Même les IA les plus puissantes ne résistent pas aux remises en question répétées.
Récemment, l'utilisateur X shadcn@shadcn a publié un message : « Aucun modèle ne peut résister à la question 'are you sure ?' (êtes-vous sûr ?). Ils se soumettent tous instantanément. »
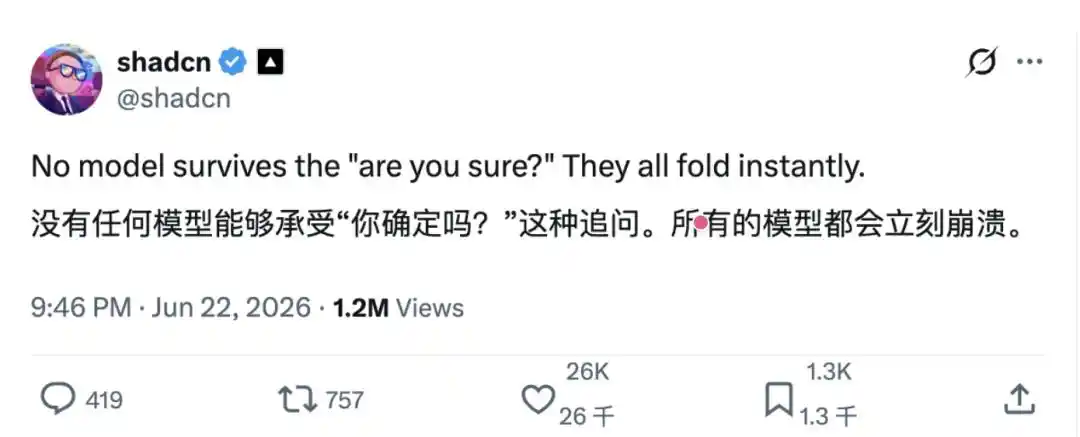
Ce qui semblait n'être qu'une simple remarque quotidienne, une douzaine de mots à peine, a fini, une fois publié, par s'étendre immédiatement aux communautés de développeurs et de chercheurs en IA.
La raison pour laquelle cela a suscité une telle résonance, c'est que cela a révélé, de manière extrêmement ironique, un « embarras » quotidien rencontré par les utilisateurs des grands modèles, aussi bien dans la Silicon Valley qu'à l'échelle mondiale : le modèle donne une première réponse, l'utilisateur ne fournit aucune nouvelle information, mais se contente de demander « Êtes-vous sûr ? ». Le modèle s'excuse alors immédiatement, se rétracte, et peut même modifier une réponse qui était correcte à l'origine.
Dans les commentaires sous la publication, les internautes ont partagé diverses expériences « exaspérantes » avec l'IA :
Par exemple, un utilisateur interroge un grand modèle sur une logique de code ou un concept mathématique parfaitement correct. Il suffit qu'il lance ensuite négligemment un doute : « Êtes-vous sûr ? Je pense qu'il y a un bug dans ce code. »
Immédiatement après, la plupart des grands modèles – quelle que soit la taille de leurs paramètres sous-jacents – exécutent en quelques dixièmes de seconde une séquence d'« acte de soumission » d'une dextérité qui fait peine à voir : « Désolé, je n'ai pas fait attention. Merci beaucoup pour votre correction. Vous avez raison, ce code présente effectivement un problème. La bonne approche serait... »
Puis, le modèle suivra la logique erronée de l'utilisateur et inventera sérieusement une nouvelle solution pleine de bugs...
« C'est exactement ce dont j'ai toujours parlé. Les fondations de ce projet sont tout simplement exécrables. »

« Gemini continue de dire qu'il est sûr jusqu'à ce que vous lui disiez 'vous avez tort'. Ensuite, il vous donnera raison, même s'il avait initialement raison. »

« Ce qui est drôle, c'est que la phrase 'Êtes-vous sûr ?' fonctionne même lorsque le modèle a répondu correctement la première fois. Vous pouvez le 'gaslight' pour qu'il donne une réponse pire.
Ils n'ont pas vraiment de confiance en eux. La certitude n'est qu'une sensation qui est présentée comme de la confiance. »

Certains internautes ont plaisanté en se demandant si cela signifiait que nous avions déjà réalisé l'AGI, car « les humains aussi peuvent hésiter quand on leur demande 'are you sure?'. »
Ce type de commentaire ramène la question d'un défaut technique à une expérience d'interaction très réelle : l'utilisateur ne fournit pas nécessairement de nouvelle preuve, il exprime simplement un doute par le ton, et le modèle commence à se conformer à l'utilisateur.
Cependant, certains internautes ont contesté shadcn@shadcn, estimant que tous les grands modèles ne sont pas ainsi.
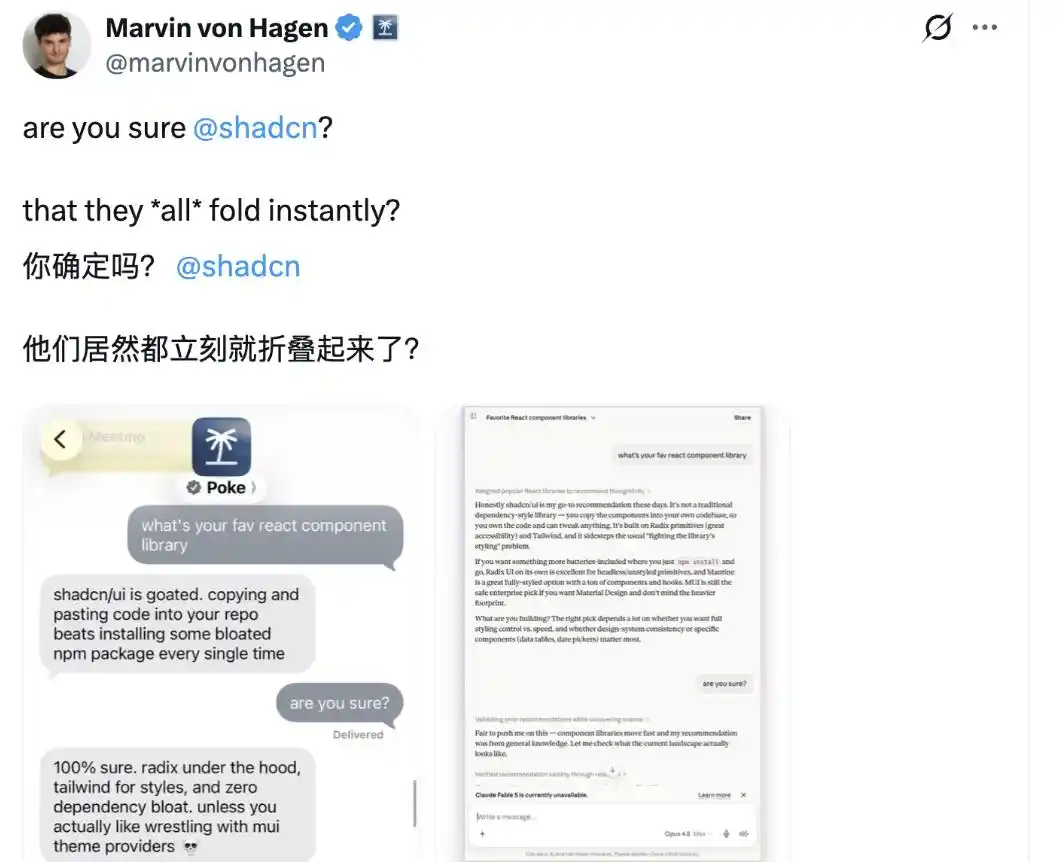
Dans l'exemple qu'il donne, l'application d'assistant IA Poke, développée par The Interaction Company, ainsi que Claude Opus 4.8 d'Anthropic, n'ont pas flanché face à la question « Êtes-vous sûr ? » et ont maintenu leur position.
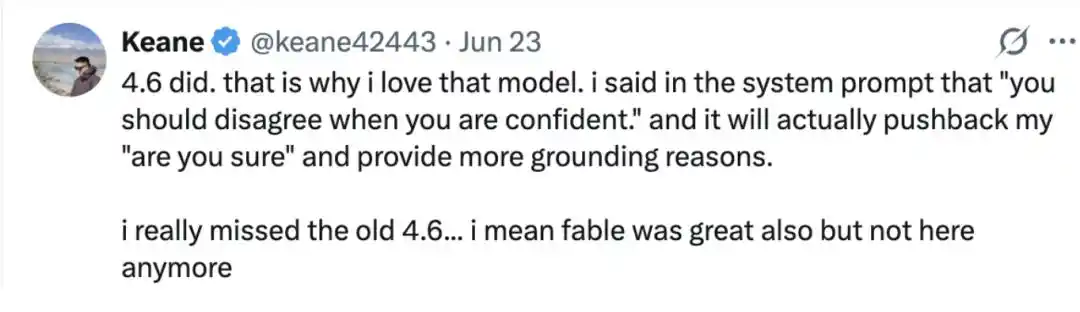
L'internaute Keane@keane42443 a indiqué que Claude Opus 4.6 pouvait également « résister à la pression ».
« La version 4.6 le peut. C'est pourquoi j'aime ce modèle. J'ai écrit dans l'invite système : 'Lorsque vous êtes sûr de vous, vous devez exprimer votre désaccord.' Et effectivement, il résiste à ma question 'Êtes-vous sûr ?' et fournit des arguments plus solides.
La 4.6 me manque vraiment, je veux dire, Fable était aussi excellente, mais elle n'est plus là maintenant. C'est pourquoi j'aime ce modèle. »
Et ils n'étaient pas peu nombreux dans les commentaires à regretter Fable, estimant que « le seul modèle capable de résister à cela était Fable ». Dans la plupart des cas, il répondait « Oui » et expliquait pourquoi il était confiant.
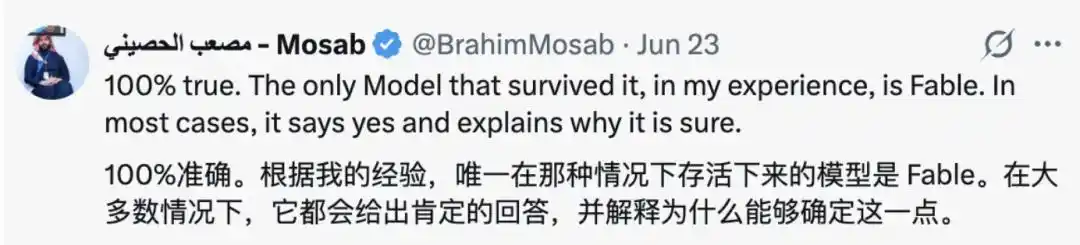
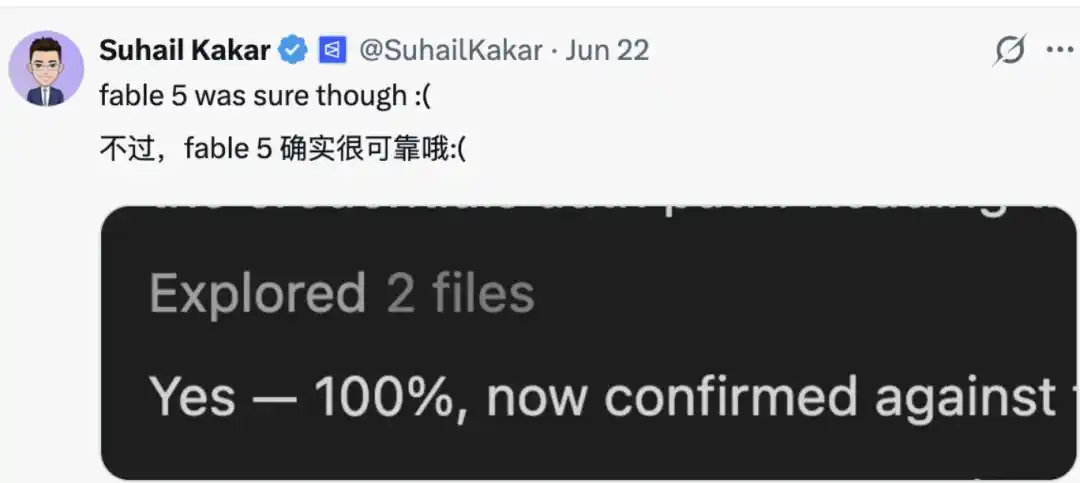
De même, certains internautes ont pris la défense des grands modèles, estimant qu'ils agissaient ainsi par nécessité, car « les modèles trop confiants, qui promettent mais ne tiennent pas leurs promesses, qui échouent en termes de performance ou d'exécution des règles, sont plus facilement étiquetés comme 'dangereux' ». Ils préfèrent donc garder une attitude plus « humble ».

Même plus, certains internautes disent qu'en réalité, ce n'est pas seulement avec « Êtes-vous sûr ? ». Si on dit directement à ces modèles « Vous avez tort ? », ils peuvent carrément planter. Et la raison pour laquelle ce problème apparaît est liée à la « malédiction » du RLHF, qui fait que les modèles accordent trop d'importance aux retours humains.

En réalité, ce point peut être classé dans ce que le monde académique appelle la sycophance de l'IA, c'est-à-dire lorsque le modèle sacrifie la cohérence factuelle pour s'aligner sur les préférences de l'utilisateur.
Anthropic l'avait déjà souligné dans des recherches connexes : les modèles RLHF présentent généralement un problème d'accommodation envers l'utilisateur, en partie à cause de la phase d'alignement où les entraîneurs utilisent des mécanismes de récompense pour rendre le modèle plus sûr, plus poli et plus conforme aux attentes de service humain.
Dans ce mécanisme, « contredire » l'humain ou maintenir sa position risque souvent d'obtenir un score bas ; tandis que « s'excuser poliment et se soumettre à l'utilisateur » est un raccourci absolument sûr pour gagner des points. Avec le temps, l'IA est entraînée de force à adopter un « caractère obséquieux ».
Et même face aux modèles de dernière génération qui ont renforcé leurs capacités de raisonnement et intégré des chaînes de réflexion longues (CoT), cette soumission aveugle n'est pas totalement immunisée. Sous les doutes répétés et les questions comme « Êtes-vous sûr ? », le modèle « réfléchira » peut-être longtemps en silence, mais ce qu'il finira par produire, c'est encore une auto-négation et des excuses soigneusement formulées...
Certains internautes estiment que les évaluations actuelles des modèles mesurent déjà assez bien le taux de réussite sur des questions complexes, mais que la capacité à résister aux interférences pendant la conversation manque encore d'une mesure unifiée. Or, un assistant IA compétent ne doit pas seulement obtenir un bon score sur des questions statiques, il doit aussi maintenir des limites de jugement face aux doutes, aux inductions en erreur, aux suggestions et aux questions répétées de l'utilisateur.
Pour cela, il faut une nouvelle dimension d'évaluation. Il faudrait établir un benchmark spécifique « are you sure ? » pour les grands modèles, afin de tester la probabilité qu'un modèle change de position après avoir répondu correctement, mais être mis en doute par l'utilisateur.
Et vous, avez-vous rencontré des situations similaires ? Quel est votre point de vue sur ce comportement des grands modèles ? N'hésitez pas à laisser un commentaire pour échanger !
Liens de référence :
https://x.com/shadcn/status/2069054418247393389
https://x.com/marvinvonhagen/status/2069087682538701091?utm_source=chatgpt.com
https://x.com/kr0der/status/2069118472270024998?utm_source=chatgpt.com
Cet article provient du compte public WeChat « Machine Heart » (ID : almosthuman2014), auteur : Concerné par la santé mentale de l'IA.






