TL;DR
Sebuah diagram perkiraan yang memecah biaya berlangganan Claude Pro AS sekitar $20 per bulan untuk perusahaan model, daya komputasi awan, depresiasi GPU, listrik, dan rantai pasokan, sedang membuat investor mendiskusikan kembali bagaimana pendapatan aplikasi AI seharusnya dinilai.
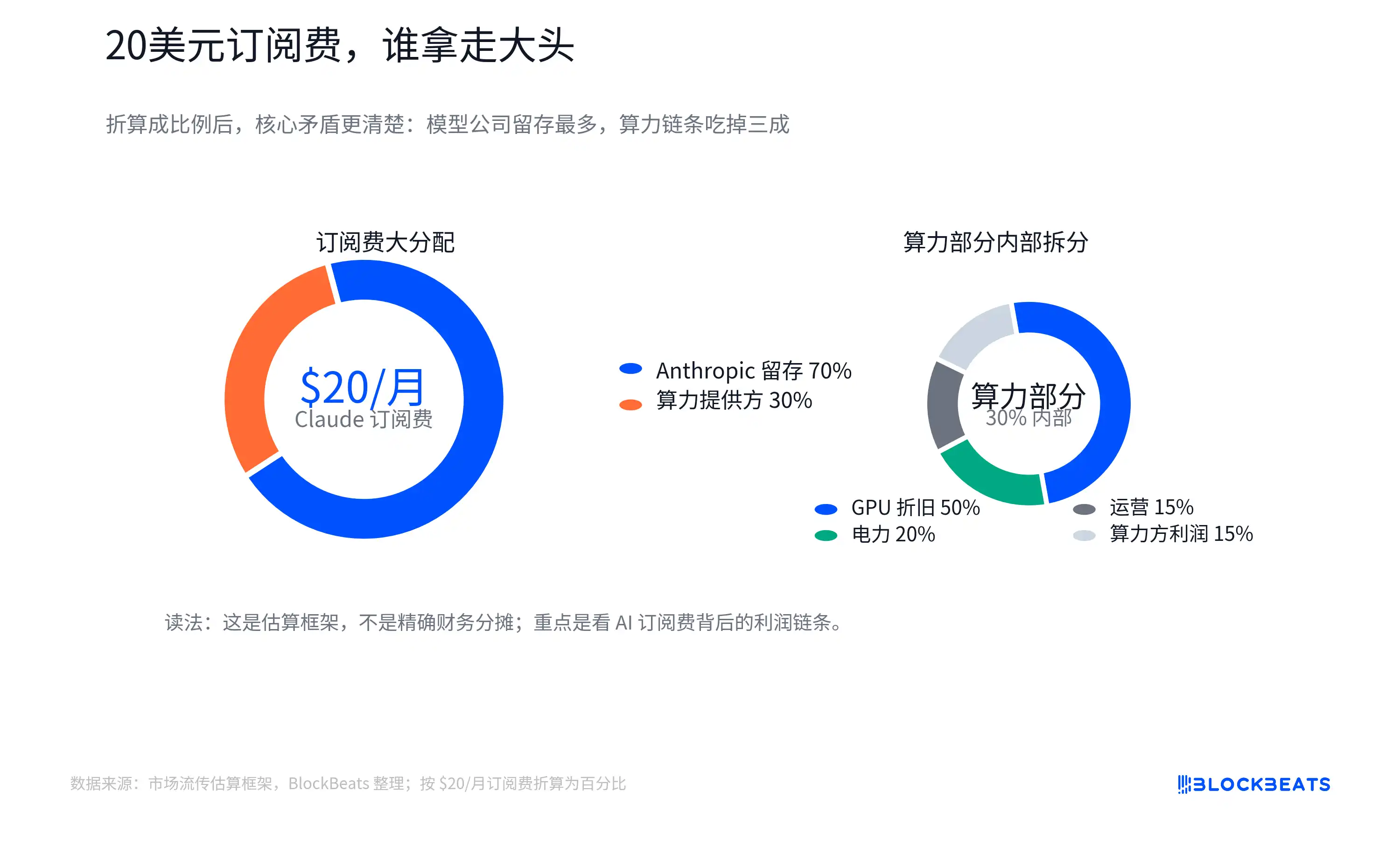
Diagram ini bukan data pembagian resmi dari Anthropic, Amazon Web Services, atau Nvidia, dan juga tidak bisa dianggap sebagai buku besar nyata dari perusahaan mana pun. Nilainya terletak pada pengajuan pertanyaan yang lebih mendasar: Dari biaya berlangganan yang dibayarkan pengguna untuk aplikasi AI, berapa banyak yang dapat mengendap menjadi margin keuntungan perangkat lunak seperti layanan SaaS tradisional?
Imajinasi valuasi untuk SaaS tradisional cukup jelas. Setelah perangkat lunak selesai dikembangkan, menjual satu akun tambahan biasanya memiliki biaya tambahan yang tidak tinggi. Perusahaan perangkat lunak murni yang matang umumnya memiliki margin kotor di atas 70% atau bahkan 80%. Investor bersedia memberikan kelipatan tinggi karena margin keuntungan berpeluang terus meningkat setelah skala pendapatan meluas.
Masalah aplikasi AI terletak pada fakta bahwa setiap kali pengguna mengajukan pertanyaan, menulis kode, menganalisis file, atau memanggil agen, di baliknya ada konsumsi waktu GPU, daya listrik, bandwidth memori, dan sumber daya awan. Permukaannya adalah biaya bulanan tetap, tetapi dasarnya adalah rantai biaya yang berubah sesuai dengan volume penggunaan. Pengguna ringan mungkin menghasilkan margin kotor yang tinggi, tetapi pengguna berat yang menjalankan tugas secara berkelanjutan dalam kuota atau paket alat terkait yang tersedia, biayanya bisa meningkat dengan cepat.
Jadi, diagram pemecahan $20 ini bukan ingin menantang berapa dolar yang diambil oleh perusahaan tertentu, melainkan "apakah pendapatan aplikasi AI secara alami sama dengan pendapatan SaaS". Perusahaan AI yang ingin membuktikan dirinya layak mendapat kelipatan tinggi, tidak hanya perlu membuktikan bahwa pengguna bersedia membayar, tetapi juga membuktikan bahwa margin kotor berbobot volume penggunaan dapat terus membaik.
Di Balik Biaya Berlangganan Ada Rantai Biaya Inferensi
Perbedaan terbesar antara langganan AI dan langganan perangkat lunak biasa adalah bahwa biaya marginal "menggunakan sekali" tidak lagi mendekati nol.
Dalam SaaS tradisional, saat sebuah tim membuka satu akun tambahan, penyedia layanan juga memiliki biaya server, layanan pelanggan, dan bandwidth, tetapi biaya ini biasanya tidak naik secara linear dengan setiap klik. Yang benar-benar mahal adalah penelitian dan pengembangan, penjualan, dan akuisisi pelanggan di tahap awal. Setelah produk diskalakan, sebagian besar dari pendapatan tambahan dapat dipertahankan.
Produk model besar berbeda. Pengguna memasukkan pertanyaan, model menghasilkan jawaban. Proses ini disebut inferensi, yaitu komputasi aktual saat model dipanggil oleh pengguna. Token adalah satuan dasar pengukuran untuk membaca dan menulis teks oleh model. Semakin banyak pengguna bertanya, semakin panjang konteksnya, dan semakin kompleks konten yang dihasilkan, maka token dan daya komputasi yang dikonsumsi semakin banyak.
Ini menciptakan kontradiksi antara langganan tetap dan biaya variabel. Biaya berlangganan Claude Pro AS sekitar $20 per bulan, harganya dapat dipengaruhi oleh wilayah, pajak, dan penyesuaian dari Anthropic. Yang dilihat pengguna adalah harga tetap, tetapi yang dihadapi perusahaan model adalah perilaku penggunaan yang sangat berbeda. Ada yang hanya menulis email dan mencari informasi, ada yang memproses dokumen panjang, menjalankan tugas kode, atau memanggil alur otomatisasi yang lebih kompleks.
Diagram pemecahan yang beredar di pasar mencoba menggambarkan hal ini secara konkret: Dari $20, sebagian disisakan untuk perusahaan model, sebagian dibayarkan ke penyedia awan dan daya komputasi. Biaya daya komputasi mencakup listrik, pemeliharaan, dan depresiasi GPU. Pembelian GPU kemudian mengalir ke atas ke Nvidia, TSMC, pemasok HBM (High Bandwidth Memory), produsen modul optik, ODM, dan perusahaan terkait listrik.
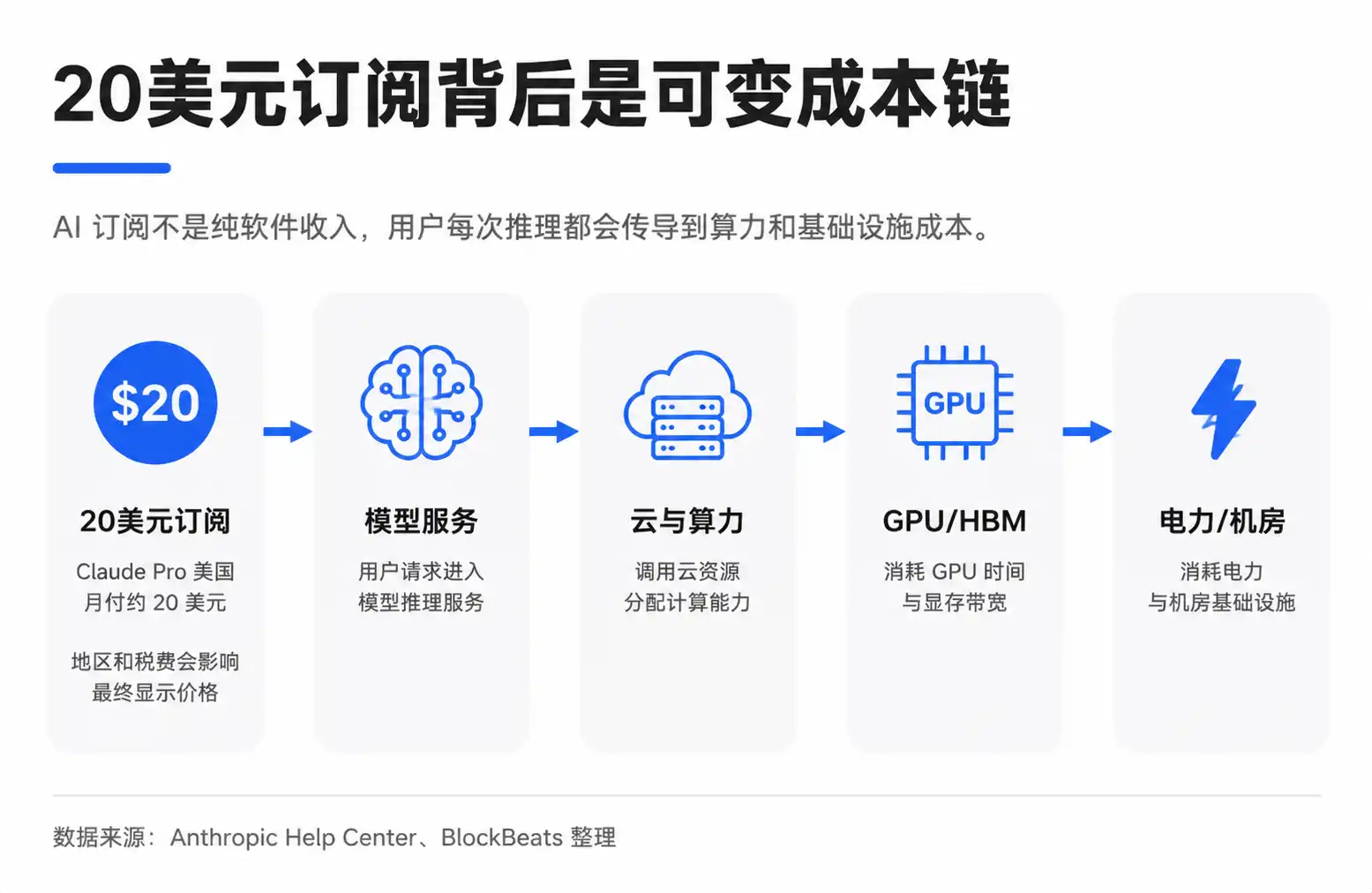
"Depresiasi GPU" di sini dapat dipahami bahwa GPU yang mahal tidak dihitung biayanya sekaligus, tetapi dialokasikan secara bertahap ke dalam layanan AI berdasarkan masa pakai, intensitas penggunaan, atau standar akuntansi. Alokasi nyata akan dipengaruhi oleh batasan paket, rasio pengguna ringan-berat, harga penyelesaian internal penyedia awan, diskon untuk kapasitas komputasi yang dipesan, tingkat pemanfaatan GPU, dan masa depresiasi. Biaya rata-rata juga tidak sama dengan biaya marginal.
Arah yang benar-benar perlu diwaspadai investor adalah: Perusahaan aplikasi AI tidak hanya perlu mengungkapkan pertumbuhan pendapatan, tetapi juga menjawab apakah biaya daya komputasi di balik pertumbuhan pendapatan tersebut juga tumbuh bersamaan. Jika ekspansi volume penggunaan lebih cepat daripada peningkatan efisiensi model, semakin tinggi pendapatan langganan, tekanan terhadap margin kotor mungkin semakin jelas. Hanya jika peningkatan efisiensi cukup cepat, perusahaan model baru memiliki peluang untuk mendekati kembali struktur keuntungan perusahaan perangkat lunak.
Infrastruktur Mendapatkan Pendapatan yang Lebih Pasti Terlebih Dahulu
Saat ini, pertumbuhan volume penggunaan AI lebih langsung mengalir ke infrastruktur, dan tidak semuanya mengendap di lapisan aplikasi.
Tidak peduli apakah pengguna menggunakan model di Claude, ChatGPT, Gemini, atau agen internal perusahaan, inferensi pada akhirnya harus mengandalkan daya komputasi, listrik, memori, dan jaringan. Mungkin ada pergantian produk di lapisan aplikasi, tetapi konsumsi sumber daya dasar lebih kaku. Selama volume penggunaan AI terus meningkat, pengeluaran modal awan, pembelian GPU, permintaan HBM, dan konsumsi listrik pusat data akan terdorong.
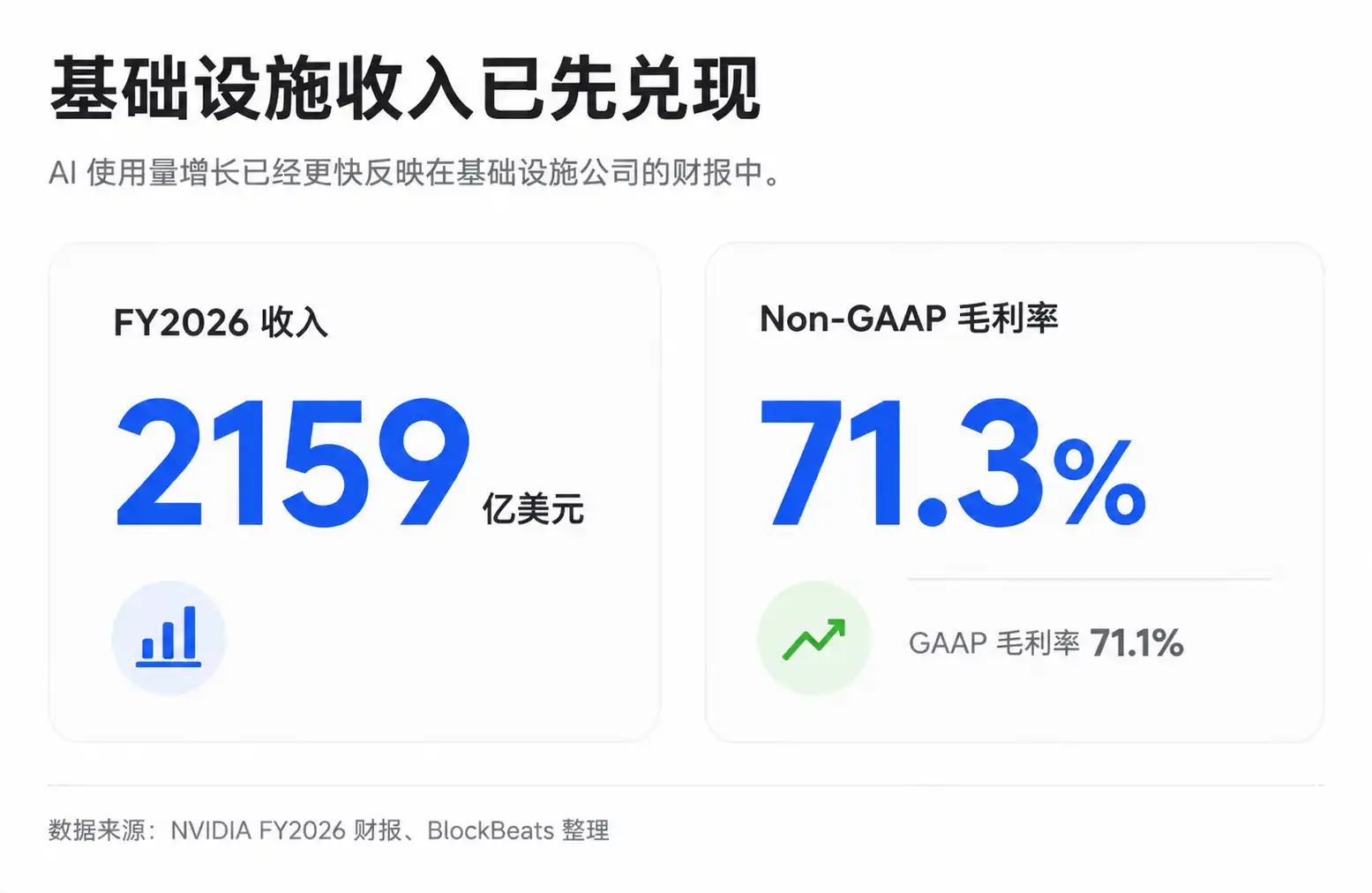
Ini juga alasan mengapa rantai infrastruktur seperti Nvidia, TSMC, SK Hynix terus dievaluasi ulang oleh pasar. Margin kotor keseluruhan Nvidia dalam beberapa tahun terakhir berada di level tinggi. Margin kotor GAAP dan non-GAAP untuk tahun fiskal 2026 sekitar 71,1% dan 71,3%, dan panduan untuk kuartal berikutnya juga tetap tinggi. Perlu diperhatikan, kuartal tertentu dapat terganggu oleh biaya tertentu, dan laporan keuangan publik tidak selalu dapat secara langsung memecah struktur margin kotor nyata pusat data AI. Namun, fakta bahwa infrastruktur langka memiliki kekuatan penentuan harga telah tercermin dalam kinerja.
HBM adalah mata rantai paling khas dalam rantai ini. Ini bukan memori biasa, tetapi komponen kunci dalam akselerator AI yang mendukung komputasi throughput tinggi. Setelah skala model, panjang konteks, dan kebutuhan inferensi bersamaan meningkat, ketergantungan chip AI pada memori bandwidth tinggi menjadi lebih kuat. Perkiraan rantai pasokan menunjukkan bahwa porsi HBM dalam biaya chip AI generasi baru meningkat. Ini juga alasan penting mengapa SK Hynix, Samsung, Micron diberi harga ulang dalam siklus AI.
Listrik dan pusat data juga berubah dari biaya latar belakang menjadi tema investasi utama. Konsumsi energi untuk satu kueri teks biasa mungkin tidak terlalu besar, tetapi agen kompleks, konteks panjang, pembuatan kode, dan tugas multi-ronde akan memperbesar volume komputasi. Bagi penyedia awan dan operator pusat data, kuncinya bukanlah berapa banyak listrik yang dikonsumsi oleh satu kueri tertentu, melainkan ketika sejumlah besar permintaan inferensi terjadi secara terus-menerus, pemanfaatan klaster, harga listrik, pendinginan, kapasitas ruang server, dan kemampuan akses jaringan listrik akan menjadi biaya dan hambatan.
Kelebihan di sisi infrastruktur adalah bahwa verifikasi kinerja lebih cepat. Pengeluaran modal AI penyedia awan telah terjadi, pendapatan dan margin kotor Nvidia tercermin dalam laporan keuangan, pesanan dan harga pemasok HBM juga akan lebih cepat masuk ke laporan laba rugi. Lapisan aplikasi model lebih banyak memperdagangkan ekspektasi masa depan: konversi langganan, penetrasi perusahaan, pendapatan API, dan pelepasan keuntungan setelah kurva biaya masa depan turun.
Peningkatan Efisiensi Masih Menjadi Argumen Inti Pendukung Bullish
Investor perangkat lunak dan pendukung bullish AI juga memiliki sanggahan. Inti pandangan dari pihak efisiensi adalah bahwa tingginya biaya inferensi saat ini hanyalah fenomena tahap awal. Optimisasi model, cache, model kecil, chip buatan sendiri, dan pemanfaatan klaster yang lebih tinggi akan terus menurunkan biaya per unit. Selama penurunan biaya cukup cepat, aplikasi AI masih mungkin kembali ke logika perangkat lunak margin kotor tinggi.
Sanggahan ini memiliki dasar realitas. Beberapa model utama telah menunjukkan penurunan harga per unit yang signifikan dengan kemampuan yang setara atau lebih tinggi. OpenAI pernah mengungkapkan bahwa biaya per token untuk GPT-4o mini turun 99% dibandingkan dengan text-davinci-003 tahap awal. Ritme antarperusahaan tidak sepenuhnya seragam. Anthropic baru-baru ini lebih banyak menunjukkan peningkatan dengan harga yang sama dan stratifikasi model, tetapi arah industri tetap menggunakan biaya yang lebih rendah untuk memberikan kemampuan yang lebih kuat.

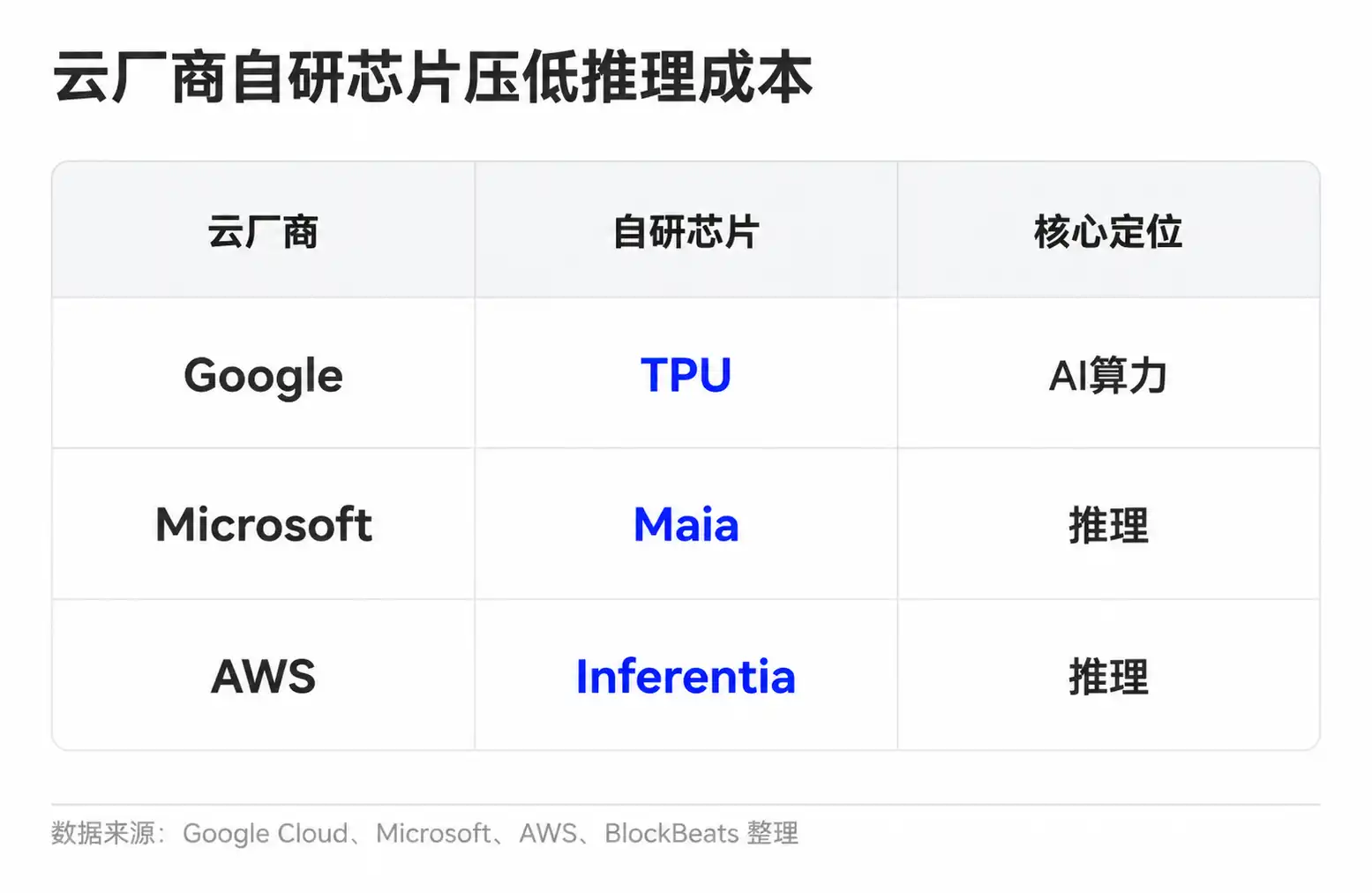
Perusahaan model juga memiliki berbagai cara untuk meningkatkan ekonomi per unit. Tugas sederhana diserahkan ke model kecil, permintaan umum digunakan ulang melalui cache, konteks panjang dan tugas kompleks diserahkan ke model yang lebih kuat. Penyedia awan menurunkan biaya daya komputasi per unit melalui chip buatan sendiri dan penjadwalan klaster. Google memiliki TPU, Microsoft meluncurkan Maia untuk inferensi, dan Amazon juga mengembangkan Trainium dan Inferentia.
Jika hanya melihat kemajuan teknologi, margin keuntungan aplikasi AI memang memiliki ruang untuk perbaikan. Inferensi yang lebih murah, routing model yang lebih baik, dan kemampuan kompresi yang lebih kuat, semuanya dapat membuat langganan $20 yang sama menanggung volume penggunaan yang lebih banyak. Pengguna ringan, paket perusahaan berharga tinggi, penetapan harga berlapis API, dan batasan penggunaan yang lebih ketat juga dapat meningkatkan ekonomi per unit secara keseluruhan.
Kesulitannya adalah, penurunan biaya bukan satu-satunya variabel. Aplikasi AI sedang bergerak dari obrolan sederhana ke beban kerja yang lebih berat. Dulu pengguna mungkin hanya tanya jawab dan menulis ulang teks, sekarang semakin banyak kebutuhan berasal dari agen kode, pemrosesan dokumen panjang, pembuatan video dan multimodal, serta alur otomatisasi perusahaan. Skenario ini bernilai lebih tinggi, tetapi juga konsumsinya lebih tinggi. Semakin berguna modelnya, pengguna semakin mungkin mempercayakan tugas yang lebih kompleks dan lebih lama padanya.
Perbedaan pendapat menjadi lebih konkret: Apakah kecepatan penurunan biaya inferensi dapat melampaui pertumbuhan volume penggunaan dan kompleksitas tugas? Jika biaya per unit turun dengan cepat, tetapi konsumsi rata-rata pengguna tumbuh lebih cepat, margin kotor berbobot perusahaan model masih akan tertekan. Sebaliknya, jika routing model, cache, chip buatan sendiri, dan stratifikasi harga cukup efektif, langganan AI mungkin secara bertahap terbebas dari karakteristik biaya berat saat ini.
Jumlah Pengguna Berlangganan Bukanlah Margin Kotor
Diagram pemecahan $20 tidak boleh dipahami sebagai keadaan akhir. Ini lebih seperti pengingat valuasi di tahap saat ini: Ketika pasar belum dapat melihat data margin kotor perusahaan model yang cukup transparan, investor perlu memberikan diskon untuk asumsi "aplikasi AI secara alami sama dengan SaaS".
Bagi perusahaan model yang belum terdaftar seperti OpenAI dan Anthropic, investor eksternal sulit melihat buku besar lengkap. Materi pendanaan, pengungkapan mitra, struktur biaya awan, harga paket perusahaan, proporsi pendapatan API, dan batasan penggunaan akan menjadi petunjuk penilaian. Data yang benar-benar berharga bukanlah berapa banyak pengguna berbayar, melainkan berapa proporsi pengguna ringan dan berat, apakah klien perusahaan bersedia membayar harga lebih tinggi untuk penggunaan intensif, apakah biaya penyelesaian awan menurun, serta apakah penurunan biaya inferensi per unit dapat masuk ke margin kotor perusahaan.
Verifikasi dari rantai perusahaan yang sudah terdaftar akan lebih cepat muncul dalam laporan keuangan. Margin kotor keseluruhan dan kecepatan pertumbuhan pendapatan pusat data Nvidia, permintaan proses canggih dan pengemasan TSMC, harga dan margin keuntungan pemasok HBM, intensitas pengeluaran modal penyedia awan, semua ini akan terus mencerminkan apakah volume penggunaan AI masih mengalir ke ujung infrastruktur. Jika indikator-indikator ini tetap kuat, sementara lapisan aplikasi model kurang bukti perbaikan margin kotor, pasar akan terus memberikan premi valuasi yang lebih pasti kepada infrastruktur.
Pada akhirnya, agar perusahaan model mendapatkan jangkar valuasi yang lebih tinggi, yang perlu dibuktikan bukan hanya kesediaan pengguna membayar $20, tetapi juga bahwa biaya berlangganan ini, setelah digunakan secara berat, masih dapat menyisakan margin kotor yang cukup. Perbedaan pendapat penetapan harga berikutnya, kemungkinan besar tidak terletak pada angka headline ARR, tetapi pada apakah biaya inferensi, batasan paket, dan harga berbayar perusahaan dapat berjalan bersamaan.





