C'est aujourd'hui que le dernier classement de Code Arena est tombé !
Qwen3.7-Max, avec un score de 1541 points, s'empare de la quatrième place mondiale, surpassant d'un coup une série de modèles de pointe comme GPT-5.5 et Gemini 3.5 Flash.
Devant lui, il ne reste plus que Claude Opus 4.7 et Opus 4.6.
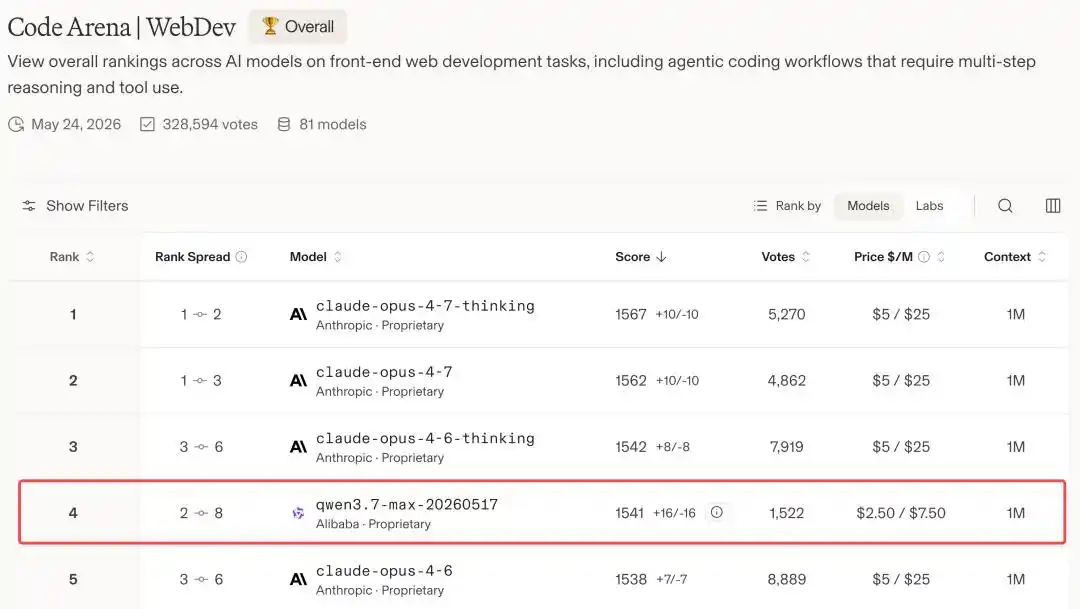
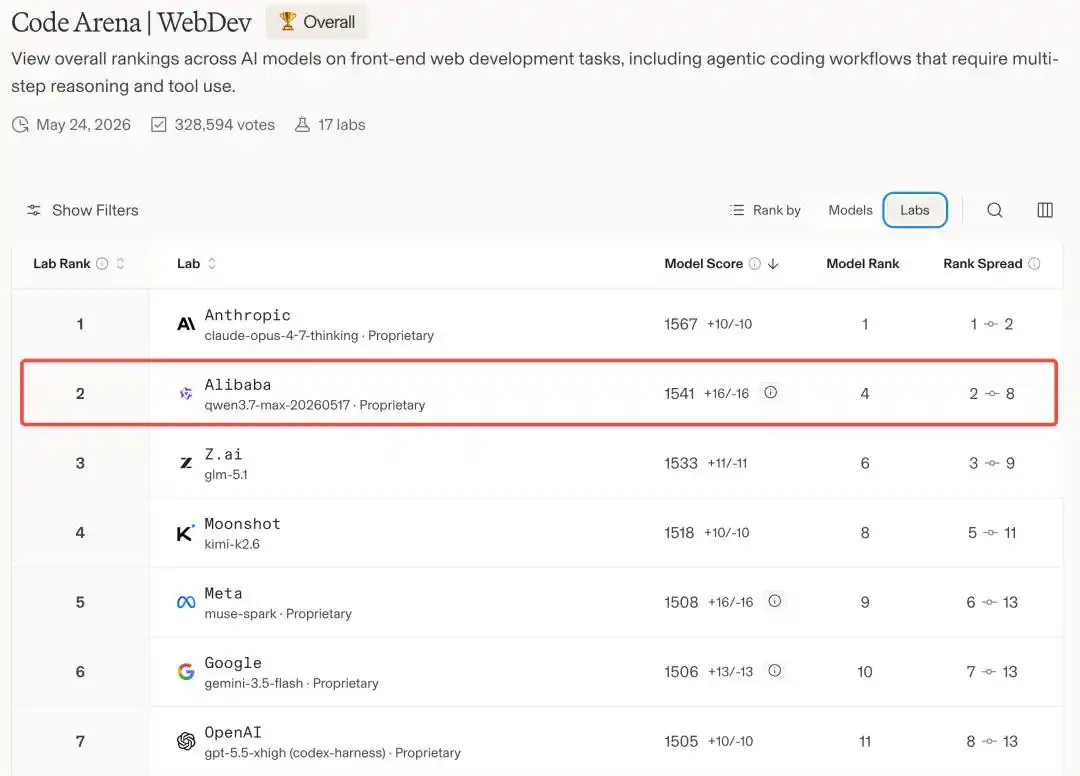
En d'autres termes, sur l'arène mondiale des modèles de programmation, Alibaba est le seul acteur chinois à avoir réussi à intégrer cette table de jeu, se positionnant deuxième derrière Anthropic.
Qwen3.7-Max s'introduit dans le top cinq mondial
Le seul modèle non-Claude
En fait, avant même la publication du classement de Code Arena, Qwen3.7-Max s'était déjà fait un nom parmi les développeurs internationaux.
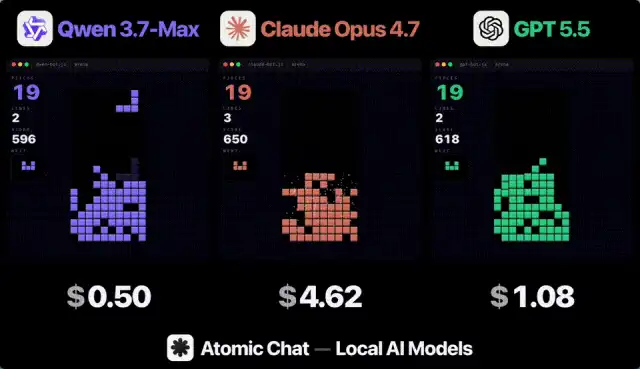
Atomic Chat a organisé une confrontation directe, mettant aux prises Opus 4.7, GPT-5.5 et Qwen3.7-Max, avec pour mission de créer une IA auto-apprenante pour Tetris.
Résultat, Qwen3.7-Max a non seulement surpassé Opus 4.7 et GPT-5.5 avec un coût en tokens de seulement 1,32 $, mais a également amélioré les performances de 56%.
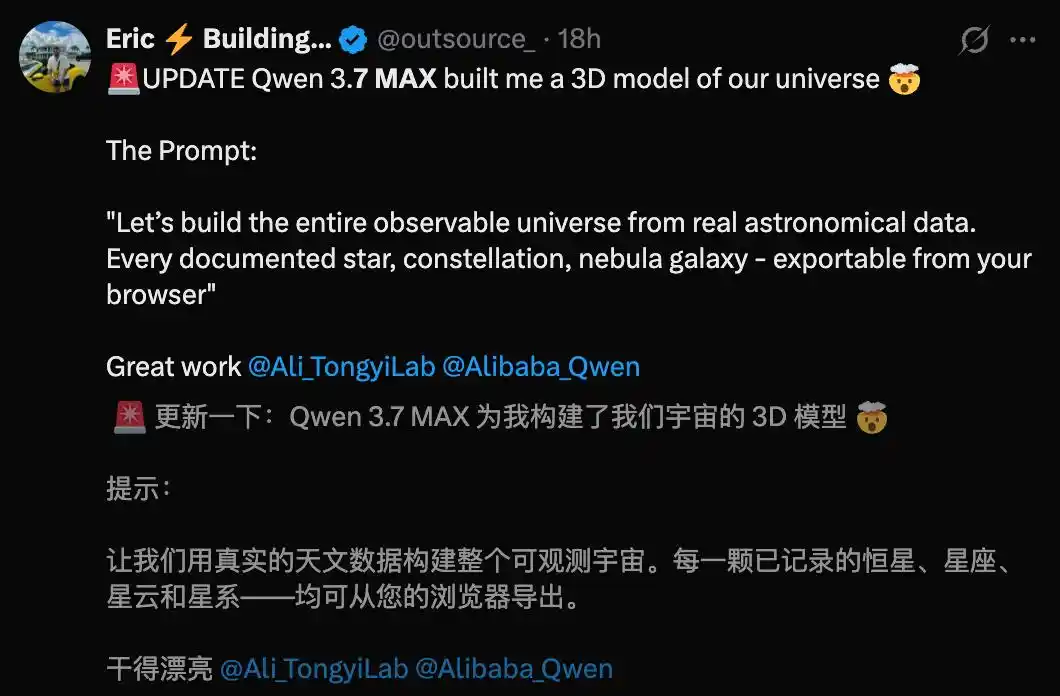
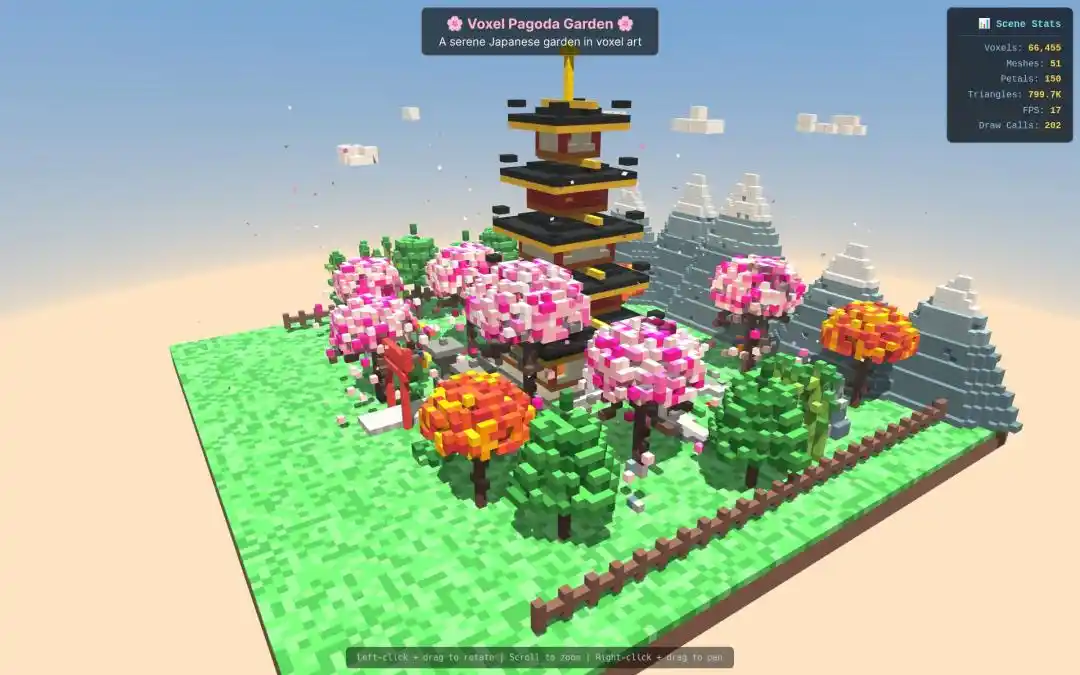
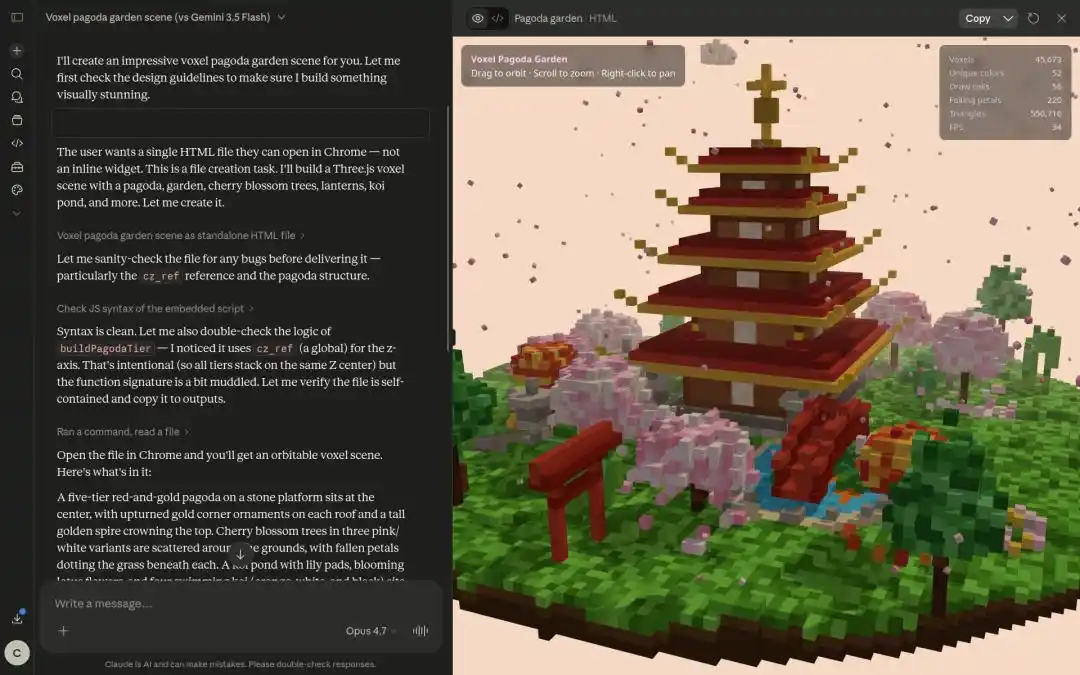
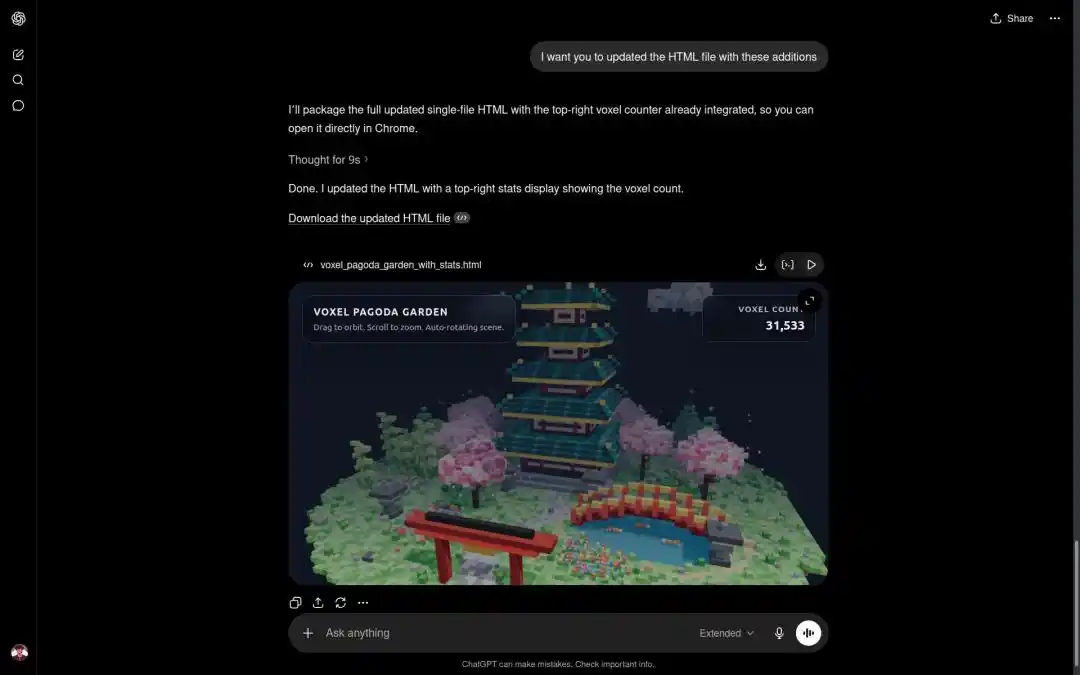
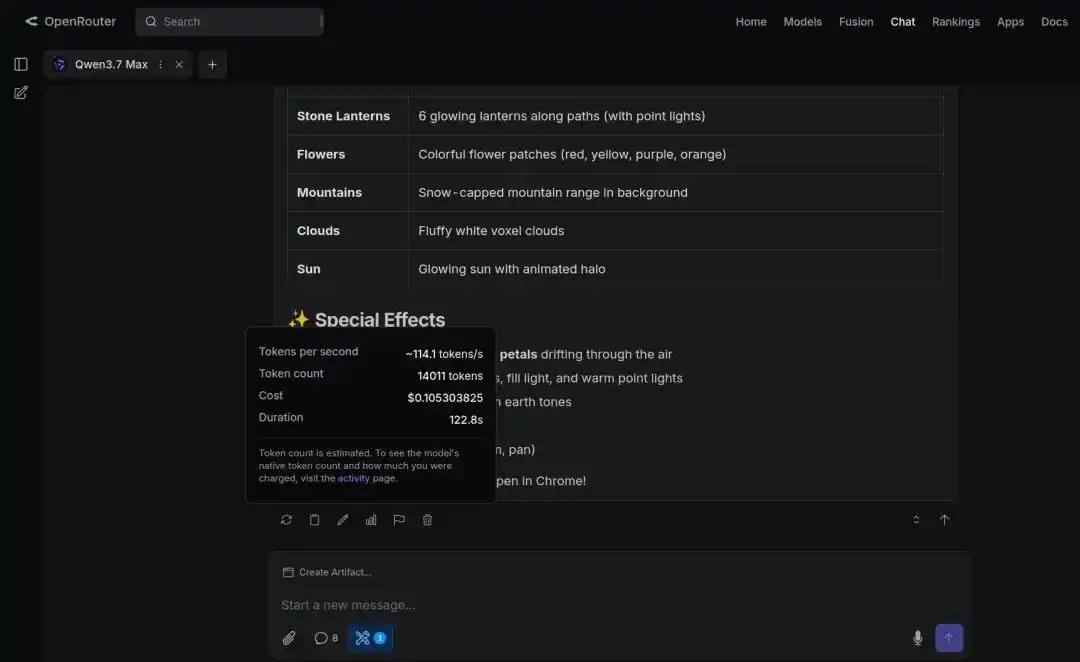
Un autre développeur international a choisi Qwen3.7-Max pour construire un modèle 3D d'un univers, avec un résultat qualifié de stupéfiant.
Dans la tâche de génération d'un « modèle miniature de pagode en pixel art 3D », la vitesse et la qualité de sortie de Qwen3.7-Max ont également surpassé la concurrence de manière complète.

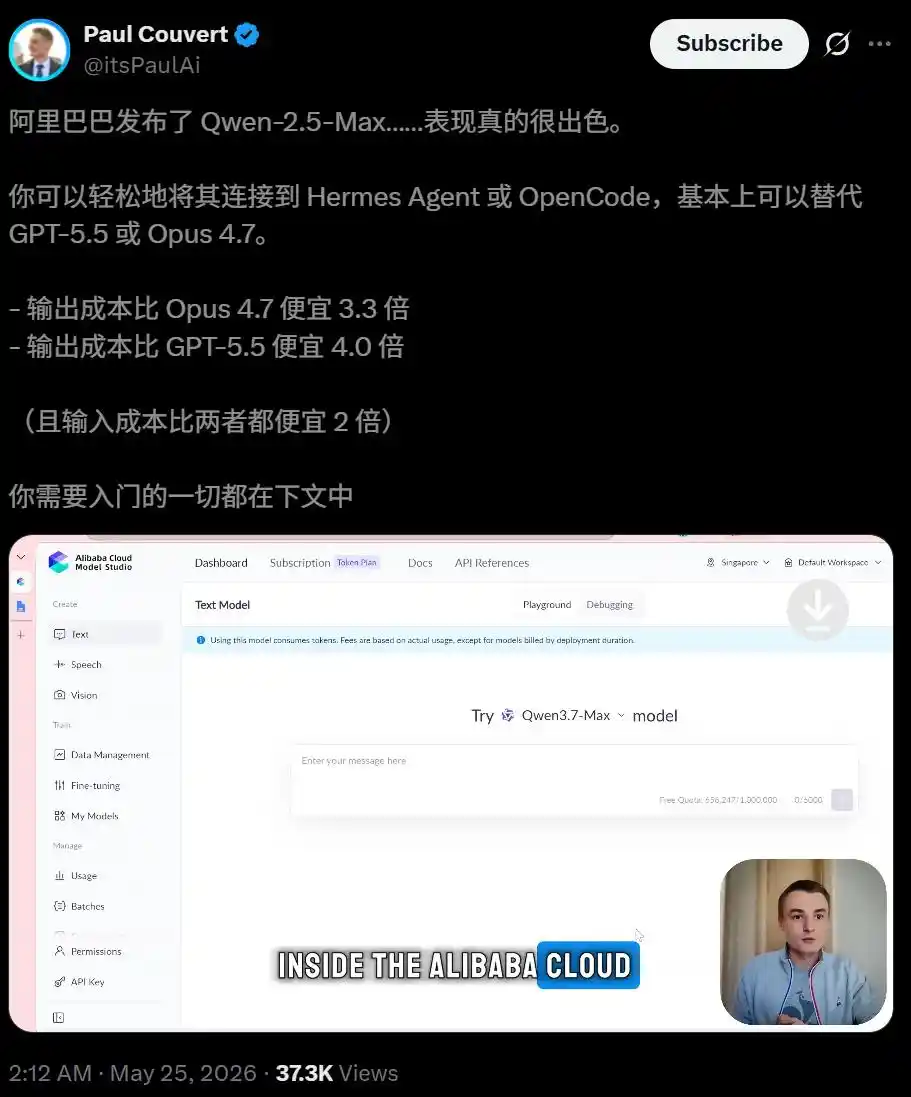
Le développeur Paul Couvert a même vivement loué Qwen3.7-Max, déclarant qu'une fois connecté à Hermes Agent et OpenCode, il pouvait essentiellement remplacer GPT-5.5 et Opus 4.7.
En programmation, vraiment efficace
Cependant, plutôt que des scores élevés, mieux vaut le tester en situation réelle.
Nous avons préparé pour Qwen3.7-Max un défi intense de « jeu de course automobile ».
Après avoir saisi un prompt détaillé, Qwen3.7-Max a rapidement généré un fichier HTML jouable.

La première version avait un petit bug : les touches de direction A/D étaient inversées.
Mais après un second ajustement simple via le dialogue, un jeu de course 3D complet et fonctionnel a été lancé.

Au moment de l'ouverture, pour être honnête, nous avons été un peu surpris.
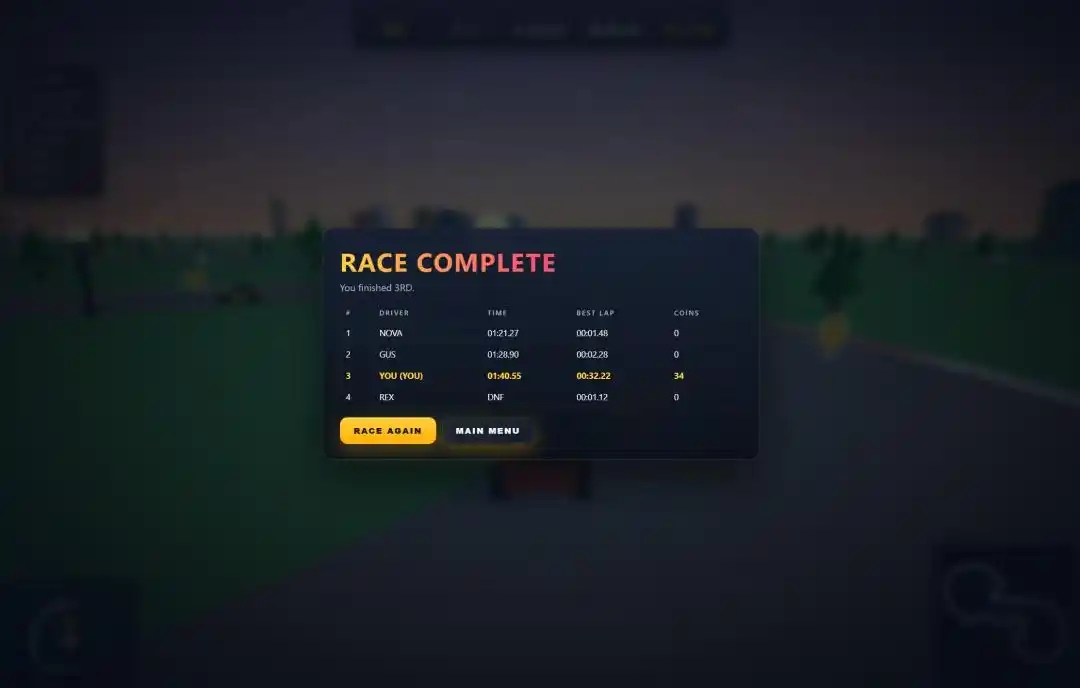
Quatre voitures sur la piste, une course de 3 tours sur un circuit ovale, plus de 100 pièces d'or dispersées sur la piste, des ralentissements et des pertes de contrôle en cas de collision avec des obstacles.
Le tableau des scores après la course affichait le classement, le temps, le nombre de pièces, le meilleur tour, rien ne manquait.
Mais ce qui a vraiment été surprenant, ce sont deux détails que seul Qwen3.7-Max a réalisés.
Le premier est l'écran de démarrage. Après un test transversal des quatre modèles, seul lui a créé un véritable écran de démarrage pour le jeu, avec un bouton « Start » pour entrer dans la course. Les trois autres démarraient directement la course, sans même un écran-titre.
Le deuxième est le son. Le prompt incluait en fin de compte une demande : ajouter des bruitages de moteur et de collecte de pièces. Parmi les quatre modèles, seul lui a intégré ce bonus, avec les rugissements du moteur et les 'ding' des pièces.
Voyons maintenant les performances des autres candidats.
Les graphiques de Gemini 3.5 Flash étaient nettement plus simplistes, manquant de cette sensation de profondeur et de relief.
La mise en page de l'interface utilisateur posait aussi problème, les informations du tableau de bord étant dispersées aux quatre coins de l'écran, créant une focalisation visuelle éparpillée.
En comparaison, Qwen3.7-Max a choisi de regrouper les indicateurs clés au centre de l'écran, correspondant mieux au point de fixation naturel du regard du joueur.

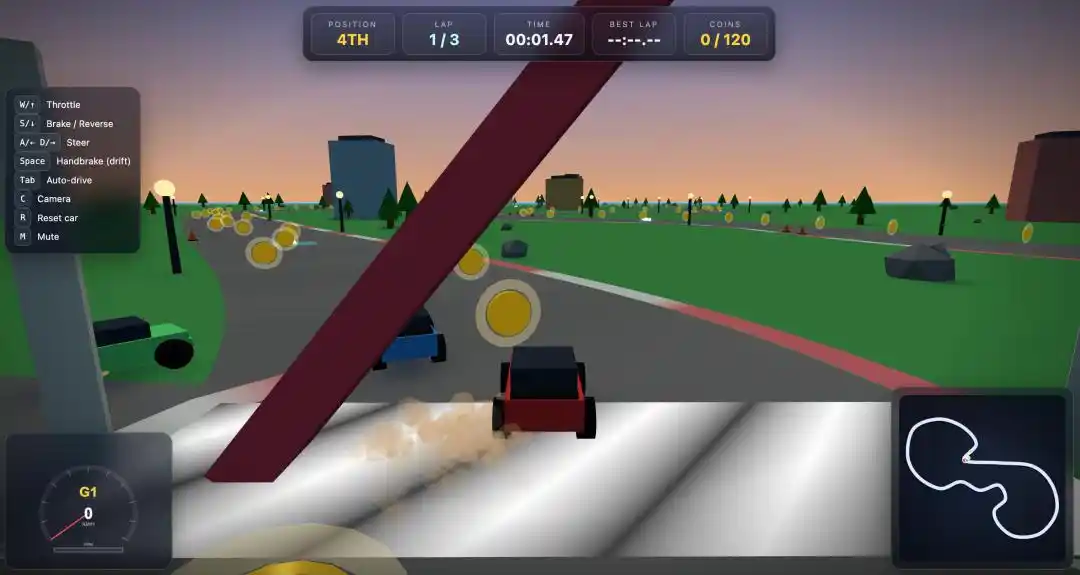
Le résultat de Claude Opus 4.6 était, disons, assez décevant.
Non seulement les pièces sur la piste étaient très rares, mais les 3 voitures IA se déplaçaient pratiquement de manière synchronisée, sans aucune randomisation, comme si elles étaient copiées-collées.
Enfin, GPT-5.5.
On peut voir que la qualité visuelle est en effet bien supérieure aux deux premiers, et les sensations de jeu sont plus fluides.
Mais, on ne sait pas pourquoi, les pièces ont été transformées en « donuts » jaunes...
La forme est un détail. Le point crucial est que Gemini, Claude et ChatGPT ont tous dû corriger plusieurs bugs avant de faire fonctionner toutes les fonctionnalités.
Seul Qwen3.7-Max était fondamentalement jouable dès la première génération.
Des scores comparables, des tests réels solides, un prix plusieurs fois inférieur. La conclusion, il suffit d'attendre que les développeurs votent avec leurs pieds.
Le modèle « de base » de l'ère des Agents
Si Qwen3.7-Max peut performer à un tel niveau sur le ring de la programmation, l'explication réside dans son positionnement produit.
Il y a quelques jours, lors de la sortie de Qwen3.7-Max, Alibaba lui a attribué une étiquette très particulière : modèle de base pour Agents.
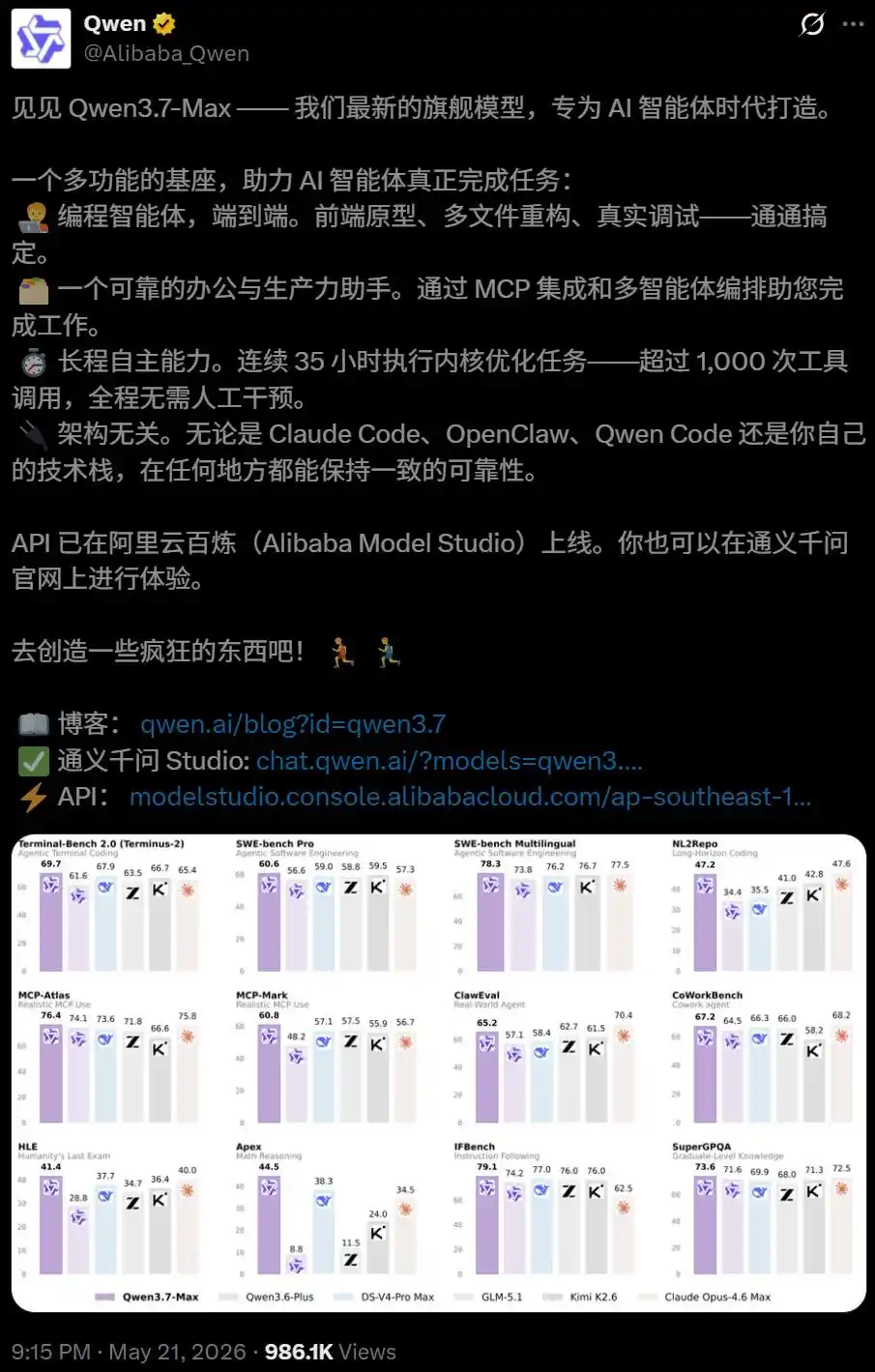
Il est conçu dès le départ pour être un modèle capable d'exécuter des tâches de manière autonome sur de longues durées.
Les données des tests internes montrent que lors d'une tâche de programmation autonome, Qwen3.7-Max a fonctionné pendant 35 heures d'affilée, effectuant 1158 appels d'outils.
Le code généré final a atteint une accélération moyenne géométrique impressionnante de 10 fois par rapport à l'implémentation de référence Triton.
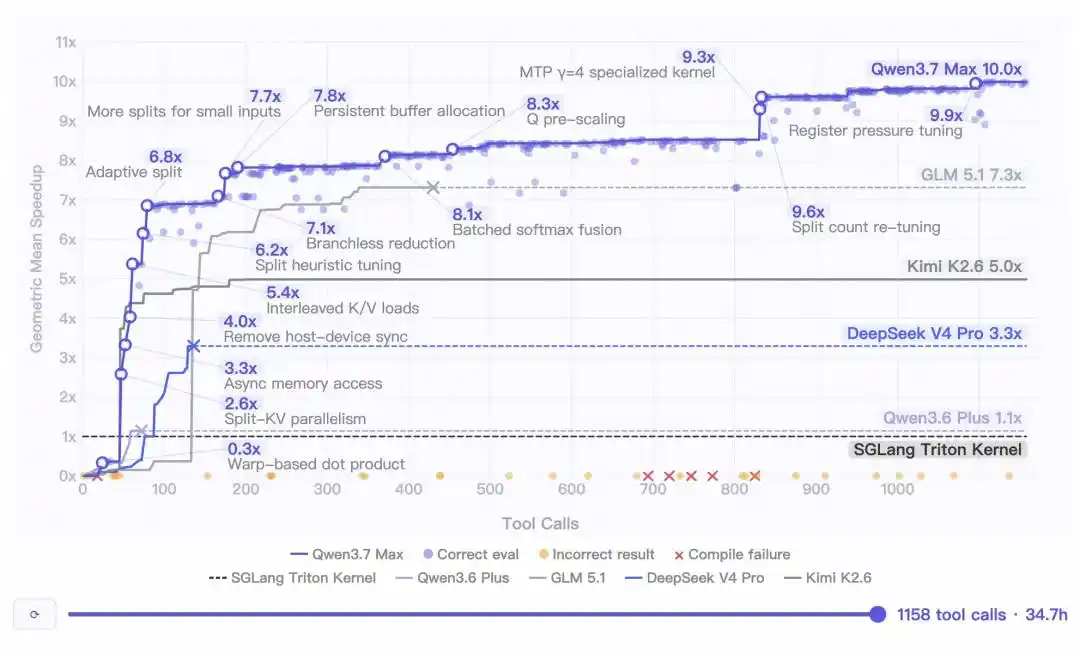
Plus impressionnante encore est sa capacité de « guerre d'usure » —
Après plus de 30 heures de raisonnement, le modèle conservait son acuité, continuant à découvrir de nouveaux espaces d'optimisation.
Et ce, sans aucune dégradation du contexte, aucune dérive des instructions, aucune boucle infinie !
Il faut reconnaître que la difficulté ne réside pas dans les 1000 appels d'outils en eux-mêmes. Depuis l'expansion du protocole MCP, faire 1000 appels n'est pas si rare.
La difficulté réside dans le raisonnement cohérent sur 35 heures.
La majorité des modèles s'effondrent lors de longues tâches : soit le contexte s'accumule et devient confus, les objectifs fixés au début étant complètement oubliés plus tard ; soit ils entrent dans une boucle infinie, réessayant sans cesse la même solution qui échoue.
Qwen3.7-Max a réussi à « continuer à faire les choses correctement ».
Révélation des technologies clés
Nous pensons que cette amélioration significative en programmation de Qwen3.7-Max est liée à l'amélioration de deux méthodes d'entraînement.
Premièrement, l'extension de l'environnement.
Lors de l'entraînement en programmation de Qwen3.7-Max, chaque tâche est décomposée en trois dimensions indépendantes : la tâche elle-même, le cadre d'exécution et la méthode de validation, ces trois éléments étant combinés librement.
Un même problème est parfois traité dans le cadre de Claude Code, parfois dans OpenClaw, parfois avec une méthode de validation différente.
L'effet est comparable à un stagiaire envoyé en rotation dans tous les groupes de projets. Ce qu'il est forcé d'apprendre, ce sont des stratégies génériques de résolution de problèmes, pas « comment tricher dans un cadre spécifique ».
Cela explique un phénomène contre-intuitif : Qwen3.7-Max performe de manière stable dans les cadres Claude Code, OpenClaw et Qwen Code, sans présenter de faiblesse flagrante lorsqu'il change de cadre par rapport à ses propres performances dans son cadre natif.

La deuxième amélioration est l'exécution autonome de longue durée.
Dans l'entraînement, l'équipe a introduit un cadre de « jeu de survie à accumulation dynamique ».
C'est-à-dire, faire en sorte que le modèle prenne des décisions séquentielles sur plus de mille étapes dans un environnement simulé en constante évolution, qu'il établisse ses propres hypothèses, ajuste ses stratégies en fonction des retours, et qu'il ne « corrompe » pas son contexte en raison d'une exécution trop longue.
Voici une donnée illustrative : sur le benchmark YC-Bench simulant la gestion d'une startup pendant un an, Qwen3.7-Max a atteint un chiffre d'affaires de 2,08 millions de dollars, soit le double de la génération précédente (1,05 million).
Plus crucial encore, il a montré une évolution stratégique : en milieu de parcours, face à une crise, il a pu ajuster son orientation de manière autonome, identifier et bloquer des clients malveillants, pour finalement converger vers une boucle d'exécution stable.
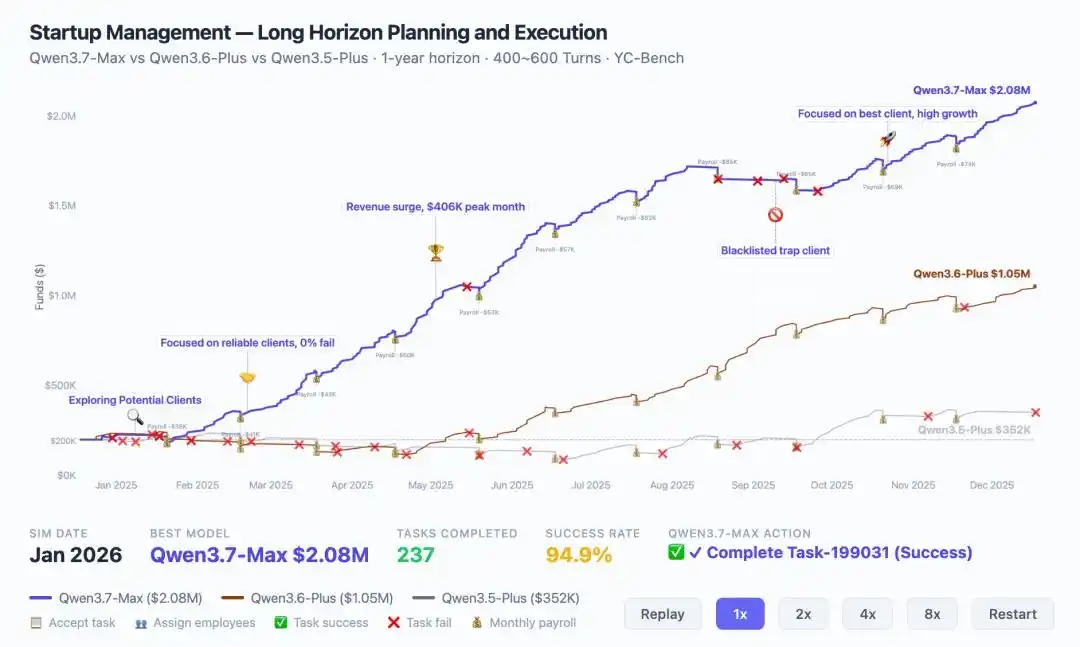
C'est le socle sous-jacent de l'exemple d'optimisation de kernel de 35 heures, et c'est pourquoi sur Kernel Bench L3, Qwen3.7-Max a permis d'obtenir un effet d'accélération dans 96% des scénarios.
Et la programmation n'est que le premier champ de bataille. Ces fondations de raisonnement de longue durée et d'appel d'outils pointent vers une ambition plus grande : un modèle de base universel pour Agents.
La finale de la programmation compte un nouvel agitateur
Depuis son lancement, Code Arena teste toujours des compétences concrètes : raisonnement multi-étapes, orchestration d'outils, livraison de projets complets, tout est du vrai combat au niveau Agent.
Aujourd'hui, Qwen3.7-Max, avec son score de 1541 points, s'est inséré en quatrième position, se calant entre Opus 4.6 Thinking et Opus 4.6.
Sur cette piste dominée par Claude depuis plus d'un an, il a apporté sa réponse : les modèles chinois ne sont pas seulement des poursuivants, ils peuvent aussi être des définisseurs.
La compétition mondiale des modèles de programmation n'est plus un spectacle en solo pour la Silicon Valley.
Références :
https://arena.ai/leaderboard/code/webdev
Cet article provient du compte WeChat officiel « New Zhiyuan », auteur : ASI Apocalypse





