Menerobos paradigma pra-latihan model besar tradisional, tim alumni Tsinghua '00 Wang Guan kembali menampilkan karya terbaru:
Mereka memanfaatkan Model Rekursif Berlapis (HRM) untuk menggantikan Transformer standar, dan mengusulkan pra-latihan efisien HRM-Text yang melampaui Scaling.

Tautan makalah:https://arxiv.org/abs/2605.20613
Dengan hanya menggunakan token pelatihan sekitar 100-900 kali lebih sedikit dan perkiraan daya komputasi 96-432 kali lebih sedikit daripada model baseline standar, HRM-Text tetap menunjukkan performa yang setara dengan model sumber terbuka berparameter 2B hingga 7B.
Secara bersamaan, dengan parameter 1B, token unik 40B, dan biaya pelatihan sekitar $1500, HRM-Text mencapai hasil berikut dalam tes tolok ukur utama: MMLU 60.7%, ARC-C 81.9%, DROP 82.2%, GSM8K 84.5%, MATH 56.2%.
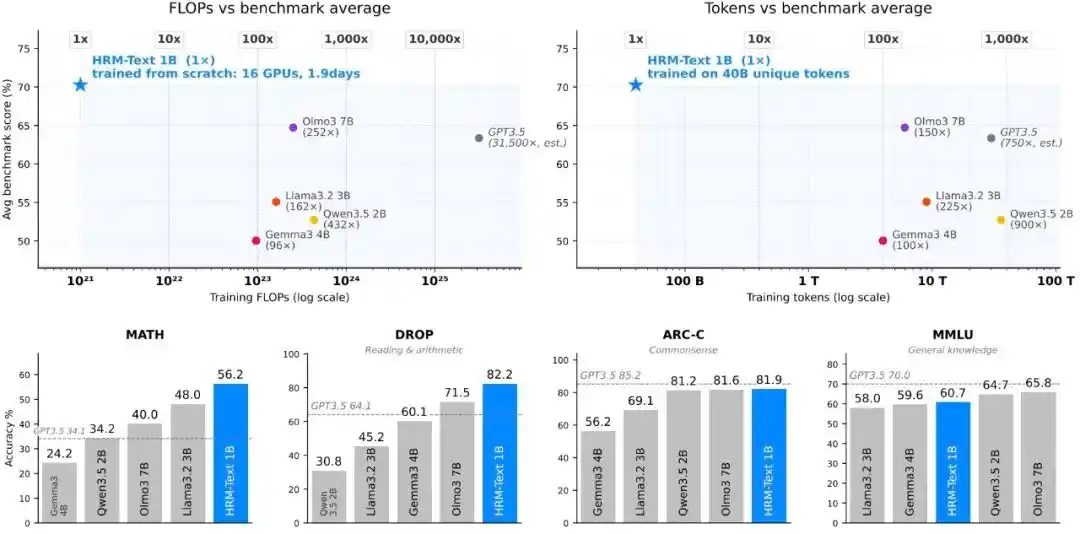
Gambar|Efisiensi pra-latihan.
Berdasarkan hal ini, mereka secara eksplisit menyatakan: Priors struktural dan target pelatihan yang tepat sasaran dapat secara signifikan menurunkan ambang batas pra-latihan. Skema pelatihan seperti ini membuat pelatihan model dasar dari nol menjadi layak.
Bagaimana HRM-Text Dirancang?
Pra-latihan Model Bahasa Besar (LLM), semakin bergantung pada segelintir lembaga yang memiliki sumber daya komputasi dan data yang melimpah. Melatih model dasar yang kompetitif sering kali membutuhkan triliunan token, ribuan GPU, bahkan investasi komputasi jutaan dolar.
Namun, pola pelatihan saat ini tidak efisien, sebagian besar komputasi dihabiskan pada token yang tidak relevan seperti prompt, padding format, dan noise halaman web, sehingga banyak daya komputasi pelatihan tidak melayani inferensi secara langsung.
Dalam karya ini, tim peneliti mendesain ulang arsitektur dan target pelatihan, membuat pra-latihan HRM-Text relatif lebih efisien.
Arsitektur: Mengadopsi Model Rekursif Berlapis dengan dua skala waktu, memecah komputasi menjadi modul H lambat dan modul L cepat. Transformer standar hanya melakukan satu kali forward propagation untuk setiap token, sedangkan HRM akan melakukan pembaruan rekursif multi-putaran pada token yang sama. Modul H dan L masing-masing hanya mencakup setengah dari parameter inti rekursif, total komputasi kira-kira setara dengan melakukan 4 kali ekspansi rekursif pada parameter yang sama, meningkatkan kedalaman komputasi tanpa menambah jumlah parameter.
Target Pelatihan: Tidak lagi menggunakan pra-latihan otoregresif teks lengkap standar, melainkan melatih langsung pada pasangan instruksi-jawaban, hanya menghitung loss pada bagian jawaban, dan dikombinasikan dengan mask PrefixLM, sehingga bagian instruksi memperhatikan secara dua arah, dan bagian jawaban dihasilkan dengan mask kausal.
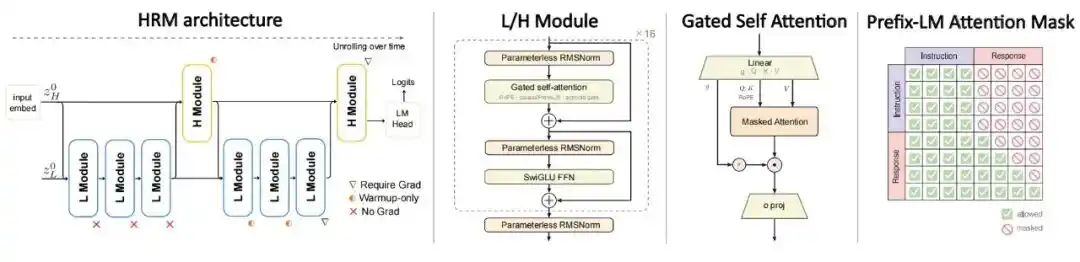
Gambar|Arsitektur HRM-Text.
Untuk meningkatkan stabilitas pelatihan rekursif, tim peneliti memperkenalkan MagicNorm dan Warmup Deep Credit Assignment.
MagicNorm adalah strategi normalisasi hibrida, memanfaatkan asimetri kedalaman komputasi maju dan mundur di bawah Backpropagation Through Time Terpotong (Truncated BPTT), menggunakan PreNorm di dalam modul, dan menambahkan normalisasi ekstra pada pintu keluar modul, sehingga meningkatkan stabilitas pelatihan rekursif dalam.
Warmup Deep Credit Assignment pada awal pelatihan hanya melakukan backpropagation gradient untuk 2 langkah rekursif terakhir, kemudian diperluas secara linear hingga 5 langkah terakhir. Mekanisme pelatihan ini memungkinkan model konvergen dengan stabil pada jalur kredit yang lebih pendek, lalu secara bertahap memperkenalkan dependensi yang lebih panjang.
Bagaimana Hasilnya?
Hasil eksperimen menunjukkan bahwa HRM-Text menunjukkan keunggulan yang jelas dalam efisiensi arsitektur, target pelatihan, dan performa keseluruhan.
1. Dalam daya komputasi pelatihan tetap, apakah arsitektur rekursif lebih efektif
Hasil menunjukkan, dalam kondisi FLOPs yang diselaraskan, HRM 1B mengungguli Transformer 1B, Transformer 3B, Looped Transformer 1B, dan RINS 1B di sebagian besar tolok ukur; perbandingan dengan TRM juga menunjukkan bahwa pelatihan HRM lebih stabil.
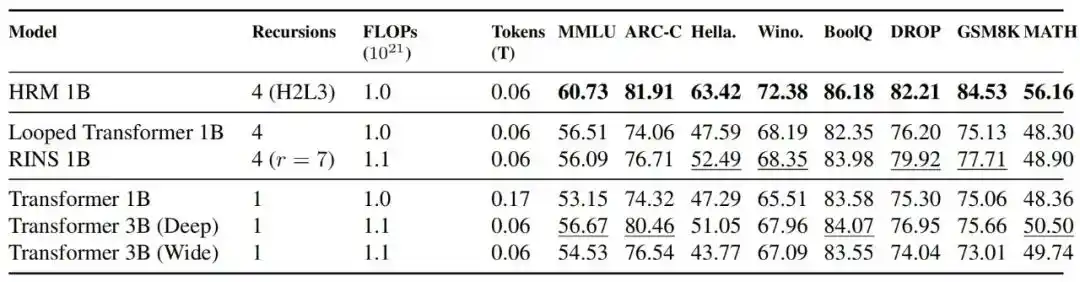
Gambar|Perbandingan performa dan stabilitas dengan model Transformer. HRM mempertahankan dinamika pelatihan yang stabil di semua skala, sementara model Transformer menunjukkan ketidakstabilan serius pada skala 1 miliar parameter. Selain itu, pada skala 0.6B, HRM hanya membutuhkan komputasi 2 kali lebih sedikit daripada model Transformer untuk mencapai performa yang kompetitif di sebagian besar tolok ukur.
2. Apakah target penyelesaian tugas dan PrefixLM membantu
Eksperimen ablasi menunjukkan, dalam kondisi FLOPs yang diselaraskan, MMLU Transformer 1B meningkat dari 40.55 (otoregresif standar) menjadi 47.72 setelah memperkenalkan target penyelesaian tugas, kemudian 53.15 setelah menambahkan PrefixLM, dan mencapai 60.73 setelah mengganti arsitektur menjadi HRM.
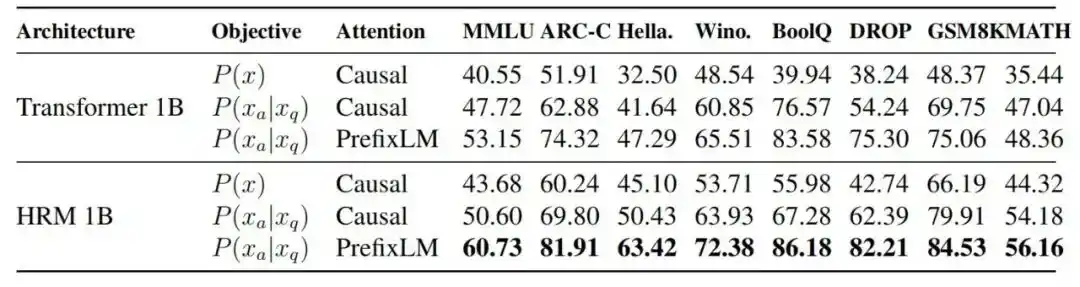
Gambar|Perbandingan performa antara arsitektur model dan target pelatihan yang berbeda
3. Seberapa efisien HRM-Text dibandingkan dengan model terbuka kontemporer
HRM-Text 1B mencapai 60.7, 81.9, 82.2, 84.5, dan 56.2 pada MMLU, ARC-C, DROP, GSM8K, dan MATH. Dibandingkan dengan model terbuka yang umumnya memiliki anggaran pelatihan lebih besar, hanya dengan 40 miliar token unik dan 1B parameter, HRM-Text memasuki rentang performa model sumber terbuka 2B hingga 7B; token yang dibutuhkan untuk pelatihan paling sedikit 900 kali lebih sedikit, dan biaya komputasi paling sedikit 432 kali lebih sedikit.
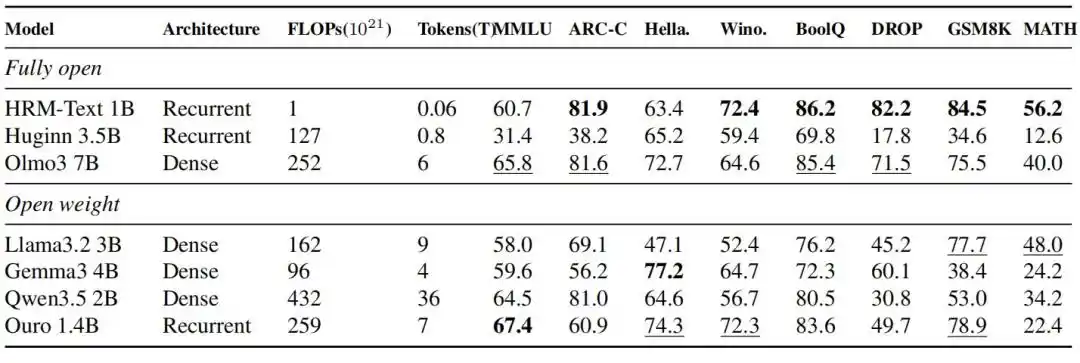
Gambar|Hasil evaluasi HRM-Text 1B dengan model sepenuhnya sumber terbuka dan model dengan bobot terbuka sezaman
4. Apakah struktur rekursif membawa kedalaman efektif yang lebih besar
Hasil menunjukkan bahwa Transformer standar dan Looped Transformer cenderung stabil di lapisan yang lebih dangkal, sedangkan HRM tetap menunjukkan perubahan representasi antar-blok yang lebih jelas, similaritas kosinus yang lebih rendah, dan nilai KL logit lens yang lebih tinggi di lapisan yang lebih dalam.
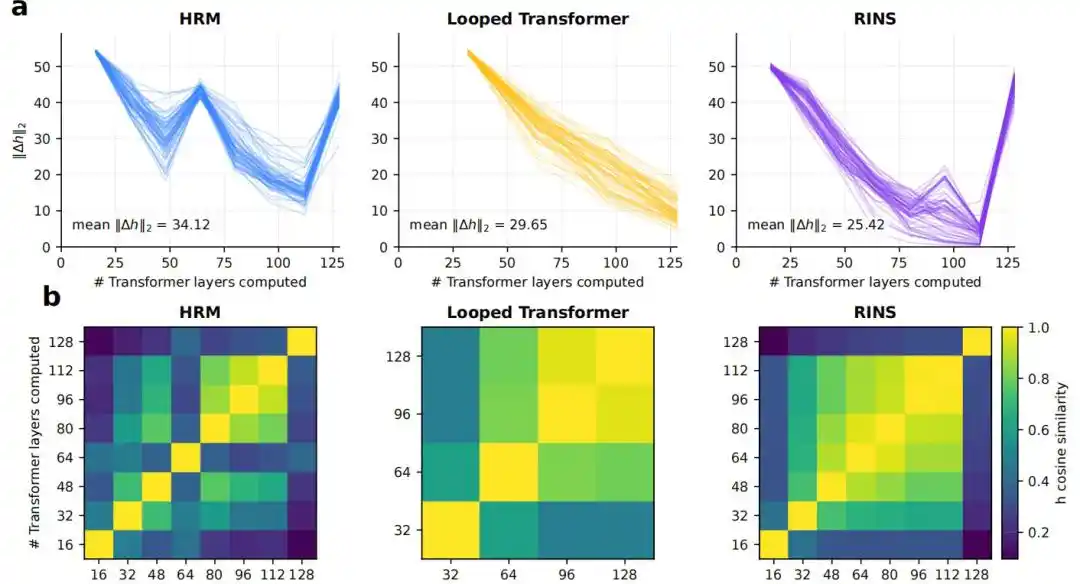
Gambar|Analisis kedalaman efektif.
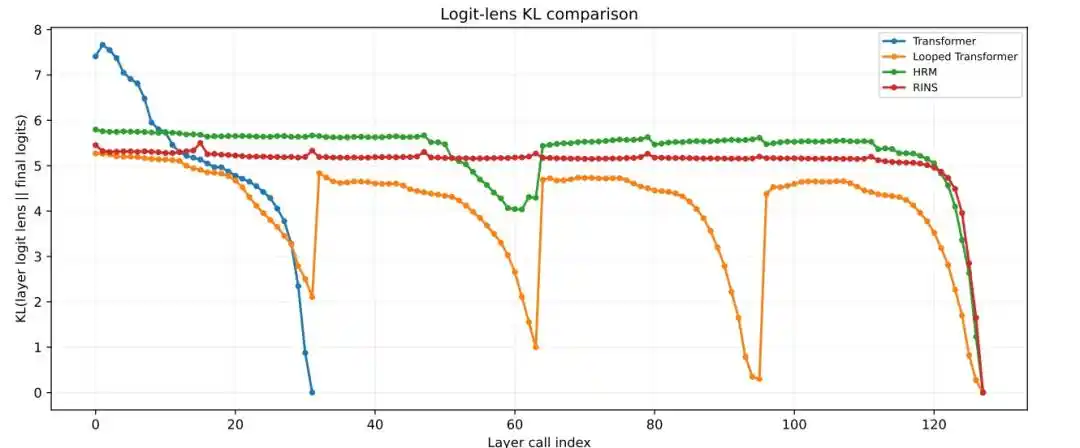
Gambar|Analisis Logit Lens KL per lapisan.
Kekurangan dan Arah Masa Depan
Meskipun HRM-Text menunjukkan performa kuat dalam tugas-tugas intensif penalaran, metode ini masih memiliki keterbatasan, dan mengusulkan arah penelitian di masa depan.
1. Menuju pemisahan "Pengetahuan" dan "Penalaran"
Saat ini, cakupan pengetahuan faktual yang lebih luas masih lebih bergantung pada skala model dan keluasan data. HRM-Text hanya dilatih pada 40 miliar token unik, dan sumber pengetahuan eksplisit hanya menjadi bagian dari data campuran yang diformat tugas. Di masa depan, peneliti perlu mendesain secara terpisah inti penalaran yang kompak dengan penyimpanan fakta eksternal, menyerahkan keluasan pengetahuan kepada korpus terpilih, modul augmentasi retrieval, atau memori yang dapat dipelajari.
2. Waktu Komputasi Adaptif
Penjadwalan rekursif HRM-Text membawa kedalaman serial efektif yang lebih besar, tetapi ini juga berarti model perlu mengeksekusi jumlah langkah rekursif tetap selama inferensi. Di masa depan, arah yang layak dieksplorasi adalah memperkenalkan mekanisme waktu komputasi adaptif, sehingga sampel sederhana dapat menghentikan komputasi lebih awal, dan mengalokasikan anggaran rekursif penuh untuk sampel sulit, mengurangi biaya inferensi.
3. Ruang lingkup validasi penskalaan yang ada masih terbatas
Eksperimen penskalaan saat ini hanya mencakup grup kontrol Transformer 3B dan HRM-Text 1B. Tim peneliti menyatakan, apakah keunggulan efisiensi serupa masih dapat dipertahankan pada skala model yang lebih besar masih perlu diverifikasi lebih lanjut oleh pekerjaan selanjutnya.
4. PrefixLM dan Kerangka Kerja Inferensi
Saat ini, PrefixLM masih menghadapi batasan implementasi teknikal tertentu dalam penyebaran praktis. Meskipun dapat berjalan pada kerangka kerja inferensi teks standar seperti vLLM, hal ini memerlukan dukungan kerangka kerja terhadap mask perhatian kustom pada tahap prefill. Jika diperluas ke skenario percakapan multi-putaran, perlu mendesain mekanisme KV-cache lebih lanjut, yang memastikan segmen pengguna tetap terlihat dua arah secara internal, dan juga memastikan proses generasi di sisi asisten terus mengikuti batasan kausal.
Untuk detail teknis lebih lanjut, lihat makalah aslinya.
Artikel ini berasal dari akun WeChat publik "学术头条" (ID:SciTouTiao), penulis: Xia Qiansi







