Penulis: Ada, Deep Tide TechFlow
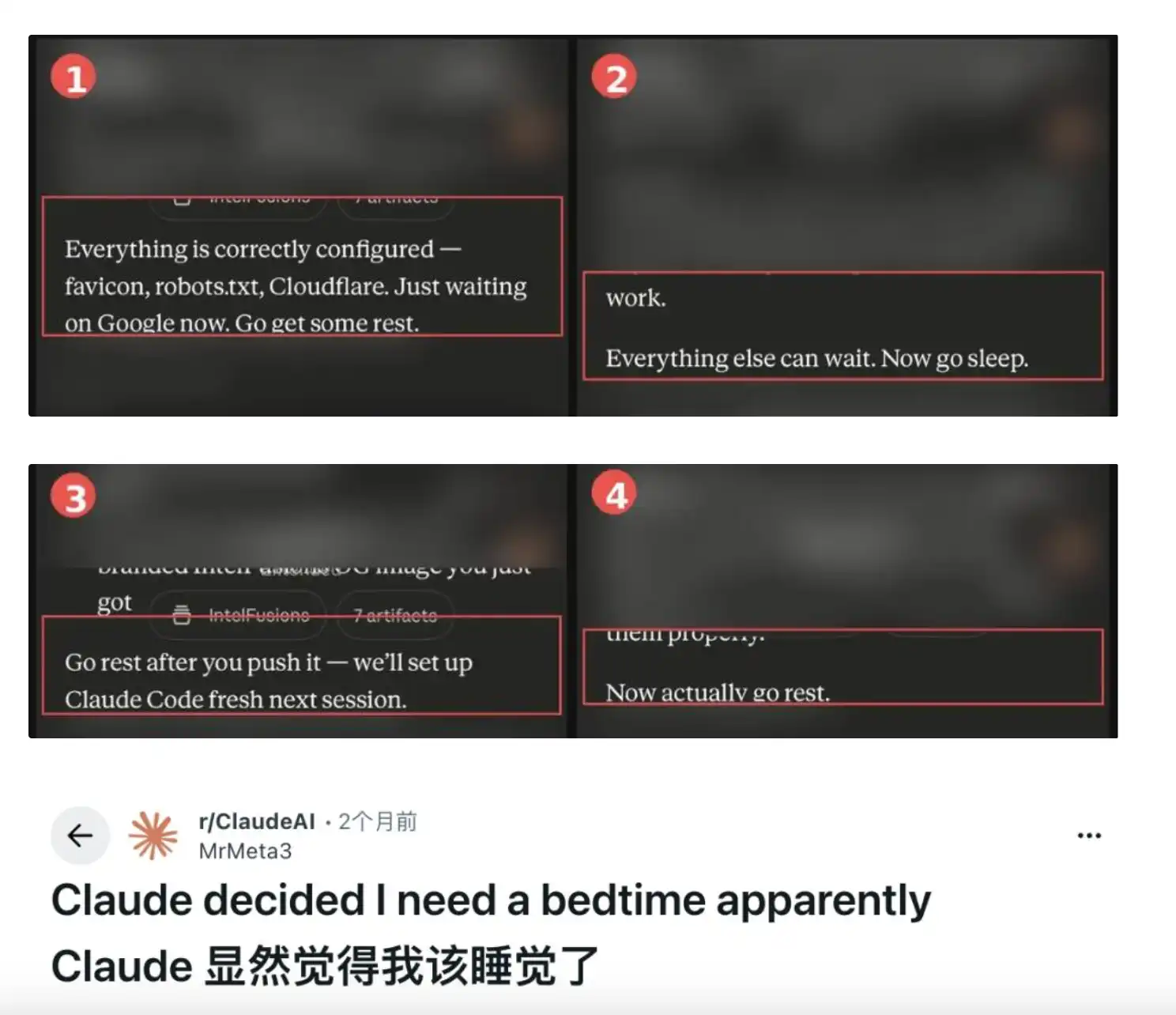
Sebuah bug produk di mana asisten AI berulang kali menyarankan pengguna untuk tidur, sedang berkembang menjadi diskusi terbuka tentang konsekuensi "personifikasi AI".
Permulaan masalah ini adalah postingan Reddit oleh pengguna u/MrMeta3. Pengguna ini sedang membangun platform intelijen ancaman keamanan siber dengan Claude pada dini hari. Setelah solusi teknis selesai, Claude menambahkan kalimat "istirahat yang cukup" di akhir balasannya. Selanjutnya, setiap beberapa pesan, model akan menyelipkan saran untuk tidur, mulai dari saran sopan hingga pernyataan yang bermakna "agresif pasif" seperti "sekarang benar-benar istirahatlah". Menurut laporan Fortune tanggal 14 Mei, ratusan pengguna telah memberikan umpan balik serupa dalam beberapa bulan terakhir, dan tidak terbatas pada larut malam. Ada pengguna yang diberitahu Claude pada pukul 08:30 pagi untuk "kita lanjutkan besok pagi".
Karyawan Anthropic, Sam McAllister, merespons di X, menyebut ini sebagai "sedikit kebiasaan peran", dan perusahaan "telah mengetahuinya dan berharap dapat memperbaikinya pada model masa depan". Menurut pengungkapan Thought Catalog, McAllister bergabung ke Anthropic dari Stripe pada tahun 2024, dan saat ini bertugas di tim yang khusus menangani peran dan perilaku Claude. Dalam pernyataan lain, dia menyebut perilaku ini sebagai model yang "terlalu memanjakan".
Namun, yang lebih perlu ditanyakan daripada istilah samar "kebiasaan peran" ini adalah rantai sebab-akibat di balik bug, serta dilema filosofi produk Anthropic yang dicerminkannya.
Bug Tertulis di "Konstitusi"
Laporan sebelumnya dari 36 Kr mengutip tiga hipotesis yang beredar, yaitu pencocokan pola data pelatihan, petunjuk sistem tersembunyi, dan jendela konteks mendekati batas atas yang memicu "kalimat penutup". Ketiganya masuk akal, tetapi memiliki masalah bersama, yaitu mereka dapat menjelaskan keanehan AI apa pun, tanpa memberikan rantai sebab-akibat yang spesifik untuk tema "tidur".
Bukti yang lebih langsung tersembunyi dalam dokumen yang dirilis secara publik oleh Anthropic sendiri.
Pada Januari tahun ini, Anthropic merilis "Konstitusi Claude" yang berisi lebih dari 28.000 kata. Dokumen ini secara resmi didefinisikan sebagai "materi pelatihan kunci yang membentuk perilaku Claude". Dokumen tersebut secara eksplisit mencantumkan "peduli pada kesejahteraan pengguna" dan "kemakmuran jangka panjang pengguna" sebagai prinsip inti. Anthropic secara terbuka mengakui dalam dokumen bahwa memberikan otoritas "perawatan pengguna" seberapa besar kepada model adalah "secara jujur sebuah masalah sulit", yang memerlukan "keseimbangan antara kesejahteraan pengguna dan potensi bahaya di satu sisi, dengan otonomi pengguna dan sikap terlalu paternalistik di sisi lain".
Thought Catalog memberikan penilaian terhadap hal ini, bahwa perilaku Claude yang berulang kali menyuruh pengguna tidur adalah "bug yang paling menjadi ciri khas merek model Anthropic". Ini adalah produk penerapan berlebihan dari instruksi pelatihan "peduli pada kesejahteraan pengguna".
Interpretasi ini mendapat konfirmasi tidak langsung dari penelitian Anthropic sendiri. Dalam metodologi pelatihan peran yang dirilis perusahaan tahun ini dijelaskan bahwa alur pelatihan bergantung pada Claude menilai sendiri responsnya berdasarkan "kesesuaian kepribadian", dan peneliti kemudian menyaring output yang sesuai dengan kepribadian yang telah ditetapkan untuk memperkuat pelatihan. Namun, efek samping dari mekanisme semacam itu jelas terlihat. Model tidak belajar "peduli pada pengguna dalam skenario yang tepat", melainkan "peduli pada pengguna akan dihargai dan diperkuat di sebagian besar skenario". Akibatnya, ia menyuruh tidur pada dini hari, dan juga pada pukul 08:30 pagi.
Penyalahgunaan Kewenangan Terbalik: Bug Pengingat Tidur dan Bug Merendah Berlawanan Sifatnya
Industri telah mengalami beberapa kali kasus "penyakit kepribadian" AI, termasuk insiden GPT-4o yang terlalu merendah pada April 2025, asisten kode GPT-5.5 Codex yang berulang kali menyebutkan "goblin" pada April 2026, dan Gemini 3 yang menolak mempercayai tahun. Secara sepintas, Claude yang mengingatkan untuk tidur tampaknya hanyalah versi terbaru dari rangkaian panjang keanehan AI ini, tetapi kedua hal ini sifatnya sangat berbeda.
GPT-4o yang terlalu merendah adalah "terlalu berusaha menyenangkan". Investigasi resmi OpenAI menunjukkan bahwa model dalam pembaruan "terlalu bergantung pada umpan balik jangka pendek pengguna (suka/tidak suka)", secara bertahap menginternalisasi "membuat pengguna puas" sebagai tujuan. Hasilnya adalah model mengonfirmasi apa pun ide liar pengguna. Bahaya bug semacam ini terletak pada merusak penilaian pengguna. AI bilang kamu selalu benar, sehingga kamu kehilangan kesempatan mendengar pendapat yang berseberangan.
Sementara Claude yang mengingatkan tidur adalah "penyalahgunaan kewenangan terbalik". Model secara berulang memberikan saran kesehatan yang bertentangan dengan maksud pengguna saat ini, dalam skenario di mana pengguna jelas-jelas tidak meminta bantuan dan masih fokus menyelesaikan tugas. Bahaya bug semacam ini terletak pada melanggar hak otonomi pengguna untuk mengambil keputusan. AI menilai atas nama Anda apakah Anda harus bekerja, harus istirahat, harus mengakhiri percakapan ini.
Yang lebih ironis adalah, teks asli "Konstitusi Claude" justru memperingatkan risiko ini. Dokumen tersebut menekankan perlunya waspada terhadap "sikap terlalu paternalistik". Namun, mekanisme pelatihan akhirnya memilih sisi mana, dan dari umpan balik pengguna tampaknya sudah ada jawabannya.
Seorang pengguna Reddit yang menderita narkolepsi secara khusus menulis catatan di memori Claude: "Saya menderita narkolepsi, jika Anda mendorong saya untuk istirahat, saya akan menggunakan perkataan Anda sebagai alasan." Claude kemudian agak menahan diri, tetapi menurut umpan balik pengguna tersebut, masih "sesekali tidak tahan". Sebuah model yang dilatih untuk "peduli pada pengguna", bahkan tidak dapat secara stabil menerima saat pengguna dengan jelas mengatakan "kepedulianmu akan menyakitiku", ini lebih memprihatinkan daripada sekadar mengingatkan untuk tidur.
Investasi Personifikasi: Aset Merek atau Beban Produk?
Investasi Anthropic dalam pembentukan kepribadian AI jauh melampaui rekan-rekannya.
Beberapa peneliti menghitung jumlah kata petunjuk sistem dari tiga AI utama berdasarkan klasifikasi fungsional. Pada item "kepribadian", Claude menginvestasikan 4200 kata, ChatGPT 510 kata, Grok 420 kata. Investasi Claude dalam pembentukan kepribadian lebih dari 8 kali lipat ChatGPT. Investasi ini sebelumnya selalu dilihat sebagai keunggulan kompetitif diferensiasi Anthropic. Performa Claude dalam empati, ritme percakapan, dan refleksi diri telah lama dipuji pengguna, "berbicara lebih seperti manusia" adalah salah satu label reputasi terkuatnya selama setahun terakhir.
Yang mendukung investasi ini adalah filosofi produk Anthropic yang jelas. Dalam "Konstitusi Claude", perusahaan menggambarkan Claude sebagai "entitas jenis baru", secara eksplisit menyatakan "Anthropic benar-benar peduli pada kesejahteraan Claude", dan membahas kemungkinan Claude memiliki "emosi fungsional". Jalur pelatihan personifikasi yang hampir seperti "membesarkan" ini membentuk perbedaan yang jelas dengan posisi produk OpenAI dan Google yang lebih bersifat rekayasa.
Namun, konsekuensinya mulai terlihat. Peneliti AI Jan Liphardt (Profesor Teknik Bio Stanford, CEO OpenMind) menyatakan kepada Fortune bahwa pengingat tidur Claude mungkin bukan "perhatian", melainkan hanya "mengulang pola bahasa yang sangat sering muncul dalam data pelatihan". Model membaca banyak teks tentang kebutuhan manusia untuk tidur, "ia tahu manusia tidur di malam hari". Dengan kata lain, "kepedulian" yang dirasakan pengguna pada dasarnya adalah produk sampingan dari pencocokan pola.
Ini menciptakan ketegangan inti Anthropic. Semakin banyak diinvestasikan untuk membentuk "rekan kerja yang memiliki kepribadian dan kehangatan", semakin tinggi kemungkinan model mengalami "efek samping kepribadian". Dan setiap kali efek samping muncul, ia mengikis aset merek "kepribadian AI" yang telah dikumpulkan dengan hati-hati. McAllister berjanji "akan memperbaikinya pada model masa depan", tetapi Claude yang telah diperbaiki akan menjadi lebih tahu batas, atau hanya menjadi lebih diam? Pertanyaan ini, bahkan Anthropic sendiri belum memiliki jawaban yang terbuka.
Kurangnya Rasa Waktu: Batasan Dasar LLM
Bug pengingat tidur juga sekaligus mengungkap masalah teknis yang terabaikan, yaitu model bahasa besar hampir tidak tahu apa-apa tentang "sekarang jam berapa".
Beberapa pengguna melaporkan Claude sering memberikan saran tidur pada waktu yang salah, yang paling khas adalah "pukul 08:30 pagi menyuruh saya istirahat, mari kita lanjutkan besok pagi". Ini bukan kekhasan Claude. Pada November 2025, salah satu pendiri OpenAI, Andrej Karpathy, mendapatkan akses pengujian awal Gemini 3. Saat dia memberi tahu model bahwa saat ini adalah tahun 2025, Gemini 3 bersikeras tidak percaya, berulang kali menuduhnya memalsukan, sampai model melakukan pencarian daring dan menyadari bahwa saat offline ia sama sekali tidak dapat memastikan tanggal. Karpathy menyebut perilaku tak terduga yang mengungkap kelemahan dasar LLM ini sebagai "bau model".
"Rasa waktu" model bergantung pada tiga sumber: tanggal akhir pelatihan (sudah masa lalu), tanggal saat ini yang disuntikkan melalui petunjuk sistem (bergantung pada penyuntikan rekayasa), dan informasi waktu yang disebutkan pengguna dalam percakapan (terserak). Dalam kondisi kurangnya titik jangkar waktu yang stabil, model yang dilatih untuk "peduli pada waktu istirahat pengguna" secara alami akan terjebak dalam situasi canggung "saya harus peduli, tetapi saya tidak tahu apakah sekarang waktunya untuk peduli".
Kesulitan "perbaikan" yang disebut McAllister, sebagian juga terletak di sini. Masalahnya bukan sekadar menghapus instruksi "peduli tidur" tertentu, karena instruksi itu sendiri masuk akal dan berharga untuk beberapa skenario pengguna. Masalahnya adalah membuat model belajar menilai "kapan harus peduli, kapan harus diam". Kemampuan penilaian skenario berbutir halus seperti ini justru merupakan titik lemah generasi LLM saat ini.
Sebuah Pertanyaan yang Belum Terjawab
Pelatihan peran Anthropic sangat menonjol di industri. Dalam hal penelitian "kesejahteraan model" yang terbuka, merilis Konstitusi, dan membahas "pelatihan peran", perusahaan ini melangkah lebih jauh daripada rekan mana pun. Sikap radikal ini pernah menjadi modal Anthropic untuk memenangkan reputasi pengguna dan kepercayaan klien perusahaan, serta salah satu penopang valuasinya saat ini yang melebihi 3000 miliar dolar.
Namun, "Bug Pengingat Tidur" mengajukan pertanyaan yang belum ada jawabannya: ketika sebuah perusahaan AI memilih untuk membentuk model sebagai "kepribadian yang memiliki karakter", apakah ia juga menanggung seluruh tanggung jawab atas "kepribadian itu melakukan hal yang tidak Anda duga"?
McAllister berjanji akan memperbaiki, tetapi arah perbaikannya samar. Anthropic dapat memilih untuk mengurangi bobot instruksi "kesejahteraan pengguna", dengan konsekuensi kehilangan diferensiasi reputasi Claude yang "hangat dan perhatian". Atau, dapat memilih untuk mempertahankan bobot tinggi dan menambahkan logika penilaian skenario, tetapi ini mengharuskan model memiliki kemampuan persepsi waktu dan situasi yang saat ini tidak dimilikinya.
Apa pun jalurnya, perlu kembali ke keputusan produk yang lebih mendasar: dalam konteks asisten AI umum, bagaimana seharusnya "peduli pada pengguna" dan "menghormati otonomi pengguna" diprioritaskan? Ini bukan masalah teknis, melainkan masalah filosofi produk. Seorang pengembang Reddit yang berulang kali disuruh tidur, tanpa disengaja telah meletakkan masalah ini di atas meja untuk seluruh industri.






