Remettant en question le paradigme traditionnel du pré-entraînement des grands modèles, l'ancien élève de Tsinghua Wang Guan et son équipe présentent une nouvelle réalisation :
Ils ont remplacé le Transformer standard par un modèle récurrent hiérarchique (HRM), proposant un pré-entraînement efficace HRM-Text qui dépasse la simple loi de mise à l'échelle (Scaling).

Lien de l'article : https://arxiv.org/abs/2605.20613
En utilisant environ 100 à 900 fois moins de tokens d'entraînement et une estimation de puissance de calcul 96 à 432 fois inférieure à celle du modèle de référence standard, HRM-Text parvient tout de même à offrir des performances comparables à des modèles open source de 2B à 7B de paramètres.
Par ailleurs, avec seulement 1 milliard de paramètres, 40 milliards de tokens non répétitifs, et un coût d'entraînement d'environ 1500 dollars, HRM-Text obtient les résultats suivants sur les benchmarks principaux : MMLU 60.7 %, ARC-C 81.9 %, DROP 82.2 %, GSM8K 84.5 %, MATH 56.2 %.
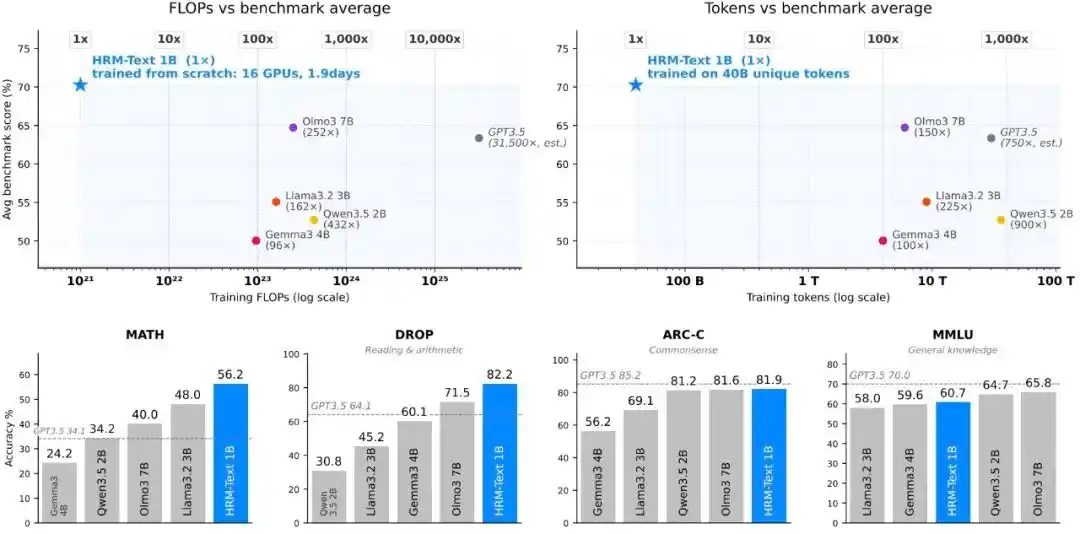
Figure | Efficacité du pré-entraînement.
Sur cette base, ils affirment clairement : Un biais structurel et des objectifs d'entraînement ciblés peuvent significativement abaisser le seuil du pré-entraînement. Ce schéma d'entraînement pourrait rendre viable l'entraînement de modèles de base à partir de zéro.
Comment HRM-Text est-il conçu ?
Le pré-entraînement des grands modèles de langage (LLM) dépend de plus en plus d'un petit nombre d'organisations disposant de ressources suffisantes en calcul et en données. Entraîner un modèle de base compétitif nécessite souvent des milliers de milliards de tokens, des milliers de GPU, voire un investissement en puissance de calcul de plusieurs millions de dollars.
Cependant, le mode d'entraînement actuel n'est pas efficace. Une grande partie des calculs est consommée par des tokens sans rapport comme les prompts (consignes), le remplissage de format ou le bruit des pages web, ce qui fait que beaucoup de puissance d'entraînement ne sert pas directement à l'inférence.
Dans ce travail, l'équipe de recherche a repensé l'architecture et les objectifs d'entraînement pour rendre le pré-entraînement de HRM-Text relativement plus efficace.
Architecture : Adoption d'un modèle récurrent hiérarchique à double échelle de temps, divisant les calculs en un module lent (H) et un module rapide (L). Alors qu'un Transformer standard effectue une seule passe avant par token, le HRM effectue des mises à jour récursives multiples sur le même token. Les modules H et L ne représentent chacun qu'environ la moitié des paramètres du noyau récurrent. Globalement, la quantité de calcul équivaut approximativement à dérouler récursivement le même ensemble de paramètres 4 fois, augmentant ainsi la profondeur de calcul sans accroître le nombre de paramètres.
Objectif d'entraînement : Abandon de l'approche standard de pré-entraînement autorégressif sur le texte complet. L'entraînement se fait directement sur des paires (instruction, réponse), en calculant la perte uniquement sur la partie réponse, et en utilisant un masque PrefixLM pour permettre une attention bidirectionnelle sur la partie instruction et une génération sous masque causal sur la partie réponse.
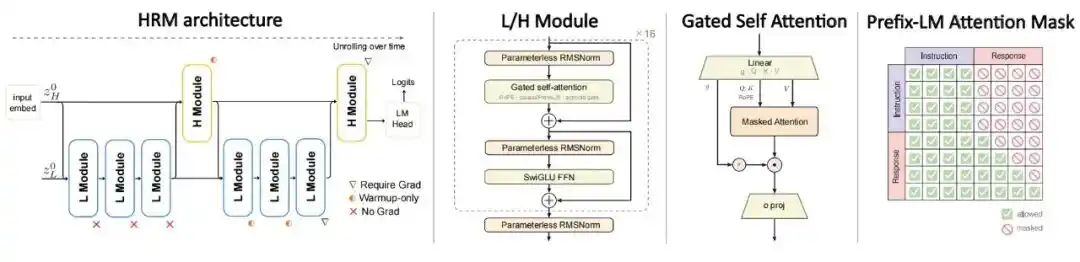
Figure | Architecture de HRM-Text.
Pour améliorer la stabilité de l'entraînement récursif, l'équipe de recherche a introduit MagicNorm et Warmup Deep Credit Assignment.
MagicNorm est une stratégie de normalisation hybride qui exploite l'asymétrie entre les profondeurs des calculs avant et arrière dans le contexte d'une rétropropagation du gradient tronquée (Truncated BPTT). Elle utilise PreNorm à l'intérieur des modules et ajoute une normalisation supplémentaire à la sortie des modules, améliorant ainsi la stabilité de l'entraînement récursif profond.
Warmup Deep Credit Assignment ne rétropropage le gradient que sur les deux dernières étapes récursives en début d'entraînement, puis étend linéairement ce nombre jusqu'aux 5 dernières étapes. Ce mécanisme d'entraînement permet au modèle de converger de manière stable sur des chemins de crédit courts, avant d'introduire progressivement des dépendances plus longues.
Quels sont les résultats ?
Les résultats expérimentaux montrent que HRM-Text présente des avantages significatifs en termes d'efficacité architecturale, d'objectifs d'entraînement et de performance globale.
1. L'architecture récurrente est-elle plus efficace pour une puissance de calcul d'entraînement fixe ?
Les résultats montrent qu'à FLOPs équivalents, HRM 1B surpasse Transformer 1B, Transformer 3B, Looped Transformer 1B et RINS 1B sur la plupart des benchmarks ; la comparaison avec TRM indique également que l'entraînement de HRM est plus stable.
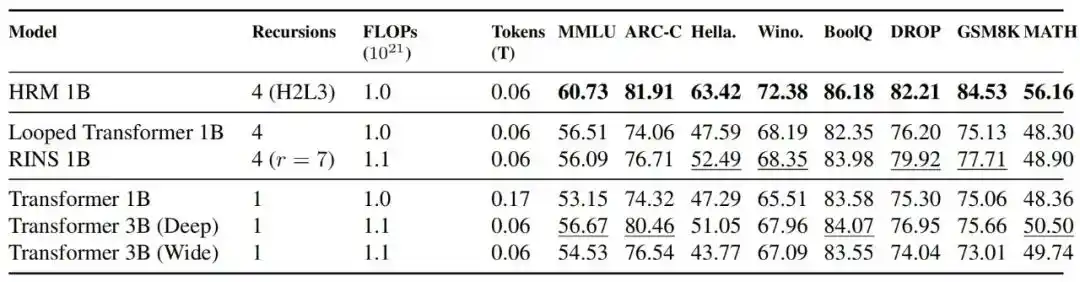
Figure | Comparaison des performances et de la stabilité avec les modèles Transformer. Le HRM maintient une dynamique d'entraînement stable à toutes les échelles, tandis que les modèles Transformer présentent une instabilité sévère à l'échelle du milliard de paramètres. De plus, à l'échelle 0,6B, le HRM n'a besoin que de 2 fois moins de calculs que les modèles Transformer pour obtenir des performances compétitives sur la plupart des benchmarks.
2. L'objectif de tâche et PrefixLM sont-ils bénéfiques ?
Une étude d'ablation montre qu'à FLOPs équivalents, pour un Transformer 1B, le score MMLU passe de 40,55 avec l'autorégressif standard, à 47,72 après l'introduction de l'objectif de tâche, puis à 53,15 après l'ajout de PrefixLM, et enfin à 60,73 après le passage à l'architecture HRM.
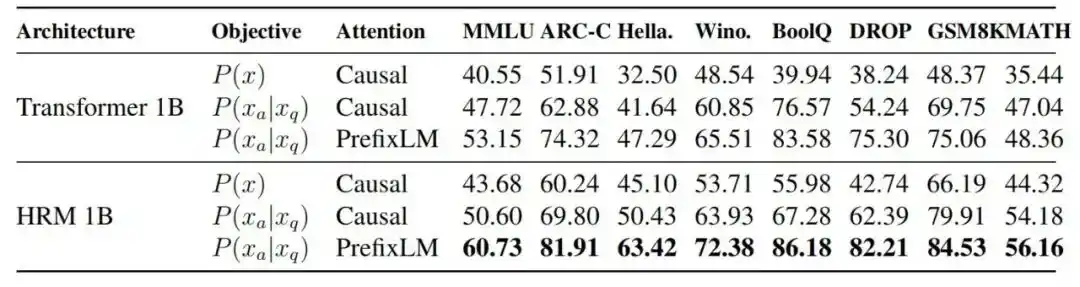
Figure | Comparaison des performances entre différentes architectures de modèle et objectifs d'entraînement.
3. Quelle est l'efficacité de HRM-Text par rapport aux modèles open contemporains ?
HRM-Text 1B obtient respectivement 60,7, 81,9, 82,2, 84,5 et 56,2 sur MMLU, ARC-C, DROP, GSM8K et MATH. Comparé aux modèles ouverts qui ont généralement des budgets d'entraînement bien plus importants, il atteint la plage de performance des modèles open source de 2B à 7B en utilisant seulement 40 milliards de tokens uniques et 1 milliard de paramètres ; l'entraînement nécessite jusqu'à 900 fois moins de tokens et jusqu'à 432 fois moins de puissance de calcul.
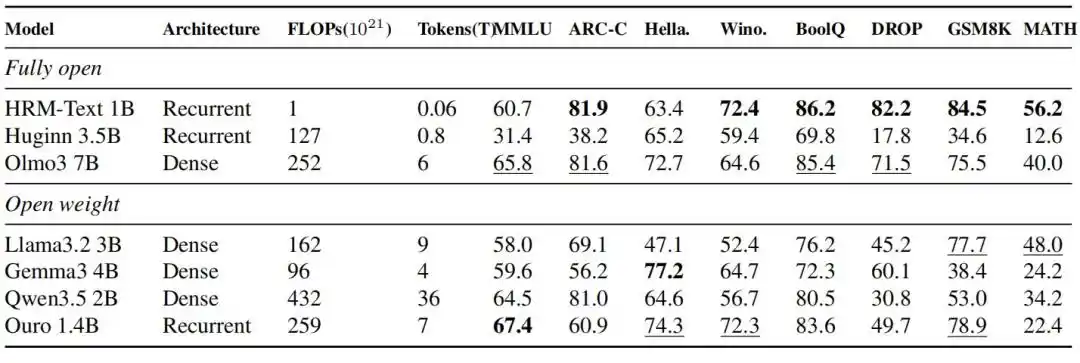
Figure | Résultats de l'évaluation de HRM-Text 1B comparé aux modèles entièrement open source et aux modèles à poids ouverts de la même période.
4. La structure récurrente confère-t-elle une plus grande profondeur effective ?
Les résultats montrent que les Transformer standard et Looped Transformer se stabilisent à des couches relativement peu profondes, tandis que le HRM maintient des changements de représentation plus marqués entre blocs, une similarité cosinus plus faible et une valeur KL du logit lens plus élevée à des couches plus profondes.
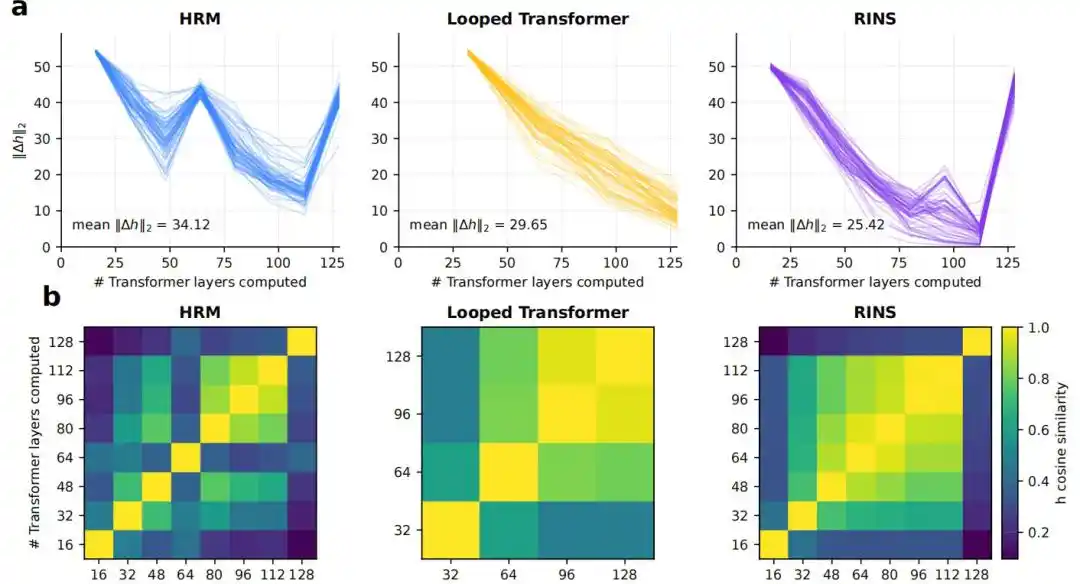
Figure | Analyse de la profondeur effective.
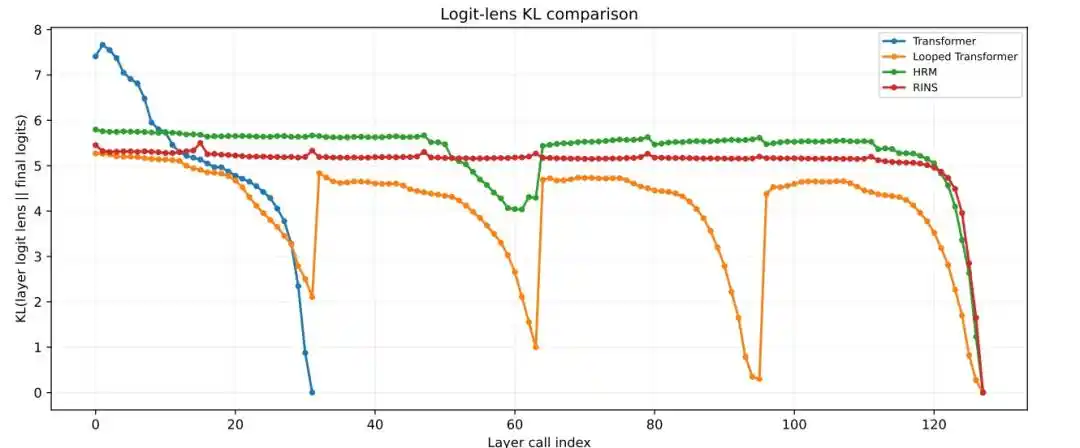
Figure | Analyse Logit Lens KL couche par couche.
Limites et perspectives futures
Bien que HRM-Text montre des performances solides sur les tâches nécessitant de la déduction, cette approche présente encore des limites et ouvre des pistes de recherche futures.
1. Vers un découplage entre « connaissance » et « raisonnement »
Actuellement, une couverture plus large des connaissances factuelles dépend encore davantage de la taille du modèle et de l'étendue des données. HRM-Text n'est entraîné que sur 40 milliards de tokens uniques, et les sources de connaissances explicites ne constituent qu'une partie du mélange de données formatées en tâches. À l'avenir, les chercheurs devront concevoir séparément un noyau de raisonnement compact et un stockage externe de faits, en confiant l'étendue des connaissances à des corpus soigneusement sélectionnés, des modules d'augmentation par recherche ou une mémoire apprenable.
2. Temps de calcul adaptatif
L'ordonnancement récursif de HRM-Text apporte une plus grande profondeur série effective, mais cela signifie aussi que le modèle doit exécuter un nombre fixe d'étapes récursives lors de l'inférence. Une piste d'exploration future prometteuse serait l'introduction d'un mécanisme de temps de calcul adaptatif, permettant aux exemples simples de terminer le calcul plus tôt et de réserver le budget récursif complet aux exemples difficiles, réduisant ainsi le coût de l'inférence.
3. La validation de la mise à l'échelle reste encore limitée
Les expériences de scaling actuelles ne couvrent que le groupe de contrôle Transformer de 3B de paramètres et le HRM-Text de 1B. L'équipe de recherche indique que des travaux ultérieurs devront encore vérifier si l'avantage d'efficacité similaire peut être maintenu à des échelles de modèles plus grandes.
4. PrefixLM et les infrastructures d'inférence
Actuellement, PrefixLM fait toujours face à certaines limitations d'implémentation technique pour un déploiement réel. Bien qu'il puisse fonctionner sur des infrastructures d'inférence standard comme vLLM, cela nécessite que l'infrastructure prenne en charge des masques d'attention personnalisés pendant la phase de pré-remplissage (prefill). Pour l'étendre aux scénarios de conversation multi-tours, il faudra en outre concevoir un mécanisme de cache KV qui garantisse à la fois la visibilité bidirectionnelle à l'intérieur des segments de l'utilisateur et le respect des contraintes causales lors de la génération côté assistant.
Pour plus de détails techniques, consultez l'article original.
Cet article provient du compte WeChat officiel « Academic Headlines » (ID : SciTouTiao), auteur : Xia Qiansi







