Juin 2026, l'industrie des grands modèles de langage traverse un « tsunami open source » sans précédent : NVIDIA a publié un modèle hybride de 550B paramètres, Google offre une nouvelle version multimodale de Gemma, et Zhipu a open-sourcé son modèle phare sous licence très permissive.
Pratiquement tous les fabricants racontent la même histoire : intégrer plus de paramètres via une architecture Mixtes d'Experts (MoE), réduire les coûts grâce à une activation plus parcimonieuse, et utiliser une largeur de réseau élastique pour s'adapter à différents scénarios de déploiement.
En d'autres termes, toute l'industrie s'efforce de comprendre « comment caser plus de paramètres dans un budget de calcul équivalent ».
Mais un nouvel article de chercheurs de Mila, de l'Université Cornell et de l'Université de Montréal pose une question presque opposée : Que se passe-t-il si l'on n'ajoute aucun paramètre, mais que l'on se contente de « déplacer » les paramètres déjà existants dans le modèle ?

Titre de l'article : Tapered Language Models Adresse de l'article : https://arxiv.org/abs/2606.23670
Contexte : « L'égalité de traitement » négligée
Depuis le papier fondateur de 2017, « Attention Is All You Need », qui a introduit le Transformer, presque tous les modèles de langage partagent la même ossature, qu'il s'agisse du Transformer classique, des mécanismes d'attention à gâchette, des réseaux à mémoire récurrente, ou même des nouvelles architectures avec capacité de « mémoire pendant les tests ». Cette ossature est la suivante : empiler un certain nombre de « couches » structurellement identiques, chacune recevant exactement la même quantité de paramètres.

C'est comme une chaîne de restaurants qui équiperait chaque établissement, qu'il soit en centre-ville ou en banlieue, avec exactement le même nombre de chefs et le même équipement de cuisine, sans tenir compte des différences d'affluence. Cette approche « égalitaire » est simple et facile à maintenir, mais n'est pas nécessairement optimale.
Ces dernières années, de plus en plus de recherches sous différents angles ont souligné que les couches d'un modèle ne sont pas toutes aussi importantes les unes que les autres.
Les expériences de « sortie précoce » montrent que souvent, la réponse est déjà pratiquement déterminée avant même que le modèle n'atteigne la dernière couche.
Les recherches sur l'« élagage de couches » révèlent que supprimer certaines des dernières couches affecte à peine les performances du modèle.
Les études d'interprétabilité découvrent que les couches superficielles capturent des « informations de base » comme la grammaire, tandis que les couches profondes traitent des « informations avancées » comme la sémantique.
En clair, bien que les couches soient radicalement différentes, l'allocation des paramètres leur reste uniformément appliquée.
C'est la question centrale soulevée par cet article : puisque l'importance inégale des couches a déjà été prouvée, pourquoi leur « capacité cérébrale » devrait-elle encore être répartie de manière égale ?
Déplacer la « capacité cérébrale » vers l'avant
L'équipe de recherche a d'abord mené une expérience de validation simple et directe : diviser les couches d'un modèle Transformer de 440M paramètres en trois groupes (début, milieu, fin), et, tout en maintenant le nombre total de paramètres constant, élargir le « réseau feed-forward » (FFN, composant central du modèle responsable du stockage et du traitement de l'information, qu'on peut voir comme la « mémoire de travail » de chaque couche) d'un groupe tout en rétrécissant celui des deux autres.
Le résultat est très clair : concentrer la capacité sur les couches initiales (distribution « avec la tête plus lourde ») a fait chuter la perplexité du modèle sur l'ensemble de validation (la perplexité est une mesure de la précision prédictive d'un modèle de langage ; une valeur plus basse indique de meilleures prédictions) de 16.28 à 15.96. À l'inverse, concentrer la capacité sur les couches finales a fait grimper la perplexité à 17.29.

Pour le même nombre total de paramètres, simplement en changeant leur emplacement, la différence de performance atteint plus d'un point, ce qui représente un écart considérable dans l'évaluation des modèles de langage.
Cette découverte oriente la question vers une granularité plus fine : au lieu d'un regroupement en trois segments « brutaux », pourrait-on utiliser une courbe plus lisse pour faire décroître graduellement la capacité du début à la fin du modèle ?
Les chercheurs ont nommé cette approche les « Modèles de Langage Coniques » (Tapered Language Models, TLMs) : choisir n'importe quelle dimension du modèle qui détermine la quantité de paramètres (par exemple, la largeur du réseau feed-forward) et la faire décroître de façon monotone le long de la profondeur, tout en garantissant que la largeur moyenne de toutes les couches reste égale à la valeur fixe d'origine.
Ainsi, le nombre total de paramètres et le coût en calculs restent exactement les mêmes ; seule la forme de distribution passe d'un « rectangle » à un « coin de tarte ».
L'équipe a testé trois courbes de décroissance : linéaire, cosinus et en forme de S (Sigmoid).
La différence entre ces trois courbes est comparable à trois manières différentes de « plier boutique » :
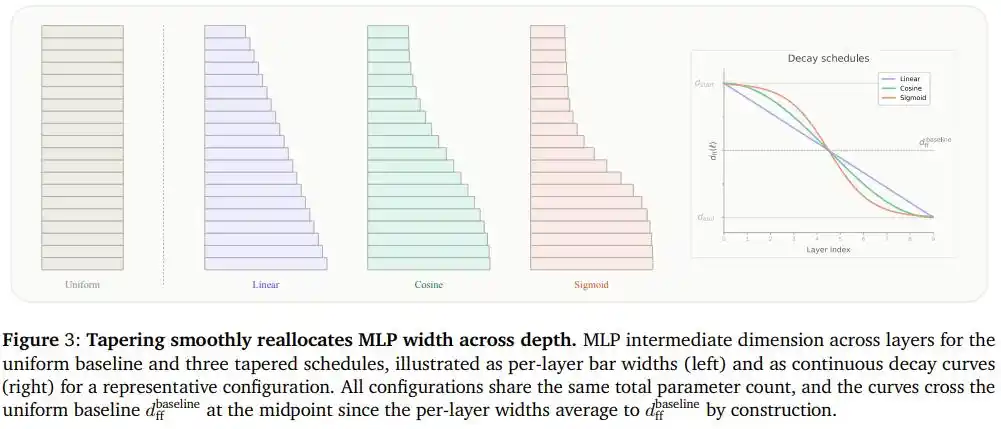
La décroissance linéaire ressemble à une fermeture à rythme constant, avec à peu près le même nombre de comptoirs fermés à chaque intervalle.
La décroissance en S ressemble à une annonce soudaine et concentrée de fermeture, la plupart des stands restant comme avant, et seule une petite partie au milieu se contractant rapidement.
La décroissance cosinus se situe entre les deux, avec des transitions douces aux extrémités et un resserrement progressif au milieu, ne sacrifiant pas la flexibilité des deux bouts de manière « brutale », ni ne distribuant les efforts de manière uniforme et manquant l'endroit où la contraction est la plus nécessaire.
Résultats expérimentaux : Un gain gratuit de 1.84 point
Après avoir testé cinq combinaisons de ratios de largeur et trois courbes sur le Transformer de 440M paramètres, la décroissance cosinus l'emporte largement : avec la configuration optimale (largeur initiale à 1.5 fois la référence, largeur finale à 0.5 fois la référence), la perplexité chute de 16.28 (ligne de base à distribution uniforme) à 14.44, soit une amélioration nette de 1.84 point, et ce sans ajouter un seul paramètre ou une seule opération en virgule flottante supplémentaire.
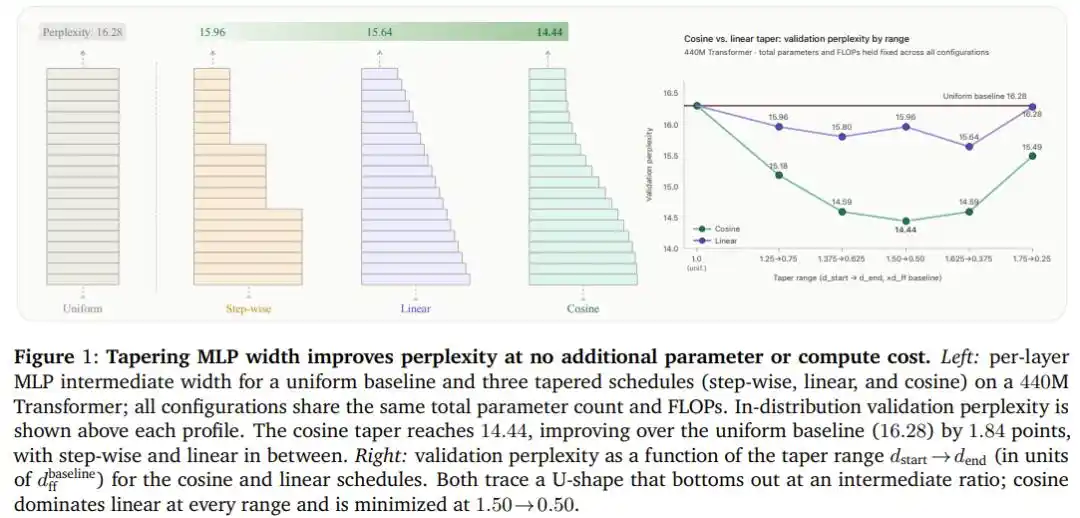
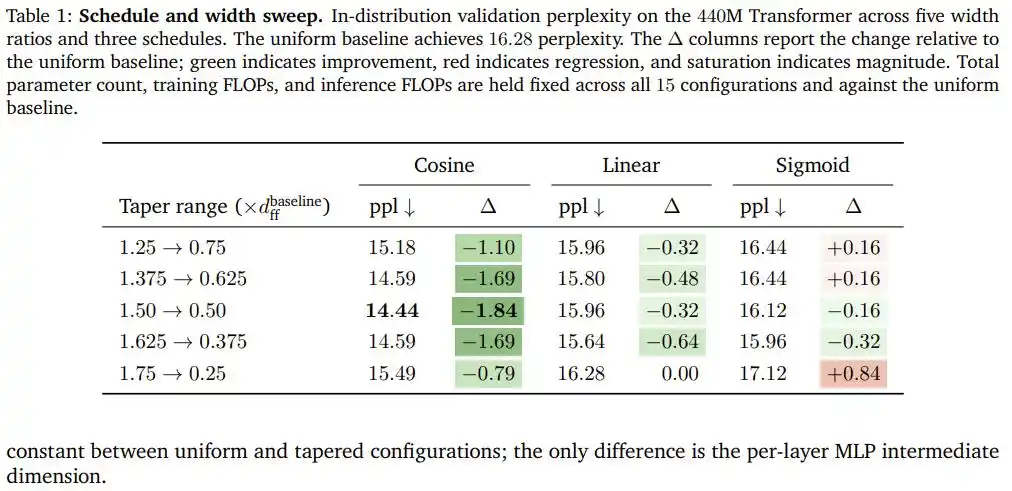
Plus crucial encore, cette conclusion n'est pas le fruit du hasard pour une architecture particulière.
L'équipe de recherche a appliqué la même configuration (décroissance cosinus, ratio largeur début/fin = 1.5/0.5) telle quelle à trois autres architectures structurellement très différentes : un modèle d'attention avec mécanisme à gâchette, Hope-attention (qui possède une capacité de « mémoire auto-modifiante »), et l'architecture Titans dotée d'un module de mémoire à long terme neuronal. Ils ont également validé l'approche à deux échelles plus grandes : 760M et 1.3B paramètres.
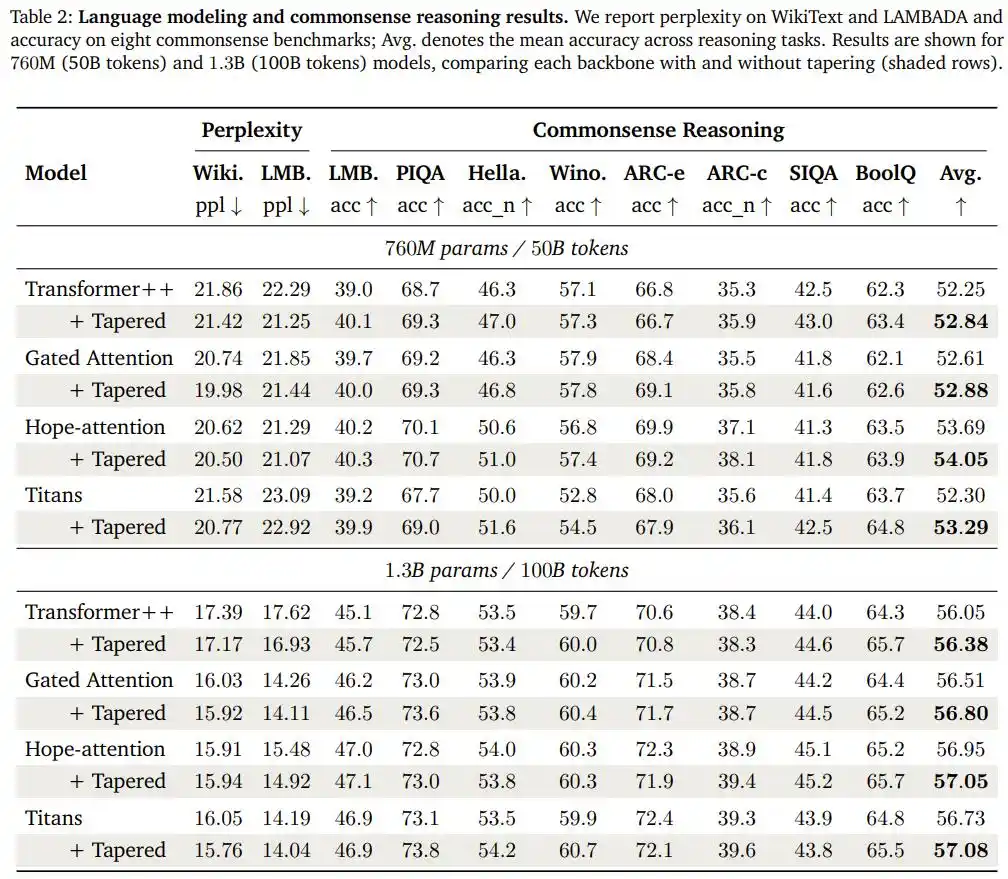
Le résultat : pour les quatre architectures et les deux échelles, dans les huit groupes de comparaison, les modèles modifiés en version « conique » ont tous amélioré leur précision moyenne sur un benchmark de raisonnement de bon sens, et ont tous réduit leur perplexité sur la tâche de prédiction linguistique LAMBADA.
Les chercheurs ont également effectué un test supplémentaire de recherche dans de longs textes (Needle-in-a-Haystack) pour confirmer que cette réallocation ne sacrifie pas la capacité du modèle à traiter des contextes longs.
Pour expliquer le phénomène sous-jacent, l'équipe a également mesuré, dans une série de modèles GPT-2, la similarité entre la sortie du « réseau feed-forward » de chaque couche et le flux d'information déjà présent. Ils ont découvert une régularité nette : plus on avance en profondeur dans le modèle, plus le contenu nouvellement écrit par chaque couche ressemble à l'information déjà existante. En d'autres termes, les couches postérieures « réaffirment » davantage des jugements déjà établis plutôt que de « créer » une nouvelle compréhension.
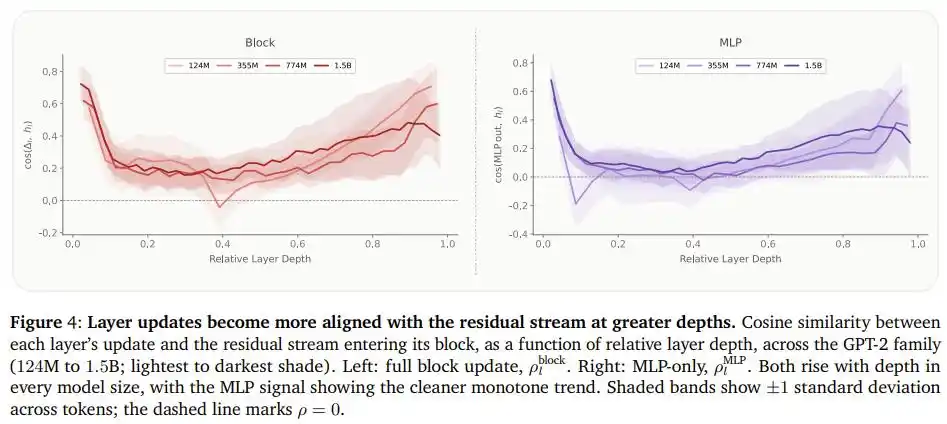
Cela corrobore parfaitement pourquoi il est logique de déplacer la capacité des couches postérieures vers les couches antérieures : ces dernières utilisent réellement cette « capacité cérébrale » supplémentaire, alors que les premières n'en ont pas besoin.
Conclusion
Cette recherche soulève essentiellement une proposition simple mais longtemps négligée : la capacité d'un modèle ne devrait pas être une ressource uniformément répartie, mais devrait plutôt être dirigée vers les endroits qui en ont véritablement besoin.
En 2026, alors que toute l'industrie rivalise pour savoir « qui a le plus de paramètres » ou « qui a l'architecture la plus parcimonieuse », cet article propose une alternative pratiquement à coût zéro : pas besoin de changer d'architecture, pas besoin d'ajouter de paramètres, il suffit simplement de changer la « forme » de l'allocation.
Les chercheurs reconnaissent également que la configuration optimale actuelle a été déterminée en ajustant un modèle de 440M paramètres. Savoir s'il existe des « recettes dédiées » plus adaptées à différentes échelles et architectures reste une question ouverte.
Mais ce qui mérite encore plus d'attention, c'est que l'article indique que cette approche ne se limite pas aux modèles de langage – les Transformers visuels, les modèles de diffusion, les modèles multimodaux, ont presque tous hérité du même réglage par défaut de « répartition égale par couches ». Si la forme de l'allocation de capacité est elle-même une dimension de conception longtemps négligée, alors ce « levier gratuit caché à la vue de tous » vient peut-être tout juste d'être remarqué.
Présentation de l'équipe
L'article est le fruit d'une collaboration entre Reza Bayat de Mila (Institut des Algorithmes d'Apprentissage de Montréal), Ali Behrouz de l'Université Cornell, et Aaron Courville, cofondateur de Mila et professeur à l'Université de Montréal.
Ali Behrouz est actuellement chercheur chez Google Research et doctorant à l'Université Cornell. Ces deux dernières années, il a participé à la conception de plusieurs nouvelles architectures ayant suscité un large intérêt, notamment l'architecture Titans capable « d'apprendre et de mémoriser pendant la phase de test », ainsi que les frameworks Atlas et « Nested Learning » (Apprentissage Imbriqué) qui ont suivi. Il se concentre depuis longtemps sur la manière de permettre aux modèles d'utiliser et de stocker plus efficacement les informations de contexte à long terme.
Aaron Courville est un chercheur chevronné dans le domaine de l'apprentissage profond, titulaire d'une Chaire IA CIFAR. Il promeut depuis longtemps la recherche fondamentale en apprentissage profond aux côtés de Yoshua Bengio, avec une expertise approfondie en apprentissage de représentations et en modèles génératifs. Il est également l'un des auteurs des Réseaux Antagonistes Génératifs (GAN) et a co-écrit l'ouvrage classique « Deep Learning » avec Ian Goodfellow et Bengio.
Cet article provient du compte WeChat officiel « Machine Heart » (ID : almosthuman2014), auteur : suivi de l'IA





