Oleh | Luo Chao Channel
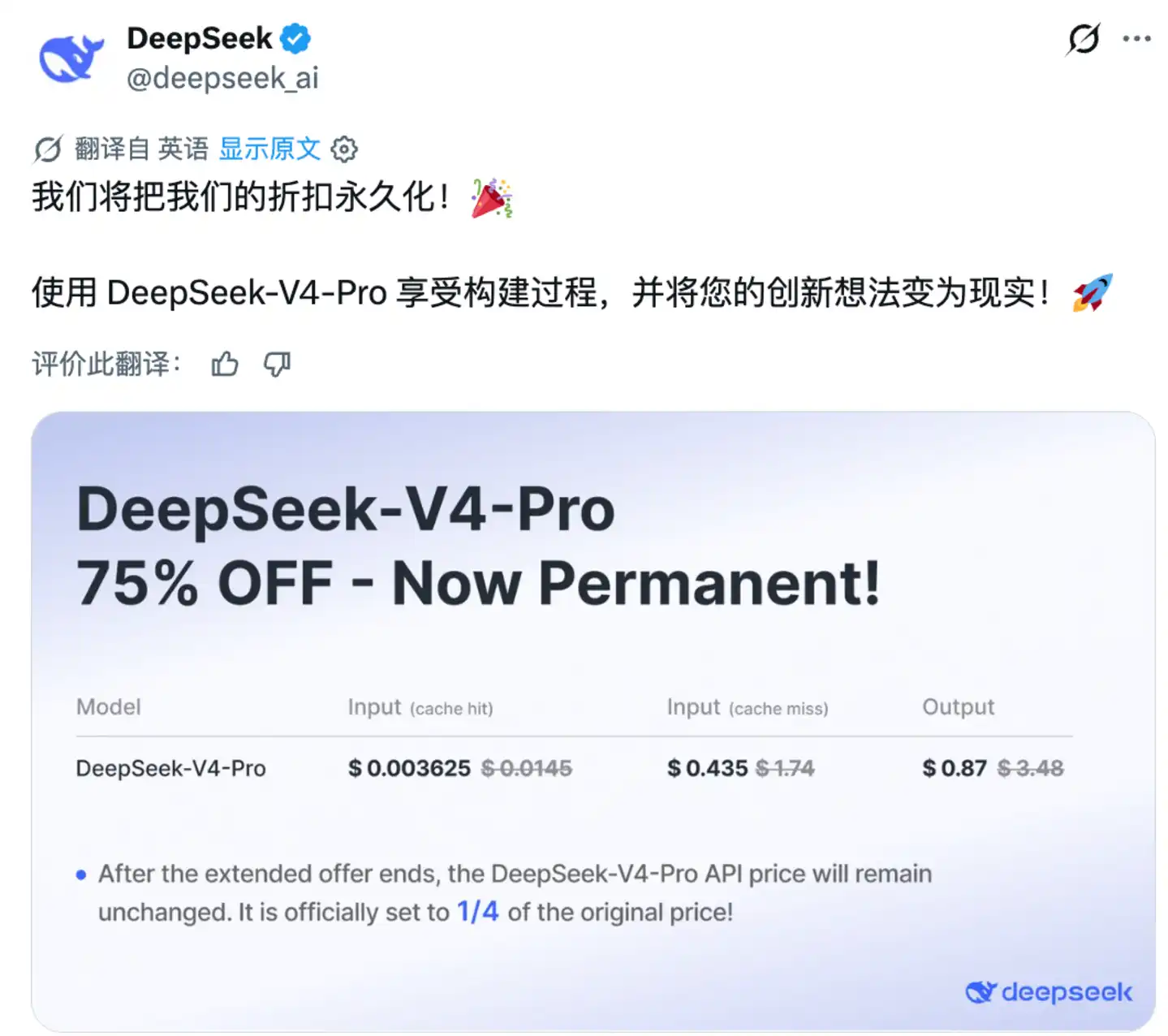
DeepSeek mengumumkan akan mempertahankan secara permanen diskon 75% untuk API V4-Pro, berlaku secara global.
Struktur harga akhir: harga input dasar turun dari 1,74 dolar AS / juta Token menjadi 0,435 dolar AS / juta Token, harga output turun dari 3,48 dolar AS / juta Token menjadi 0,87 dolar AS / juta Token. Untuk cache input yang mengenai target di seluruh lini produk API, DeepSeek memberikan keuntungan yang lebih besar: 0,003625 dolar AS / juta Token, semuanya mengikuti model penetapan harga lantai ala Pinduoduo.
Media sosial termasuk X segera diramaikan dengan seruan: Liang Wenfeng adalah Bodhisattwa Siber di lingkaran AI, Dewa Feng, Liang yang Suci. Sentimen ini tidak hanya berasal dari harga murah itu sendiri — DeepSeek selalu disebut sebagai Pinduoduo-nya AI, gratis untuk pengguna akhir (C-end), murah untuk bisnis (B-end), dunia sudah terbiasa dengan kemurahannya, tetapi yang sulit dari gelombang penurunan harga kali ini adalah: AI di seluruh dunia sedang naik harganya.
Ada laporan bahwa Liang Wenfeng dalam putaran pendanaan Seri A rekor yang sedang diupayakan DeepSeek, akan menginvestasikan pribadi hingga 20 miliar yuan RMB, setara dengan 40% dari total pendanaan. Hal pertama yang dilakukan sebagian besar perusahaan saat pendanaan adalah memperkuat arus kas, membuat kinerja terlihat lebih baik, tetapi Liang Wenfeng tidak berencana menggunakan kue komersialisasi untuk menarik investor, melainkan tetap berkomitmen pada open-source, mengejar AGI, gelombang penurunan harga ini benar-benar sesuai kata-katanya. Terakhir kali yang berani mengatakan tidak ingin mencari untung adalah Pinduoduo, pada tahun 24, salah satu pendirinya secara eksplisit menyatakan dalam panggilan telepon dengan investor: "Mulai Q3, laba kami akan turun secara bertahap, dan tidak akan pulih dalam waktu dekat. Dalam jangka panjang, penurunan profitabilitas tidak terhindarkan." Harga sahamnya anjlok.
Sam Altman mulut mengatakan demokratisasi AI, tetapi OpenAI sebagai perusahaan justru sedang bergerak cepat ke arah kebalikan dari namanya: CloseAI. Sementara Liang Wenfeng justru menjalankan secara nyata agar setiap orang, setiap perusahaan dapat menggunakan AI secara seluas dan semurah mungkin. Tetapi apakah Liang Wenfeng benar-benar Bodhisattwa hidup? Bukan. Dia adalah seorang pengusaha, open-source dan kemurahan hanyalah pilihan model bisnis, yang sangat berharga saat ini, dan akan semakin langka di masa depan.
Karena: AI sedang menjadi semakin mahal.
Minggu ini, Microsoft membatalkan lisensi Claude Code internalnya, karena metode penagihan berbasis token terlalu tinggi hingga tak tertahankan. Microsoft pernah mendukung OpenAI dengan dana besar, juga menyediakan layanan cloud Azure untuk Anthropic, memiliki sumber daya komputasi awan yang diidamkan semua perusahaan, namun biaya Token tetap membuatnya sakit hati. Tak sendirian, CTO Uber pada April tahun ini melaporkan kepada manajemen situasi memalukan: anggaran AI yang disiapkan perusahaan untuk seluruh tahun 2026, habis dalam empat bulan, di mana 95% insinyur menggunakan alat pemrograman AI setiap bulan, 70% kode yang disubmit dihasilkan oleh AI, ucapannya: "I’m back to the drawing board because the budget I thought I would need is blown away already." (Saya kembali ke papan gambar karena anggaran yang saya kira akan dibutuhkan sudah habis lebih dulu.)
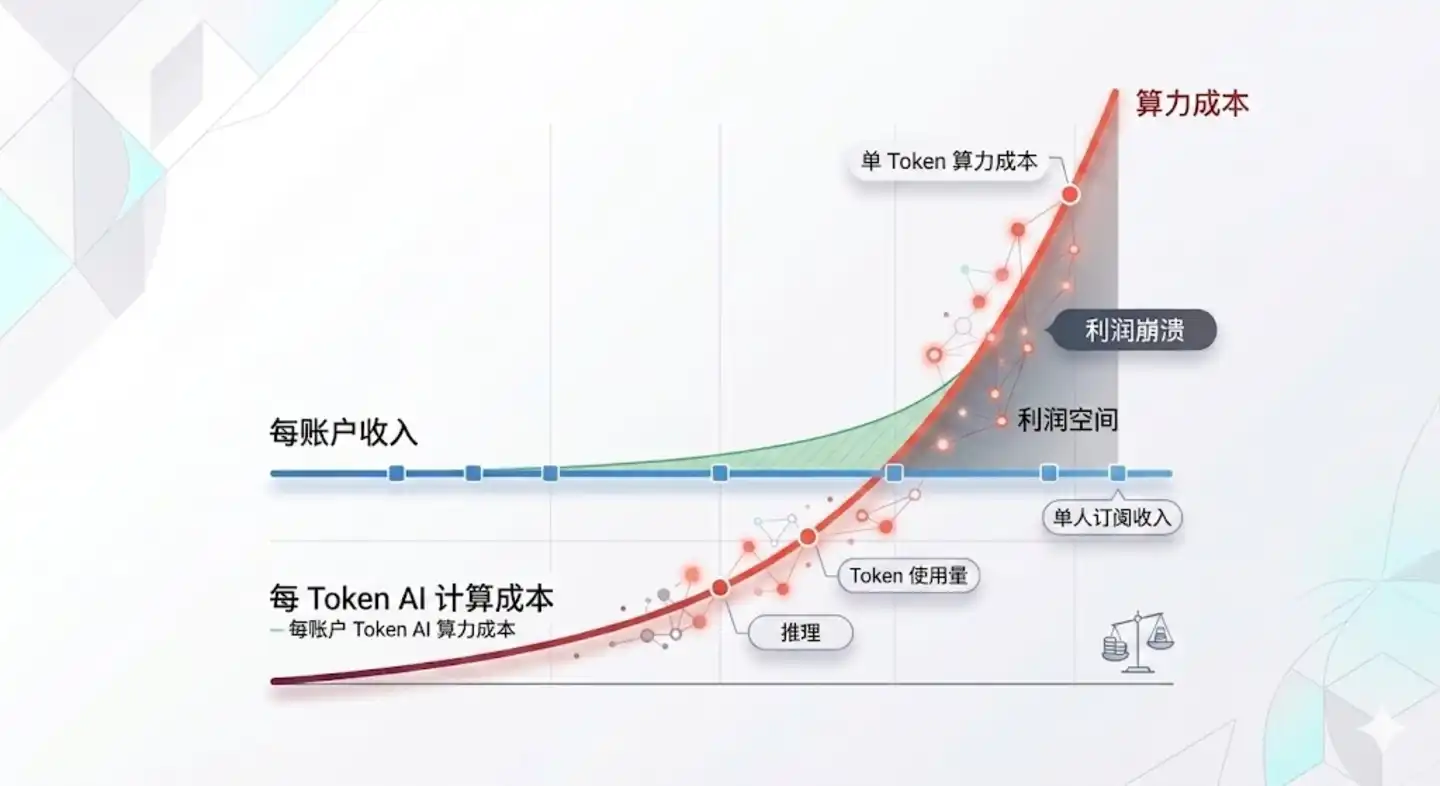
Anggaran Token perusahaan besar habis lebih cepat dari perkiraan, tentu ada alasan karyawan perusahaan yang "menganggap remeh" dan membakar Token habis-habisan, tetapi akar ketegangan anggaran Token adalah AI yang semakin mahal. Harga perangkat lunak AI di AS naik 20% hingga 37% dalam setahun terakhir. Anthropic, OpenAI, dan Google (tiga besar) diam-diam menaikkan harga aktual untuk output AI yang sama dalam enam bulan terakhir.
(Sumber: X)
Suara yang populer sebelumnya adalah "semakin besar skala penerapan AI, semakin tinggi tingkat industrialisasinya, semakin rendah biayanya, semakin senang perusahaan", ternyata naif.
Dan tren ini tidak akan berbalik. Harga ditentukan oleh permintaan dan penawaran, bukan biaya, tetapi hubungan permintaan dan penawaran AI pada tahun 26 telah sepenuhnya terbalik. Dulu perusahaan besar memohon-mohon agar orang menggunakan AI, harus mengedukasi pasar, mempromosikan teknologi, AI selalu disubsidi, berapa banyak teh susu gratis dari Qianwen yang sudah kamu minum? Sekarang? Semakin banyak orang yang secara aktif menggunakannya, "setelah menghirup napas pertama, tidak bisa lepas", pemrograman AI, dokumen AI, AIGC bahkan pencarian AI, semakin populer, era subsidi AI benar-benar berakhir.
Semakin banyak yang menggunakan, semakin besar permintaannya, semakin ketat sumber daya token, sehingga kelangkaan daya komputasi (computing power) meluap dari GPU ke CPU, penyimpanan bahkan bandwidth, Intel, Micron, SK Hynix, Samsung Electronics, SanDisk serta Jiangbolong, "dua panjang" (mungkin mengacu pada perusahaan Tiongkok tertentu) dalam negeri ikut menikmati keuntungan bersama Nvidia. Dari mana pendapatan raksasa semikonduktor yang bertambah berlipat ganda pada tahun 26 berasal? Bukan dari lingkaran investasi segitiga OpenAI-Oracle-Microsoft! Rasa sakit hati perusahaan-perusahaan ini baru permulaan? Dan produk AI seperti ChatGPT, Claude, Gemini, Doubao yang menekankan hierarki ketat antara gratis dan berbayar, juga akan membuat pengguna individu semakin bimbang.
Ini seperti taksi online: saat gila-gilaan kamu bisa naik taksi khusus pulang-pergi kerja secara gratis, modal yang membayar untukmu. Setelah kebiasaan pengguna terbentuk, subsidi berakhir, harga kembali ke tingkat normal, yang seharusnya naik kereta bawah tanah ya harus naik kereta bawah tanah. AI juga begitu. Jadi dalam latar belakang besar industri AI yang harganya naik, DeepSeek bersikeras menurunkan harga, tindakan ini tidak lagi hanya menunjukkan keberanian pribadi "Bodhisattwa Siber", melainkan menunjukkan kekuatan penetapan harga berlawanan: Saya bisa semurah ini, tetap beroperasi normal, kualitas tidak turun.
Selama Liang Wenfeng mau, DeepSeek sama sekali tidak perlu semurah ini. Lalu orang mulai khawatir: Akankah DeepSeek menjadi Linux-nya era AI? Pengaruhnya besar, tetapi tidak menghasilkan uang besar. Kontribusi Linux bagi industri IT jauh lebih besar daripada Windows, daripada Android (Android sendiri berbasis kernel Linux), tetapi dia open-source, secara komersial tidak melahirkan raksasa seperti Microsoft, Google. Pengaruh DeepSeek saat ini besar, kemampuan komersialnya jauh di bawah tiga besar Silicon Valley, bahkan tidak dapat menyaingi tiga perusahaan dalam negeri: Kimi, MiniMax, dan Zhipu. Urutan pendapatan empat naga kecil tahun 25: Zhipu (pendapatan 2025: 724 juta yuan) > MiniMax (pendapatan 2025: sekitar 560 juta yuan) > Moonshot AI (sekitar 200 juta yuan) > DeepSeek (tidak diketahui tetapi lebih rendah).
Liang Wenfeng menghasilkan uang dari AI kuantitatif, secara pribadi bisa mengeluarkan 20 miliar untuk berinvestasi di DeepSeek, tetapi kisah "menghasilkan listrik dengan cinta" tidak bisa bertahan lama.
Juga dalam mode open-source, orang lain juga bisa melakukan distilasi, penyebaran (deployment), pelatihan ulang (re-training), parit teknologi DeepSeek akan semakin tipis. Jadi kamu selalu melihat berita "peringkat teratas" seperti ini: GLM-5.1 open-source Zhipu setelah dirilis menyegarkan rekor global dalam pengujian tolok ukur SWE-bench Pro, MiMo-V2.5-Pro Xiaomi menduduki puncak peringkat model besar open-source global... Laporan bersama MIT dan Hugging Face menunjukkan, dalam setahun terakhir model open-source yang dikembangkan Tiongkok menyumbang 17,1% dari unduhan global, melampaui AS sebesar 15,8%, peringkat pertama global.
Tidak heran semakin banyak suara di Silicon Valley yang mengatakan: Harus ada DeepSeek versi AS, tidak bisa hanya diam melihat industri AI kembali memainkan kisah Shein, Temu, atau TikTok. "Jika AS tidak memiliki juara open-source yang bangkit, dunia akan dijalankan di tangan negara mana pun yang dapat menghasilkan model dan perangkat lunak open-source terkuat, paling stabil, termurah, dapat disesuaikan, dapat diskalakan, sesuai dengan kebutuhan pribadi dan bisnis." Topik yang menyangkut persaingan negara besar seringkali agak luas, tetapi persaingan di baliknya nyata.
Di balik kebangkitan DeepSeek, memang ada narasi penggantian mandiri. Dukungan V4 untuk Ascend membuat orang bersukacita, didorong oleh daya komputasi dalam negeri, daya saing harga yang ditunjukkan DeepSeek saat ini baru pembuka. Dalam laporan teknis, DeepSeek menyatakan setelah node super Ascend 950 diluncurkan secara massal pada paruh kedua tahun, harga V4-Pro akan turun drastis lagi, hari-hari baik masih di depan.
Ada juga keunggulan bakat AI tingkat tinggi, bakat AI mahal hingga tingkat "mewah", tetapi relatif lebih murah di Tiongkok, berita tentang Lei Jun yang menggaji Luo Fuli dari DeepSeek dengan gaji 10 juta yuan per tahun menjadi berita, sementara pada periode yang sama Mark Zuckerberg harus mengeluarkan 1 miliar dolar AS untuk merekrut orang, termasuk akuisisi untuk perekrutan (Acqui-hire). Tetapi perbedaan antara orang seharga 1 miliar dolar AS dan orang seharga 10 juta yuan per tahun dalam membuat sesuatu jelas tidak mencapai 700 kali lipat, perbedaan harga bakat AI sebenarnya akan berubah menjadi perbedaan harga sistemik dalam sistem produksi Token.
Daya saing yang lebih besar lagi adalah sistem energi, ini adalah lapisan pertama dari lima lapisan kue AI Jensen Huang.
Ujung AI adalah daya komputasi, ujung daya komputasi adalah listrik. April 2026, perekrutan DeepSeek menempatkan insinyur operasi dan pemeliharaan senior dan manajer pengiriman senior pusat data di Ulanqab, Mongolia Dalam, ini menunjukkan dia akan pergi ke barat untuk membangun pabrik Token, menekan keunggulan biaya dari lapisan perangkat lunak hingga lapisan fisik. Terakhir kali saya menulis tentang Ulanqab dalam artikel adalah ketika Kuaishou membangun pusat data di sini: dekat dengan pembangkit listrik, iklim cocok untuk pendinginan. Dan harga listrik hijau di barat Tiongkok sekitar 0,2-0,3 yuan/kWh, hanya 1/5 hingga 1/4 dari Eropa dan AS.
Bukan hanya listrik hijau barat yang kompetitif. Data Badan Energi Internasional (IEA) tahun 2025 menunjukkan, total kapasitas terpasang pembangkit listrik Tiongkok telah melebihi 2300 GW, sekitar 22% dari global, peringkat pertama dunia; AS sekitar 1300 GW. Yang lebih krusial adalah, Tiongkok memiliki struktur kelistrikan paling lengkap di dunia: listrik tenaga batu bara, air, angin, nuklir, fotovoltaik semuanya lengkap. Data menunjukkan, harga listrik industri Tiongkok dalam jangka panjang dipertahankan pada 0,06 hingga 0,08 dolar AS/kWh, harga listrik industri California AS sudah mendekati 0,18 dolar AS/kWh, di beberapa bagian Jerman bahkan melebihi 0,25 dolar AS/kWh, ini berarti melatih kluster sepuluh ribu kartu (10k-card cluster) yang sama, Tiongkok secara alami lebih murah puluhan persen daripada Eropa dan AS.
Dalam biaya operasi model besar AI, proporsi biaya listrik terhadap total biaya operasi mencapai 60%-70%, bukan hanya model yang berjalan membutuhkan listrik, tetapi juga pendinginan yang merupakan bagian besar, "infrastruktur gila" bahkan membangun pusat data langsung di dasar laut, listrik tenaga angin lepas pantai dimasukkan dari dekat, sementara air laut bersirkulasi mendinginkan secara gratis. Juga "pengiriman listrik barat ke timur", "penghitungan barat data timur" (proyek besar), kemampuan pengaturan daya listrik dan daya komputasi regional sangat kuat, Guizhou, Mongolia Dalam, Ningxia, tempat-tempat ini memang simpul inti "penghitungan barat data timur", jalan untuk memindahkan pusat daya komputasi AI ke barat sudah disiapkan sejak lama.
Menggunakan AI Tiongkok, pada dasarnya adalah menggunakan AI yang dilatih oleh sistem energi yang lebih kompetitif — AI yang lebih ekonomis, lebih merata. Ini adalah salah satu alasan mengapa pendapatan luar negeri Kimi, Minimax, dkk melonjak setelah Tahun Baru Imlek, bukan hanya karena algoritma lebih kuat, tetapi juga membuka cheat listrik.
Nvidia dapat mendefinisikan harga daya komputasi tinggi, tetapi DeepSeek dan kawan-kawan justru menguasai kekuatan penetapan harga Token. Kamu mungkin berkata, AI murah tidak ada barang bagus. AI memang sesuai harga dengan kualitas, DeepSeek V4 hanya memperkecil kesenjangan antara open-source dan closed-source ke tingkat terkecil sepanjang sejarah, secara resmi mengakui kesenjangan objektif dengan model puncak seperti GPT, dan juga bukan multimodal, bisa mengenali gambar, tetapi tidak bisa menghasilkan.
Tetapi ini tidak menghentikan komunitas membanjiri DeepSeek. Alasannya: sebagian besar skenario bisnis nyata tidak memerlukan pemanggilan model terkuat dunia setiap kali. Konsultasi, layanan pelanggan, ringkasan, terjemahan, penyempurnaan kode (code completion), basis pengetahuan perusahaan, otomatisasi proses, hal-hal ini tidak membutuhkan kecerdasan tertinggi, melainkan "cukup bisa digunakan + cukup murah + cukup stabil". Ketika biaya inferensi DeepSeek V4 hanya sekitar 1% (Flash) hingga 11% (Pro) dari GPT-5.5, sebuah perusahaan dengan anggaran yang sama dapat memanggil puluhan kali lipat lebih banyak token, mencoba lebih banyak rantai prompt, mengulangi lebih banyak alur kerja agen, akhirnya hasil yang dikeluarkan justru berpeluang lebih baik, toh AI sendiri adalah permainan "probabilitas", asal cukup murah, mencoba-coba bisa mendapatkan hasil, apa salahnya?
Jadi, semakin mahal AI, semakin berharga kemurahan DeepSeek, semakin berharga perusahaan DeepSeek ini, Liang Wenfeng dan investornya berpikir lebih jelas dari siapa pun.





