С 2 апреля 2025 года президент США Дональд Трамп привел в движение мировые рынки благодаря серии масштабных тарифов, часть из которых была временно приостановлена в эту среду. Рынки прогнозов стали горячей точкой для ставок, связанных с торговой политикой Трампа, привлекая значительное внимание спекулянтов и аналитиков.
От паузы до давления: тарифные шаги Трампа подпитывают спекуляции на Polymarket и Kalshi
Участники вкладывают капиталы в траекторию глобальной тарифной политики Трампа. Когда план был впервые представлен, он включал минимальную ставку в 10% по всему миру с более высокими штрафами для того, кого он назвал «основными нарушителями». 9 апреля администрация приостановила все тарифы выше 10% на 90-дневный период, за исключением Китая, ставка которого поднялась до 125%, а затем снова выросла до 145% к пятнице.
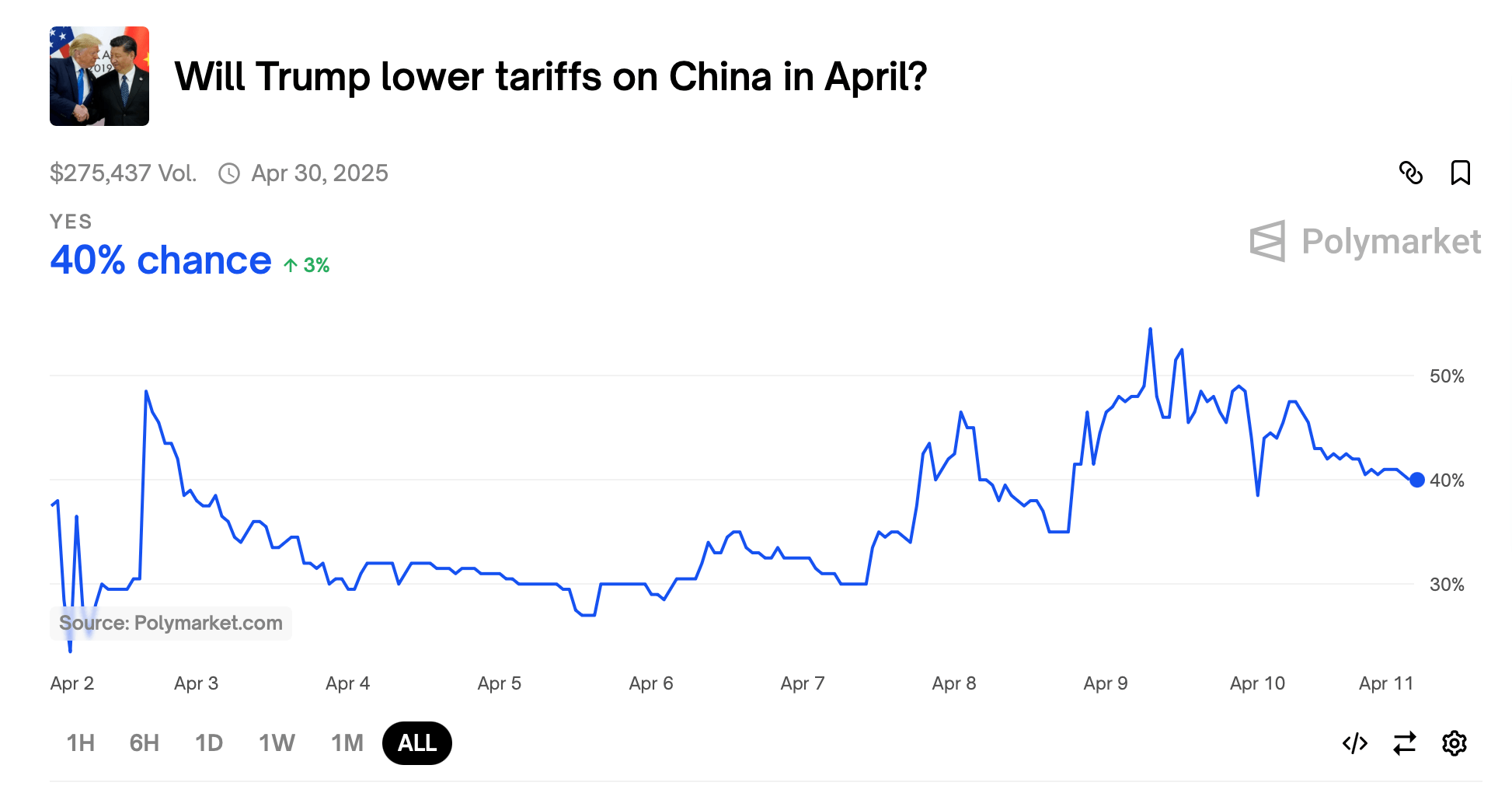
На Polymarket трейдеры устанавливают 40% вероятность того, что Трамп смягчит тарифы на Китай до конца месяца. Этот контракт привлек $275,437 в объеме и будет решен 30 апреля. Еще одна активная ставка, привлекающая $91,465, ставит шансы на отмену универсальных 10% тарифов в этом месяце всего в 8%. Между тем, существует 19% вероятность того, что Трамп повысит тарифы на Китай до 200% до июня. Эта позиция, объемом $22,844, завершится в конце этого месяца.
Kalshi также предлагает набор ставок, отслеживающих тарифные решения Трампа. Одна из них под названием «Когда Трамп завершит свои тарифы против Китая?» предлагает только 3% шанс на отмену до мая 2025 года. Шансы увеличиваются до 18% для июня и достигнут 28% к декабрю. Пользователи Kalshi также делают ставки на возможность введения Трампом экспортных тарифов.
Этот конкретный контракт, касающийся экспортных тарифов, в настоящее время показывает 15% шанс реализации. Заявления Трампа по торговле продолжают привлекать внимание финансовых рынков, уже став причиной исторических распродаж акций, уничтожений триллионов рыночной капитализации и множества опасений по поводу эскалации торговых конфликтов, инфляционного давления и экономического спада.





