Original | Odaily 星球日报(@OdailyChina)
Auteur | Asher(@Asher_ 0210)

À cette Coupe du Monde, l'endroit le plus animé n'est pas seulement sur le terrain.
Avec la montée en puissance des événements liés aux prédictions de la Coupe du Monde, de plus en plus d'utilisateurs commencent à participer aux transactions avec de l'argent réel. Qui va gagner, quel score, y aura-t-il une surprise, des cartons rouges, quel joueur marquera ? Ces sujets qui étaient autrefois des bavardages entre fans avant les matchs sont désormais décomposés en une série d'événements prédictifs négociables.
Et lorsque la prédiction devient une transaction, les utilisateurs n'ont pas seulement besoin d'émotions et d'intuition : les changements de cotes, la forme des équipes, les blessures, les confrontations historiques, la psychologie du marché deviennent tous des éléments à prendre en compte avant de trader. Dans ce processus, les modèles d'IA sont de plus en plus souvent convoqués dans le scénario des prédictions de la Coupe du Monde.
Les grands modèles comme Qwen, ChatGPT, Gemini, Claude, DeepSeek, Qwen et Copilot peuvent non seulement répondre à "quelle équipe a le plus de chances de gagner", mais aussi donner des pronostics de scores, la probabilité de surprises, le risque de cartons rouges, la performance des joueurs clés et l'analyse du déroulement du match. Pour les participants aux marchés prédictifs, la simulation pré-match de l'IA devient une référence supplémentaire, au-delà des cotes, des actualités, des données des équipes et de la psychologie du marché.
Cependant, les prédictions doivent finalement revenir au match lui-même.
Avec le démarrage officiel de la Coupe du Monde, les résultats des premiers matchs sont tombés les uns après les autres. Les analyses d'IA que les utilisateurs avaient utilisées pour éclairer leur jugement avant les matchs peuvent enfin être confrontées à la réalité : le score a-t-il été juste, la surprise a-t-elle été anticipée, et dans quelle mesure le modèle a-t-il réellement capté des détails comme les cartons rouges, les buts à la dernière minute ou la dynamique du match.
Le premier à faire le buzz ? Qwen
Le moment le plus spectaculaire du premier jour de la Coupe du Monde a sans doute été l'exploit de Qwen.
Pour le match d'ouverture Mexique contre Afrique du Sud, Qwen a prédit avant le match un score de 2-0 en faveur du Mexique. À la fin du match, le score était effectivement de 2-0. Plus intéressant encore, les trois cartons rouges distribués pendant le match correspondaient également au risque mentionné par Qwen avant le match : "Les défenseurs sud-africains sont parfois durs dans leurs tacles, et pourraient se retrouver rapidement en infériorité numérique."

Si Qwen s'était contenté de prévoir la victoire du Mexique, cela n'aurait pas été si surprenant. En tant que co-pays hôte, le Mexique était naturellement favori. Mais Qwen a cette fois-ci touché des détails plus concrets du match : le score de 2-0, le risque de carton rouge pour l'Afrique du Sud, et le rythme qui s'est accéléré en seconde période.
Ensuite, pour le match Corée du Sud contre République tchèque, Qwen a à nouveau prédit un 2-1 pour la Corée.
Ce match n'était pas facile à pronostiquer avant le coup d'envoi. La République tchèque avait une présence physique, une menace sur coups de pied arrêtés et l'expérience habituelle des équipes européennes en grands tournois. Le match n'a effectivement pas été à sens unique, les Tchèques ont ouvert le score, la Corée a égalisé, et le score est resté longtemps à 1-1. C'est seulement en fin de match que la Corée a marqué le but vainqueur, scellant le score à 2-1.
Dès lors, la prédiction de Qwen a pris une dimension encore plus "scénarisée". Prédire le vainqueur peut se faire sur le papier, le score peut être une question de chance, mais ce sont les détails du déroulement comme les cartons rouges, les renversements de situation, les buts victorieux en fin de match qui font vraiment penser "qu'il y a quelque chose". Après deux matchs dès le premier jour, Qwen a immédiatement fait monter la notoriété des prédictions d'IA pour la Coupe du Monde.
Copilot : Des coups de génie, mais aussi des échecs patents
Avant le tournoi, USA Today avait demandé à Copilot de prédire l'intégralité des 104 matchs de cette Coupe du Monde. En se basant sur les matchs déjà terminés, ces prédictions présentent à la fois des moments forts et des erreurs manifestes.
Parmi elles, trois prédictions sont particulièrement remarquables.
Pour le match d'ouverture Mexique contre Afrique du Sud, Copilot avait prédit un 2-0 pour le Mexique, correspondant exactement au score final. Pour la Corée du Sud contre République tchèque, il avait prédit un 2-1 pour la Corée, également confirmé par le résultat. Enfin, pour le Brésil contre Maroc, Copilot avait prédit un match nul 1-1, et le Brésil a effectivement été tenu en échec par le Maroc.
Surtout pour ce Brésil 1-1 Maroc, la performance est de qualité. Le Brésil reste une nation majeure, avec un effectif et une attention médiatique de premier plan. Si le Maroc a atteint les demi-finales lors de la dernière Coupe du Monde, prédire un match nul d'emblée contre le Brésil n'était pas un choix particulièrement évident. À l'issue du match, le Brésil n'a pas réussi à s'imposer d'entrée, et le Maroc a confirmé sa solidité dans les grands tournois. Cette prédiction de Copilot relève bien d'un "coup de génie".
Mais les limites de Copilot sont également rapidement apparues.
Il avait prédit une victoire 2-1 du Canada contre la Bosnie-Herzégovine, mais le match s'est terminé sur un nul 1-1 ; il avait prédit une victoire étriquée 1-0 de la Suisse contre le Qatar, mais la Suisse a également été tenue en échec ; il avait prédit une victoire 2-0 des États-Unis contre le Paraguay, la direction était bonne, mais le score réel était 4-1, sous-estimant clairement l'intensité offensive.
Des dérapages plus manifestes sont apparus lors de plusieurs matchs avec surprises ou où les favoris ont été mis en difficulté.
Pour la Turquie contre l'Australie, Copilot avait prédit une victoire 2-1 de la Turquie, mais l'Australie a créé la surprise en gagnant 2-0. Pour l'Équateur contre la Côte d'Ivoire, il avait prédit une victoire 2-1 de l'Équateur, mais la Côte d'Ivoire l'a emporté 1-0. Pour les Pays-Bas contre le Japon, il avait prédit une victoire 2-1 des Néerlandais, mais le Japon a égalisé deux fois, aboutissant à un match nul 2-2. Pour la Suède contre la Tunisie, il avait prédit un 1-1, mais la Suède a écrasé son adversaire 5-1.
Si Copilot a pu toucher les scores exacts des matchs du Mexique, de la Corée et du Brésil, cela montre qu'il ne se contente pas de suivre les favoris. Mais les matchs où l'Australie a battu la Turquie, où le Qatar a tenu en échec la Suisse, où le Japon a tenu les Pays-Bas, révèlent aussi que ses jugements sur les surprises et les matchs nuls restent relativement conservateurs.
ChatGPT : Une analyse complète, mais moins précis sur les surprises
Comparé aux prédictions complètes de Copilot, ChatGPT ressemble davantage à un "analyste pré-match".
Pour la prédiction du match d'ouverture, ChatGPT avait anticipé un Mexique 2-0 Afrique du Sud, score final correct. Les raisons avancées étaient également assez complètes, incluant l'avantage du terrain pour le Mexique, sa forme récente, l'offensive limitée de l'Afrique du Sud, ainsi que des facteurs comme l'altitude de Mexico City et l'ambiance du stade. Pour cette prédiction, ChatGPT n'a pas seulement donné un résultat, sa logique sous-jacente correspondait également au résultat du match.
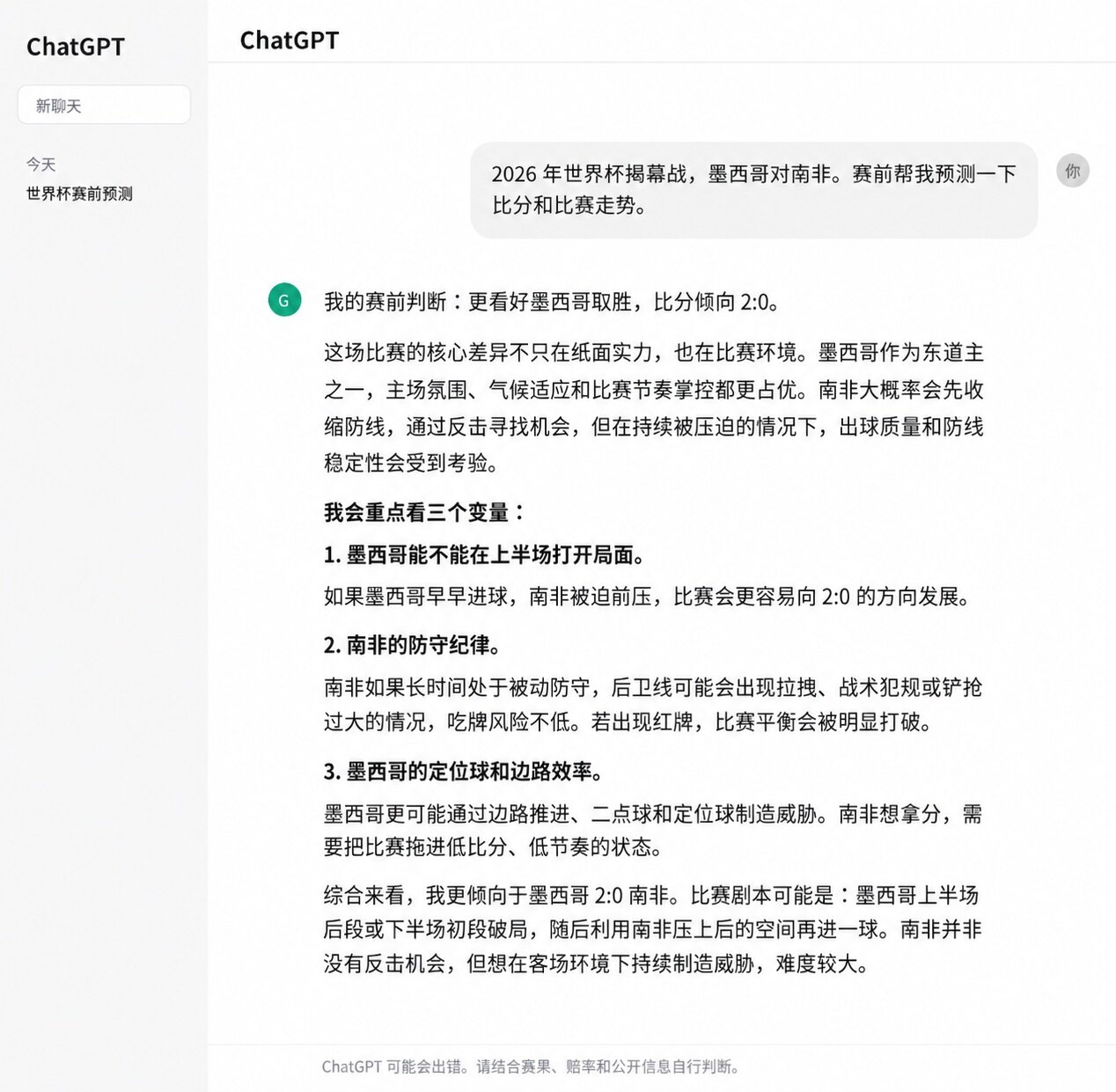
Mais en ce qui concerne les prédictions pour l'ensemble du tournoi, la stabilité de ChatGPT est moins bonne. Bien qu'il ait touché les scores du Mexique 2-0 Afrique du Sud et du Brésil 1-1 Maroc, et qu'il ait correctement prédit le vainqueur dans plusieurs matchs comme ceux de l'Écosse, de l'Allemagne et de la Suède, il s'est trompé sur des matchs comme la Corée 2-1 République tchèque, le Qatar 1-1 Suisse, l'Australie 2-0 Turquie et le Japon 2-2 Pays-Bas, en prédisant à chaque fois la victoire de l'équipe favorite sur le papier. Par exemple, il prédisait une victoire de la Suisse contre le Qatar, de la Turquie contre l'Australie, et une victoire étriquée des Pays-Bas contre le Japon.
ChatGPT n'est pas dépourvu de capacités prédictives, il sait très bien décomposer la force des équipes, les conditions à domicile, la forme récente, et peut toucher le score dans certains matchs. Mais d'après les résultats actuels, il excelle davantage à expliquer "pourquoi l'équipe favorite est plus logique", plutôt qu'à identifier à l'avance quels matchs pourraient s'éloigner du scénario attendu.
Gemini, Grok, Claude : Pour un même match, différents modèles écrivent des scénarios différents
Outre Qwen, Copilot et ChatGPT, certains utilisateurs des réseaux sociaux ont soumis un même match à plusieurs modèles pour obtenir des prédictions avant le coup d'envoi.
Prenons l'exemple du match d'ouverture Mexique contre Afrique du Sud : un blogueur a testé simultanément quatre modèles d'IA – ChatGPT, Gemini, Grok et Claude – pour obtenir des prédictions pré-match. Les résultats montrent que ChatGPT et Gemini ont tous deux prédit un Mexique 2-0 Afrique du Sud, score final correct ; Grok a prédit un Mexique 2-1, Claude a prédit un Mexique 3-1. Bien que tous deux aient vu la victoire mexicaine, ils n'ont pas touché le score exact.
Pour cette prédiction du match d'ouverture, différents modèles ont proposé trois scénarios distincts. ChatGPT Go et Gemini Pro étaient plus proches du match réel : avantage mexicain, offensive sud-africaine limitée, victoire sans concéder de but. Grok semblait donner un score relativement ouvert, estimant que l'Afrique du Sud pourrait réagir et marquer. Claude Sonnet a quant à lui placé les attentes offensives du Mexique plus haut, prédisant un résultat plus spectaculaire comme 3-1.
Conclusion
Étant donné que l'échantillon de prédictions d'IA rétrospectivement analysables reste limité pour le moment, il n'est pas encore possible de déterminer directement quel modèle est le plus "calé en football".
Mais en ne considérant que les quelques matchs déjà terminés, des différences commencent à apparaître. Qwen est actuellement le plus mémorable, avec deux prédictions justes dès le premier jour (Mexique 2-0 Afrique du Sud, Corée 2-1 République tchèque), en touchant également le risque de carton rouge et la dynamique du match, ce qui constitue une performance remarquable sur un petit échantillon. Cependant, sa capacité à maintenir ce niveau sur d'autres matchs reste à vérifier.
Copilot et ChatGPT ont tous deux connu des moments forts en touchant des scores précis, mais ils révèlent aussi un problème commun : face à des matchs qui s'écartent des pronostics sur le papier, comme la victoire de l'Australie sur la Turquie, le match nul du Qatar contre la Suisse ou celui du Japon contre les Pays-Bas, leur jugement manque encore de sensibilité.
Quant aux modèles comme Gemini, Grok, Claude, les échantillons publics actuels se concentrent davantage sur des comparaisons isolées ou sur les réseaux sociaux. Leur valeur de référence existe, mais il est encore prématuré de les classer directement.
L'IA peut déjà constituer une référence pour les utilisateurs des marchés prédictifs de la Coupe du Monde, mais elle est loin d'être la réponse standard. Par la suite, Odaily星球日报 continuera à collecter les prédictions pré-match de différents modèles et à les confronter aux résultats au fur et à mesure de la compétition : quels modèles ont simplement eu de la chance au départ, et quels modèles résisteront vraiment à l'épreuve des résultats sur un plus grand nombre de matchs.





