Il est bien connu que l'entraînement des grands modèles est extrêmement coûteux.
Mais on sait aussi que réduire la précision de l'entraînement permet de diminuer significativement ces coûts. DeepSeek-V3 a utilisé l'entraînement en FP8 pour réduire les coûts à 5,6 millions de dollars, ce qui a impressionné toute l'industrie.
Après le succès du FP8, le secteur continue d'explorer les limites des basses précisions : en passant du FP8 au FP4, de combien pourrait-on encore réduire les coûts d'entraînement ?
Théoriquement, le débit de calcul en FP4 peut être le double de celui du FP8. Les séries NVIDIA Blackwell et AMD MI350 supportent déjà nativement les opérations FP4 au niveau matériel, la première affichant une puissance de calcul FP4 théorique allant jusqu'à 4500 TOPS (éparse) sur le B200. Le matériel est prêt, mais le logiciel et les algorithmes sont bloqués par un problème :
Entraîner de grands modèles de zéro en FP4 rend le processus d'entraînement très instable.
Au cours des deux dernières années, des travaux comme LLM-FP4, NVFP4 pré-entraînement ont exploré cette voie, mais peu de solutions ont pu exécuter proprement un pré-entraînement complet en 4 bits, tout en maintenant une qualité de convergence proche du FP8.
Pire encore, la cause de l'instabilité restait floue. L'analyse suggérait que l'instabilité de l'entraînement en FP4 provenait probablement d'un manque de stochasticité (aléatoire).
Mais récemment, AMD, en collaboration avec l'Université d'État de Pennsylvanie, a publié un article qui bouleverse cette vision traditionnelle, offrant un nouveau diagnostic clair pour l'entraînement natif en FP4.

- Titre de l'article : Pretraining large language models with MXFP4 on Native FP4 Hardware
- Lien de l'article : https://arxiv.org/abs/2605.09825
Cet article a réalisé un pré-entraînement complet de Llama 3.1-8B en utilisant le format MXFP4 sur des GPU AMD Instinct MI355X, avec une vitesse d'entraînement de bout en bout 9 à 10 % plus rapide que la ligne de base FP8, pour seulement 8 à 9 % de jetons supplémentaires consommés. C'est actuellement la première expérience complète de pré-entraînement d'un grand modèle réalisée sur du matériel natif FP4 (et non en simulation logicielle).
Plus important encore, l'article révèle le problème central : la source de l'instabilité de l'entraînement en FP4 n'est pas le manque de stochasticité, mais l'accumulation et l'amplification d'erreurs structurelles de micro-mise à l'échelle le long de chemins de gradient sensibles.
Qu'est-ce que le MXFP4 ?
Avant d'analyser l'article, il est nécessaire de comprendre le format de données MXFP4.
La quantification entière traditionnelle utilise généralement un facteur d'échelle unique pour tout un tenseur. La conception centrale du MXFP4 s'appelle la « micro-mise à l'échelle » (Micro-scaling) : un tenseur est découpé en petits blocs (par exemple, par groupes de 32 éléments), et un exposant partagé (format E8M0) est attribué à chaque bloc. Chaque élément à l'intérieur du bloc est représenté par un nombre flottant sur 4 bits. La formule de reconstruction peut s'écrire :
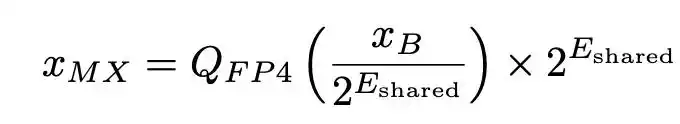
où E_shared est l'exposant maximum du bloc, et Q_FP4 est l'arrondi au plus proche vers une valeur représentable en flottant 4 bits.
L'avantage de la micro-mise à l'échelle est que chaque petit bloc a sa propre plage dynamique et n'est pas « pris en otage » par des valeurs aberrantes globales. Cela améliore considérablement la qualité de représentation par rapport à une quantification globale naïve sur 4 bits.
Mais même avec la micro-mise à l'échelle, l'entraînement en FP4 reste instable.
Expérience d'investigation : la racine de l'instabilité
L'équipe de recherche a d'abord conçu une expérience de contrôle d'investigation étape par étape.
Un calcul complet de couche linéaire de Transformer implique trois opérations de multiplication matricielle généralisée (GEMM) :
Fprop (propagation avant) : calcule Y = XW^T, produisant les valeurs d'activation.
Dgrad (gradient de l'activation) : calcule ∇X = ∇Y · W, renvoyant le gradient vers l'entrée.
Wgrad (gradient des poids) : calcule ∇W = (∇Y)^T · X, produisant le gradient utilisé pour mettre à jour les poids.
L'équipe a maintenu tous les autres facteurs constants, en remplaçant progressivement ces trois opérations du FP8 vers le MXFP4, observant l'impact de chaque étape sur la convergence. Toutes les expériences ont été exécutées sur des AMD Instinct MI355X en utilisant les cœurs tensoriels FP4 natifs, sans dépendre de simulations logicielles.
La tâche d'entraînement suit la configuration standard MLPerf, pré-entraînant Llama 3.1-8B sur l'ensemble de données C4, l'objectif de convergence étant d'atteindre une perplexité de validation de 3,3.
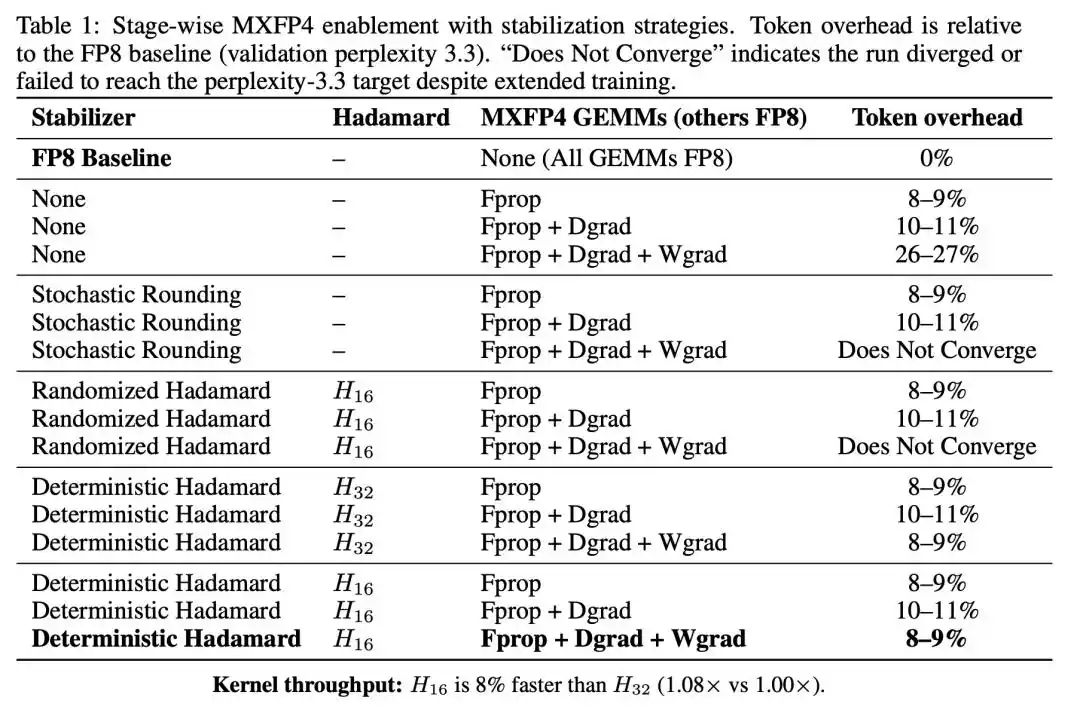
Les deux premières étapes n'ont entraîné qu'une augmentation modérée du nombre de jetons consommés, mais dès que le Wgrad a également été basculé en MXFP4, cette augmentation a bondi à 26-27 %.
Wgrad est le goulot d'étranglement de l'entraînement en FP4. La propagation avant et le gradient de l'activation sont relativement tolérants à la quantification FP4, mais dès que le gradient des poids est quantifié en 4 bits, la qualité de convergence se dégrade significativement.
L'intuition dominante dans l'industrie jusqu'alors était que l'erreur de quantification FP4 est essentiellement un problème de bruit, et qu'on pouvait donc « lisser » la distribution de l'erreur en injectant de la stochasticité. Deux stratégies courantes sont :
Arrondi stochastique (Stochastic Rounding) : introduire de l'aléatoire lors de la quantification, de sorte que l'espérance de l'erreur d'arrondi soit nulle.
Rotation de Hadamard aléatoire (Randomized Hadamard) : utiliser une transformée de Hadamard avec retournement de signe aléatoire pour disperser la distribution des données avant quantification.
Lorsque Wgrad est quantifié, les deux stratégies de stochasticité n'ont pas stabilisé l'entraînement, mais ont au contraire directement conduit à une divergence. La stochasticité n'a pas aidé ; elle a plutôt introduit davantage d'erreurs de quantification effectives sur le chemin critique du gradient.
En revanche, la rotation de Hadamard déterministe a réduit la surconsommation de jetons de 26-27 % à 8-9 %, la trajectoire d'entraînement suivant étroitement la ligne de base FP8.
C'est un résultat très révélateur. Les rotations de Hadamard aléatoire et déterministe sont toutes deux des transformations orthogonales, elles peuvent toutes deux disperser l'énergie des valeurs aberrantes, et en théorie, leurs effets d'atténuation de l'erreur de quantification devraient être similaires. Mais leurs performances dans le scénario Wgrad sont diamétralement opposées, ce qui révèle la nature du problème :
L'instabilité de l'entraînement en FP4 est pilotée par des erreurs structurelles générées par la micro-mise à l'échelle MXFP4 sur des chemins de gradient sensibles. Les stratégies de stochasticité échouent car elles introduisent à chaque étape des modèles d'erreur différents, et ces modèles d'erreur variables s'accumulent le long du chemin de gradient, amplifiant ainsi l'instabilité. La rotation déterministe est efficace précisément parce qu'elle applique la même transformation à chaque étape, rendant le modèle d'erreur cohérent et évitant ainsi l'accumulation d'erreurs.
Efficacité de bout en bout : Débit par étape +20 %, accélération globale de 9-10 %
Après avoir ajouté la rotation de Hadamard déterministe et l'utilisation complète de MXFP4 sur tout le processus, les données d'efficacité sont les suivantes :

Le débit par étape d'entraînement a augmenté de 20 %. En déduisant les 8-9 % supplémentaires de jetons consommés, l'accélération globale de bout en bout reste de 9-10 %.
Étant donné que la précision est directement réduite de 8 bits à 4 bits, cette qualité de convergence et cette ampleur d'accélération sont toutes deux remarquables.
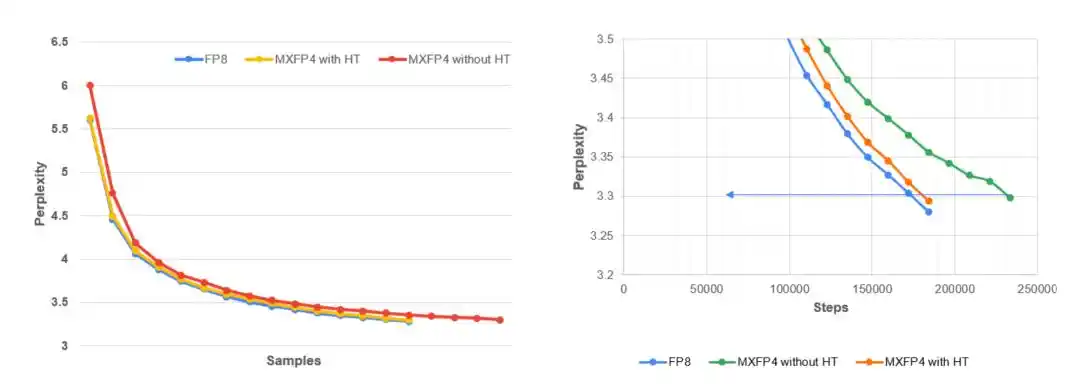
Graphique de gauche : Courbe de la perplexité de validation de Llama 3.1–8B en fonction du nombre de jetons d'entraînement lors du pré-entraînement MLPerf sur l'ensemble de données C4. Les résultats montrent que MXFP4 + Hadamard déterministe est très proche des performances du FP8, tandis que l'utilisation complète de MXFP4 sans stabilisation converge plus lentement et est moins stable. Graphique de droite : Vue agrandie de la fin de l'entraînement. L'objectif de perplexité MLPerf est de 3,3. Par rapport à l'exécution MXFP4 non stabilisée, le Hadamard déterministe (H16) maintient une cohérence beaucoup plus étroite avec la ligne de base FP8.
Il est important de noter que les auteurs soulignent explicitement dans l'article une limitation importante : l'efficacité de ce schéma d'entraînement FP4 (ensemble de données MLPerf C4 + Llama 3.1-8B) a été validée, mais on ne peut pas supposer qu'il puisse être transposé tel quel à tous les modèles, tous les ensembles de données et toutes les méthodes d'entraînement. Le comportement de l'entraînement en FP4 peut être hautement dépendant du contexte, et les stratégies de stabilisation spécifiques doivent être revalidées en fonction du scénario.
Conclusion
Placé dans le contexte industriel plus large, cet article a au moins trois niveaux de signification.
Premier niveau : Il répond à un « pourquoi » fondamental. Les travaux précédents sur l'entraînement FP4 se concentraient surtout sur « comment éviter l'instabilité ». Cet article offre pour la première fois un diagnostic de cause à effet clair : l'instabilité provient d'erreurs structurelles de micro-mise à l'échelle sur le chemin Wgrad, et non d'un manque de stochasticité. Ce diagnostic a une valeur méthodologique en soi ; il indique aux chercheurs futurs que face à l'instabilité dans l'entraînement en basse précision, il faut d'abord rechercher des sources d'erreurs structurelles, et non ajouter aveuglément de la stochasticité.
Deuxième niveau : Il fait passer le FP4 du domaine « exclusif à l'inférence » vers « utilisable pour l'entraînement ». Le consensus industriel précédent était que le FP4 n'était adapté qu'à la quantification pour l'inférence, l'entraînement nécessitant au moins du FP8. Le fait que NVIDIA mette en avant le FP4 pour l'inférence et non pour l'entraînement sur Blackwell reflétait ce jugement. Cet article a exécuté un pré-entraînement complet sur du matériel natif FP4, ce qui signifie que la puissance de calcul FP4 présente sur les MI355X et Blackwell, initialement destinée à l'inférence, pourrait théoriquement aussi être utilisée pour l'entraînement. Si l'entraînement en FP4 s'avère viable sur des modèles plus grands et dans davantage de scénarios, la puissance de calcul disponible pour l'entraînement sur le matériel existant pourrait virtuellement doubler.
Troisième niveau : Il utilise une norme ouverte OCP. MXFP4 fait partie de la norme OCP Microscaling Formats, soutenue conjointement par sept entreprises : AMD, NVIDIA, Intel, Meta, Microsoft, Arm et Qualcomm. Le fait de s'appuyer sur une norme ouverte signifie que cette méthode est portable sur du matériel de différents fabricants, sans être enfermée dans un écosystème unique.
Du FP16 au FP8, DeepSeek-V3 a déjà prouvé que réduire la précision de moitié peut considérablement abaisser les coûts d'entraînement. Du FP8 au FP4, cet article représente une première étape cruciale. Chaque réduction de la précision transforme l'économie de l'entraînement des grands modèles.
Cet article provient du compte WeChat « 机器之心 » (ID : almosthuman2014), éditeur : Leng Mao (冷猫).







