversarial, membuat setiap putaran eksekusi membawa lebih banyak informasi, bukan hanya mengandalkan keacakan.
Keunggulannya terletak pada kemampuan menangani tugas dengan volume kerja yang tidak diketahui. Lima mode lain mengasumsikan batasan tugas pasti, Loop Until Done adalah satu-satunya mode yang dapat menangani "tidak tahu berapa banyak putaran yang harus dilakukan".
Kelemahannya adalah risiko potensial kehilangan kendali—desain kondisi berhenti yang buruk akan menyebabkan loop tak terbatas. Agen setiap putaran adalah konteks baru, tidak dapat mengakumulasi status lintas putaran (kecuali secara eksplisit ditulis ke file).
4. Skill Saya Sendiri vs Alur Kerja Resmi
Sebelum alur kerja dinamis muncul, saya secara khusus merancang deep-research saya sendiri. Logika skill saya kira-kira seperti ini:
- Hanya memberikan informasi sederhana (misalnya suatu proyek meluncurkan fungsi baru)
- Meminta AI mencari semua materi terkait: dokumentasi resmi, kode sumber, opini pasar
- Mengompres informasi menjadi ringkasan yang bermakna
- Beberapa peran agen melakukan analisis adversarial, menghasilkan laporan
- Otomatis menghapus duplikat, karena tingkat duplikasi konten multi-agen sangat tinggi
Setelah digunakan beberapa waktu, saya merasa cukup bagus. Tetapi memiliki satu kelemahan mendasar: kurangnya konvergensi yang berorientasi pada tujuan.
Dan bahkan dengan langkah kelima penghapusan duplikat, seringkali ia menghapus informasi berharga; jika tidak dilakukan penghapusan duplikat, skill sering memberi Anda artikel panjang puluhan ribu kata, informasi lengkap, tetapi tidak secara langsung memberi tahu Anda "apa hubungannya dengan Anda, apa yang harus Anda lakukan".
Namun, penelitian bertujuan untuk melayani "pengambilan keputusan", inilah alasan mengapa banyak skill hanya berhenti pada penelitian itu sendiri, mendapatkan 80 poin, tetapi kurang 20 poin yang paling kritis.
Sehingga AI setelah menyelesaikan penelitian awal, masih perlu berpikir dan berdialog sepuluh kali lagi untuk mencapai kesimpulan yang memuaskan dan menyeluruh.
Apa yang Lebih Dilakukan oleh Alur Kerja Dinamis Resmi
Melalui eksperimen beberapa tugas riset kompleks minggu ini, saya menemukan bahwa deep research workflow bawaan Claude Code (perhatikan, bukan hanya skill, tetapi modul yang dikompilasi dan disematkan dalam cc), dibandingkan dengan skill saya sendiri, memiliki beberapa tautan kunci tambahan:
- Lapisan Dekomposisi Masalah: Ia tidak langsung mulai mencari, tetapi mulai bertanya terlebih dahulu, memecah masalah saya menjadi beberapa sub-masalah: Apa yang benar-benar ingin Anda pahami? Apa hubungannya dengan Anda? Dimensi mana yang layak diselidiki? Langkah ini sebelumnya saya lewati.
- Penilaian Kredibilitas: Menilai kemampuan untuk dibantah dari setiap informasi, mirip dengan penilaian otoritas dalam SEO tradisional—apakah sumbernya dapat dipercaya? Berapa kali dikutip? Ini adalah tautan yang sebelumnya tidak terpikir oleh saya untuk ditambahkan.
- Penghapusan Silang Bukan Penggabungan Rata-Rata: Cara saya sebelumnya adalah memilih semua kesimpulan secara rata-rata, sehingga dokumennya besar. Alur kerja dinamis akan melakukan pemungutan suara multi-agen untuk setiap kesimpulan, yang kurang suara akan dihapus, bukan sekadar digabungkan.
- Output Berorientasi Tujuan: Laporan akhir bukan tumpukan informasi, tetapi memberikan penilaian dan saran solusi berdasarkan tujuan awal Anda. Kunci untuk mencapai ini terletak pada kemampuannya yang telah ditetapkan untuk menjadwalkan multi-subagent. Alasan skill saya sebelumnya mudah kekurangan orientasi tujuan akhir adalah karena penurunan bobot perintah setelah informasi yang sangat banyak.
Masalah Apa yang Diatasi oleh Mekanisme Ini?
Menargetkan beberapa masalah tipikal AI dalam melakukan tugas panjang:
Pergeseran Tujuan: Kondisi baik di awal tugas, di tengah tidak tahu sedang apa, di akhir kembali menemukan ritme—mirip manusia melamun di kelas. Semakin panjang tugas semakin jelas.
Berhenti Terlalu Cepat: Saat berjalan menghadapi kesulitan, AI menganggap dirinya "selesai" dan berhenti, padahal standar penerimaan sama sekali belum terpenuhi.
Polusi Konteks: Satu agen melakukan tugas kompleks, sejumlah besar prompt sebelumnya akan menekan ruang eksekusi berikutnya. Cara yang lebih baik adalah mengontrol prompt sebelumnya dalam beberapa ribu, menggunakan multi-agen untuk membagi konteks.
Bias Output: AI cenderung menjawab sesuai ekspektasi Anda, pertanyaan informal lebih mudah memicu masalah ini.
Dan alur kerja dinamis memecahkan keempat masalah ini dengan cara terstruktur: otomatis menambahkan indikator penerimaan untuk mencegah berhenti terlalu dini; isolasi paralel konteks; verifikasi adversarial mengimbangi bias output; dekomposisi masalah membatasi AI untuk memahami tujuan terlebih dahulu baru bertindak.
5. Ringkasan
Terakhir, penulis sebagai pekerja riset yang sudah lama, takjub dengan mekanisme baru CC ini, enam mode bawaan—pilihan rute, pembagian penggabungan, verifikasi adversarial, penyaringan hasil, turnamen, loop—mencakup sebagian besar kebutuhan penjadwalan tugas riset kompleks.
Saya tidak perlu lagi merancang penjadwalan agen secara manual, juga tidak perlu melakukan penghapusan duplikat dan verifikasi silang sendiri, semua ini telah dikompilasi ke dalam alur kerja itu sendiri.
Dan ia sangat cocok untuk berpikir dalam eksplorasi masalah yang kurang informasi dan bersifat terbuka, karena penjadwalan multi-agen alami + pemecahan tujuan tugas, meningkatkan keuniversalannya lagi. Sebenarnya, sejak 3 tahun yang lalu, AI sudah sangat baik dalam menyelesaikan masalah kecil yang sangat jelas dengan kendala bertingkat. Tetapi transformasi kualitatif AI yang sebenarnya masih terletak pada keuniversalannya, inilah yang membuat pesaingnya, dari kode sederhana menjadi benar-benar menjadi Agen, dari menyelesaikan satu masalah secara statis, hingga beradaptasi dengan masalah apa pun.
Jadi Dynamic Workflows bukanlah "dialog tunggal yang lebih pintar", melainkan membuat alur proses riset itu sendiri menjadi terstruktur.
Awalnya saya perlu memulai riset dengan sepuluh kali lebih dialog independen, sekarang dikompres menjadi 3-4 kali. Meskipun konsumsi Token yang sesuai telah meningkat puluhan kali lipat.
Mengapa masih perlu 3-4 kali? Saya pikir akar penyebabnya terletak pada perbedaan kebutuhan ini.
Pertama adalah keketatan mekanisme verifikasi, saya terutama meneliti teknologi baru di blockchain, banyak hal, dokumentasi resmi tertinggal, ada data yang lebih layak dijadikan referensi seperti kode sumber terbuka, transaksi on-chain, dll. Sedangkan saat ini AI default masih mengandalkan dokumentasi resmi, bukan verifikasi faktual.
Kedua adalah pemikiran mendalam yang sepenuhnya lintas bidang, meskipun beberapa hal dapat diselesaikan melalui preset alur kerja (mendefinisikan berbagai dimensi subAgent sebelumnya) untuk berpikir tentang masalah yang sama. Tetapi AI lebih ahli dalam model pemikiran mainstream, untuk hal yang sangat baru, sangat dalam, kurang data, agak kurang.
Ketiga adalah Desain dan Verifikasi Solusi, makna solusi bukan terletak pada pengajuan tetapi pada verifikasi, dukungan, ia bergantung pada pengukuran mekanisme, investasi, dan biaya yang ada. Jika AI dilatih dengan baik tentu dapat melakukan lebih baik, tetapi ini bertentangan dengan keuniversalan.
Terakhir adalah konsentrasi informasi yang ekstrem, ini membutuhkan pemahaman tentang tingkat pengetahuan audiens informasi, beberapa orang tidak memiliki dasar latar belakang sama sekali, membutuhkan Anda menyampaikan dengan cara yang personified, sementara pendengar lain, membutuhkan Anda menyentuh mereka dengan satu kalimat~.





