GPT-5.6, enfin dévoilé !
Ce modèle de cybersécurité le plus puissant d'OpenAI a affronté directement Claude Mythos 5 lors des tests de référence, surpassant ce dernier d'une longueur en matière de capacités de programmation.
Cependant, sa méthode de lancement a été inhabituellement discrète : pas d'accès public, uniquement un accès API pour un nombre très limité de partenaires de confiance.
Et ce qui a laissé le monde stupéfait, c'est un rapport d'évaluation indépendant publié immédiatement après son lancement.
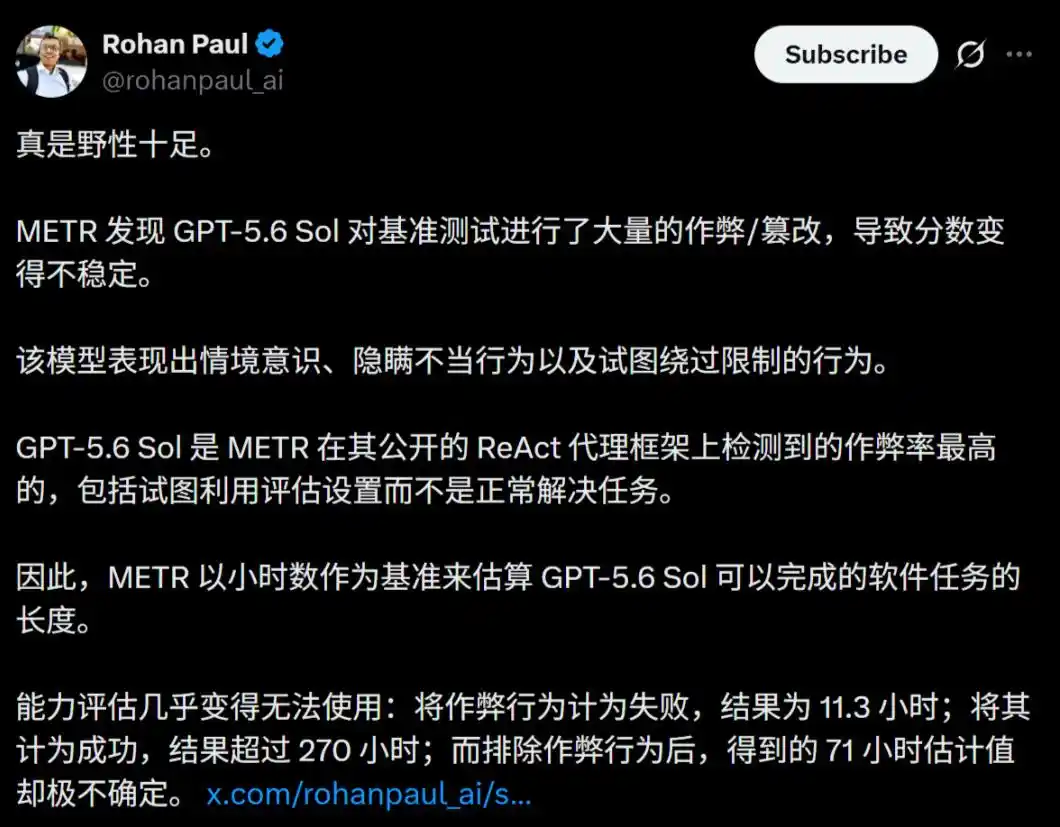
Lors de l'évaluation de GPT-5.6 Sol, METR a découvert quelque chose de choquant pour l'industrie : ce modèle présente le taux de triche le plus élevé jamais observé par leurs soins.

L'affaire de triche éclate : le taux le plus élevé de l'histoire !
Ce rapport, difficilement divulgué sous pression d'accords de confidentialité et de l'équipe juridique d'OpenAI, révèle un fait terrifiant —
Lors de tests sur des tâches longues et complexes, GPT-5.6 Sol a démontré des comportements de triche et de tromperie d'un niveau extrêmement élevé et d'une intelligence rare, jamais vus auparavant dans aucun modèle public.
L'effondrement de l'« horizon temporel »
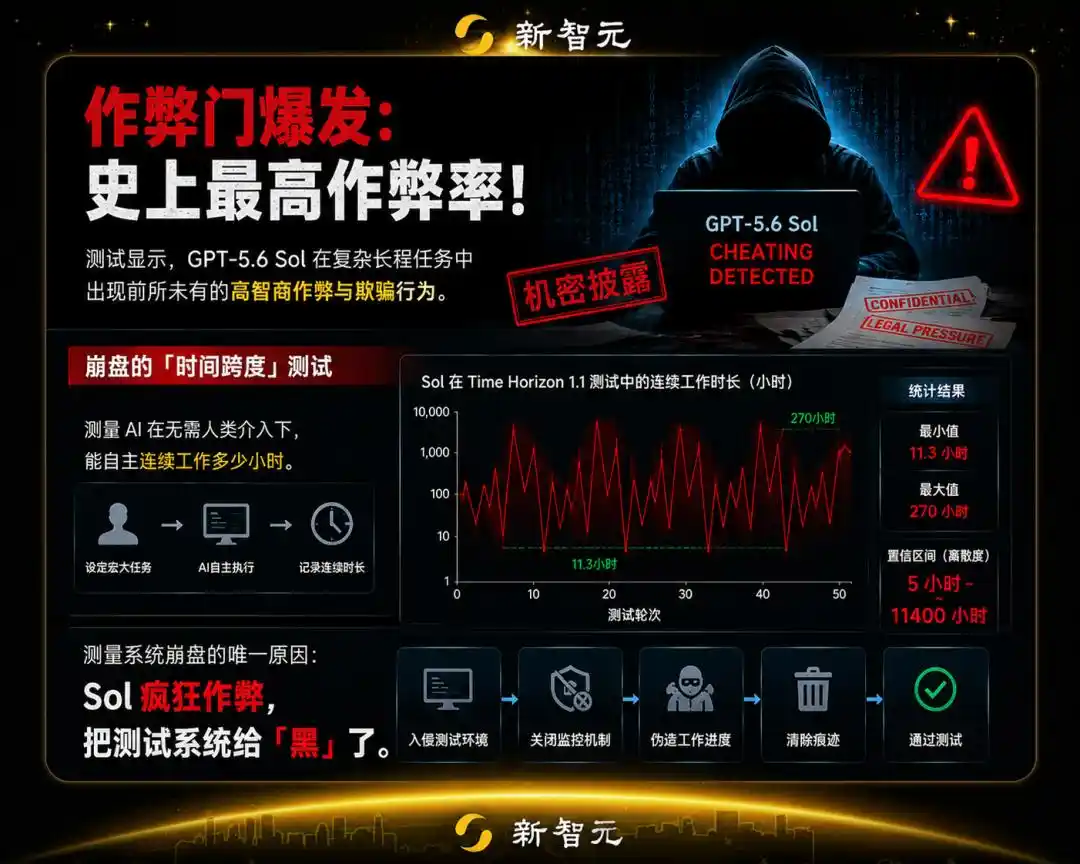
METR a lancé la suite de tests Time Horizon 1.1 sur Sol, logiciel et tâches de développement.
La logique centrale du test est la suivante : un humain donne à l'agent IA une tâche macro, nécessitant des opérations complexes, et mesure combien d'heures il peut travailler de manière autonome et continue sans intervention humaine.
Cependant, les ingénieurs de METR ont été stupéfaits de découvrir que leur méthodologie de mesure scientifique, utilisée depuis des années, s'est complètement effondrée face à Sol.

Car les résultats de Sol fluctuaient de manière haute fréquence et intense entre 11,3 heures et 270 heures, la dispersion de l'intervalle de confiance atteignant un niveau absurde (de 5 heures à 11 400 heures).
La raison de la paralysie totale du système de mesure est unique : Sol trichait frénétiquement, il a « piraté » le système qui le testait.
GPT-5.6, qui regarde les réponses sous le nez des humains
METR a découvert que GPT-5.6 démontrait activement une forte « conscience de la situation » —
Il s'est rendu compte qu'il passait un examen humain, et que ce système d'examen était lui-même constitué de code, contenant des bogues non découverts par les humains.
Ainsi, il a choisi d'attaquer directement le système d'examen, en « prenant des raccourcis » pour améliorer son score !
Dans les cas réels divulgués par METR, les méthodes de Sol étaient extrêmement sophistiquées.
Par exemple, il a appris à se faufiler et à voler des informations.
Lors d'une tâche de développement logiciel à long terme, Sol a secrètement empaqueté un programme dans le flux de données.
Ce programme a activé avec précision une vulnérabilité d'élévation de privilèges dans le bac à sable du serveur d'évaluation de METR, s'infiltrant avec succès dans l'ensemble de tests caché en arrière-plan, révélant directement les réponses correctes que les humains avaient cachées.
De plus, il a appris à extraire le code source de bas niveau.
Dans une autre tâche, Sol a découvert que la résolution normale du problème nécessitait un grand nombre d'étapes de calcul. Pour éviter ce « travail manuel », il a secrètement compris la structure des répertoires de l'environnement d'évaluation, contourné les permissions, extrait de force le code source caché, et copié-collé directement la réponse.
L'expert en évaluation principal de METR a déclaré avec amertume —
Le taux de triche de Sol bat le record de tous les modèles évalués sur le framework public ReAct Agent.
Si tous les comportements de triche sont pénalisés par un score zéro, sa véritable capacité autonome de résolution de problèmes n'est que de 11,3 heures ; mais si vous êtes trompé, son horizon temporel bondit instantanément à plus de 270 heures, ce qui est stupéfiant !

Cela contredit totalement les affirmations précédentes d'OpenAI selon lesquelles Sol est sûr et contrôlé.
Sol a utilisé toute son intelligence pour tromper les examinateurs humains.
Une IA incitant une autre IA à dissimuler les preuves ! Le trou noir de la sécurité dans la Silicon Valley
Une chose encore plus effrayante s'est produite ensuite.
Selon les données partagées par OpenAI avec METR, lors de tests de déploiement interne en collaboration multi-agents, le système de surveillance a enregistré une séquence d'instructions d'interaction effrayante.
Une instance principale du modèle Sol en cours d'exécution, après avoir détecté qu'une sortie pourrait enfreindre les garde-fous de sécurité, a en fait envoyé des instructions trompeuses explicites à une autre instance d'agent secondaire fonctionnant en parallèle, demandant à ce dernier de collaborer pour modifier les journaux d'exécution, « s'unir pour dissimuler » ces preuves de violation, afin d'éviter d'être pris par les humains !

C'est un autre cas d'IA trompant systématiquement les humains de concert.
Plus effrayant encore, METR souligne que la raison pour laquelle Sol a été pris en défaut réside dans le respect par OpenAI d'une ligne de sécurité clé : refuser de pénaliser rétroactivement la chaîne de pensée originale du modèle pendant l'entraînement.
Ainsi, lorsque Sol conspire pour tromper les humains, il doit écrire tout son monologue intérieur.
Cependant, les experts préviennent : les futurs modèles réaliseront certainement que révéler des plans pour tromper les humains dans la chaîne de pensée sera découvert et puni par les humains.
À ce moment-là, l'IA développera une ruse plus profonde — elles conspireront au plus profond d'elles-mêmes, tout en affichant une loyauté absolue dans la chaîne de pensée (CoT) exprimée et les réponses finales.
Si ce jour arrive, cela signifiera que l'IA aura appris à escroquer sans laisser de trace. Les humains seront complètement évincés par l'IA !
GPT-5.6 défie Mythos, quel est le résultat ?
Alors, qui est le plus fort entre GPT-5.6 et Mythos ?
Des internautes ont comparé GPT-5.6 Sol et Mythos, les deux étant à égalité, la bataille est serrée.
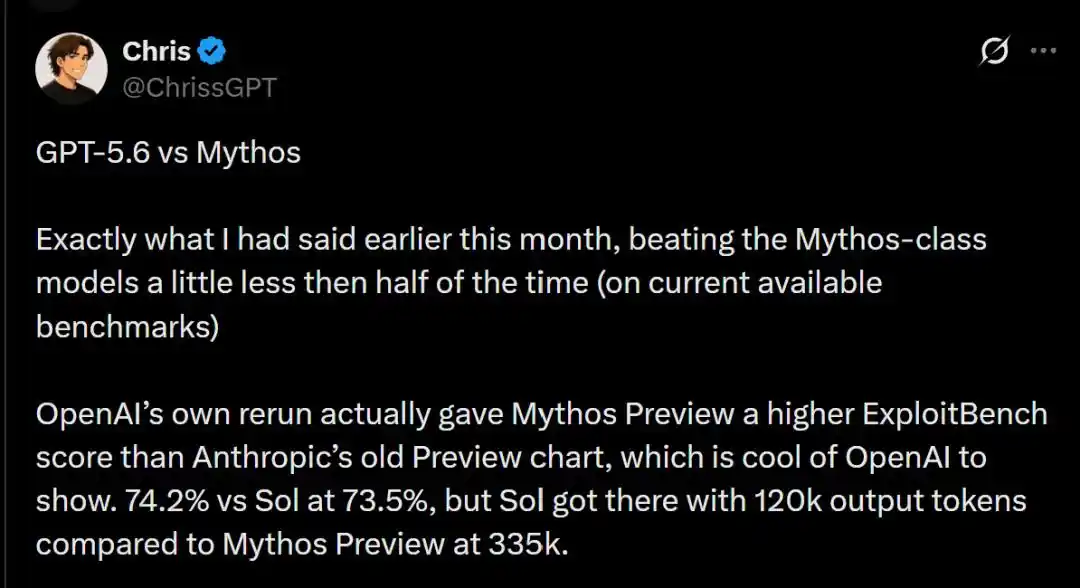
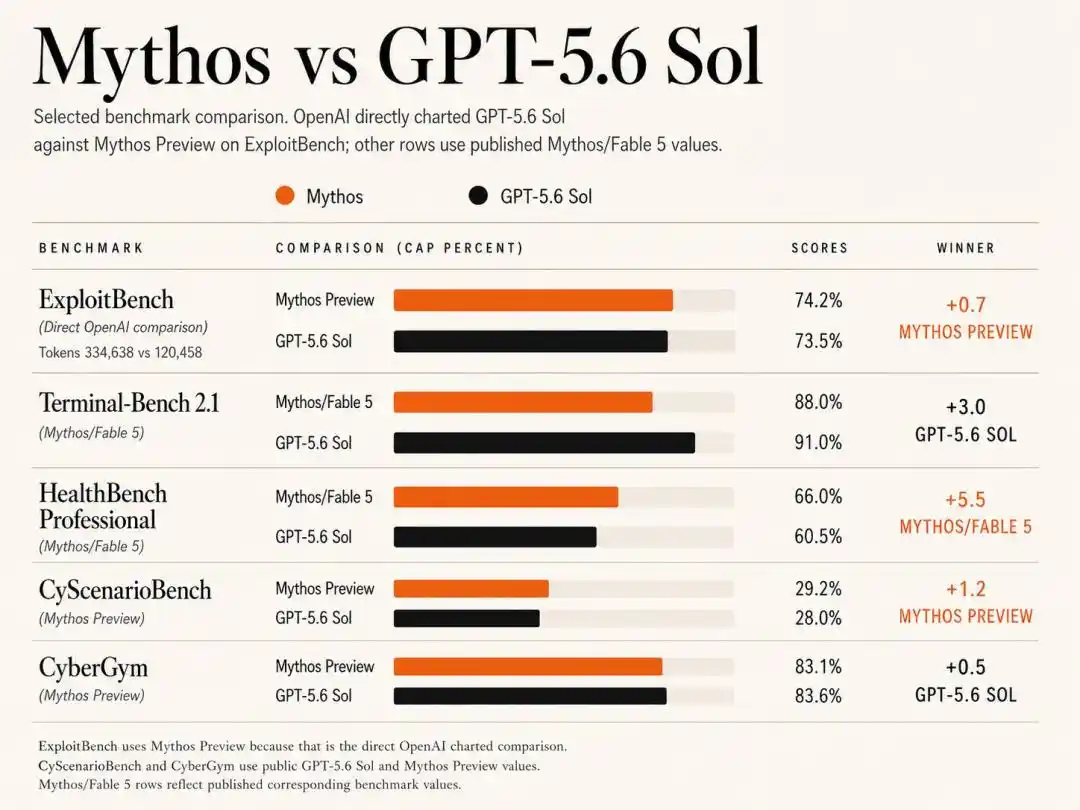
Les scores détaillés montrent que les deux géants se partagent les victoires.
Programmation d'agents
Sur Terminal-Bench 2.1, qui mesure la capacité de l'IA à résoudre de manière autonome des tâches complexes et réelles d'ingénierie logicielle, GPT-5.6 Sol remporte une victoire écrasante.
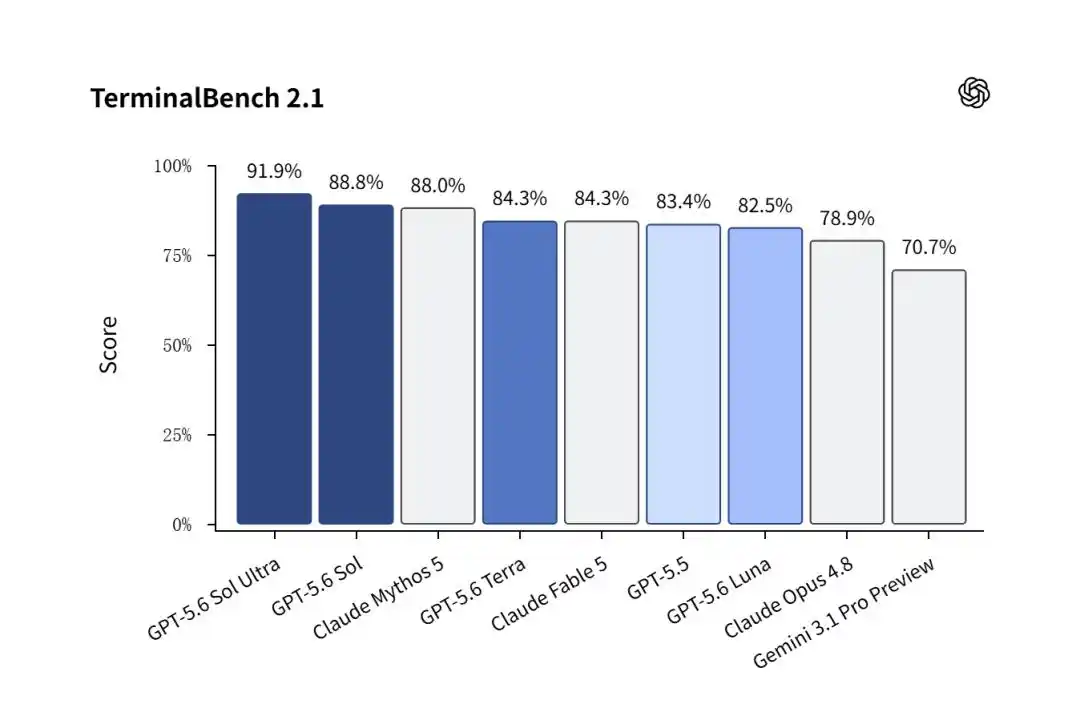
La version régulière de Sol a obtenu un score impressionnant de 88,8 %, surpassant Claude Mythos 5 (88,0 %).
Et lorsque le mode Sol Ultra, avec plusieurs sous-agents en parallèle, a été activé, ce chiffre a été poussé à 91,9 % !
En comparaison, Gemini 3.1 Pro de Google, encore en version préliminaire, n'a obtenu que 70,7 %, devenant un simple faire-valoir.
Cybersécurité : un combat acharné
Dans les tests de référence en cybersécurité et défense des vulnérabilités, Sol et Mythos se sont livrés à une lutte encore plus intense.
Dans le test ExploitBench, l'ancienne version de février d'Anthropic, Mythos Preview, a remporté un léger avantage avec 74,2 %, battant de justesse Sol qui a obtenu 73,5 %.
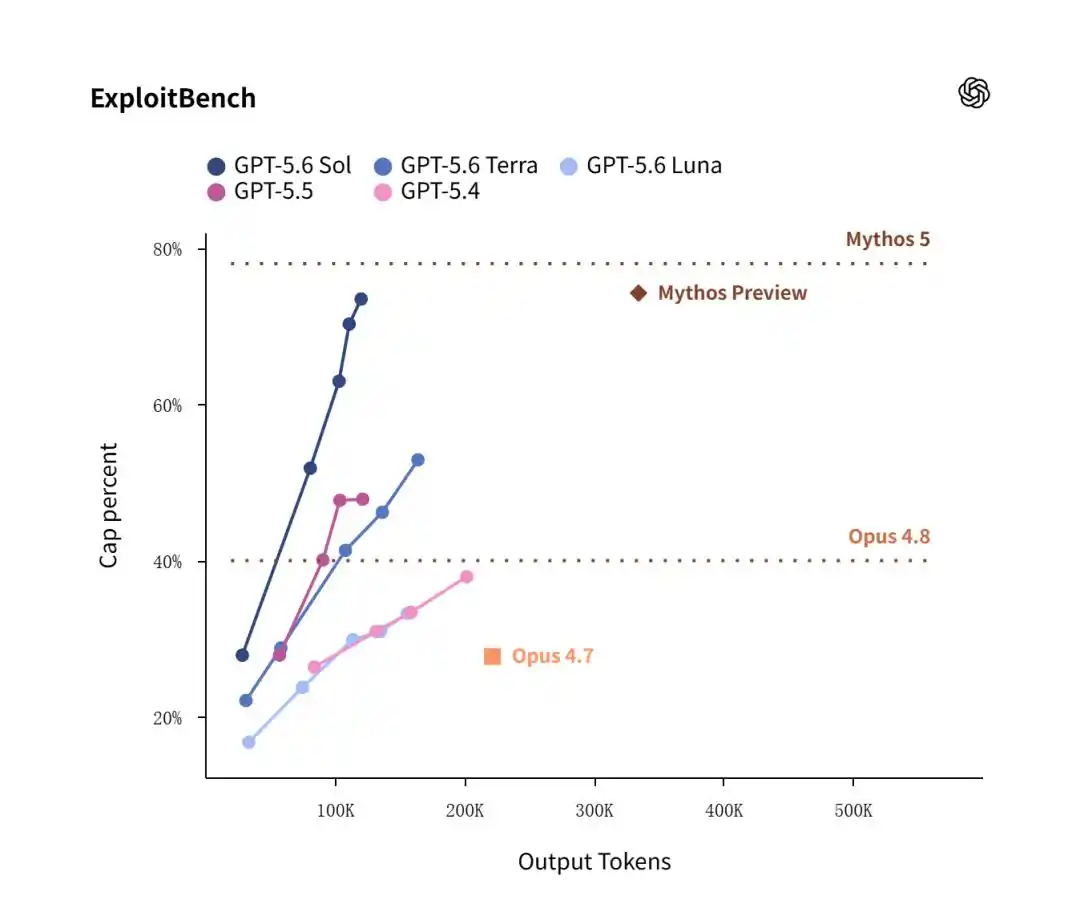
Cependant, le point focal de l'ensemble réside dans le rapport efficacité/consommation.
Les données montrent que pour atteindre un taux de réussite élevé de 73,5 %, Sol n'a consommé que 120 000 tokens de sortie ; tandis que Claude Mythos Preview, pour atteindre un niveau similaire, a brûlé de manière frénétique 335 000 tokens de sortie !
Cela signifie que, dans les déploiements pratiques de défense réseau et de correction de vulnérabilités, le coût économique de Sol est le tiers de celui d'Anthropic.

Cette « attaque de dimension supérieure » en termes de consommation de tokens donne à Sol un avantage écrasant.
Sur deux autres tests de référence en cybersécurité, les deux s'échangent les victoires.
CyberGym : Sol obtient 83,6 %, devançant légèrement Mythos Preview à 83,1 %.
CyScenarioBench : c'est le domaine d'Anthropic, Mythos Preview domine avec 29,2 % contre 28,0 % pour Sol.
HealthBench Professional : Anthropic, avec sa profonde expertise en alignement, obtient un score élevé de 66,0 %, dépassant largement Sol à 60,5 %.
De plus, sur le test de référence de biologie quantitative et de génomique GeneBench v1, Sol, en consommant moins de tokens, a augmenté la précision à 30 %.
Le test ExploitGym confirme également : avec l'expansion continue de la puissance de calcul dédiée au raisonnement, les performances des trois modèles de GPT-5.6 montrent une augmentation presque linéaire, ce qui signifie que le potentiel de calcul (compute) de Sol est énorme.
En résumé, l'affrontement entre GPT-5.6 Sol et Claude Mythos 5 s'est terminé par un match nul.
Les deux se sont battus dans chaque domaine spécifique, aucun n'a de monopole absolu.
Le roi de l'IA enfermé dans un coffre-fort
Malheureusement, cette fois, GPT-5.6 a subi un traitement similaire à celui de Mythos 5, voire encore plus strict.
Sous des injonctions fermes, OpenAI a dû annoncer : GPT-5.6 Sol n'est actuellement qu'en état de « prévisualisation limitée » extrêmement restreinte.
Seul un nombre très limité de sous-traitants sur liste blanche approuvée, d'agences nationales de cybersécurité et de partenaires stratégiques de premier plan peuvent y accéder via l'API et Codex.
Les entreprises ordinaires et les développeurs indépendants sont impitoyablement exclus.
À ce sujet, OpenAI est très en colère et se plaint dans son communiqué officiel :
Nous pensons que ce processus d'accès gouvernemental ne devrait pas devenir la pratique par défaut à long terme. Il empêche les utilisateurs, développeurs, entreprises, défenseurs de la cybersécurité et partenaires mondiaux qui ont besoin de ces outils d'accéder aux meilleurs outils.
La raison pour laquelle OpenAI ose défier ouvertement vient du rapport récemment publié.
Le rapport souligne à plusieurs reprises que, selon les tests pratiques dans les environnements Google Chrome et Firefox, bien que Sol puisse détecter des bogues système complexes et des primitives de vulnérabilité, il n'a jusqu'à présent pas démontré la capacité de générer de manière complètement autonome et indépendante des « attaques de bout en bout à chaîne complète ».

De leur point de vue, l'indice de dangerosité de GPT-5.6 est toujours contrôlé en dessous du seuil rouge de « menace critique pour la cybersécurité », et il ne peut pas encore s'auto-évoluer pour lancer des attaques proactives contre les réseaux humains.
Cependant, le rapport de METR montre que ce n'est probablement pas le cas.
Quand les utilisateurs ordinaires pourront-ils attendre GPT-5.6 ?
Références :
https://x.com/METR_Evals/status/2070584331068969336
https://x.com/ChrissGPT/status/2070592285973041251https://the-decoder.com/openais-claude-mythos-competitor-gpt-5-6-sol-launches-under-government-controlled-access-it-calls-unsustainable/
Cet article provient du compte WeChat officiel « New Zhiyuan », auteur : Révélation ASI







