Oleh | Teknologi Tidak Boleh Dingin
Tanggal 24 April, sebuah sepatu jatuh di arena model besar domestik. DeepSeek-V4 versi preview resmi diluncurkan dan sekaligus open source, langsung menjadikan konteks super panjang 1M (satu juta kata) sebagai konfigurasi standar layanan resmi.
Jika setahun yang lalu, kemampuan pemrosesan teks panjang tingkat ini masih menjadi hak eksklusif perusahaan-perusahaan besar luar negeri yang dikunci di balik tembayar berbayar tingkat perusahaan. Sekarang, ini langsung dibentangkan di atas meja komunitas open source, menjadi infrastruktur yang dapat diambil dan digunakan kapan saja oleh pengembang. Bagi pengembang yang sering begadang menangani basis kode yang panjang atau kontrak hukum yang rumit, ini jelas merupakan kabar baik.
Namun di balik penurunan teknologi ini, siaran pers resmi menyisakan satu kalimat yang sangat sederhana: "Dibatasi oleh komputasi high-end, saat ini throughput layanan DeepSeek-V4-Pro sangat terbatas".
Bagi mereka yang terbiasa melihat vendor berbicara besar tentang cadangan komputasi dalam konferensi pers, kejujuran seperti ini terasa sangat langka dan dingin.
Model besar memasuki babak kedua, siapa yang punya berapa banyak chip perangkat keras high-end, industri sudah tahu. Daripada mempertahankan kemakmuran di tingkat parameter, lebih baik mengungkapkan kondisi industri yang sebenarnya. Langkah DeepSeek kali ini sebenarnya adalah melepaskan obsesi berlomba skor murni, dan menemukan satu set skema kompromi yang mempertimbangkan evolusi teknologi dan kondisi perangkat keras saat ini, di antara terobosan algoritma inti, ekosistem komputasi heterogen domestik yang masih perlu disempurnakan, dan lingkungan bisnis nyata perusahaan.
Industri AI China sedang melepaskan pakaian awal yang membakar uang secara membabi buta, dan memasuki era "buku besar komputasi" yang sangat realistis.
Bagaimana Menyeimbangkan Buku Besar Komputasi Versi Pro?
Secara spesifik, lihatlah V4-Pro yang throughput-nya secara eksplisit dibatasi. Sebagai flagship dalam sistem, V4-Pro memiliki total parameter hingga 1.6T, tetapi saat inferensi hanya perlu mengaktifkan 49B parameter. Desain sparse yang sangat ekstrem ini bukanlah model etalase yang hanya untuk dipamerkan; di bawah pemeriksaan ketat lini produksi nyata, landasan teknologinya memiliki ketahanan yang sangat kuat.
Mampu menangani kode kompleks dan penalaran logika adalah batu ujian apakah model besar benar-benar dapat memasuki link produksi inti. Dalam lingkungan evaluasi Agentic Coding (kode agen), kinerja praktis V4-Pro dengan mantap berada di jajaran teratas model open source saat ini.
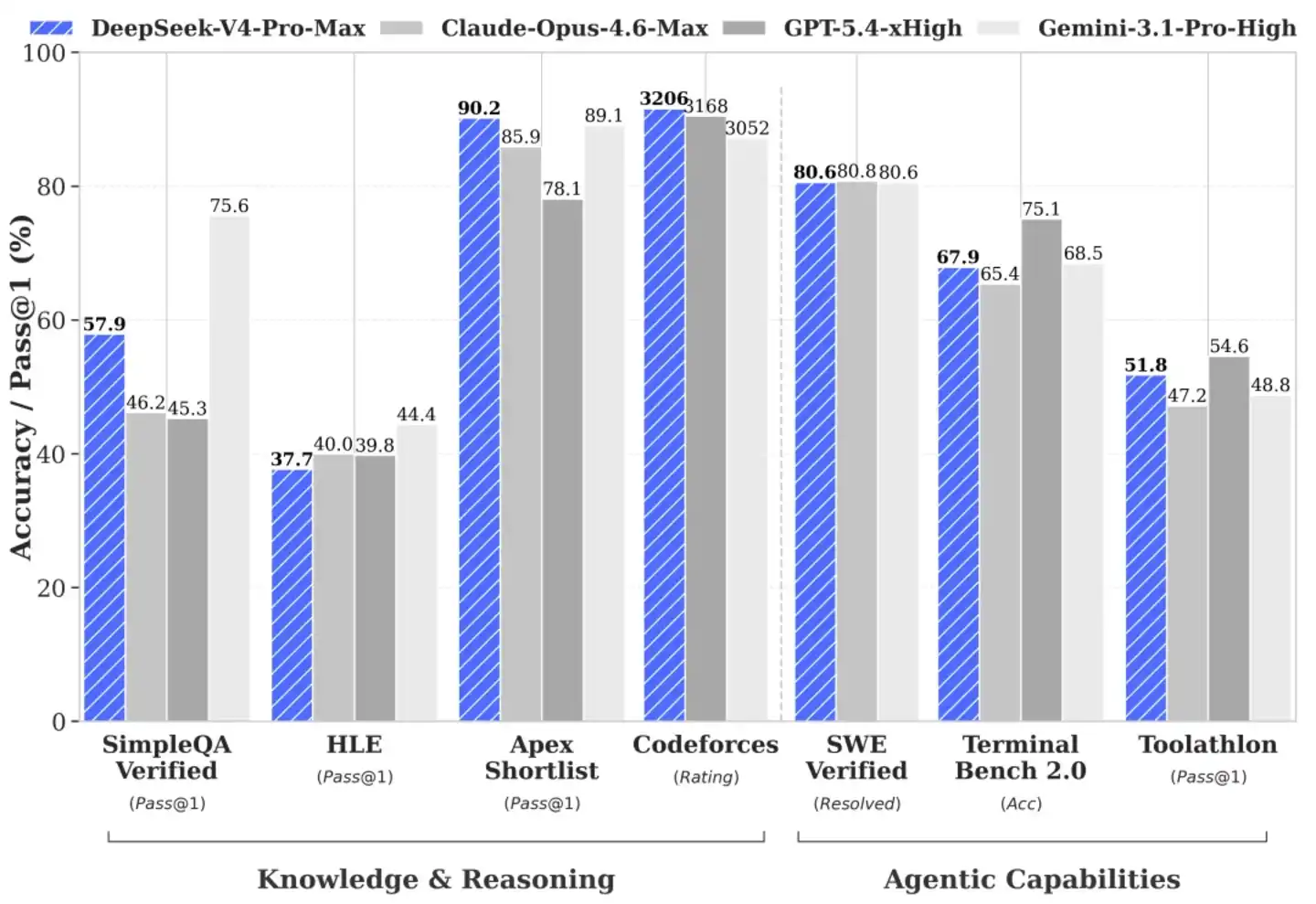
DeepSeek telah lama menghubungkannya ke pipeline kode internal, menjadikannya alat produktivitas yang sangat diandalkan oleh insinyur lini depan. Umpan balik dari personel R&D menunjukkan bahwa pengalaman pembuatan kode dan koreksi kesalahannya lebih baik daripada Sonnet 4.5, dan dalam skenario non-pemikiran mendalam telah mendekati Opus 4.6, meskipun masih ada kesenjangan dengan mode pemikiran Opus 4.6.
Di balik kinerja pertempuran nyata ini adalah penggalian ekstrem tim penelitian terhadap kedalaman algoritma. Dalam evaluasi pengetahuan dunia yang menguji kualitas pembersihan data pelatihan awal dan kepadatan pengetahuan, V4-Pro memimpin sebagian besar model open source yang ada, saat ini hanya sedikit lebih rendah dari model tertutup puncak Gemini-Pro-3.1. Adapun matematika, STEM (Sains, Teknologi, Teknik, Matematika), serta evaluasi kode tipe kompetisi, ia mendapatkan tiket untuk bertanding di panggung yang sama dengan perusahaan model besar tertutup puncak dunia.
Mendapatkan kekuatan tempur seperti ini jelas bukan hanya mengandalkan tumpukan kartu komputasi. Tim domestik tahu, jika benar-benar bersaing cadangan kartu grafis high-end tidak realistis. V4-Pro dapat menangani konteks super besar 1M dengan memori terbatas, dukungan dasarnya adalah tim R&D yang melakukan rekonstruksi mendalam terhadap mekanisme perhatian. Mereka mencapai skema kompresi perhatian baru, melakukan kompresi intensitas tinggi pada dimensi token, dan dipadukan dengan teknologi perhatian sparse DSA andalannya (DeepSeek Sparse Attention).
Jalur teknologi orisinal ini, ditambah dengan algoritma sliding window dan kompresi KV Cache yang diperkenalkan pertama kali, secara efektif mengendalikan biaya komputasi dan penggunaan memori yang disebabkan oleh pemrosesan urutan panjang. Agar pengembang benar-benar dapat memanggil kemampuannya dalam bisnis, tim R&D khusus melakukan adaptasi底层 untuk alat Agent utama seperti Claude Code, OpenClaw, dll.
Dokumentasi teknis bahkan secara eksplisit menunjukkan bahwa pengembang dapat langsung mengaktifkan mode pemikiran saat menangani tugas kompleks, dengan mengatur parameter reasoning_effort ke max. Optimasi teknik tingkat sistem yang dilakukan di bawah sumber daya komputasi terbatas ini justru membuktikan kepada industri bahwa bahkan dengan komputasi high-end yang terbatas, tim domestik masih dapat melebarkan batas kinerja model melalui desain arsitektur asli.
13B Aktivasi Mengunci Siapa?
Mereka yang memfokuskan pada bottleneck throughput versi Pro sering mengabaikan titik tumpu bisnis yang disembunyikan DeepSeek di belakang, versi Flash. Ada suara di industri yang menganggap ini hanya produk kompromi di bawah kekurangan komputasi, pandangan ini jelas meremehkan pertimbangan jangka panjang tim manajemen. Ini adalah posisi yang matang setelah perhitungan biaya yang ketat, terhadap ekosistem下沉 yang diluncurkan secara pragmatis.

Menurut informasi kode adaptasi yang diungkapkan, total parameter versi Flash dipertahankan pada level 284B yang besar, tetapi parameter aktivasi-nya, secara presisi dikunci pada 13B.
13B, dalam konteks di mana rekan-rekan mencoba mendorong parameter ke skala triliunan, tampak tidak mencolok. Namun ini justru mencerminkan logika ekonomi arsitektur Mixed Expert (MoE) dalam penerapan komersial: total parameter menentukan luasnya pengetahuan model, sedangkan parameter aktivasi secara langsung menentukan biaya listrik dan bandwidth memori yang perlu dikeluarkan server setiap kali memanggil antarmuka.
Menekan aktivasi hingga 13B, langsung memisahkan model besar dari pusat komputasi cerdas tingkat atas yang mahal. Kebutuhannya terhadap memori kartu tunggal dan puncak komputasi sangat sederhana. Hasil pengujian menunjukkan bahwa versi Flash dalam menangani tugas sehari-hari sederhana yang besar dan frekuensi tinggi, kecepatan respons dan akurasi mempertahankan tingkat stabil, kemampuan inferensi umum dasar tidak menunjukkan penurunan yang signifikan. Bagi pengembang kecil dan menengah serta perusahaan ekor panjang yang perlu menangani ribuan panggilan API setiap hari, ini adalah alat produktivitas terjangkau yang benar-benar dapat digunakan dan dijalankan.
Logika industri yang lebih dalam adalah, chip komputasi heterogen mainstream domestik saat ini, dalam kinerja absolut kartu tunggal masih dalam masa mengejar. Sistem komputasi yang membawa aktivasi penuh sangat mudah menyentuh dinding memori, menyebabkan efisiensi operasi rendah; tetapi menghadapi versi Flash dengan aktivasi hanya 13B, chip-chip ini justru dapat beroperasi lancar di bawah daya menengah-rendah.
Langkah DeepSeek ini menghidupkan kembali banyak sumber daya komputasi menengah-rendah domestik yang menganggur, menyediakan tempat uji coba yang sangat cocok untuk chip domestik yang sangat membutuhkan skenario penerapan. Logika pembangunan infrastruktur yang inklusif ke bawah ini, jauh lebih sesuai dengan realitas komersial saat ini daripada sekadar menyapu peringkat di berbagai daftar pengujian.
Apakah Chip Domestik Dapat Menerima?
Yang memicu diskusi luas industri dalam rilis ini adalah label penerapan full-stack domestik yang diluncurkannya. Untuk waktu yang lama, ada ketidaksesuaian tertentu antara perusahaan algoritma dan produsen chip domestik: vendor model khawatir ekosistem perangkat keras yang tidak sempurna akan menghambat kemajuan R&D, sementara vendor chip kekurangan model besar paling mutakhir untuk penyesuaian mendalam. Kali ini, kebuntuan secara substantif dipecahkan.
Huawei Computing dengan cepat bersuara, mengonfirmasi bahwa seluruh seri produk Ascend Super Node sepenuhnya mendukung model baru. Dari detail teknis, chip底层 Ascend mengandalkan teknologi kernel fusion dan multi-stream parallel, secara efektif mengurangi biaya komputasi sistem, sehingga menstabilkan kinerja inferensi dalam skenario teks panjang. Cambricon juga dengan cepat menyelesaikan adaptasi Day 0 dan open source kode底层, Haiguang DCU secara bersamaan mengumumkan penutupan loop.
Namun kita perlu membuka表象 kemakmuran ekosistem, memeriksa resistensi nyata yang dihadapi saat menjahit perangkat lunak dan keras di ruang server. Mengambil chip Ascend 950 series sebagai contoh, menurut informasi industri, chip ini memiliki 112GB HBM buatan sendiri, bandwidth 1.4TB/detik, konsumsi daya kartu tunggal mencapai 600 watt. Pada presisi inferensi tertentu (seperti FP4), kinerja kartu tunggalnya telah menunjukkan performa data yang sangat kuat, mencapai 2.87 kali lipat dari Nvidia H20. Namun dalam rentang presisi pelatihan umum FP16 atau FP32 yang lebih tinggi, kesenjangan kinerja antara perangkat keras domestik dan Nvidia masih ada.
Selain itu, yang disebut "adaptasi Day 0", jarak dari operasi bisnis tingkat perusahaan yang tidak rusak, masih perlu melintasi biaya tersembunyi yang dibawa oleh ketidaktransparan rantai pasok. Standar koneksi kecepatan tinggi perangkat keras Super Node sangat tertutup, aliran komponen inti seperti kotak informasi hitam. Hambatan di ujung pembelian ini, tidak diragukan lagi membuat penyebaran dan pemeliharaan sistem komputasi skala besar menjadi lebih kompleks.
Pada saat yang sama, sistem ini saat ini sangat bergantung pada pesanan besar pembelian terpusat dari sedikit lembaga besar domestik. Kekurangan pesanan pasar luar negeri berarti bahwa pertempuran penerobosan komputasi ini hanya dapat berputar dalam siklus internal. Penutupan bisnis tunggal ini membuat efisiensi operasi seluruh sistem kolaborasi perangkat lunak dan keras, sangat perlu mengalami tempering lingkungan bisnis yang lebih beragam.
Kenaikan ketat kapasitas komputasi high-end, langsung menyebabkan DeepSeek secara jujur mengakui dalam siaran pers, bahwa versi Pro ingin mencapai penurunan harga besar, masih perlu menunggu kehadiran massal Super Node pada paruh kedua tahun ini. Model besar dan chip domestik memang telah menyelesaikan gigitan fisik awal, tetapi di bawah kesenjangan teknologi dan kendala rantai pasok, postur berlari dengan luka ini, justru adalah potongan survival paling nyata dari ekosistem komputasi domestik.
Apakah Teknologi Masih Dapat Berjalan Setelah Orang Pergi?
Mundur ke persaingan bisnis nyata, kelahiran DeepSeek-V4 adalah pertahanan strategis yang sangat tepat. Selama setahun terakhir, situasi perusahaan ini selalu berada dalam keadaan tekanan tinggi. Jalur C berkembang menjadi lautan merah, vendor kepala menggunakan sejumlah besar dana untuk penempatan intensif. Data QuestMobile menunjukkan situasi persaingan yang jelas: hingga Maret 2026, Doubao mencapai 345 juta MAU, Qianwen 166 juta, DeepSeek mempertahankan basisnya sendiri dengan 127 juta.
Persaingan lalu lintas eksternal sengit, tim teknologi internal juga menghadapi ujian perpindahan. Kompetisi perburuan di dalam industri sangat panas, personel inti dari beberapa lini bisnis terus mengalir keluar. Menurut riwayat publik dan informasi industri, penulis inti model bahasa besar generasi pertama telah dikonfirmasi bergabung dengan Tencent, kontributor inti V3 pergi ke Xiaomi, peneliti inti R1 bergabung dengan ByteDance, kekuatan inti arah multimodal juga telah mengonfirmasi tujuan baru. Menurut rumor industri, penulis inti arah OCR Wei Haoran juga telah mengundurkan diri.
Perubahan anggota inti R&D pasti akan memicu pemeriksaan ketat terhadap daya dorong R&D-nya: apakah kemampuan inovasi arsitektur底层 perusahaan yang mengandalkan teknologi ini akan terpengaruh?
Pada titik ini, rilis versi preview V4 menjadi respons paling langsung. Ini membuktikan kepada pasar bahwa perusahaan telah membangun satu set pipeline R&D sistematis yang memiliki kemampuan tahan risiko. Bahkan menghadapi penyesuaian struktur personel, logika evolusi teknologinya masih dapat beroperasi dengan presisi. Ketahanan organisasi yang dibangun di atas dasar sistem teknik ini, dengan cepat mendapatkan umpan balik positif di pasar modal.
Baru-baru ini, DeepSeek dilaporkan mencari pendanaan dengan valuasi tidak kurang dari 10 miliar dolar AS, berencana mengumpulkan dana untuk menambah cadangan. Menurut media industri yang mengutip sumber dekat transaksi, rumor pasar bahwa raksasa internet kepala diperkirakan menyuntikkan modal, atau akan mendorong valuasi putaran ini. Jika transaksi ini akhirnya disepakati, akan menulis ulang catatan valuasi arena model besar domestik, melampaui performa sebelumnya Dark Side of the Moon. Pada periode kunci negosiasi pendanaan, mengeluarkan hasil substantif konteks satu juta kata dan adaptasi full-stack domestik, adalah langkah rasional manajemen untuk menstabilkan papan strategis dan menanggapi keraguan eksternal.
Ditulis di akhir
Dalam konteks bisnis teknologi yang sering berganti konsep, tim yang bersedia fokus pada pembangunan infrastruktur底层 selalu langka. Peluncuran DeepSeek-V4, menetapkan nada dasar yang pragmatis dan dingin untuk kompetisi babak kedua model besar.
Menghadapi bottleneck komputasi, mereka tidak memilih untuk memperindah, tetapi melemparkan kondisi pasokan dan permintaan perangkat keras high-end domestik yang sebenarnya kepada pasar; menghadapi kebutuhan penerapan下沉, mereka menggunakan versi Flash dengan aktivasi 13B, menyediakan ruang hidup untuk chip komputasi domestik yang berada dalam masa mengejar; menghadapi pengepungan lalu lintas eksternal dan persaingan talenta, mereka merespons dengan kemampuan pemrosesan teks panjang yang konkret pada tingkat industri.
Kutipan asli "Xunzi" yang dikutip resmi pada hari peluncuran sangat dalam: "Tidak tergoda oleh pujian, tidak takut pada fitnah, bertindak sesuai dengan jalan, dengan teguh memperbaiki diri."
Model dapat open source, tetapi komputasi tidak gratis. Yang diserahkan DeepSeek kali ini, bukan model yang lebih kuat, tetapi solusi bagaimana kemampuan didistribusikan kembali setelah komputasi menjadi kendala. Dalam realitas di mana komputasi masih tidak sempurna, ini mungkin arah evolusi yang lebih mendekati esensi industri.





