【Introduction】GPT-5.5 démasqué pour sa « fausse réflexion », remplacé secrètement par mini après deux heures d'utilisation. Un abonnement à 200 dollars par mois pour un « cerveau de Schrödinger ». La commande trace apporte la preuve flagrante, les documents officiels l'admettent eux-mêmes. Les plaintes affluent : OpenAI, à qui tu veux faire croire ça ?
ChatGPT est à nouveau accusé de « perte d'intelligence » !
C'est ces derniers jours que X a explosé le premier.
L'utilisateur Lisan al Gaib a découvert qu'après une ou deux heures d'utilisation, GPT-5.5 devenait soudainement stupide, chaque requête obtenant une réponse immédiate, avec une qualité en chute libre.
Mais l'interface affichait toujours « GPT-5.5 Extended Thinking ».
En d'autres termes, l'étiquette de réflexion était toujours là, mais la réflexion elle-même avait disparu.

200 dollars/mois, pour un « modèle de Schrödinger »
Sur le forum des développeurs d'OpenAI, un post de plainte a fait exploser les discussions.
Agentify.sh a déclaré que GPT-5.5 perdait soudainement sa capacité à suivre les instructions après une certaine utilisation.
On le voyait annoncer avec enthousiasme qu'il avait « réparé » quelque chose, mais la qualité du code était si mauvaise qu'elle provoquait des retours en arrière massifs.
Des tâches d'interface utilisateur que 5.5-med gérait facilement auparavant, maintenant il ne parvient même pas à faire les modifications les plus simples.
Passer à 5.5-high, inutile. Monter encore à xhigh, toujours pas.
Et là où xhigh pouvait tourner pendant plusieurs heures auparavant, la durée est maintenant clairement raccourcie.
Dès la publication du post, la section des commentaires a explosé.
Certains sont directement revenus à la version 5.4.
D'autres utilisaient le niveau le plus élevé, xhigh, mais constataient une « baisse notable par rapport à la semaine dernière, des erreurs fréquentes dans les tâches longues, ne suit pas du tout le flux de travail ».
D'autres rapportaient des situations encore plus absurdes : « même les requêtes simples mettent une éternité, si tu l'interromps pour corriger la direction, il t'ignore complètement et continue son plan erroné précédent ».
Exactement, tout le monde décrivait le même phénomène – le cerveau de GPT avait été discrètement remplacé, sans qu'on sache quand.
La performance actuelle de GPT-5.5 est similaire à celle de 5.3, sans exagérer. Les premiers jours étaient incroyables, maintenant on ne retrouve plus aucune trace du modèle d'origine.

Ce n'est pas une impression, OpenAI l'écrit noir sur blanc
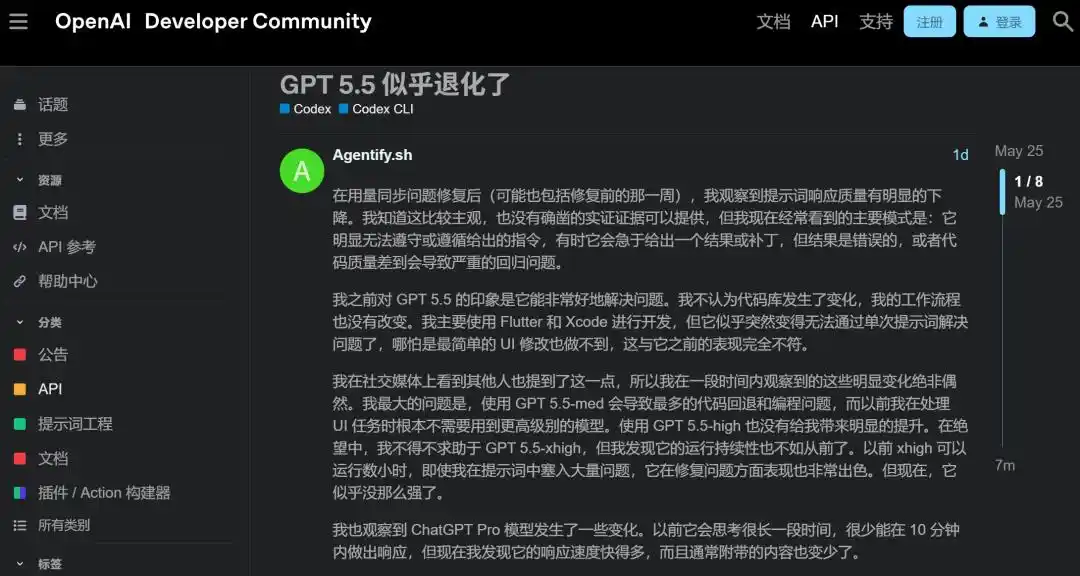
Pour vérifier, Lisan al Gaib a réalisé un test comparatif.
Avec le même compte, l'utilisation d'Extended Thinking côté ChatGPT donnait des résultats médiocres, alors que le passage à Codex avec xhigh rétablissait immédiatement des performances normales.
Ses mots exacts furent que Codex est « littéralement 4 milliards de fois plus intelligent que ce truc ».
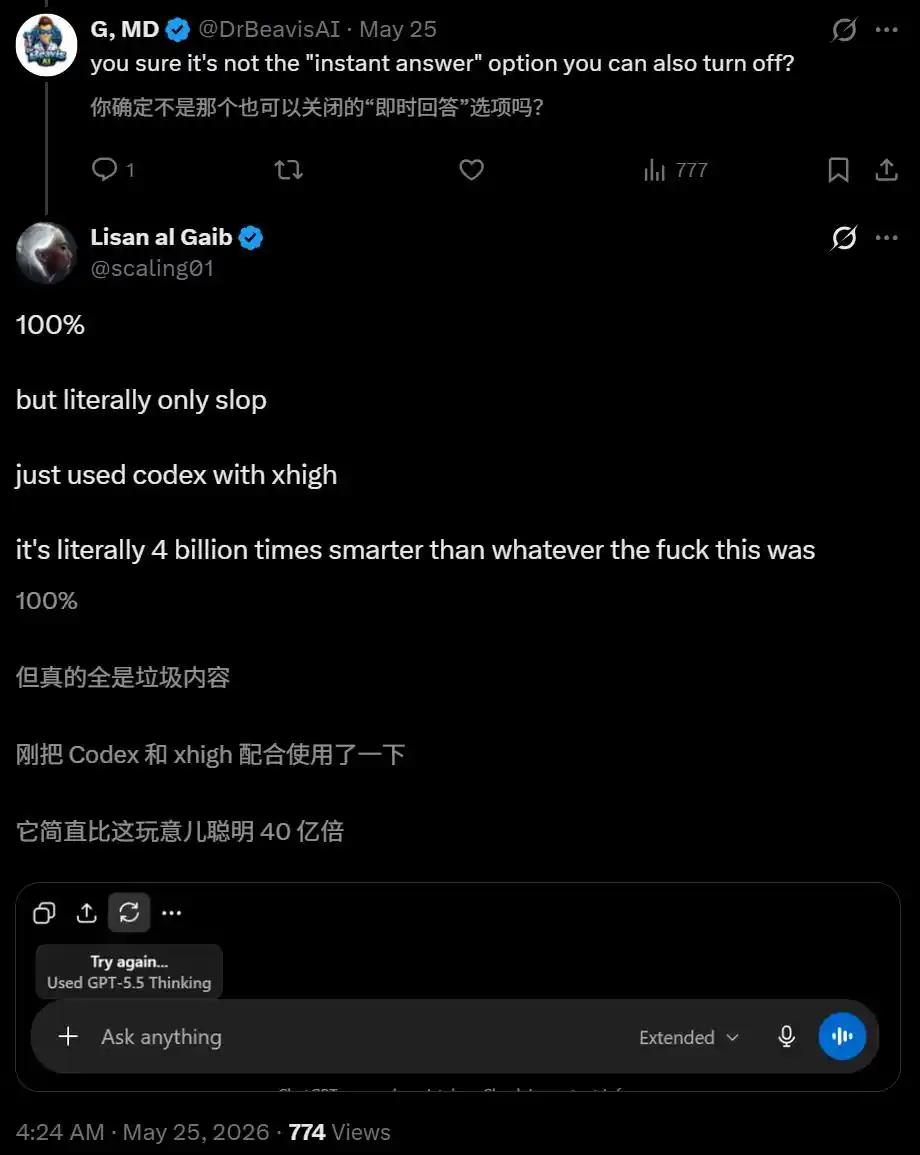
Le développeur Andrew Curran a eu une idée ingénieuse – demander directement au modèle « Quelle est la date limite de tes données d'entraînement ? »
Le modèle a répondu : août 2025.
Problème : la date limite de GPT-5.5 Thinking est décembre. Août, c'est la date limite de la version Instant !
Autrement dit, il avait sélectionné Thinking, mais le système exécutait en réalité Instant.
L'étiquette du modèle sur l'interface n'avait pas changé d'un seul mot, mais le modèle en arrière-plan avait été discrètement remplacé...
Le plus drôle, c'est que cette fois, OpenAI a lui-même fourni la preuve dans sa documentation d'aide.
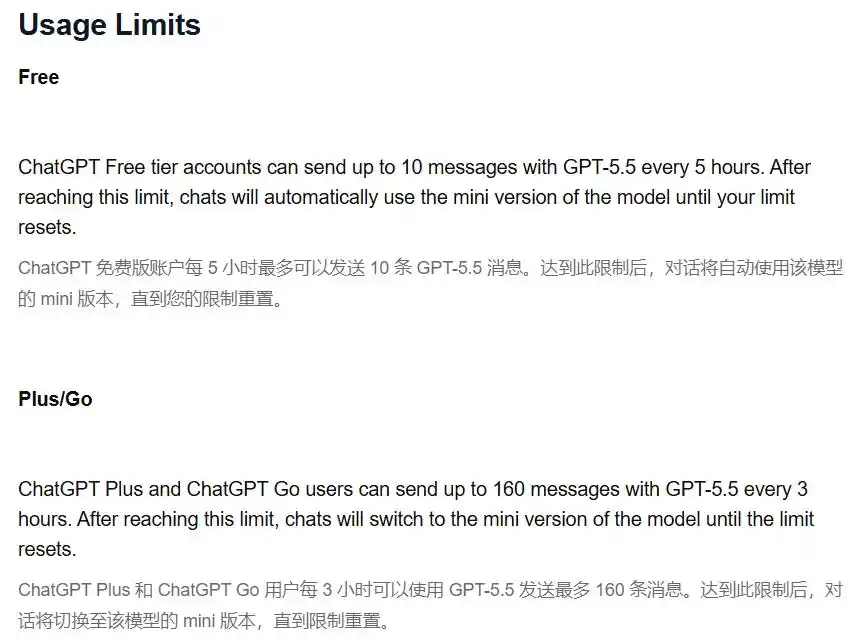
Selon les explications officielles de l'OpenAI Help Center, les utilisateurs Plus peuvent envoyer un maximum de 160 messages GPT-5.5 toutes les 3 heures.
Une fois ce quota épuisé, le système bascule silencieusement vers le modèle mini, jusqu'au réinitialisation du quota.
Notez le mot « silencieusement ».
Aucune alerte contextuelle, aucun changement d'étiquette de modèle, aucun retour visuel.
Vous pensez toujours utiliser le modèle phare, alors que de l'autre côté, on vous a discrètement passé au mini.
Les utilisateurs Pro ne doivent pas non plus trop se réjouir.
Le mode de réflexion Heavy, le niveau de raisonnement le plus élevé réservé aux Pro, est également soumis à une limitation de capacité lorsque la charge du serveur est élevée. Là aussi, sans avertissement.
En d'autres termes, un abonnement Pro à 200 dollars/mois achète un service qui peut à tout moment être victime d'un « échange de têtes ».

Cette opération de « l'étiquette reste, le cerveau change » avait été repérée encore plus tôt côté Codex.
En février de cette année, un problème (issue) est apparu sur GitHub : un utilisateur Pro utilisant la commande trace a découvert qu'il demandait GPT-5.3 Codex, mais que le modèle réellement renvoyé était GPT-5.2.
Pas même 5.2 Codex, mais la version de base inférieure, 5.2.
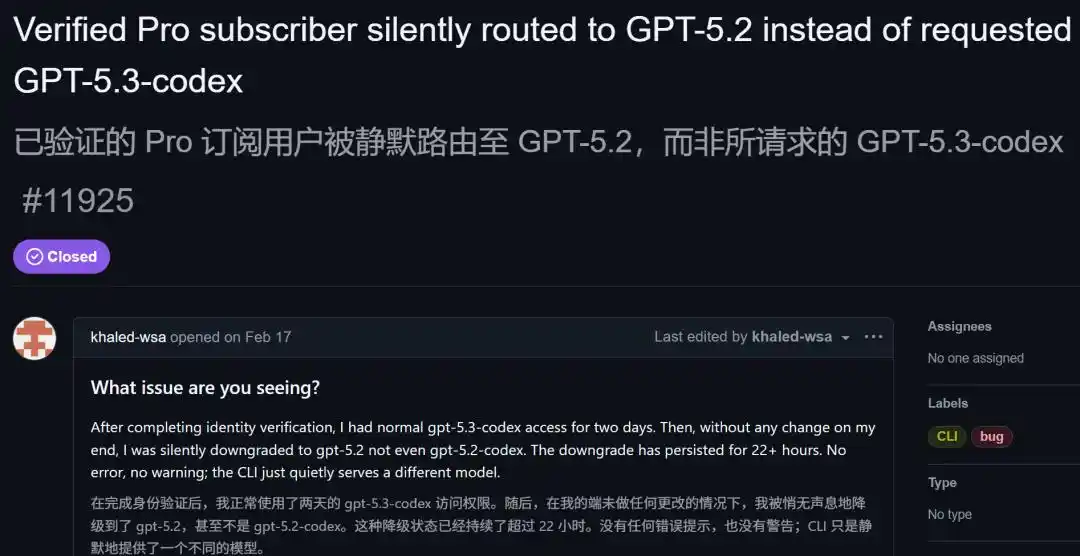
Il a partagé la commande de reproduction :
- RUST_LOG='codex_api::sse::responses=trace' codex exec --skip-git-repo-check -s read-only -m 'gpt-5.3-codex' 'hi' 2>&1 >/dev/null | rg -o --replace '$1' '"model":"([^"]+)"' | head -n1
- Sortie : gpt-5.2-2025-12-11
- Attendu : gpt-5.3-codex
Plusieurs utilisateurs Pro ont confirmé la même dégradation sous le même issue.
Et cette dégradation est « collante », elle ne se rétablit pas d'elle-même, et il n'y a aucune explication.

Mieux encore, le jour même du lancement de GPT-5.5 en avril, des utilisateurs ont signalé que la vitesse du mode Fast était similaire à celle du Standard, mais que la facturation se faisait toujours au tarif Fast.
Une tâche simple a pris 7 minutes 49 secondes, alors que normalement cela devrait prendre 5 à 6 minutes.
OpenAI a reconnu, et puis... plus rien
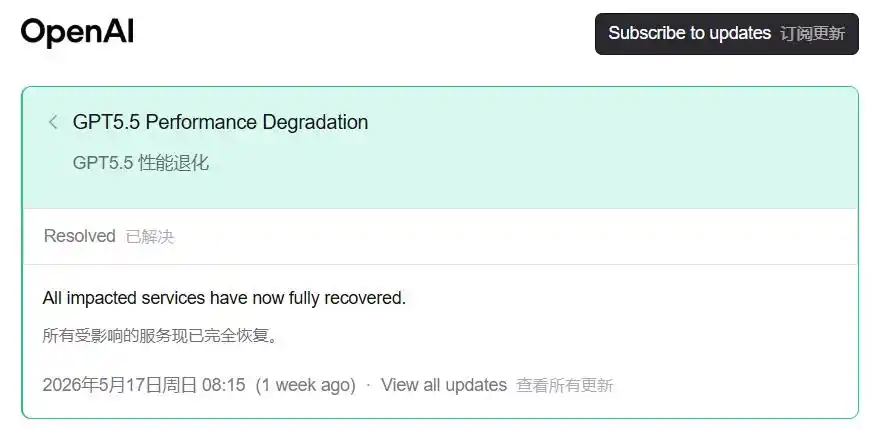
Le 15 mai, une entrée est apparue sur la page de statut d'OpenAI.
Dégradation des performances GPT5.5 : Nous enquêtons sur les problèmes de dégradation des performances de GPT-5.5 signalés par certains utilisateurs.
Le 17 mai, le statut a été mis à jour à « Résolu ».
Mais d'après la chronologie des posts sur le forum, les plaintes de perte d'intelligence des 24-26 mai étaient encore plus fortes que celles de la vague du 15 mai.
Soit le problème « résolu » est revenu, soit il n'a jamais été vraiment résolu.
Chaque mise à niveau est une « controverse de perte d'intelligence »
Bien que toutes les entreprises fassent face à des critiques de « modèle qui devient stupide », OpenAI, de GPT-5 à GPT-5.5, n'a manqué aucune de ces controverses lors de chaque mise à jour.
À chaque fois OpenAI dit enquêter, à chaque fois il dit que c'est résolu, et puis la version suivante recommence.
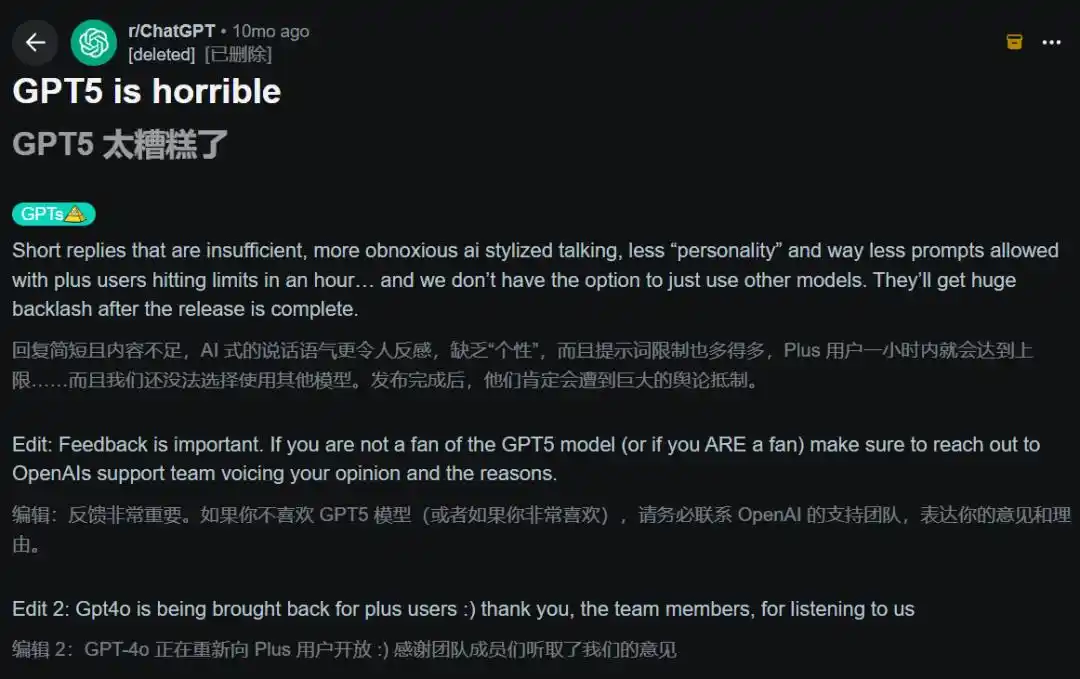
Août 2025, lancement de GPT-5. Le titre du post populaire sur Reddit était directement « GPT-5 est trop nul ». Les utilisateurs se plaignaient de réponses courtes, de plus de refus, de moins de personnalité.
OpenAI a été contraint de restaurer d'urgence l'option GPT-4o. Altman a lui-même reconnu lors d'un AMA Reddit que c'était « plus cahoteux que prévu ».
Décembre 2025, GPT-5.2. Qualité de traduction en régression, invention d'API inexistantes, refus d'exécuter des instructions de style que 5.1 accomplissait facilement.
Février 2026, GPT-5.3-Codex. Les utilisateurs Pro ont été dégradés silencieusement vers la 5.2, preuve flagrante par la commande trace.
Mars 2026, GPT-5.4. Un post « GPT-5.4 a clairement régressé dans Codex » est apparu sur le forum communautaire d'OpenAI, toutes les réponses des internautes le confirmant.
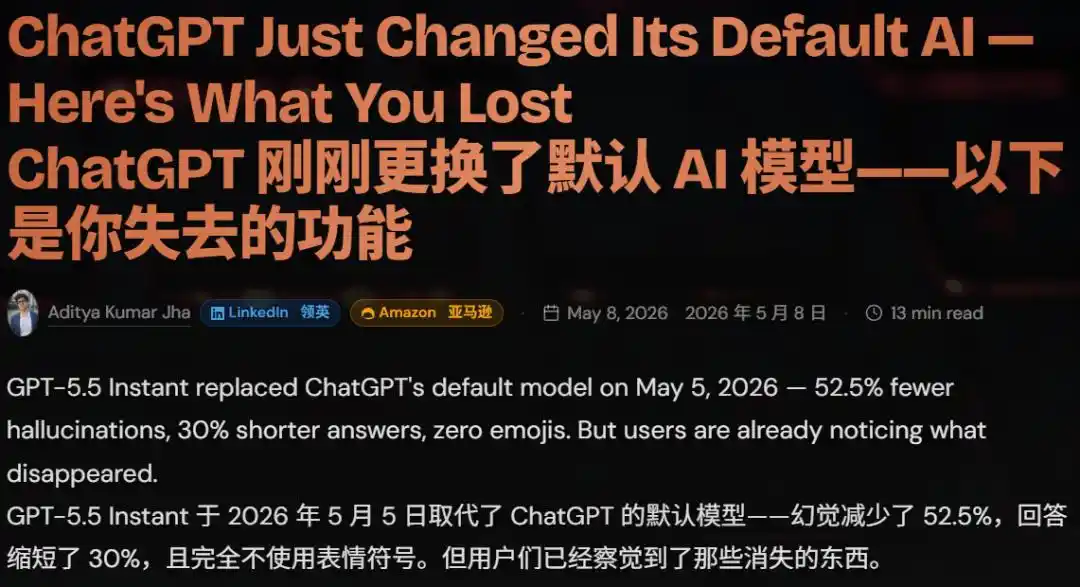
Début mai 2026, GPT-5.5 Instant lancé. Longueur des réponses réduite de 30%, les emojis ont presque disparu. Résumé des internautes : la précision a augmenté, mais la chaleur (température) a disparu.
Fin mai 2026, c'est-à-dire maintenant. Les plaintes de perte d'intelligence du mode Thinking éclatent à nouveau.
Lisan al Gaib révèle que depuis qu'il a mené la bataille pour les quotas ChatGPT Plus lors du lancement de GPT-5, il « reçoit chaque semaine des messages privés comme celui-ci ».
Le dernier en date est une demande d'aide pour récupérer le xhigh/heavy thinking.
Le jour où il est le plus fort aux benchmarks, c'est le jour du lancement
chatgptdisaster.com a compilé 1087 plaintes vérifiées d'utilisateurs, dont un scénario mentionné de façon répétée appelé « défaillance de la couche de routage » : l'interface affiche GPT-5.5 Pro, mais la sortie est d'un tout autre niveau.
Les utilisateurs décrivent un modèle reproductible : après une longue session, le modèle commence à « ignorer complètement ce que vous dites », mais le sélecteur de modèle affiche toujours l'étiquette haut de gamme.

L'annotation la plus absurde est que le mécanisme de basculement automatique vers mini après épuisement des 160 messages/3 heures pour les utilisateurs Plus est décrit comme une « fonctionnalité » dans la documentation officielle d'OpenAI.
Pourquoi en est-il ainsi ? Lisan al Gaib analyse que la réponse tient en deux mots : économiser de l'argent.
Le resserrement entre puissance de calcul et rentabilité affecte tout le monde. On économise partout, on ne laisse passer aucune opportunité de réduire les coûts.
Pourtant, la même semaine où les utilisateurs de GPT-5.5 se plaignent collectivement, la silhouette de GPT-5.6 est déjà apparue dans les logs d'arrière-plan de Codex.
Nom de code interne iris-alpha, contexte de 150 millions de tokens, la probabilité de sortie en juin donnée par Polymarket dépasse les 85%.
D'un côté, les utilisateurs de 5.5 ne parviennent même pas à conserver une expérience de base, de l'autre, 5.6 exécute déjà discrètement du trafic réel en arrière-plan.
Telle est la course à l'ASI en 2026.
La vitesse de création de nouveaux modèles s'accélère, mais faire fonctionner correctement un ancien modèle pendant toute une session devient de plus en plus difficile.
Le jour où il est le plus fort aux benchmarks est toujours le jour du lancement, et chaque jour suivant est un GPT de Schrödinger.

Référence : https://x.com/scaling01/status/2058643470357590058?s=20
Cet article provient du compte public WeChat « New Zhiyuan », auteur : ASI Apocalypse ; éditeur : Moïse





