À l'époque du télégraphe où l'on payait au mot, l'encre et le papier valaient de l'argent. Les gens avaient l'habitude de condenser leurs milliers de mots à l'extrême, « Reviens vite » valait mieux qu'une longue lettre, « Tout va bien » était la plus lourde des recommandations.
Plus tard, le téléphone est entré dans les foyers, mais les appels longue distance étaient facturés à la seconde. Les appels longue distance des parents étaient toujours concis, une fois les affaires sérieuses terminées, on raccrochait vite, et dès que la conversation s'éternisait un peu, l'idée de l'argent dépensé coupait net les ébauches de bavardage.
Ensuite, l'ADSL est arrivé dans les foyers, Internet était facturé à l'heure, les gens fixaient le chronomètre à l'écran, les pages web s'ouvraient et se fermaient instantanément, on n'osait que télécharger les vidéos, le streaming était à l'époque un verbe de luxe. Au bout de chaque barre de progression de téléchargement se cachait le désir des gens de « se connecter au monde » et la crainte d'un « solde insuffisant ».
L'unité de facturation a changé encore et encore, l'instinct d'économiser est resté immuable.
Aujourd'hui, le Token est devenu la monnaie de l'ère de l'IA. Cependant, la plupart des gens n'ont pas encore appris à compter leurs sous à cette époque, car nous n'avons pas encore appris à calculer les gains et les pertes dans un algorithme invisible.
Quand ChatGPT est sorti en 2022, presque personne ne se souciait de savoir ce qu'était un Token. C'était l'ère du repas gratuit de l'IA, pour 20 dollars par mois, on pouvait discuter autant qu'on voulait.
Mais depuis que les Agents IA sont devenus populaires récemment, la dépense en Tokens est devenue une préoccupation pour tous ceux qui utilisent un Agent IA.
Contrairement à un simple dialogue de questions-réponses, derrière un flux de tâches se cachent des centaines voire des milliers d'appels API, la réflexion autonome de l'Agent a un coût, chaque auto-correction, chaque utilisation d'outil, correspond à une augmentation du chiffre sur la facture. Puis vous vous rendez compte que l'argent que vous avez rechargé soudainement ne suffit plus, et vous ne savez même pas ce que l'Agent a fait.
Dans la vie réelle, tout le monde sait comment économiser. Pour acheter des légumes au marché, nous savons enlever les feuilles pourries et terreuses avant de les peser ; pour prendre un taxi à l'aéroport, les vieux chauffeurs savent éviter le périphérique aux heures de pointe du matin.
La logique d'économie dans le monde numérique est en fait la même, sauf que l'unité de facturation est passée du « kilo » et du « kilomètre » au Token.
Dans le passé, économiser était dû à la pénurie ; à l'ère de l'IA, économiser est pour la précision.
Nous espérons qu'avec cet article, nous pourrons vous aider à梳理 (structurer) une méthodologie d'économie à l'ère de l'IA, pour que vous dépensiez chaque centime à bon escient.
Avant de peser, enlevez d'abord les feuilles pourries
À l'ère de l'IA, la valeur de l'information n'est plus déterminée par son étendue, mais par sa pureté.
La logique de facturation de l'IA est de la faire payer pour le nombre de mots qu'elle lit. Que vous lui donniez des idées pertinentes ou des bavardages formatés sans signification, du moment qu'elle lit, vous devez payer.
Par conséquent, la première façon de penser pour économiser des Tokens est de graver le « rapport signal/bruit » dans son subconscient.
Chaque mot, chaque image, chaque ligne de code que vous donnez à l'IA, vous devez le payer. Donc, avant de donner quoi que ce soit à l'IA, souvenez-vous de vous demander : combien de cela l'IA a-t-elle vraiment besoin ? Combien sont des feuilles pourries avec de la terre ?
Par exemple, les longues introductions comme « Bonjour, pourriez-vous m'aider... », les présentations de contexte répétitives, les commentaires de code non supprimés, sont toutes des feuilles pourries avec de la terre.
En plus de cela, le gaspillage le plus courant est de jeter directement un PDF ou une capture d'écran de page web à l'IA. Certes, vous vous facilitez la vie, mais la « facilité » à l'ère de l'IA signifie souvent « cher ».
Un PDF au format complet, en plus du contenu principal, contient des en-têtes, des pieds de page, des légendes de graphiques, des filigranes cachés, et une grande quantité de codes de formatage pour la mise en page. Ces choses n'aident en rien l'IA à comprendre votre question, mais elles sont toutes facturées.
La prochaine fois, souvenez-vous de convertir d'abord le PDF en texte Markdown propre avant de le donner à l'IA. Lorsque vous transformez un PDF de 10 Mo en un texte propre de 10 Ko, vous économisez non seulement 99% de l'argent, mais vous rendez aussi le cerveau de l'IA beaucoup plus rapide qu'avant.
Les images sont un autre gouffre financier.
Dans la logique des modèles visuels, l'IA ne se soucie pas de savoir si votre photo est belle ou non, elle se soucie seulement de la surface de pixels que vous occupez.
Prenons la logique de calcul officielle de Claude comme exemple : consommation de Tokens d'une image = pixels de largeur × pixels de hauteur ÷ 750.
Une image de 1000×1000 pixels, consomme environ 1334 Tokens, au prix de Claude Sonnet 4.6, cela équivaut à environ 0,004 dollar par image ;
Mais si on compresse la même image à 200×200 pixels, elle ne consomme que 54 Tokens, le coût descend à 0,00016 dollar, une différence de 25 fois.
Beaucoup de gens jettent directement des photos haute définition prises avec leur téléphone, des captures d'écran 4K à l'IA, sans savoir que les Tokens consommés par ces images pourraient suffire à faire lire à l'IA la majeure partie d'un roman court. Si la tâche est simplement de reconnaître le texte dans l'image ou de faire un simple jugement visuel, comme faire identifier à l'IA le montant sur une facture, lire le texte dans une notice, ou juger s'il y a un feu tricolore dans l'image, alors une résolution 4K est un pur gaspillage, compressez l'image à la résolution minimale utilisable.
Mais la raison la plus facile de gaspiller des Tokens en entrée n'est en fait pas le format de fichier, mais une manière de parler inefficace.
Beaucoup de gens traitent l'IA comme un voisin réel, ont l'habitude de communiquer avec des bavardages sociaux, lancent d'abord un « Aide-moi à écrire une page web », attendent que l'IA recrache un semi-produit, puis ajoutent des détails, et négocient反复 (à plusieurs reprises). Ce dialogue en mode « goutte à goutte » oblige l'IA à générer du contenu反复 (à plusieurs reprises), chaque round de modification ajoute à la consommation de Tokens.
Les ingénieurs de Tencent Cloud ont découvert dans la pratique que pour le même besoin, un dialogue en plusieurs tours en mode « goutte à goutte » finit par consommer souvent 3 à 5 fois plus de Tokens qu'une explication claire en une fois.
La véritable façon d'économiser, c'est d'abandonner cette试探 sociale (tentative sociale) inefficace, et de dire clairement en une fois les exigences, les conditions limites, les exemples de référence. Évitez de vous fatiguer à expliquer « ce qu'il ne faut pas faire », car les phrases négatives consomment souvent plus de coût de compréhension que les phrases affirmatives ; dites-lui directement « comment faire », et donnez un exemple correct clair.
En même temps, si vous savez où est la cible, dites-le directement à l'IA, ne laissez pas l'IA jouer les détectives.
Lorsque vous ordonnez à l'IA « Trouve le code lié à l'utilisateur », elle doit effectuer en arrière-plan un balayage, une analyse et des suppositions à grande échelle ; alors que lorsque vous lui dites directement « Va voir le fichier src/services/user.ts », la consommation de Tokens est très différente. Dans le monde numérique, l'égalité d'information est la plus grande économie.
Ne payez pas pour la « politesse » de l'IA
La facturation des grands modèles a une règle non écrite que beaucoup de gens ne réalisent pas : les Tokens de sortie sont généralement 3 à 5 fois plus chers que les Tokens d'entrée.
Autrement dit, les paroles de l'IA sont beaucoup plus chères que les vôtres. Prenons le prix de Claude Sonnet 4.6 comme exemple, l'entrée coûte seulement 3 dollars par million de Tokens, tandis que la sortie monte brusquement à 15 dollars, une différence de prix de 5 fois.
Ces formules de politesse d'introduction comme « Bon, j'ai parfaitement compris votre demande, je commence maintenant à vous répondre...... », ces formules de politesse de conclusion comme « J'espère que le contenu ci-dessus vous a été utile », dans la communication avec un humain, ce sont des formules de politesse sociale, mais sur la facture de l'API, ces bavardages sans valeur informationnelle supplémentaire, vous devez aussi les payer de votre poche.
Le moyen le plus efficace de résoudre le gaspillage en sortie est de fixer des règles à l'IA. Utilisez des instructions système pour lui dire clairement : pas de formules de politesse, pas d'explications, pas de reformulation de la demande, donnez directement la réponse.
Ces règles n'ont besoin d'être définies qu'une fois, et elles prennent effet à chaque conversation, c'est un véritable moyen de gestion financière « investir une fois, bénéficier pour toujours ». Mais en établissant des règles, beaucoup de gens tombent dans un autre piège : empiler des instructions avec un langage naturel冗长 (long et verbeux).
Les données实测 (mesurées en pratique) des ingénieurs montrent que l'efficacité des instructions ne réside pas dans le nombre de mots, mais dans la densité. En compressant un message d'instruction système de 500 mots à 180 mots, en supprimant les formules de politesse sans signification, en fusionnant les instructions répétitives, et en reconstruisant les paragraphes en une liste条目化 (sous forme de listes à puces) concise, la qualité de sortie de l'IA fluctue à peine, mais la consommation de Tokens par appel peut chuter de 64%.
Un moyen de contrôle plus actif est de limiter la longueur de sortie. Beaucoup de gens ne fixent jamais de limite de sortie, laissant l'IA libre de发挥 (s'exprimer), cette放任 (permissivité) du droit d'expression conduit souvent à un失控 (dérapage) extrême des coûts. Vous n'avez peut-être besoin que d'une courte phrase qui va à l'essentiel, mais l'IA, pour montrer une certaine « sincérité intellectuelle », génère sans demander une petite rédaction de 800 mots pour vous.
Si vous recherchez des données pures, vous devez forcer l'IA à renvoyer un format structuré, plutôt qu'une description冗长 (longue et verbeuse) en langage naturel. Pour une quantité d'information équivalente, la consommation de Tokens du format JSON est bien inférieure à celle d'un paragraphe en prose. C'est parce que les données structurées éliminent tous les mots de liaison redondants, les mots de modalité et les modifications explicatives, ne conservant que le noyau logique à haute concentration. À l'ère de l'IA, vous devez清醒地意识到 (être clairement conscient) que ce qui mérite que vous payiez, c'est la valeur du résultat, et non l'auto-explication sans signification de l'IA.
En plus de cela, la « réflexion excessive » de l'IA ronge aussi follement le solde de votre compte.
Certains modèles avancés ont un mode « réflexion étendue », qui effectue une推理 (inférence) interne massive avant de répondre. Ce processus de推理 (raisonnement) est aussi facturé, et au prix de sortie, très cher.
Ce mode est essentiellement conçu pour les « tâches complexes nécessitant un support logique profond ». Mais la plupart des gens choisissent aussi ce mode pour des questions simples. Pour les tâches ne nécessitant pas de推理 profonde (raisonnement profond), dire clairement à l'IA « pas besoin d'expliquer la思路 (démarche), donnez directement la réponse », ou désactiver manuellement la réflexion étendue, peut aussi vous faire économiser pas mal d'argent.
Ne laissez pas l'IA faire les comptes anciens
Les grands modèles n'ont pas de vraie mémoire, ils ne font que疯狂地翻旧账 (repasser frénétiquement les vieux comptes).
C'est un mécanisme底层 (de base) que beaucoup de gens ne connaissent pas. Chaque fois que vous envoyez un nouveau message dans une fenêtre de dialogue, l'IA ne commence pas à comprendre à partir de cette phrase, mais relit tout le contenu dont vous avez parlé auparavant, y compris chaque tour de dialogue, chaque segment de code, chaque document cité, puis seulement elle vous répond.
Dans la facture des Tokens, cette « révision pour savoir du nouveau » n'est absolument pas gratuite. Au fur et à mesure que les tours de dialogue s'accumulent, même si vous ne demandez qu'un simple mot, le coût pour l'IA de relire tout le vieux compte en arrière-plan augmente de façon exponentielle. Ce mécanisme détermine que plus l'historique de la conversation est lourd, plus chaque question que vous posez est chère.
Quelqu'un a suivi 496 conversations réelles contenant plus de 20 messages, et a découvert que le 1er message lisait en moyenne 14 000 Tokens, chaque coût d'environ 3,6 cents ; au 50ème message, il lisait en moyenne 79 000 Tokens, chaque coût d'environ 4,5 cents, 80% plus cher. Et le contexte devient de plus en plus long, au 50ème message, le contexte que l'IA doit retraiter est déjà 5,6 fois celui du 1er message.
Pour résoudre ce problème, l'habitude la plus simple est : une tâche, une boîte de dialogue.
Quand un sujet est terminé, ouvrez果断ement (résolument) une nouvelle conversation, ne traitez pas l'IA comme une fenêtre de chat qui ne s'éteint jamais. Cette habitude semble simple, mais beaucoup de gens n'y arrivent tout simplement pas, pensant toujours « et si j'avais encore besoin du contenu précédent ? ». En fait, la grande majorité du temps, ces « et si » que vous craignez n'apparaissent pas, et pour cet « et si », vous avez déjà payé plusieurs fois plus pour chaque nouveau message.
Lorsque la conversation doit vraiment se poursuivre, mais que le contexte est déjà long, nous pouvons utiliser la fonction de compression de certains outils. Claude Code a une commande /compact, qui peut condenser un long historique de conversation en un bref résumé, vous aidant à faire un断舍离 (désencombrement) cybernétique.
Il y a aussi une logique d'économie appelée Prompt Caching (mise en cache des invites). Si vous utilisez反复 (à plusieurs reprises) la même invite système, ou si chaque conversation doit citer le même document de référence, l'IA mettra ce contenu en cache, et la prochaine fois qu'elle sera appelée, elle ne facturera qu'un faible frais de lecture du cache, au lieu de facturer le prix plein à chaque fois.
La tarification officielle d'Anthropic montre que le prix des Tokens en cas de succès du cache est 1/10 du prix normal. Le Prompt Caching d'OpenAI peut également réduire le coût d'entrée d'environ 50%. Un article publié en janvier 2026 sur arXiv, qui a testé de longues tâches sur plusieurs plateformes d'IA, a découvert que la mise en cache des invites pouvait réduire le coût de l'API de 45% à 80%.
Autrement dit, pour le même contenu, la première fois que vous le donnez à l'IA, vous payez le prix plein, ensuite chaque appel ne coûte que 1/10. Pour les utilisateurs qui doivent utiliser quotidiennement les mêmes documents normatifs ou invites système, cette fonctionnalité peut économiser beaucoup de Tokens.
Mais le Prompt Caching a une condition préalable, le contenu et l'ordre de votre invite système et des documents de référence doivent être cohérents, et doivent être placés au tout début de la conversation. Dès que le contenu est modifié, le cache devient invalide, et vous êtes facturé au prix plein. Donc, si vous avez un ensemble de normes de travail fixes, fixez-les, ne les modifiez pas随意 (arbitrairement).
La dernière technique de gestion du contexte est le chargement à la demande. Beaucoup de gens aiment fourrer toutes les normes, documents, notes importantes dans l'invite système d'un coup, pour la même raison « au cas où ».
Mais le prix à payer est que, alors que vous ne faites qu'une tâche très simple, vous êtes obligé de charger des milliers de mots de règles, gaspillant inutilement une pile de Tokens. La documentation officielle de Claude Code recommande de garder CLAUDE.md à moins de 200 lignes, de diviser les règles spécialisées de不同场景 (différents scénarios) en fichiers de compétences indépendants, et de ne charger les règles du scénario que lorsque vous en avez besoin. Garder le contexte absolument pur, c'est le plus grand respect pour la puissance de calcul.
N'utilisez pas une Porsche pour faire les courses
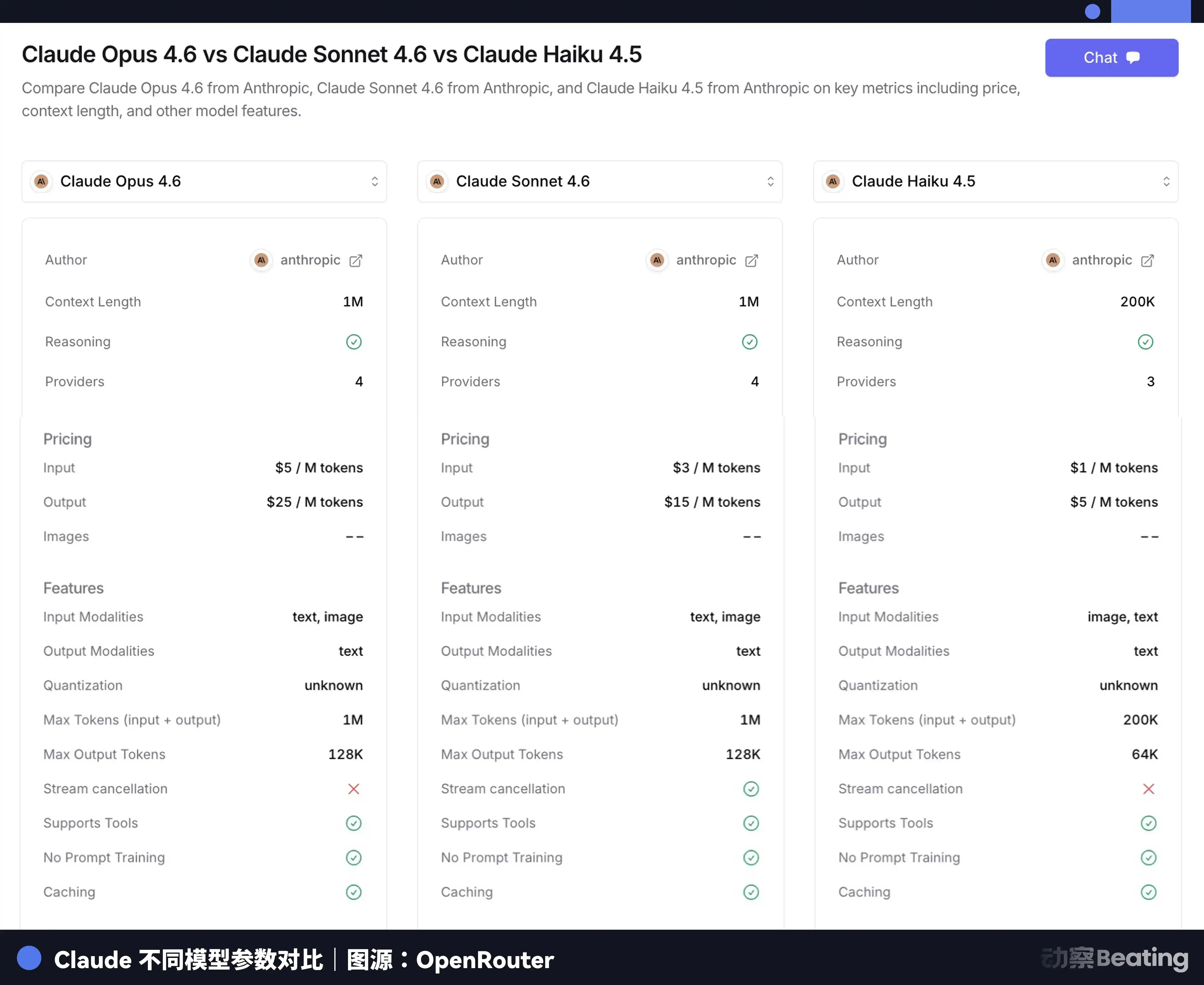
Différents modèles d'IA ont des écarts de prix énormes.
Claude Opus 4.6 coûte 5 dollars par million de Tokens en entrée, 25 dollars en sortie, Claude Haiku 3.5 seulement 0,8 dollar en entrée, 4 dollars en sortie, une différence de près de 6 fois. Faire faire les tâches杂活 (subalternes) de collecte d'informations, de mise en forme au modèle le plus haut de gamme, est non seulement lent, mais aussi très cher.
L'utilisation intelligente consiste à apporter la pensée de « division du travail de classe » courante dans notre société humaine à la société de l'IA, confier des tâches de difficulté différente à des modèles de prix différents.
Comme pour embaucher des gens dans le monde réel, vous n'iriez pas embaucher un expert avec un salaire annuel de un million pour porter des briques sur un chantier. C'est la même chose pour l'IA. La documentation officielle de Claude Code recommande également clairement : Sonnet pour la plupart des tâches de programmation, Opus pour les décisions architecturales complexes et le raisonnement à plusieurs étapes, les sous-tâches simples指定 (assignées) à Haiku.
Un plan opérationnel plus concret est de construire un « flux de travail en deux étapes ». Dans la première phase, utilisez des modèles de base gratuits ou bon marché pour faire le sale boulot前期 (préliminaire), comme la collecte de données, le nettoyage du format, la génération de brouillon, la classification simple et la归纳 (synthèse). Entrez dans la deuxième phase, puis donnez l'essence de haute pureté raffinée au modèle de haut de gamme, pour la prise de décision核心 (centrale) et la修整 (reprise) profonde.
Par exemple, si vous devez analyser un rapport sectoriel de 100 pages, vous pouvez d'abord utiliser Gemini Flash pour extraire les données et conclusions clés du rapport, les organiser en un résumé de 10 pages, puis donner ce résumé à Claude Opus pour une analyse et un jugement approfondis. Ce flux de travail en deux étapes peut, tout en garantissant la qualité, compresser considérablement les coûts.
Plus avancé que le simple traitement par segments, est la division du travail en profondeur basée sur la déconstruction des tâches. Une tâche d'ingénierie complexe peut être complètement décomposée en plusieurs sous-tâches indépendantes, et correspondre au modèle le plus approprié.
Par exemple, pour une tâche nécessitant d'écrire du code, on peut faire écrire le框架 (cadre) et le code样板 (modèle) par un modèle bon marché, puis ne donner que la partie logique核心 (centrale) au modèle coûteux pour la mise en œuvre. Chaque sous-tâche a un contexte propre et专注 (concentré), le résultat est plus précis, et le coût est plus bas.
Vous n'aviez pas besoin de dépenser des Tokens à l'origine
Toutes les discussions précédentes résolvent essentiellement le problème战术 (tactique) de « comment économiser de l'argent », mais une question logique plus fondamentale est négligée par beaucoup de gens : cette action, a-t-elle vraiment besoin de coûter des Tokens ?
L'économie la plus ultime n'est pas l'optimisation algorithmique, mais le断舍离 (désencombrement) décisionnel. Nous nous sommes habitués à demander des réponses universelles à l'IA, mais nous avons oublié que dans de nombreux scénarios, appeler un grand modèle coûteux revient à utiliser un canon pour tuer une mouche.
Par exemple, si vous laissez l'IA traiter automatiquement les e-mails, elle traitera chaque e-mail comme une tâche indépendante à comprendre, classer, répondre, la consommation de Tokens est énorme. Mais si vous prenez d'abord 30 secondes pour parcourir la boîte de réception, filtrer manuellement les e-mails qui n'ont manifestement pas besoin d'être traités par l'IA, puis donnez le reste à l'IA, le coût descend immédiatement à une petite fraction de l'original. Le jugement humain n'est pas un obstacle ici, c'est le meilleur filtre.
Les gens de l'époque du télégraphe savaient combien coûtait每个多发一个字) (chaque mot supplémentaire), donc ils pesaient leurs mots, c'était une perception intuitive des ressources. C'est la même chose à l'ère de l'IA, quand vous savez vraiment combien coûte每让 AI 多说一句话) (chaque phrase supplémentaire de l'IA), vous pèserez naturellement si cela vaut la peine de le faire faire par l'IA, si cette tâche nécessite un modèle de haut de gamme ou un modèle bon marché, si ce contexte est encore utile.
Cette掂量 (pesée) est la capacité la plus économique. À une époque où la puissance de calcul devient de plus en plus chère, l'utilisation la plus intelligente n'est pas de让 AI 替代人) (laisser l'IA remplacer l'homme), mais de让 AI 和人去干各自擅长的事) (laisser l'IA et l'homme faire ce qu'ils savent faire de mieux). Quand cette sensibilité aux Tokens est internalisée comme un réflexe conditionné, vous redevenez enfin le maître de la puissance de calcul, et non son附属 (subordonné).






