原文作者:Zhiyong Fang
"如何吃掉一头大象?一口一口地吃。"
近年来,机器学习模型以惊人的速度实现跨越式发展。随着模型能力的提升,其复杂性亦同步激增——当今先进模型往往包含数百万乃至数十亿参数。为应对此等规模挑战,多种零知识证明系统应运而生,这些系统始终致力于在证明时间、验证时间与证明大小三者间实现动态平衡。
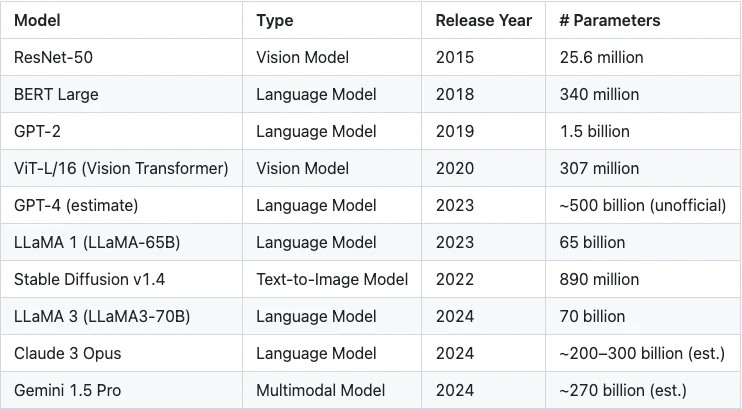
表 1 :模型参数规模的指数级增长
尽管当前零知识证明领域的大部分工作集中在优化证明系统本身,但一个关键维度却常常被忽视——如何将大规模模型合理拆分为更小、更易于处理的子模块以进行证明。你可能会问,这一点为什么如此重要?
下面我们来详细解释:
现代机器学习模型的参数数量往往以十亿计,即便在不涉及任何密码学处理的情况下,也已占用极高的内存资源。而在零知识证明(Zero-Knowledge Proof, ZKP)的场景下,这一挑战被进一步放大。
每一个浮点数参数都必须被转换为代数域(Arithmetic Field)中的元素,这一转换过程本身会导致内存占用增加约 5 至 10 倍。此外,为了在代数域中精确模拟浮点运算,还需额外引入操作开销,通常也在 5 倍左右。
综合来看,模型整体内存需求可能提升至原始规模的 25 至 50 倍。例如,一个拥有 10 亿个 32 位浮点参数的模型,仅存储转换后的参数就可能需要 100 至 200 GB 内存。再考虑中间计算值与证明系统本身的开销,整体内存占用轻易突破 TB 级别。
当前主流的证明系统,如 Groth 16 和 Plonk,在未经优化的实现中,通常假设所有相关数据可同时加载至内存中。这种假设虽然在技术上可行,但在实际硬件条件下极具挑战性,极大限制了可用的证明计算资源。
Polyhedra 的解决方案:zkCuda
什么是 zkCuda?
如我们在《zkCUDA 技术文档》中所述:
Polyhedra 推出的 zkCUDA 是一个面向高性能电路开发的零知识计算环境,专为提升证明生成效率而设计。在不牺牲电路表达能力的前提下,zkCUDA 可充分利用底层证明器和硬件并行能力,实现快速的 ZK 证明生成。
zkCUDA 语言在语法和语义上与 CUDA 高度相似,对已有 CUDA 经验的开发者十分友好,且其底层以 Rust 实现,确保安全性与性能兼备。
借助 zkCUDA,开发者可以:
快速构建高性能 ZK 电路;
高效调度并利用分布式硬件资源,如 GPU 或支持 MPI 的集群环境,实现大规模并行计算。
为什么选择 zkCUDA?
zkCuda 是一套受 GPU 计算启发设计的高性能零知识计算框架,能够将超大规模的机器学习模型拆分为更小、更易管理的计算单元(kernels),并通过类似 CUDA 的前端语言实现高效控制。这一设计带来了以下关键优势:
1. 精准匹配的证明系统选择
zkCUDA 支持对每个计算 kernel 进行细粒度分析,并为其匹配最适合的零知识证明系统。例如:
对于高度并行的计算任务,可选用如 GKR 等擅长处理结构化并行度的协议;
对于规模较小或结构不规则的任务,则更适合使用如 Groth 16 这类在紧凑计算场景下具有低开销的证明系统。
通过定制化选择后端,zkCUDA 能最大化发挥各类 ZK 协议的性能优势。
2. 更智能的资源调度与并行优化
不同的证明 kernel 对 CPU、内存和 I/O 的资源需求差异显著。zkCUDA 可准确评估每个任务的资源消耗,并智能排程,最大化整体吞吐能力。
更重要的是,zkCUDA 支持在异构计算平台之间进行任务分发——包括 CPU、GPU 和 FPGA——从而实现硬件资源的最优利用,显著提升系统级性能。
zkCuda 与 GKR 协议的天然契合
尽管 zkCuda 被设计为一个兼容多种零知识证明系统的通用计算框架,但它与 GKR(Goldwasser-Kalai-Rothblum)协议在架构上具有天然的高度契合性。
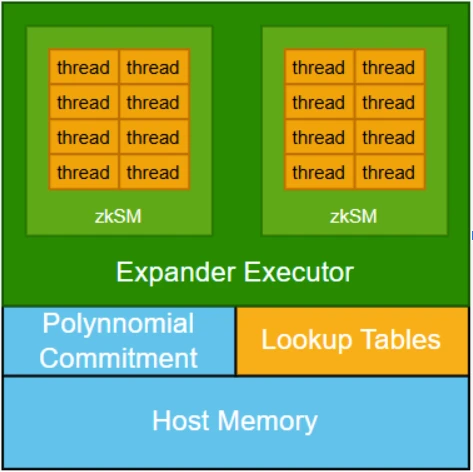
在架构设计上,zkCUDA 通过引入多项式承诺机制,将各个子计算内核连接起来,确保所有子计算基于一致的共享数据运行。这一机制对于保持系统完备性至关重要,但也带来了显著的计算成本。
相比之下,GKR 协议提供了一种更高效的替代路径。与传统零知识系统要求每个内核完整证明其内部约束的方式不同,GKR 允许将计算正确性的验证从内核输出递归回溯至输入。这一机制使得跨内核的正确性得以传递,而非在每个模块中完全展开验证。其核心思想类似于机器学习中的梯度反向传播,通过计算图追踪和传导正确性主张。
虽然在多路径中合并这类“证明梯度”带来了一定复杂性,但正是这一机制,构成了 zkCUDA 与 GKR 之间的深度协同基础。通过对齐机器学习训练流程中的结构特性,zkCUDA 有望实现更紧密的系统集成和大模型场景下更高效的零知识证明生成。
初步成果与未来方向
我们已完成 zkCuda 框架的初始开发,并在多个场景中成功进行了测试,包括 Keccak 和 SHA-256 等密码学哈希函数,以及小规模的机器学习模型。
展望未来,我们希望进一步引入现代机器学习训练中的一系列成熟工程技术,如内存优化调度(memory-efficient scheduling)与计算图级优化(graph-level optimization)。我们相信,将这些策略融合进零知识证明生成流程,将极大提升系统的性能边界与适配灵活性。
这只是一个起点,zkCuda 将持续向高效、高扩展性、高适配性的通用证明框架迈进。





