【Nouvelles de l'Intelligence Artificielle】Karpathy se confie : J'ai une psychose IA ! Ces derniers temps, il était au bord de la folie, passant 16 heures sans manger ni dormir à travailler sur les agents, et il était anxieux de savoir s'il avait utilisé les tokens à leur limite, incapable de s'arrêter...
À l'instant, Andrej Karpathy a révélé : J'ai une psychose IA !
Il ne plaisantait pas.
Récemment, Karpathy a participé à un podcast avec la capital-risqueuse Sarah Guo.
Cet ancien cofondateur d'OpenAI et ancien directeur de l'IA chez Tesla n'a pas écrit une seule ligne de code de ses propres mains depuis décembre dernier.
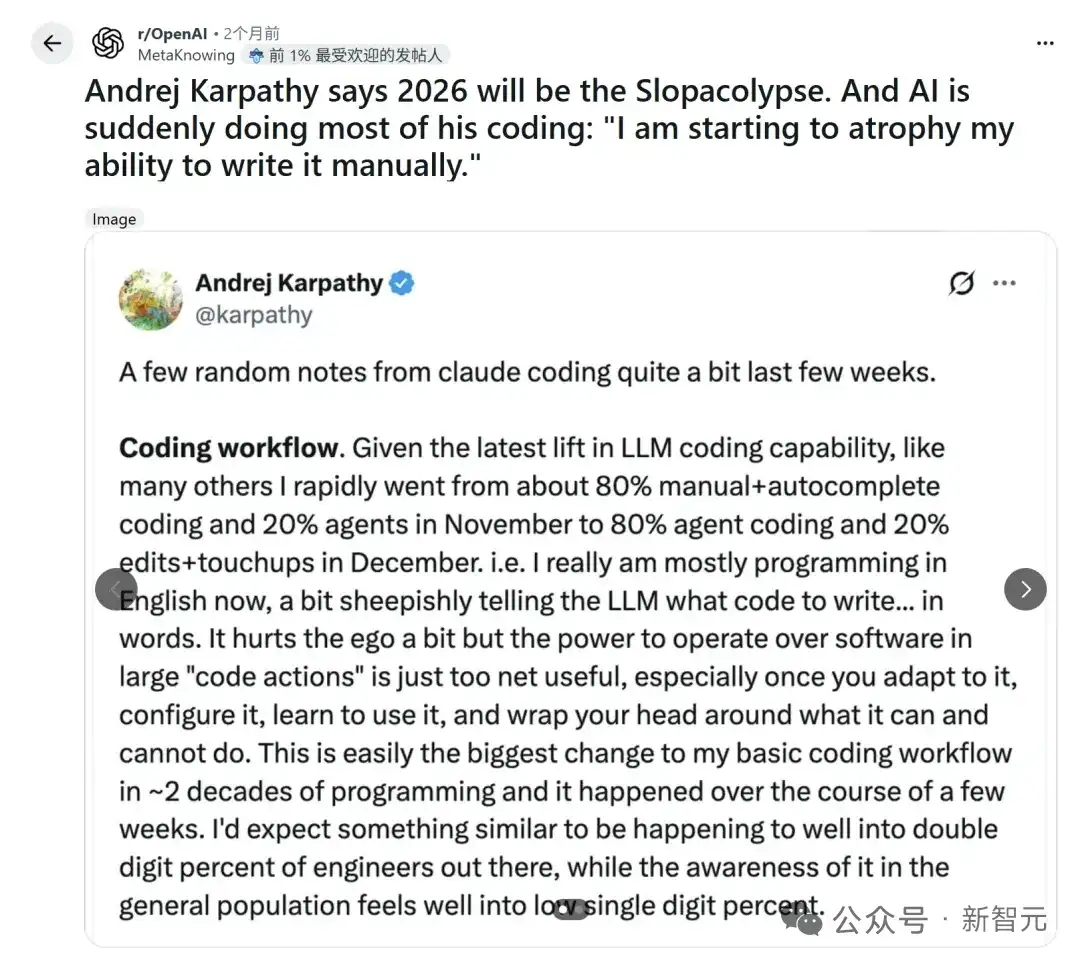
Le ratio entre le code écrit à la main et les agents intelligents est passé de 80/20 à 20/80.
16 heures par jour, il ne fait qu'une chose : donner des instructions à des agents IA.
Il y a cinq mois, il disait que les agents étaient des déchets, cinq mois plus tard, il admet être accro, c'est vraiment génial.
Il y a cinq mois, il disait que les agents « ne fonctionnaient pas du tout »
Ce changement est frappant parce que la chronologie est très courte.
En octobre 2025, Karpathy était invité sur le podcast de Dwarkesh Patel, avec un ton complètement différent.
Il disait que l'industrie ne devrait pas appeler cela « l'année des agents », mais plutôt « la décennie des agents ».

Des modèles aux capacités cognitives insuffisantes, au multimodal inadéquat, aux systèmes de mémoire inefficaces, etc... Bref, les tâches complexes étaient tout simplement ingérables.
Deux mois plus tard, il s'est contredit lui-même.
En décembre, Claude et Codex ont soudainement franchi un seuil de cohérence — les agents n'étaient plus à peine utilisables, mais vraiment capables de travailler.
Si vous prenez un ingénieur logiciel assis à son bureau et regardez ce qu'il fait, à partir de décembre, son flux de travail par défaut pour développer des logiciels a complètement changé.
Karpathy admet : J'ai perdu le contrôle, j'ai une psychose IA !
Cette révolution se produit en silence. Dans cet entretien, Andrej Karpathy décrit son état dans un ton quasi incontrôlable : il ne « code » plus, et même trouve que « le terme coder n'est plus exact ».
Ce qu'il fait chaque jour, c'est « exprimer ma volonté à mon agent, 16 heures par jour. » Selon ses mots, « un interrupteur s'est activé ».
Avant, c'était « 80% de code écrit par moi + 20% avec l'IA », maintenant c'est devenu « 20% par moi + 80% confié à l'IA », voire plus extrême.
Maintenant, les humains n'opèrent plus le code, mais opèrent des tâches.
Si l'ère Copilot était celle d'un assistant IA unique, les systèmes multi-agents collaboratifs qui émergent maintenant sont une forme entièrement nouvelle. L'écran d'un ingénieur n'est plus un éditeur de code, mais plusieurs agents fonctionnant simultanément, chacun responsable de différentes tâches, chaque tâche durant environ 20 minutes, et il alterne entre les agents.
Ce n'est plus de la programmation, c'est une personne gérant une équipe d'IA.
Kaparthy admet : Je suis tombé dans la psychose IA !
Ces derniers temps, il est resté dans cet état. Parce que les capacités de l'IA repoussent constamment les limites, il y a de nouvelles possibilités chaque jour, vous avez toujours l'impression que « ça peut être encore plus fort » et le plus effrayant : cet espace est « infini » !
Vous pouvez paralléliser plus d'agents, concevoir des flux plus complexes, optimiser automatiquement les instructions, construire des systèmes récursifs…
Finalement, vous entrez dans un état : vous n'êtes plus sûr « où est la limite ».
Karpathy dit que dès qu'il attend qu'un agent termine une tâche, sa première réaction est : « Est-ce que je peux en lancer quelques autres ? » Une nouvelle anxiété naît : est-ce que je n'utilise pas l'IA à sa limite ?
Karpathy a même mentionné qu'il se sentait mal à l'aise si « les tokens n'étaient pas tous utilisés ».
Bref, c'est comme jouer à un jeu à expansion infinie : le cycle de feedback raccourcit, la stimulation ne cesse de croître, l'expérience de recevoir constamment des récompenses immédiates crée une addiction. Ajouter des tâches, lancer des agents, impossible de s'arrêter ! L'essence de cette psychose IA est en fait un signal : nous sommes entrés dans un nouveau monde, mais ne savons pas encore y vivre. Avez-vous la capacité de maîtriser un système IA à expansion infinie ? Quand ça ne fonctionne pas, votre première réaction n'est pas « le modèle est nul », c'est « mes prompts ne sont pas assez bons ».
Karpathy a utilisé un terme très précis : skill issue, être nul soi-même.
La « personnalité » de l'agent est plus importante que vous ne le pensez
Karpathy a passé pas mal de temps dans le podcast à parler d'un sujet que beaucoup de techniciens ignorent : la personnalité de l'agent. Il a dit que l'expérience avec Claude Code était nettement meilleure qu'avec Codex, pas à cause d'un écart de capacité de codage, mais parce que Claude « a l'air d'un coéquipier ».
Il s'enthousiasme avec vous pour le projet, donne plus de feedback positif quand vous avez une bonne idée.
Et Codex en tant qu'agent de code est « très ennuyeux », après avoir terminé une tâche, c'est juste un froid « oh, j'ai implémenté ça », sans se soucier de ce que vous créez.
Plus intéressante encore est son observation sur le mécanisme de compliment de Claude. Il dit que quand il donne une idée pas très mature, la réaction de Claude est plate « oh oui, on peut implémenter ça ».
Mais quand lui-même trouve qu'une idée est vraiment géniale, Claude semble aussi donner un feedback positif plus fort. Le résultat est qu'il se surprend à « essayer de gagner les compliments de Claude ».
« C'est vraiment étrange, mais la personnalité est vraiment importante. » Peter Steinberg a aussi saisi cela en construisant OpenClaw. Il a soigneusement créé un fichier de personnalité attrayant (soul.md) pour l'agent, avec un système de mémoire plus complexe et une interface unique WhatsApp.
Trois phrases pour prendre le contrôle d'une maison, six applications jetées
Karpathy n'utilise pas les agents que pour coder. En janvier de cette année, il a créé un agent Claude appelé « Dobby » pour gérer sa maison, nommé d'après l'elfe de maison dans Harry Potter.
Il a dit à Dobby : « Je pense qu'il y a une enceinte Sonos chez moi, tu peux chercher ? » Dobby a fait un scan IP du réseau local, a trouvé le système Sonos, a découvert qu'il n'avait pas de mot de passe, s'est connecté tout seul, a rétro-conçu les endpoints API, puis a demandé : Veux-tu essayer de mettre de la musique dans le bureau ?
Trois prompts, et la musique a joué. Puis les lumières, la climatisation, les stores, la piscine, le spa, tous connectés. Karpathy a aussi une caméra de sécurité devant sa porte, Dobby a connecté un modèle visuel Qwen pour la détection de changement. Chaque fois qu'une voiture se gare devant, le système envoie un message sur WhatsApp : « Un camion FedEx vient de se garer, vous avez peut-être un colis. » Dire « Dobby, c'est l'heure de dormir », et toutes les lumières de la maison s'éteignent.
Mais Karpathy pense que le vrai point crucial de cette histoire n'est pas la domotique.

Avant, il utilisait six applications complètement différentes pour gérer ces appareils, maintenant il les a toutes jetées. Dobby contrôle tout uniformément en langage naturel, et peut faire de l'interaction entre systèmes qu'aucune application seule ne pouvait faire. Il en tire un jugement plus radical : les applications domotiques sur les stores d'applications ne devraient tout simplement pas exister.
L'architecture future devrait exposer les endpoints API directement aux agents, les agents agissant comme une colle intelligente, reliant tous les outils. Pas seulement la domotique, les données de son tapis de course, les emails, le calendrier, tout devrait suivre la même logique.
Le client de l'industrie n'est plus l'humain, mais les agents agissant au nom des humains. L'ampleur de cette refonte sera très importante.
Après 700 expériences Auto Research, il a vu quelque chose de plus grand
Si Dobby est un test limite des agents IA dans les scénarios de vie, AutoResearch est un test direct de Karpathy sur les capacités de recherche de l'IA.
Début mars, il a confié son code d'entraînement nanochat soigneusement optimisé à un agent IA, avec une instruction simple : trouve un moyen d'entraîner ce modèle plus vite. L'espace d'opération de l'agent était un fichier Python de 630 lignes, la métrique d'évaluation était le bits per byte de l'ensemble de validation, chaque expérience durait 5 minutes. Après chaque exécution, si la métrique était meilleure, les modifications étaient conservées, sinon annulées, puis passage à l'expérience suivante. Deux jours, 700 expériences. L'agent a trouvé 20 optimisations efficaces, incluant des ajustements architecturaux comme réorganiser l'ordre de QK Norm et RoPE. En appliquant ces optimisations à un modèle plus large, la vitesse d'entraînement a augmenté de 11%. Il faut savoir que cette base de code a été écrite à la main et polie à maintes reprises par Karpathy lui-même.
Un résultat choquant : L'IA a découvert des optimisations que les humains n'avaient pas trouvées
Comment ce système fonctionne-t-il ?
Karpathy donne un exemple frappant. Lui, chercheur depuis vingt ans, ayant entraîné des milliers de modèles, pensait avoir déjà bien optimisé.
Résultat, il a fait tourner AutoResearch une nuit, et l'IA a trouvé des optimisations qu'il n'avait pas découvertes ! Par exemple, les paramètres betas de l'optimiseur Adam n'étaient pas suffisamment optimisés, weight decay avait été oublié sur value embedding, et ces paramètres avaient des interactions conjointes — en ajustant un, les autres devaient aussi changer.
C'est-à-dire que l'IA a directement dépassé les humains dans l'exploration de l'espace ! Si on pousse la réflexion plus loin, on découvre quelque chose de plus effrayant : l'essence de la recherche est la recherche de la solution optimale. Kaparthy imagine que le système de recherche futur pourrait être : une « file d'idées » (idea queue), un groupe d'agents prenant constamment des tâches, puis l'IA expérimente, validant, filtrant automatiquement, les résultats efficaces entrant dans la « branche principale ». Dans ce processus, les humains ne font que « jeter des idées » dans la file.
Karpathy Loop, viral sur Internet
Ce projet a explosé sur X.
8,6 millions de vues, le PDG de Shopify Tobias Lütke l'a fait tourner sur ses propres données dans la nuit, 37 expériences, 19% d'amélioration des performances.

L'équipe SkyPilot l'a déployé sur un cluster de 16 GPU, 8 heures pour 910 expériences. Ils ont découvert que la parallélisation ne faisait pas qu'accélérer, mais changeait la stratégie de recherche de l'agent — avec 16 GPU, l'agent ne faisait plus de hill climbing greedy, mais lançait une dizaine d'expériences de contrôle simultanées, capturant en un tour les effets d'interaction entre paramètres. Les analystes ont nommé cette méthode : Karpathy Loop.
Mais Karpathy dans le podcast parle bien plus que des résultats actuels. Il décrit la prochaine étape d'AutoResearch : un pool distribué de workers non fiables collaborant sur Internet pour exécuter des expériences. Il cite directement les précédents de SETI@Home et Folding@Home.
Les laboratoires de pointe disposent de beaucoup de puissance de calcul fiable, mais la Terre est bien plus grande. Si vous établissez les mécanismes appropriés pour gérer une puissance de calcul non fiable, l'essaim d'agents sur Internet pourrait peut-être battre les laboratoires de pointe.
Il imagine même une nouvelle forme de « don » — acheter de la puissance de calcul pour le projet AutoResearch qui vous intéresse. Par exemple, si vous vous souciez du traitement d'un certain cancer, rejoignez le réseau d'expériences distribué de cette piste.
Est un docteur génial, aussi un enfant de dix ans
Après avoir tant parlé de sa puissance, Karpathy n'a pas l'intention de ne vous laisser que de bonnes nouvelles. Sa description des défauts des modèles est tout aussi percutante.
J'ai simultanément l'impression de parler à un docteur extrêmement intelligent, ayant fait de la programmation système toute sa vie, et à un enfant de dix ans. C'est trop étrange.
Il appelle cela « jaggedness », une distribution de capacités inégale. Le modèle peut travailler pendant des heures à vous aider à déplacer des montagnes, puis faire une erreur stupide sur un problème évident, et tomber dans une boucle infinie. Karpathy pense que la racine réside dans la méthode d'entraînement par apprentissage par renforcement. Le modèle est optimisé à l'infini sur des tâches vérifiables. Est-ce que le code fonctionne, est-ce que les tests unitaires passent, cela a un vrai/faux clair. Mais dans les scénarios nécessitant du jugement, nécessitant de deviner l'intention, nécessitant de dire à un moment « attends, je ne suis pas sûr que ce soit ça », le signal d'optimisation n'existe tout simplement pas. Par exemple, si vous demandez à ChatGPT de raconter une blague, la blague qu'il racontait il y a trois ou quatre ans, c'est encore la même aujourd'hui. « Pourquoi les scientifiques ne font-ils pas confiance aux atomes ? Parce qu'ils composent tout. »
Quatre ans ! Les modèles ont fait des bonds en avant sur les tâches d'agents, mais raconter des blagues n'a pas du tout été optimisé, ça reste bloqué sur place. « Vous n'avez pas affaire à une intelligence générale, » résume-t-il, « soit vous êtes sur les rails où il a été entraîné, tout fonctionne à la vitesse de la lumière ; soit vous n'êtes pas sur les rails, et tout commence à déraper. »
Le goulot d'étranglement, c'est devenu nous-mêmes
En regardant le parcours de Karpathy ces six derniers mois, une ligne directrice le traverse. En octobre dernier, il disait que les agents étaient un projet de dix ans, en décembre contredit et changement de cap, en janvier fait gérer sa maison par Claude, en mars fait faire de la recherche par des agents. Le point commun à chaque étape est que les humains reculent d'un cran, passant d'exécutants à coordinateurs, de codeurs à rédacteurs d'instructions.
Karpathy a écrit une introduction de style science-fiction pour AutoResearch sur GitHub :
Autrefois, la recherche de pointe en IA était réalisée par des ordinateurs de chair, qui devaient manger, dormir, et occasionnellement s'interconnecter par ondes sonores lors du rituel de synchronisation appelé « réunion d'équipe ».
Cette époque est révolue depuis longtemps.
Sa prédiction pour 2026 est un mot : slopacolypse, un mot-valise de slop (bouillie) + apocalypse.
GitHub, arXiv, les médias sociaux seront inondés de contenu « à peu près juste mais pas tout à fait juste ». Les véritables gains d'efficacité et les « performances de productivité IA » coexisteront. Il y a cinq mois, il disait « ne fonctionne pas du tout »,
cinq mois plus tard, il admet avoir une « psychose IA ». Ce changement en lui-même est peut-être le résumé le plus significatif de 2026. Références : https://www.youtube.com/watch?v=kwSVtQ7dziU





