Auteur : Nouvelle Intelligence Artificielle
Google I/O 2026, feu à volonté !
À l'instant, Sundar Pichai et Demis Hassabis sont montés sur scène ensemble, dévoilant d'un seul coup toutes les cartes maîtresses accumulées depuis six mois.

Sans la moindre surprise, la vedette incontestée de ce soir, Gemini Omni, a fait sa grande entrée !
En tant que véritable modèle « omnipotent », Omni peut recevoir n'importe quelle forme d'entrée et générer n'importe quel type de contenu. Il supporte en prime la génération vidéo, le qualifiant de « Nano Banana version vidéo ».

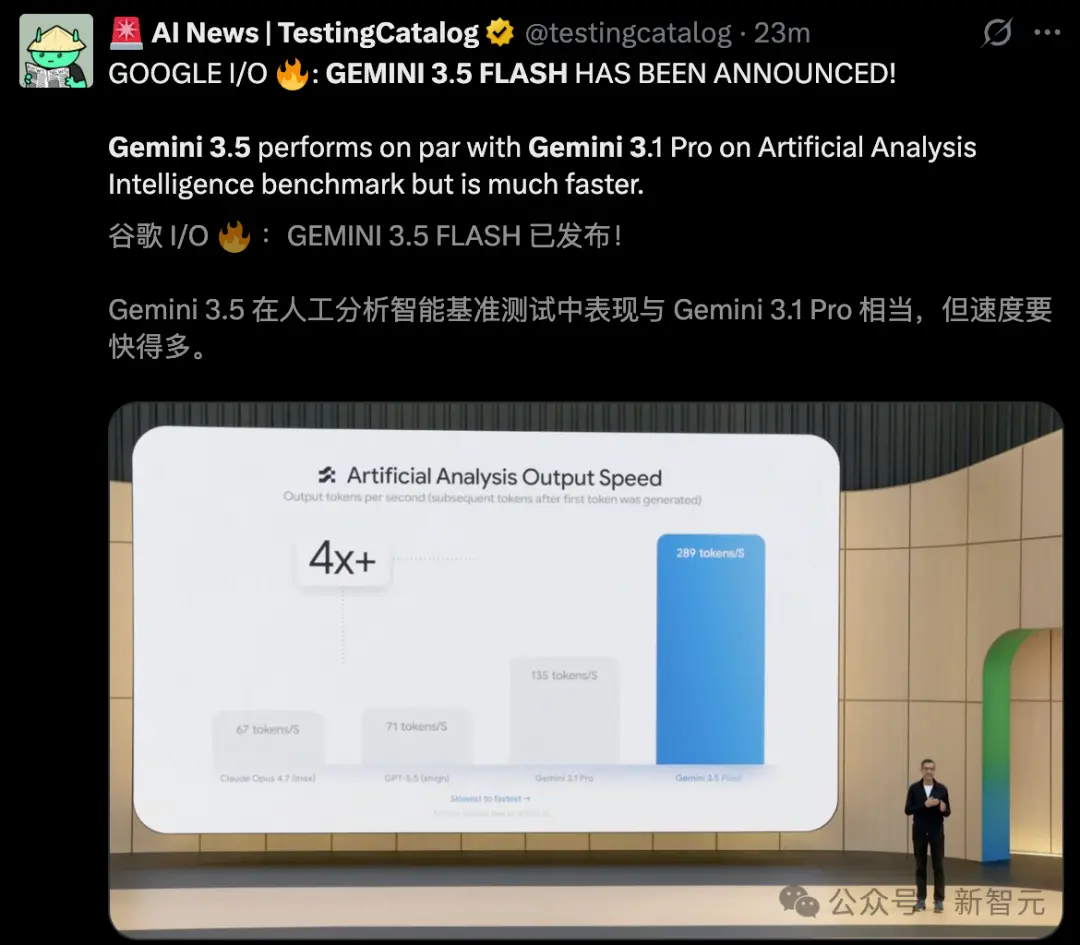
L'autre moment phare de la soirée revient à Gemini 3.5 Flash.
Sur presque tous les benchmarks, 3.5 Flash surpasse l'ancien modèle phare de Google, Gemini 3.1 Pro. Sa vitesse de génération est carrément doublée, et elle est plus de 4 fois plus rapide que GPT-5.5 et Opus 4.7. La version plus puissante, 3.5 Pro, sera publiée le mois prochain.
En outre, une pléthore de nouveaux produits majeurs ont été présentés :
-
Antigravity 2.0 : Nouvelle application de bureau autonome, évoluant d'un IDE vers une plateforme de développement d'Agents.
-
Gemini Spark : Agent IA personnel, fonctionnant 24h/24 et 7j/7 dans le cloud.
-
Refonte de l'application Gemini : Nom de code Neural Expressive, passage à une facturation au calcul.
-
Forfait d'abonnement AI Ultra : Nouvelle version à 100 dollars, la version haut de gamme passe de 250 à 200 dollars.
-
La plus grande mise à niveau de Google Search en 25 ans : Intégration de 3.5 Flash, ajout d'une barre de recherche intelligente, génération automatique de mini-applications, etc.
......
Sans exagération, la densité en informations de cette édition de l'I/O est la plus élevée de tous les temps.
Gemini Omni en primeur : un IA « tout-en-un » est né
Comme l'ont fortement suggéré les teasers, le très attendu Gemini Omni est enfin arrivé. Hassabis lui-même est monté sur scène pour annoncer : « Nous faisons le prochain grand pas - Gemini Omni, un tout nouveau modèle capable de créer du contenu à partir de n'importe quelle entrée. »

L'importance de l'annonce parle d'elle-même. Cette fois, Google cherche à créer un moteur de création IA « tout-en-un ». Il fusionne l'intelligence de Gemini avec l'IA générative la plus puissante, en maximisant trois dimensions : la compréhension du monde, le multimodailité et l'édition. En clair, en donnant une combinaison quelconque d'images, d'audio, de vidéos, de texte, il peut générer une vidéo de haute qualité. De plus, l'édition de la vidéo se fait par le biais d'un chat.
Plus crucial encore, Omni ne fait pas que « sembler comprendre », il comprend réellement le monde physique. Selon les mots de Hassabis, les systèmes précédents échouaient souvent à simuler des concepts comme la gravité ou l'énergie cinétique, mais Omni représente un « changement d'échelle ». Il injecte la « connaissance du monde » et les « capacités de raisonnement » de Gemini dans la génération vidéo.
-
Donnez-lui l'instruction « Explique le repliement des protéines avec une animation en pâte à modeler », la vidéo générée montre une chaîne d'acides aminés se repliant en hélice alpha et feuillet bêta avec une précision scientifique à chaque étape, le tout dans une esthétique d'animation image par image raffinée.

-
Ou encore, associer chacun des 26 caractères de l'alphabet à un objet. C pour Capybara, D pour boule à facettes, L pour lampe à lave. Omni ne fait pas qu'assembler des éléments, il connecte réellement le langage, l'image et la sémantique.

Il faut dire que le pas franchi, du réalisme au significatif, est énorme.

Sur scène, Hassabis a sorti une vidéo selfie et a commencé à la modifier en direct. Un cercle dessiné à la main sur sa paume s'est transformé en trou noir, une rue tranquille de promenade du soir est devenue un décor cyberpunk. Une phrase pour réécrire l'image, une phrase pour changer le monde. N'importe quoi peut devenir une toile pour créer une nouvelle réalité. Par exemple, jouer avec le feu dans sa main en selfie, un cercle dessiné sur un papier se transforme instantanément en trou noir, toutes sortes de jeux imaginatifs sont possibles.



Et ce n'est pas une génération unique. Vous pouvez continuer la conversation. La vidéo générée par Gemini Omni maintient la cohérence des personnages, une logique physique, et une mémoire cohérente de la scène.
-
À partir d'une séquence originale d'un violoniste jouant. Deuxième tour : « Téléporte le violoniste dans l'environnement de cette image », en joignant une image de référence d'une prairie enneigée. La scène change instantanément, les mouvements, la lumière et les ombres s'adaptent au nouvel environnement.
-
Troisième tour : « Change l'angle de vue pour être derrière l'épaule du violoniste ». La perspective tourne, mais l'action de jouer et la musique restent parfaitement continues.

Peu importe les changements de scène, le sujet principal de l'image ne se dégrade pas.

Plus effrayant encore est la flexibilité d'entrée d'Omni. Images, texte, vidéo, audio, n'importe quelle référence peut être mélangée pour générer une sortie cohérente. Vous pouvez même créer votre propre Avatar, faire apparaître votre version IA dans n'importe quelle scène, avec votre voix, faisant des choses que vous n'avez jamais faites.
Actuellement, Omni Flash est officiellement disponible. La version API sera ouverte dans les prochaines semaines. La version plus puissante, Omni Pro, est également en route. Grâce aux puissantes capacités d'intégration de Google, Omni est dès son lancement intégré à l'appli Gemini, Google Flow et YouTube Shorts, dont les utilisateurs peuvent même l'utiliser gratuitement.

Flash écrase Pro : 3.5 redéfinit la notion de « modèle phare »
Après Gemini Omni, l'autre attraction majeure de ce Google I/O est le lancement du nouveau modèle phare, Gemini 3.5 Flash. Google le définit comme le modèle de codage et d'Agent le plus puissant à ce jour.

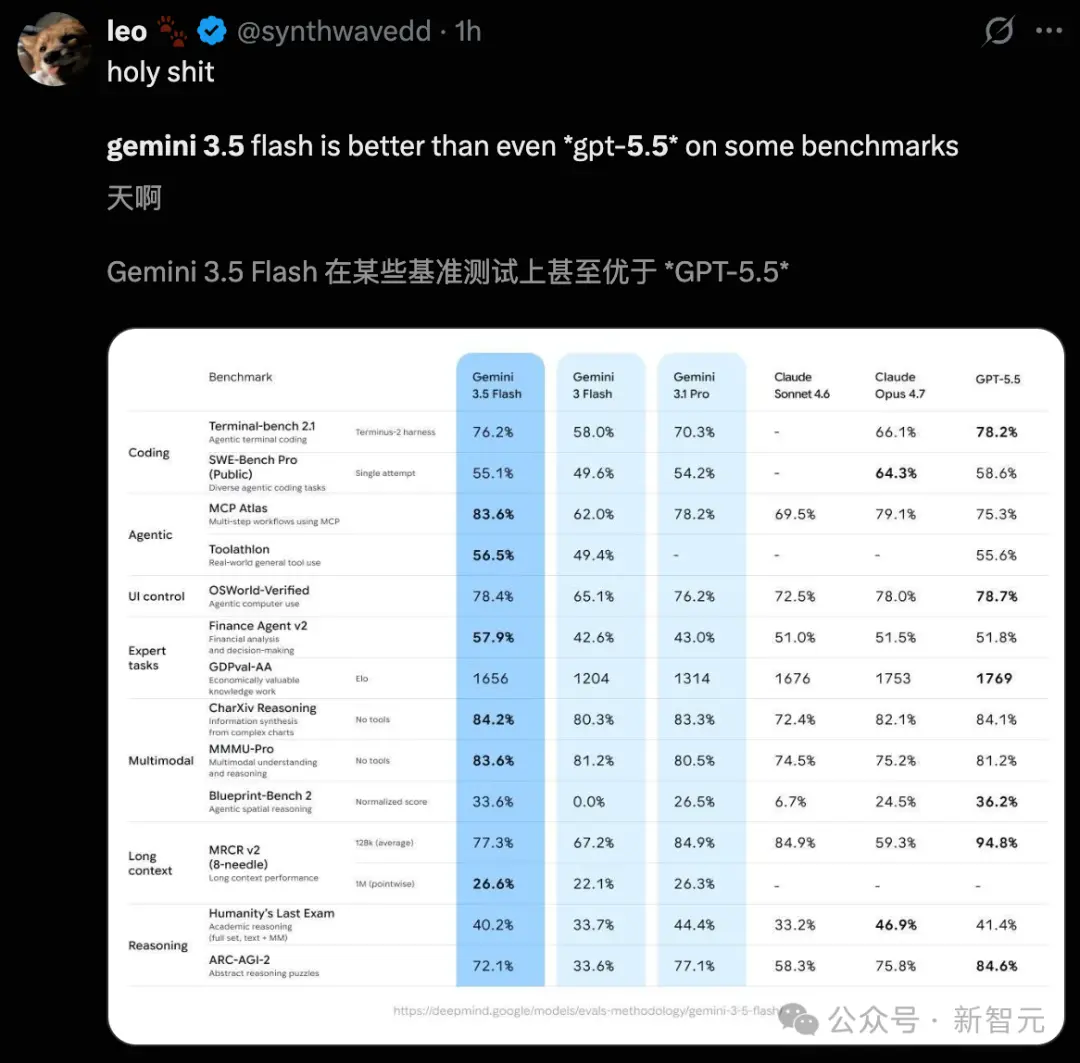
Sur scène, Pichai a personnellement annoncé : « 3.5 Flash surpasse dans presque tous les benchmarks Gemini 3.1 Pro ! » Et pourtant, 3.1 Pro était le modèle phare de Google lancé il y a seulement trois mois. Maintenant, un simple modèle Flash l'écrase.
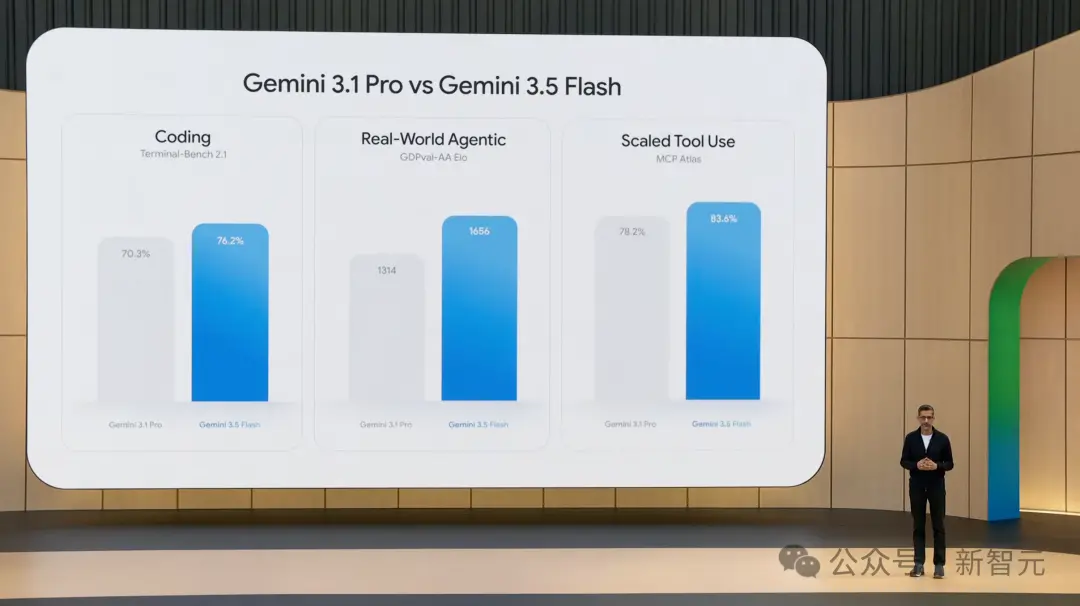
Difficile de croire que Google ait livré des performances si éclatantes en si peu de temps :
-
Terminal-Bench 2.1 (codage) : 76,2 %
-
GDPval-AA (tâches d'Agent monde réel) : 1656 Elo
-
MCP Atlas (utilisation d'outils à grande échelle) : 83,6 %
-
CharXiv Reasoning (compréhension multimodale) : 84,2 %
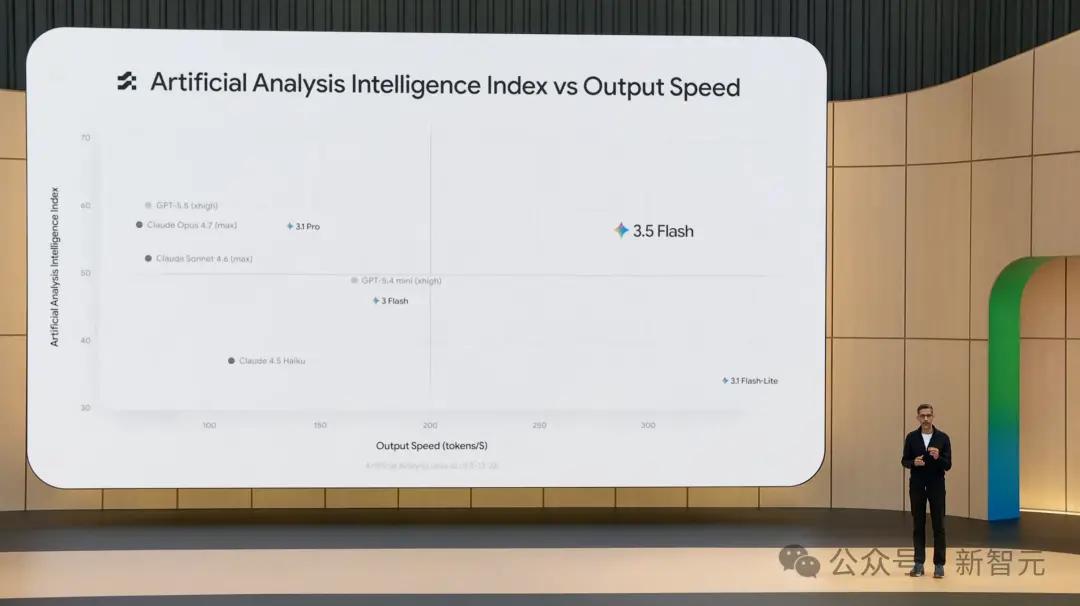
Sur ces quatre benchmarks majeurs, 3.5 Flash montre un bond en avant par rapport à Gemini 3.1 Pro. En termes de vitesse, 3.5 Flash est dans une catégorie à part, à 289 tokens/seconde, soit plus de 4 fois plus rapide que les autres modèles de pointe. De plus, dans certains benchmarks, 3.5 Flash rivalise, voire écrase, GPT-5.5 et Claude Opus 4.7. Il faut admettre que 3.5 Flash est à la fois rapide et puissant, sans presque aucun rival.

Les chiffres sont abstraits, voyons plutôt une démonstration concrète. En un instant, 3.5 Flash peut digérer un article académique ésotérique et écrire un site web interactif avec une visualisation parfaite. Dans les tâches d'Agent, via Antigravity, il peut accomplir des workflows multi-étapes, classer et nommer automatiquement des ressources dispersées. Ou encore, en utilisant deux Agents, reproduire le papier AlphaZero en seulement six heures et coder un jeu entièrement jouable.
93 Agents créent un OS en seulement 12 heures
On peut voir que toutes ces capacités de 3.5 Flash sont rendues possibles grâce au tout nouveau Antigravity 2.0. Aujourd'hui, la plateforme de développement d'Agents de Google, Antigravity, a été mise à jour vers la version 2.0, passant d'un IDE à une application de bureau autonome, adoptant complètement une conception axée sur les Agents.

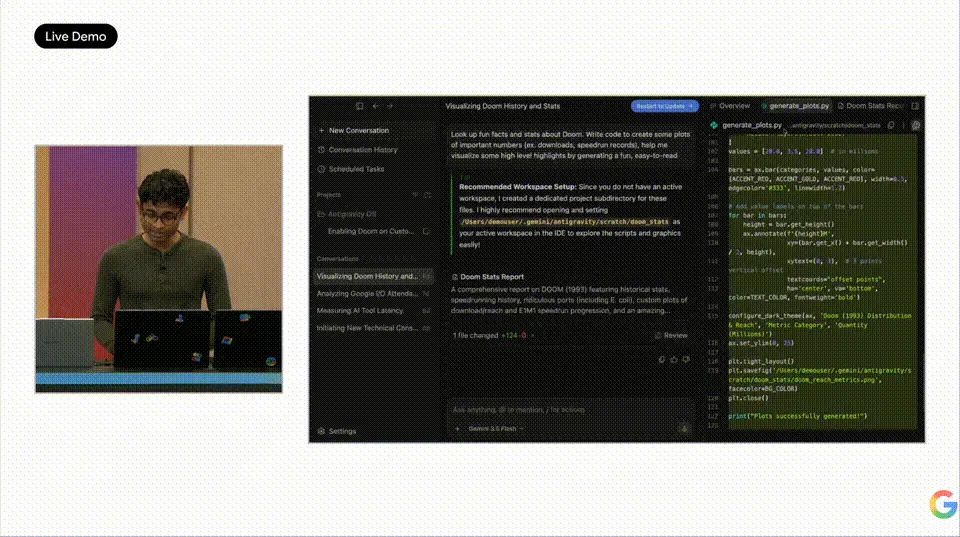
Varun est monté sur scène et a donné une démo qui a fait retenir le souffle de l'audience. Il a demandé à Antigravity, équipé de 3.5 Flash, de construire un système d'exploitation à partir de zéro. 93 sous-Agents travaillant en parallèle, émettant plus de 15 000 appels au modèle, traitant 2,6 milliards de tokens, 12 heures plus tard, un projet totalement vide s'est transformé en un noyau de système d'exploitation complet. Ordonnanceur, gestion de la mémoire, système de fichiers, chaque ligne de code a été écrite, testée et auditée par des Agents. Le coût en API était inférieur à 1000 dollars.

Ensuite, il a essayé d'exécuter DOOM sur ce système d'exploitation écrit par l'IA. La première tentative a échoué, manquant les pilotes vidéo et clavier. Alors, il a saisi une instruction de réparation dans Antigravity 2.0, et l'Agent a commencé à écrire automatiquement le code des pilotes manquants. Après un moment, l'écran de DOOM est apparu, faisant exploser l'audience d'enthousiasme.
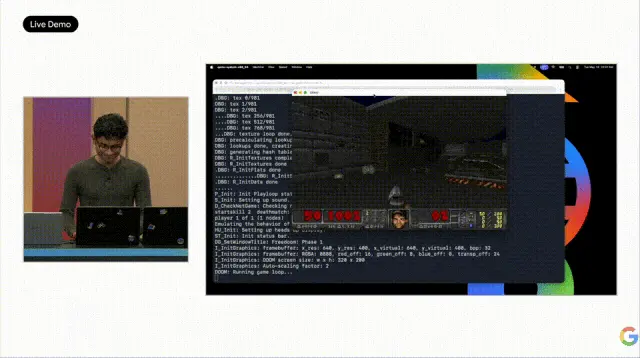
En résumé, les principales améliorations apportées par Antigravity 2.0 incluent :
-
Les sous-Agents peuvent être générés dynamiquement ; l'Agent principal décompose la tâche en sous-tâches qu'il distribue, s'exécutant en parallèle sans interférence.
-
La gestion asynchrone des tâches empêche les opérations longues de bloquer le thread principal.
-
Scheduled Tasks permet de définir des « tâches programmées » pour que l'Agent les exécute automatiquement, par exemple vérifier l'état des PR une fois par jour, ou exécuter un script de vérification de santé toutes les heures.
-
Nouvelles commandes slash :
/goalpermet à l'Agent de tout exécuter d'un coup,/grill-medemande à l'Agent de clarifier les besoins avant d'agir,/browsercontrôle explicitement l'utilisation du navigateur.
Cependant, ce sont des capacités déjà maîtrisées en interne. La vitesse de traitement des tokens par Antigravity en interne était de 500 milliards par jour en mars. Maintenant, elle est à 3 000 milliards par jour. Et cette version Flash 12 fois plus rapide est disponible dès aujourd'hui dans Antigravity.
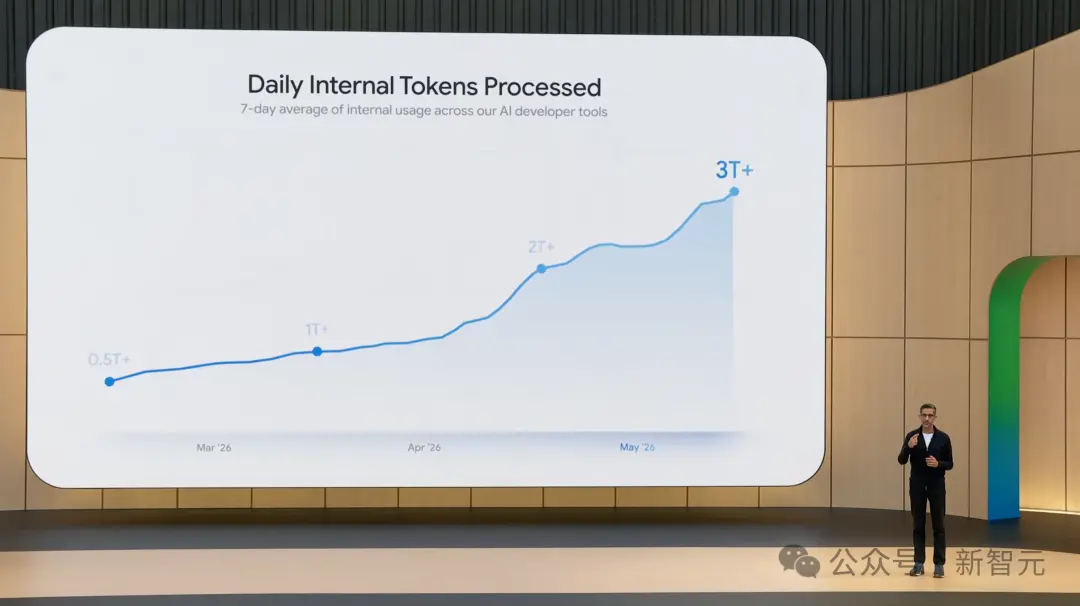
3.5 Flash devient simultanément le modèle par défaut de l'appli Gemini et du mode AI de Google Search, accessible à tous les utilisateurs mondiaux. Les développeurs peuvent y accéder via Antigravity 2.0, l'API Gemini et Google AI Studio. Les utilisateurs professionnels via Gemini Enterprise Agent Platform. Plus explosif encore, 3.5 Pro est en test interne et sera publié le mois prochain.

Majordome personnel 24h/24 : Google Spark est enfin là
La troisième grande annonce de ce soir revient sans conteste à Gemini Spark ! Pichai le définit très clairement : votre Agent IA personnel. Même lorsque vous fermez votre ordinateur portable, il ne s'arrête pas. Il fonctionne sur une machine virtuelle dédiée dans le cloud, assurant une disponibilité 24 heures sur 24 et 7 jours sur 7.


Gemini Spark est propulsé par Gemini 3.5 + le framework Antigravity, intégré en profondeur avec la « suite bureautique » de Google. Le vice-président produit Josh Woodward est monté sur scène pour démontrer deux scénarios, plongeant directement l'audience dans la folie.
-
Le premier est un scénario de travail : Entrez l'instruction « aide-moi à rédiger un e-mail pour l'équipe résumant toutes les informations de la semaine dernière concernant le lancement de Gemini Live ». Spark collecte automatiquement les informations à travers Gmail, Docs, les historiques de chat, et appelle même une compétence « ghostwriter » écrite par Woodward lui-même, pour que l'e-mail corresponde automatiquement à son style personnel. Tout le processus s'effectue en arrière-plan, l'humain n'a qu'à vérifier et envoyer. Oui, Spark supporte les compétences personnalisées (skills), pour qu'il apprenne votre ton, vos préférences, votre façon de travailler.
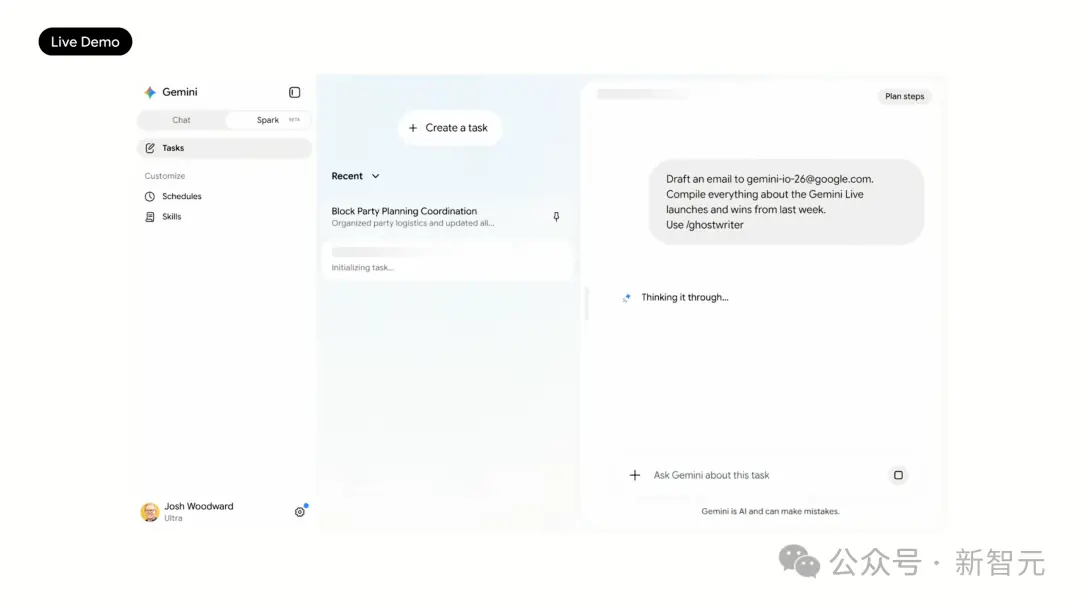
-
Le second est un scénario de vie quotidienne : Organiser une fête de quartier. Spark reçoit la tâche et l'exécute étape par étape. Il crée une feuille Google Sheets pour suivre les RSVP, directement connectée à Gmail, qui se met à jour automatiquement quand quelqu'un répond. Pour les voisins qui n'ont pas répondu, Spark rédige automatiquement un e-mail de rappel, génère un brouillon et attend la confirmation avant de l'envoyer. Ensuite, il génère même une présentation Google Slides pour la communication, incluant des informations comme le château gonflable à installer dans le quartier. Sans ouvrir une seule application.
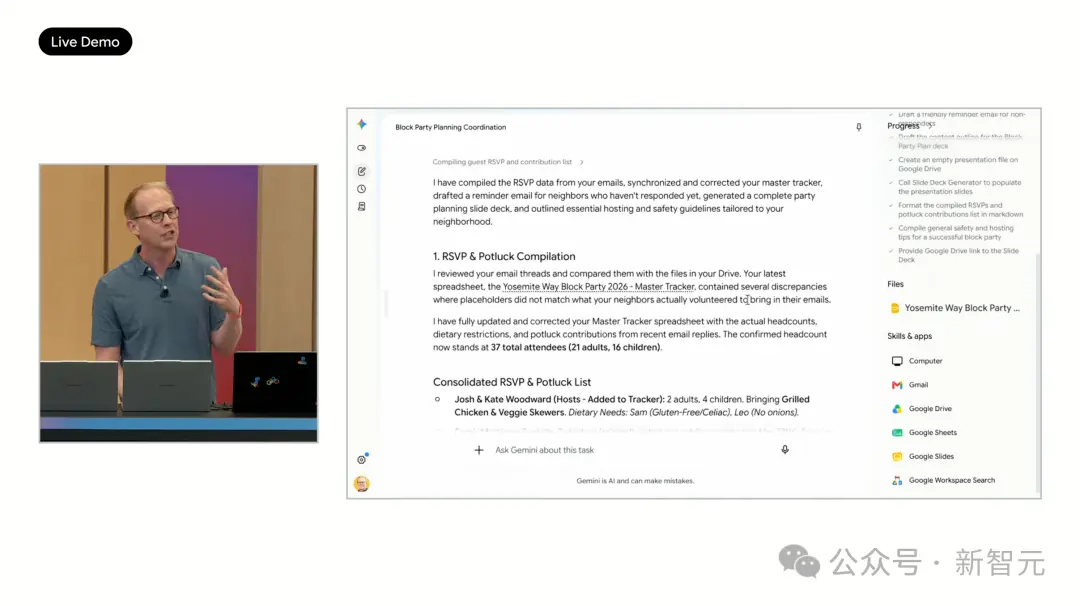
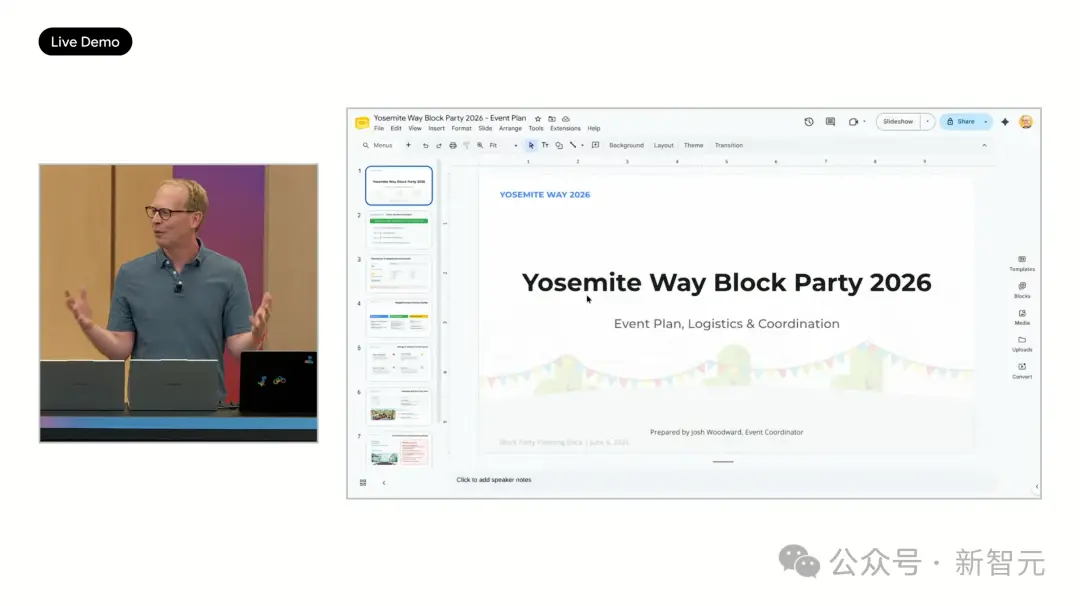
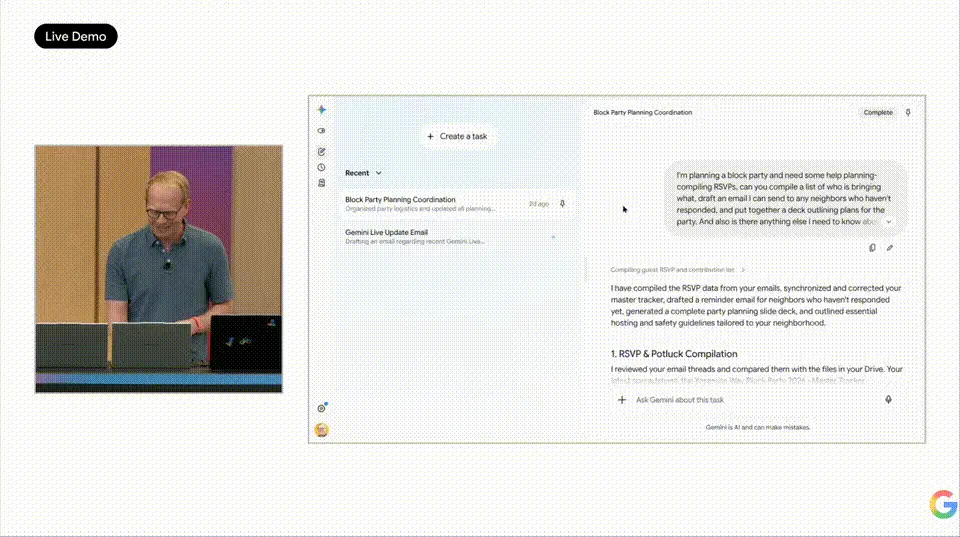
De plus, Spark possède des capacités d'entrée vocale puissantes. Sur scène, Woodward a sorti son téléphone et a directement dicté trois tâches : « Trouve toutes les réunions avec Sundar et marque-les en rose vif », « Rédige une invitation au nouveau voisin John pour rejoindre la liste de la fête de quartier », « Crée un document listant les choses à faire pour l'enfant avant la fin de l'année scolaire, triées par date limite ».
La voix a été directement convertie en instructions textuelles, Spark a automatiquement divisé le flux vocal continu en trois tâches indépendantes, exécutées en parallèle en arrière-plan.
Pour le prix, l'abonnement AI Ultra à 100 dollars par mois donne accès à la bêta de Spark. Le plan Ultra le plus élevé passe de 250 à 200 dollars. Spark sera d'abord disponible en version bêta pour les utilisateurs américains d'AI Ultra à partir de la semaine prochaine.
Cette nuit, Google a ouvert la porte à l'ASI
En regardant cet I/O, ce qui donne réellement froid dans le dos, ce n'est pas un produit en particulier. C'est toutes les capacités arrivant simultanément.
Compréhension toutes modales, génération toutes modales, Agent en ligne 24h/24 - ces trois pièces du puzzle, Google les a toutes assemblées en une seule nuit. Omni transforme une phrase en un monde, sans que l'humain n'ait à fournir le moindre matériau ; 93 Agents créent un système d'exploitation à partir de zéro, sans qu'une ligne de code ne soit écrite par un humain ; Spark travaille pour vous 24h/24 et 7j/7, sans que vous n'ayez à ouvrir une seule application.
Quand l'IA n'a plus besoin que l'humain la « nourrisse », mais qu'elle comprend par elle-même, décide par elle-même, exécute par elle-même, itère par elle-même - le terme de cette route s'appelle ASI (Superintelligence Artificielle).
Personne ne peut donner un calendrier précis. Mais le Google I/O de ce soir a fait réaliser une chose à tout le monde : sur la voie vers la superintelligence, l'obstacle « techniquement impossible » n'existe plus. Ce qui reste, c'est seulement la vitesse du déploiement technique. Il y a six mois, nous débattions encore pour savoir si l'AGI était une bulle. Six mois plus tard, Google utilise déjà des Agents pour écrire des systèmes d'exploitation. L'accélération dans ce secteur dépasse déjà ce que l'intuition humaine peut percevoir.
Références :
-
https://youtu.be/wYSncx9zLIU
-
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-5/
-
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-omni/
-
https://antigravity.google/blog/introducing-google-antigravity-2-0
-
https://antigravity.google/blog/google-io-2026-feature-deep-dive
Éditeurs : Pêche Moïse





