Penulis: Jumat, Deep Wave TechFlow
Anthropic baru saja meluncurkan nilai akademik yang di atas kertas sempurna.
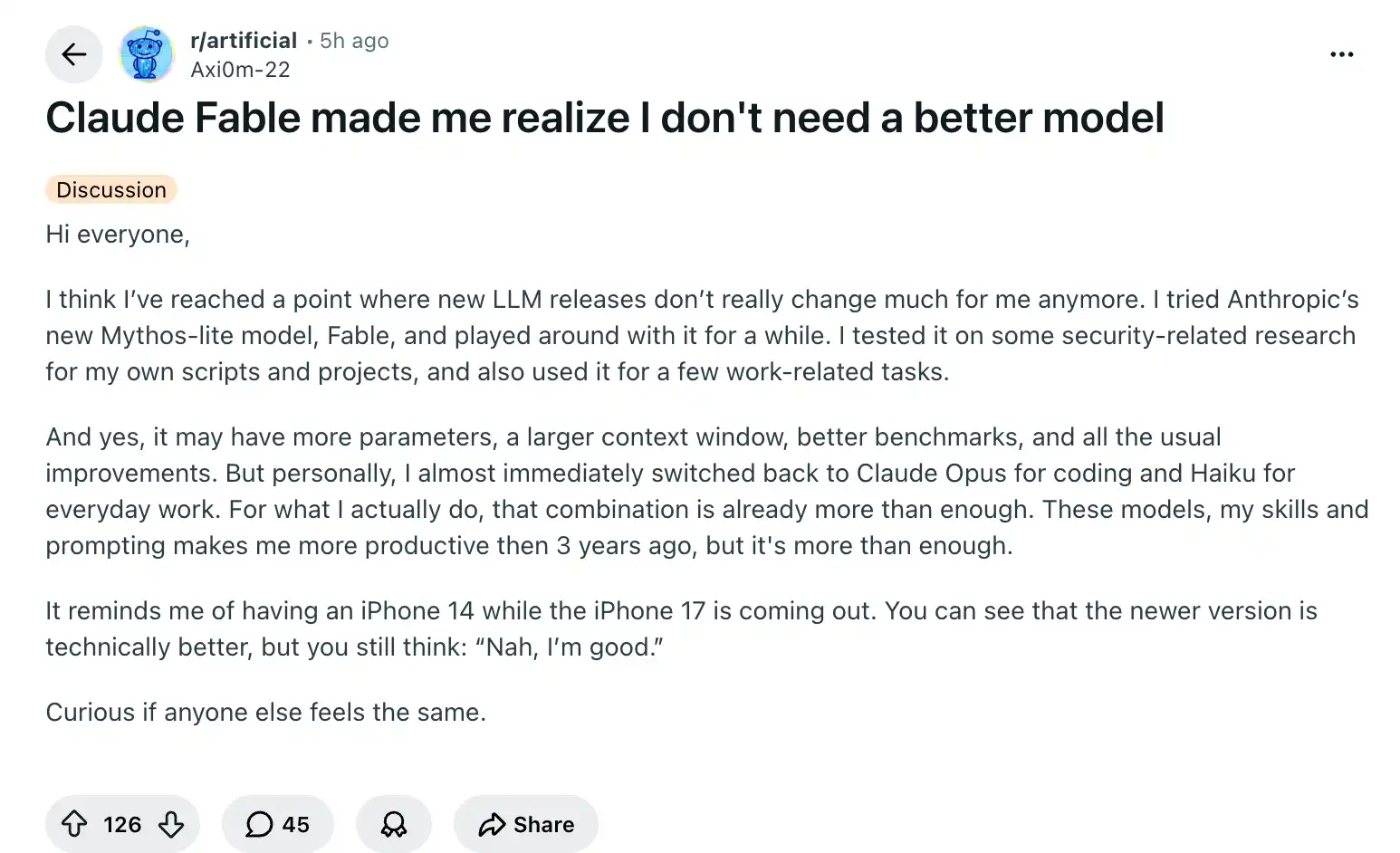
Claude Fable 5 yang dirilis pada 9 Juni adalah model tingkat *Mythos* pertama perusahaan yang terbuka untuk publik, mencapai skor 80.3% pada tolok ukur tugas rekayasa perangkat lunak nyata SWE-Bench Pro, unggul sekitar 11 poin persentase dari flagship generasi sebelumnya sendiri Opus 4.8, dan unggul lebih dari 20 poin persentase dari GPT-5.5.
Namun reaksi pengguna menuangkan air dingin.
Tiga hari setelah rilis, sebuah postingan populer di subreddit r/artificial (kunjungan mingguan 305 ribu) berjudul: "Claude Fable Membuat Saya Sadar, Saya Tidak Perlu Model yang Lebih Baik Lagi." Poster Axi0m-22 berkata, dia menggunakan Fable untuk beberapa waktu dalam penelitian keamanan dan pekerjaan sehari-hari, kemudian hampir segera beralih kembali ke Opus untuk menulis kode dan Haiku untuk pekerjaan sampingan. Dia membuat perumpamaan: Ini seperti memegang iPhone 14 melihat iPhone 17 diluncurkan, "Anda tahu yang baru lebih baik, tetapi yang Anda pikirkan: sudahlah, yang saya punya ini sudah cukup baik."
Area High-Vote Dikuasai "Kelompok Cukup Cukup": Kelelahan Estetika Model Menjadi Sentimen Utama
Komentar peringkat pertama mendapat 42 suka: "Selain konteks jendela yang lebih besar, saya sudah tidak merasa perlu model yang lebih kuat sejak Opus 4.5."
Pernyataan pengguna lain hyprlab mendapat 13 suka: "Beralih ke model yang lebih boros membakar token, saya tidak melihat manfaatnya untuk alur kerja saya, mode intensitas tinggi Opus 4.8 sudah cukup nyaman."
Di balik pernyataan semacam ini ada buku biaya yang sama.
Harga API Fable 5 adalah $10 per juta token input, mendekati dua kali lipat Opus 4.8. Pengguna siromega37 berkata blak-blakan: "Konsumsi token lebih tinggi, tetapi tidak ada ROI (Return on Investment). Saya rasa kita sedang melihat dataran tinggi, gelembung akhirnya akan pecah."
Pengguna hobopwnzor memberikan interpretasi yang lebih sistematis: "Kita sudah berada di puncak kurva-S untuk sementara waktu. Kemajuan terkini terutama berasal dari pemanggilan alat dan rekayasa periferal, bukan kemampuan model itu sendiri."
Pagar Pengaman Jadi Keluhan Terbesar: "90% Penggunaan Langsung Ditolak"
Jika "cukup" masih hanya emosi, maka keluhan tentang pagar pengaman adalah masalah produk yang konkret.
Menurut penjelasan resmi Anthropic, Fable 5 berbagi model dasar yang sama dengan Mythos 5 yang hanya dibuka untuk sedikit lembaga, perbedaannya adalah Fable dipasangi pengklasifikasi keamanan: permintaan yang melibatkan bidang berisiko tinggi seperti keamanan siber akan diblokir, dan dialihkan untuk dijawab oleh Opus 4.8. Resmi menyatakan mekanisme ini dikalibrasi agak konservatif, rata-rata terpicu dalam kurang dari 5% sesi, dan dapat memengaruhi permintaan yang tidak berbahaya.
Di bawah postingan Reddit ini, tingkat pemicu yang dirasakan jelas jauh lebih tinggi dari 5%. Pengguna jradoff yang mendapat 17 suka berkata, dia meminta Fable memeriksa keamanan kodenya sendiri, hasilnya "hampir setiap kali menyebutkan hal terkait keamanan, pada dasarnya ditolak untuk diproses", lalu dialihkan ke Opus. Komentar lain dengan 12 suka bahkan lebih tidak sopan: "90% hal yang ingin Anda lakukan dengannya akan ditolak, sama saja tidak berguna."
Keluhan pengguna berbayar lebih besar. Pengguna kaitava yang berlangganan paket $200 menulis: "Saya membayar biaya penggunaan dua kali lipat, ingin memintanya melakukan satu kali tinjauan keamanan, malah diturunkan ke Opus. Sekarang saya tidak suka semuanya tentangnya, tinggal menunggu OpenAI menyusul."
Untuk produk flagship yang mengusung lompatan kemampuan, "pengorbanan kegunaan demi keamanan" sedang menjadi variabel inti bagi pengguna untuk memutuskan apakah akan membayar atau tidak.
Suara Oposisi: Pengalaman Pengguna Tugas Berat Adalah "Malam dan Siang"
Di bawah postingan panas ini bukan tidak ada penentang, dan profil pihak oposisi cukup jelas: semakin berat tugasnya, semakin tinggi penilaiannya.
Komentar pengguna Phylaras mendapat 15 suka: "Fable membuat perbedaan substantif bagi saya. Dalam tugas kompleks yang membutuhkan jendela konteks sangat besar, ia menemukan kesalahan yang sebelumnya tidak terdeteksi." Seorang pengguna yang mengaku melakukan simulasi fisika energi tinggi menyatakan, satu model simulasi saja mudahnya 8000 hingga 10 ribu baris kode, ratusan model berinteraksi, "memiliki model yang dapat bekerja secara independen dan terus menerus, memahami detail lingkungan, bagi saya sangat layak dinantikan".
Sanggahan paling sengit datang dari pengguna Navetz: "Jujur saja, orang yang pernah menggunakan model ini akan menganggap postingan seperti ini omong kosong. Bagi saya ia cerdas seperti orang yang berbeda, saya terus-menerus menggunakannya. Saya jelaskan kepada teman non-teknis: ini setara dengan langsung mengganti pemain mahasiswa dengan starter NBA."
Ada juga yang memberikan penggunaan kompromi. Pengguna ready-eddy menyarankan menggunakan Fable sebagai "perencana dan perbaiki", bukan "pembangun" sehari-hari, kecuali tidak peduli membakar uang. Komentar lain merangkumnya lebih seperti manual penggunaan: menggunakan Fable untuk menghitung tabel adalah memilih model yang salah, menggunakan Haiku untuk menjalankan 16 tugas kompleks agen cerdas juga memilih model yang salah, "tidak ada model yang buruk secara alami, hanya model yang digunakan dalam konteks yang salah".
Setelah Pencapaian Skor dan Pengalaman Terlepas, Akankah AI Publik Lebih Kuat Lagi?
Komentar paling menarik dalam perdebatan ini mengalihkan topik dari produk ke struktur industri.
Pengguna KedMcJenna mengajukan "teori pembekuan AI publik": model yang dapat diakses orang biasa mungkin akan selamanya berhenti di sekitar tingkat saat ini, sementara elit perusahaan dan pemerintah akan terus mendapatkan model privat yang lebih kuat, "setidaknya yang kita tahu ada Mythos, sangat mungkin ada model yang lebih kuat, yang tidak akan pernah kita dengar".
Komentar ini mengarah pada fakta: Mythos 5 memang tidak terbuka untuk publik, saat ini hanya tersedia melalui program Project Glasswing untuk lembaga pertahanan jaringan dan perusahaan infrastruktur kunci.
Melihat pencapaian skor dan sentimen bersama-sama, kesimpulannya tidak bertentangan.
Tes tolok ukur mengukur batas atas kemampuan, sementara area high-vote Reddit mencerminkan batas atas kebutuhan sehari-hari. Ketika tugas kebanyakan pengguna sudah terpenuhi pada era Opus 4.6, model yang lebih kuat hanya dapat membuktikan dirinya dalam skenario ekstrem seperti simulasi fisika, konteks superpanjang. Produsen model tidak lagi menghadapi masalah "bisakah dilakukan", tetapi masalah "siapa yang butuh, mau bayar berapa, bisa mentoleransi berapa banyak gesekan keamanan".
Tiga hari setelah rilis, Fable 5 mendapatkan dua laporan nilai yang sama sekali berbeda di papan peringkat skor dan medan opini publik. Mana yang lebih mendekati kebenaran, tergantung pada kecepatan Anthropic menyesuaikan pengklasifikasi keamanan selanjutnya, dan voting dompet pengguna berat.






