Baru saja, DeepSeek V4 melakukan pembaruan.
Meluncurkan framework decoding spekulatif (Speculative Decoding) DSpark, dan sekaligus membuka sumber (open-source) framework decoding spekulatif full-stack DeepSpec yang mendukung versi ini.
DeepSeek-V4-Pro-DSpark bukanlah model arsitektur baru, melainkan pengenalan modul decoding spekulatif pada basis DeepSeek-V4-Pro. Fokus pembaruan ini terletak pada implementasi rekayasa (engineering), bukan pada iterasi kemampuan model itu sendiri.
DSpark telah diterapkan di lalu lintas online nyata DeepSeek-V4 (Flash dan Pro), secara signifikan mempercepat kecepatan inferensi model bahasa besar (Large Language Model/LLM).

Laporan Teknis: "DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation"
Tautan Laporan Teknis: https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
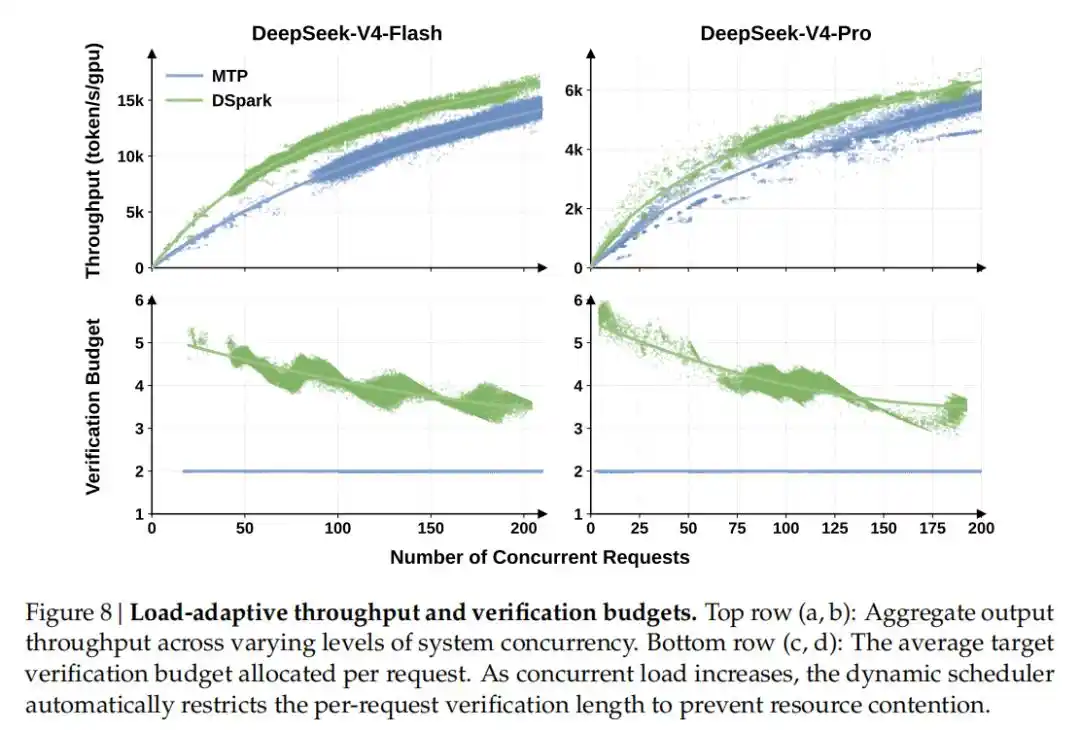
Inti awal DSpark adalah untuk mengatasi hambatan latensi dan throughput yang dihadapi oleh inferensi LLM dalam lingkungan produksi (terutama skenario konkurensi tinggi). Singkatnya, DSpark berhasil menggabungkan "pembuatan paralel" ber-throughput tinggi dengan "validasi sadar beban (load-aware)" yang adaptif.
Decoding spekulatif adalah teknik untuk mempercepat inferensi model bahasa besar tanpa mengubah distribusi output model. Inti pemikirannya adalah memperkenalkan "model draf (draft model)" yang ringan, untuk menghasilkan beberapa token kandidat terlebih dahulu, kemudian model target (target model) memvalidasi dan menerima kumpulan kandidat ini secara batch, sehingga mengubah pembuatan token demi token serial menjadi verifikasi batch paralel, secara drastis mengurangi latensi end-to-end.
Dasar ini, inovasi DSpark terletak pada pengenalan Arsitektur Generasi Semi-Autoregresif (Semi-Autoregressive Generation): Ia mempertahankan keunggulan throughput tinggi model draf paralel, sekaligus menambahkan modul serial ringan untuk memodelkan hubungan ketergantungan antar token di dalam blok, guna meredakan masalah penurunan tingkat penerimaan (acceptance rate) yang mudah terjadi pada posisi selanjutnya dalam model draf paralel.
Selain itu ada Validasi Penjadwalan Keyakinan Sadar Perangkat Keras (Hardware-Aware Confidence-Scheduled Verification): Decoding spekulatif sebelumnya biasanya akan secara membabi buta mengirimkan semua Token draf yang dihasilkan untuk divalidasi. Saat sistem mengalami beban tinggi, Token-Token ekor yang sangat mungkin ditolak ini akan sangat menyia-nyiakan daya komputasi pemrosesan batch yang berharga. DSpark memperkenalkan kepala keyakinan (Confidence Head) untuk mengevaluasi probabilitas kelangsungan hidup setiap Token. Digabungkan dengan penjadwal awalan (prefix scheduler) sadar perangkat keras, sistem dapat secara dinamis menyesuaikan panjang verifikasi optimal untuk setiap permintaan berdasarkan karakteristik throughput mesin waktu nyata, mengalokasikan daya komputasi hanya pada Token yang diharapkan memberikan hasil tertinggi.
Untuk diterapkan di infrastruktur online nyata, penjadwal DSpark menggunakan mekanisme asinkron untuk kompatibel dengan penjadwalan tanpa overhead (Zero-Overhead Scheduling/ZOS) dan pemutaran ulang grafik CUDA yang berkelanjutan. Ia menggunakan prediksi historis dari dua langkah sebelumnya untuk menentukan panjang pemotongan dinamis saat ini, sehingga menyembunyikan latensi penjadwalan, menghindari jeda pipa GPU, sekaligus memastikan restorasi distribusi output model target yang sepenuhnya tanpa kehilangan (lossless).
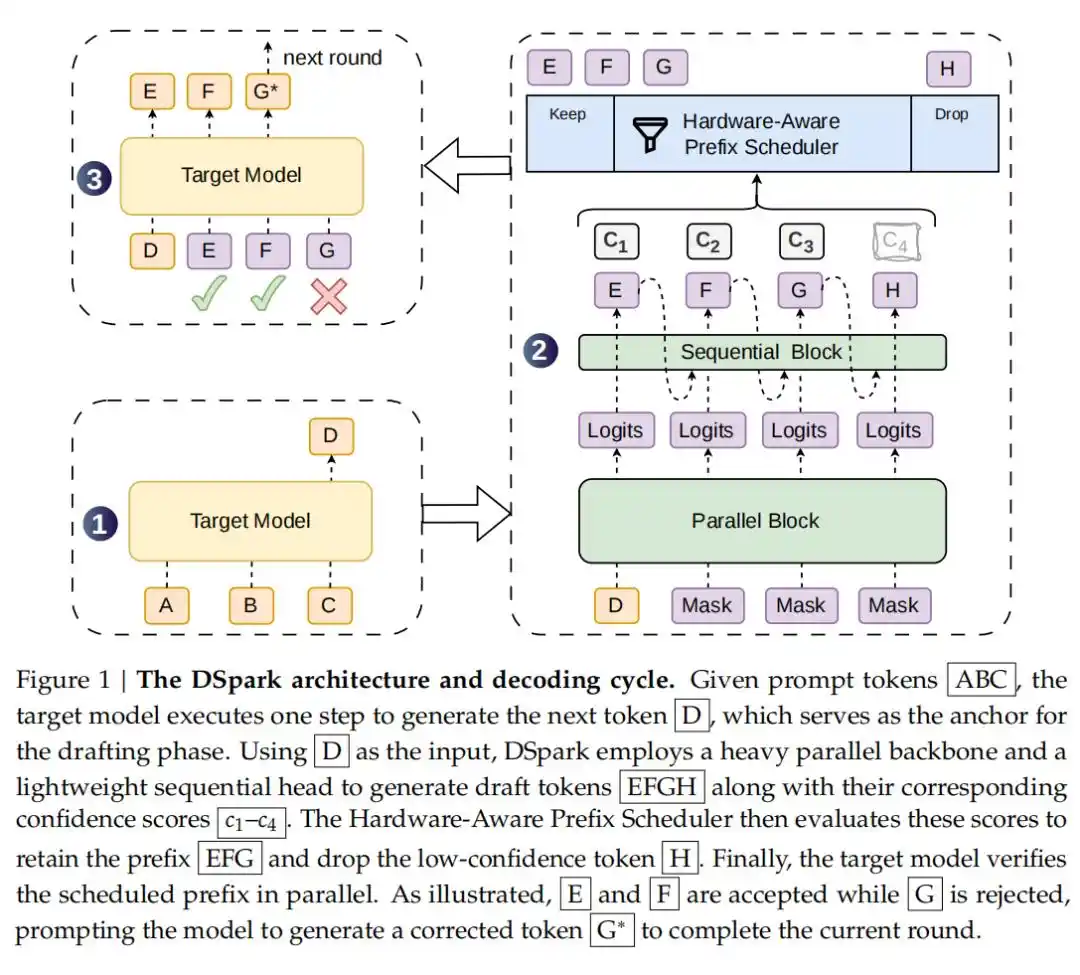
Dalam pengujian yang mencakup berbagai bidang seperti penalaran matematika, pembuatan kode, dan percakapan sehari-hari, DSpark jauh melampaui model autoregresif (Eagle3) dan model draf paralel (DFlash) yang paling mutakhir saat ini. Misalnya, pada model target seri Qwen3 (4B, 8B, 14B), panjang penerimaan rata-ratanya meningkat 26.7% hingga 30.9% dibandingkan Eagle3, dan meningkat 16.3% hingga 18.4% dibandingkan DFlash.
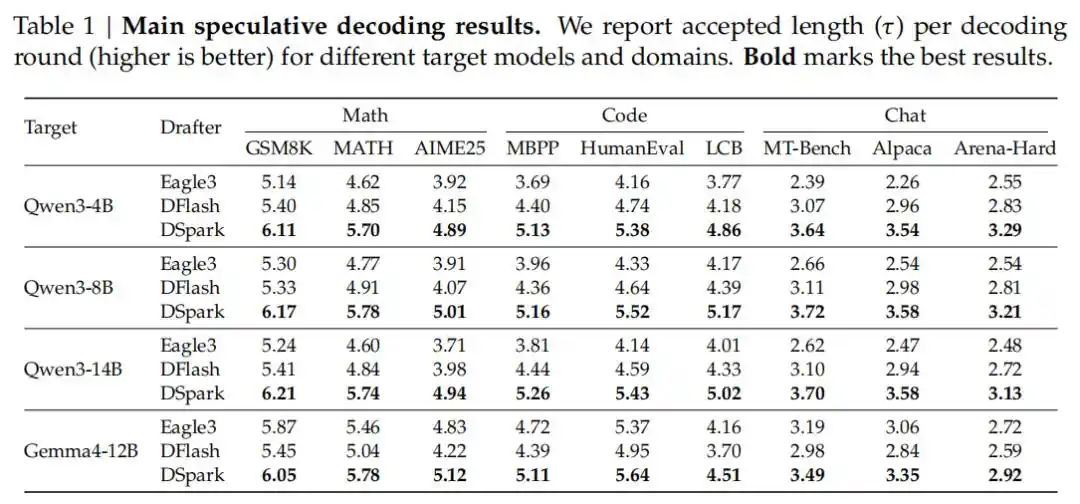
Dibandingkan dengan benchmark produksi Token tunggal yang diterapkan sebelumnya (MTP-1), dalam kondisi mempertahankan total throughput yang sama, DSpark meningkatkan kecepatan pembuatan pengguna masing-masing sebesar 60%-85% (model Flash) dan 57%-78% (model Pro).
Bersama dengan DSpark, juga dibuka sumberkan DeepSpec, ini adalah kodebase full-stack untuk melatih dan mengevaluasi model draf decoding spekulatif. Merupakan "infrastruktur sumber terbuka" yang menampung skema ini serta implementasi algoritma mutakhir lainnya, berisi alat persiapan data, implementasi model draf, kode pelatihan, dan skrip evaluasi.
DeepSpec membagi proses keseluruhan menjadi tiga tahap: persiapan data, pelatihan, dan evaluasi. Ketiga tahap perlu dijalankan secara berurutan, output tahap sebelumnya akan menjadi input tahap berikutnya.
Tahap persiapan data, perlu mengunduh data prompt, menggunakan mesin inferensi untuk menghasilkan ulang jawaban model target, dan membangun cache target (target cache). Patut diperhatikan, dengan konfigurasi default Qwen/Qwen3-4B, volume cache target dapat mencapai sekitar 38 TB, perlu mengevaluasi sumber daya penyimpanan dengan cukup sebelum digunakan.
Tahap pelatihan dapat dimulai melalui bash scripts/train/train.sh. Skrip ini akan memanggil train.py, dan meluncurkan sebuah worker untuk setiap GPU yang terlihat. Pengguna dapat memilih konfigurasi algoritma dan model target yang berbeda di direktori config/ dengan menentukan config_path. Proyek ini juga mendukung penyesuaian pengaturan pelatihan dengan menimpa config_path, target_cache_dir, serta menggunakan --opts untuk memodifikasi field konfigurasi tunggal.
Dari sisi perangkat keras, konfigurasi default dan skrip DeepSpec ditujukan untuk lingkungan satu node dengan 8 GPU. Jika jumlah GPU lebih sedikit, pengguna perlu mengurangi jumlah GPU yang terlihat dalam CUDA_VISIBLE_DEVICES sesuai kebutuhan.
Tahap evaluasi kemudian dimulai melalui bash scripts/eval/eval.sh. Skrip evaluasi akan menggunakan checkpoint model draf yang telah dilatih, untuk mengukur penerimaan pada beberapa tugas benchmark decoding spekulatif. Dataset evaluasi yang tercantum saat ini dalam proyek termasuk GSM8K, MATH500, AIME25, HumanEval, MBPP, LiveCodeBench, MT-Bench, Alpaca, dan Arena-Hard-v2, mencakup berbagai jenis tugas seperti penalaran matematika, pembuatan kode, kemampuan dialog, dan tanya jawab komprehensif.
Dari sisi algoritma, DeepSpec saat ini menyertakan tiga model draf bawaan: DSpark, DFlash, dan Eagle3. Untuk seri model target, proyek saat ini mendukung Qwen3 dan Gemma.
Pembukaan sumber DeepSpec, mengintegrasikan praktik rekayasa decoding spekulatif yang sebelumnya tersebar di berbagai tim penelitian internal, menjadi seperangkat toolchain terstandarisasi yang dapat direproduksi dan diperluas. Bagi peneliti dan insinyur yang berharap mempercepat inferensi model besar mereka sendiri, ini berarti dapat langsung melatih model draf kustom pada framework yang matang, melewati banyak pekerjaan pembangunan infrastruktur dasar yang berulang.
Tautan Referensi:
https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
https://github.com/deepseek-ai/DeepSpec
Artikel ini berasal dari akun WeChat publik "机器之心" (ID:almosthuman2014), penulis: Zenan, Yang Wen





