Auteur : Omnitools
Les stations relais IA sont en train de passer d'outils de niche à une porte d'entrée plus large vers les modèles. Pour de nombreux utilisateurs, leur attrait est direct : prix plus bas, plus de modèles, interface unifiée, et possibilité de se connecter à des outils de développement comme Claude Code, Codex, Cursor, etc.
Mais le problème des stations relais se situe précisément ici. Les utilisateurs pensent simplement changer d'adresse API pour une moins chère, mais en réalité, ils peuvent livrer leurs prompts, leur code, leurs documents professionnels, les données clients, les journaux d'appels, voire tout le contexte de développement d'un projet.
Omnitools estime que la discussion sur les stations relais IA ne devrait pas se limiter à « peut-on les utiliser » ou « quelle est la moins chère ». La question la plus importante est : d'où vient le besoin derrière les stations relais ? Les utilisateurs en ont-ils vraiment besoin ? Et s'ils doivent les utiliser, comment contrôler les risques ?
I. La demande du marché derrière les stations relais
Une conclusion évidente est que les stations relais sont populaires parce qu'il existe une réelle demande.
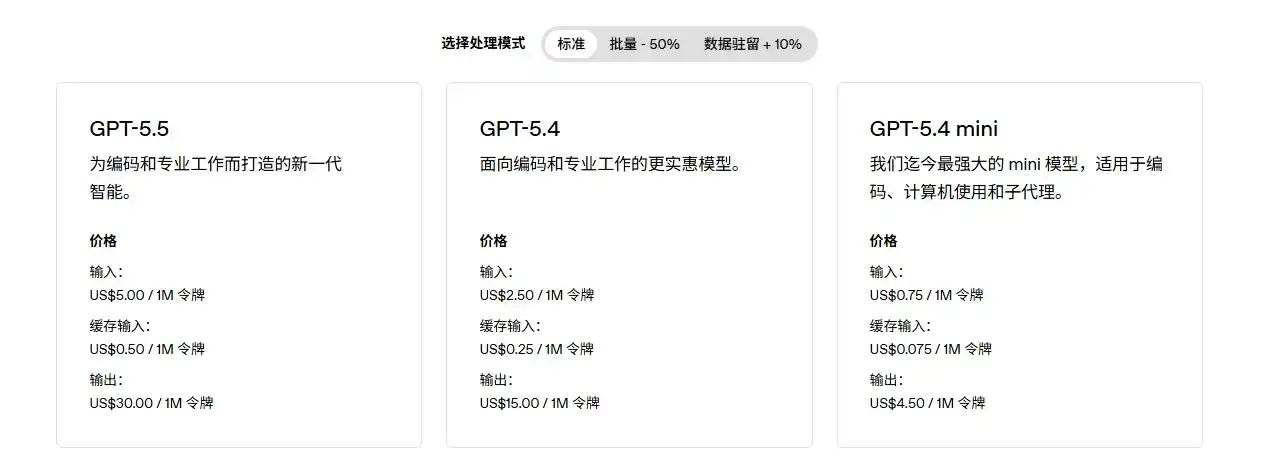
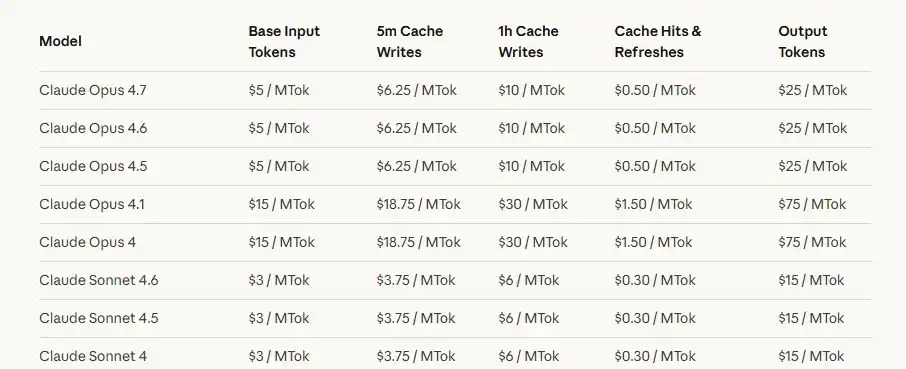
Premièrement, l'avantage prix. Les API officielles des grands modèles leaders à l'étranger ne sont pas bon marché. La page tarifaire d'OpenAI indique que l'entrée pour GPT-5.5 coûte 5 $ par million de tokens, la sortie 30 $ par million ; celle d'Anthropic montre que l'entrée pour Claude Sonnet 4.7 coûte 5 $ par million de tokens, la sortie 25 $. Pour un chat ordinaire, ces coûts ne sont pas visibles, mais pour le traitement de texte long, la génération de code, les tâches d'agent multi-tours et les flux de travail automatisés, les coûts d'appel deviennent rapidement perceptibles.
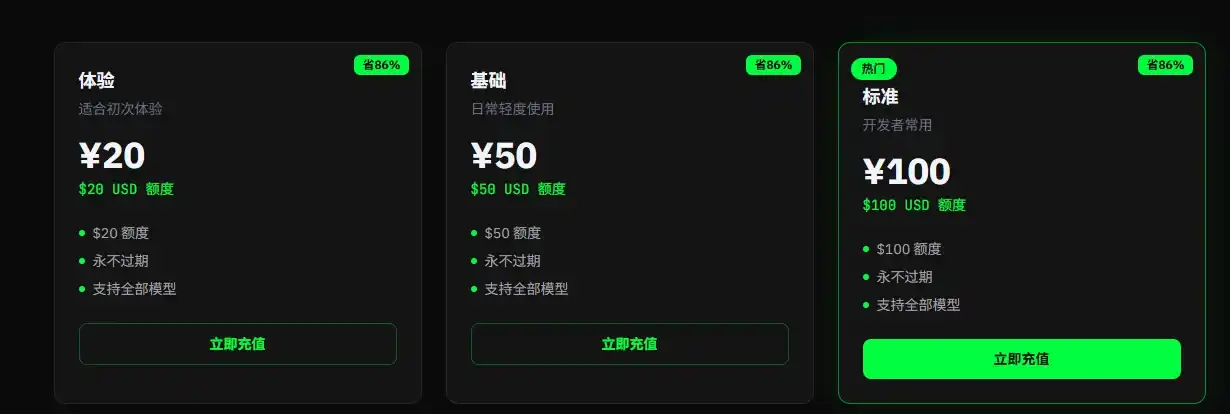
Or, l'argument principal des stations relais est un prix bien inférieur à l'officiel pour accéder à l'API, par exemple 1 yuan chinois pour acheter 1 $ de tokens, soit un prix réduit d'environ 15 % par rapport au tarif officiel. Pour les utilisateurs ayant des besoins importants, c'est une économie réelle.
Deuxièmement, la barrière d'accès. Alors que les restrictions d'accès des modèles américains envers les utilisateurs de Chine continentale se durcissent, même en ignorant l'avantage prix, utiliser l'API ou les forfaits officiels au prix fort représente un seuil de vérification très élevé pour de nombreux utilisateurs. De plus, dans les scénarios d'utilisation, si un utilisateur veut utiliser simultanément Claude, GPT, Gemini ainsi que des modèles chinois, il doit basculer entre plusieurs plateformes. Les stations relais compressent cette complexité en un seul point d'entrée, comme une « prise multiple » dans le monde des modèles IA, où l'utilisateur ne se soucie plus de savoir quelle ligne est connectée derrière, mais seulement si l'électricité arrive de manière stable.
Troisièmement, la poussée des outils de développement. Autrefois, les modèles étaient surtout utilisés pour le Q&R et l'écriture ; aujourd'hui, des outils comme Claude Code, Codex, Cursor intègrent les modèles dans les flux de développement locaux. L'appel au modèle n'est plus une simple conversation, mais peut être une revue de code, une restructuration de projet, une correction automatique. De plus, avec l'essor de la tendance « élever des homards », cette demande de tokens augmente aussi. Plus la demande est importante, plus les utilisateurs cherchent facilement des moyens d'accès moins chers, avec des quotas plus élevés et plus unifiés.
Ainsi, le succès commercial des stations relais est alimenté par une réelle demande, ce n'est pas un simple effet de mode.
II. Avez-vous vraiment besoin d'une station relais ?
Cependant, tout le monde n'a pas besoin d'une station relais.
Si vous ne posez que des questions occasionnelles, traduisez du texte, résumez des documents publics, écrivez un texte ordinaire, souvent une station relais n'est pas nécessaire. ChatGPT, Gemini, Antigravity et d'autres modèles et outils offrent des quotas gratuits. Si la vérification et la création de compte posent problème, de nombreux agrégateurs de grands modèles existent, certains offrant également des quotas gratuits pour un usage quotidien.
Pour l'utilisateur occasionnel, plutôt que de donner ses données à une station relais inconnue pour « économiser », il vaut mieux d'abord épuiser les quotas gratuits des outils officiels et réguliers. Les quotas gratuits peuvent changer, les limites spécifiques doivent être vérifiées sur les pages officielles, mais le principe reste : une demande à faible fréquence ne nécessite pas de se précipiter vers une station relais.
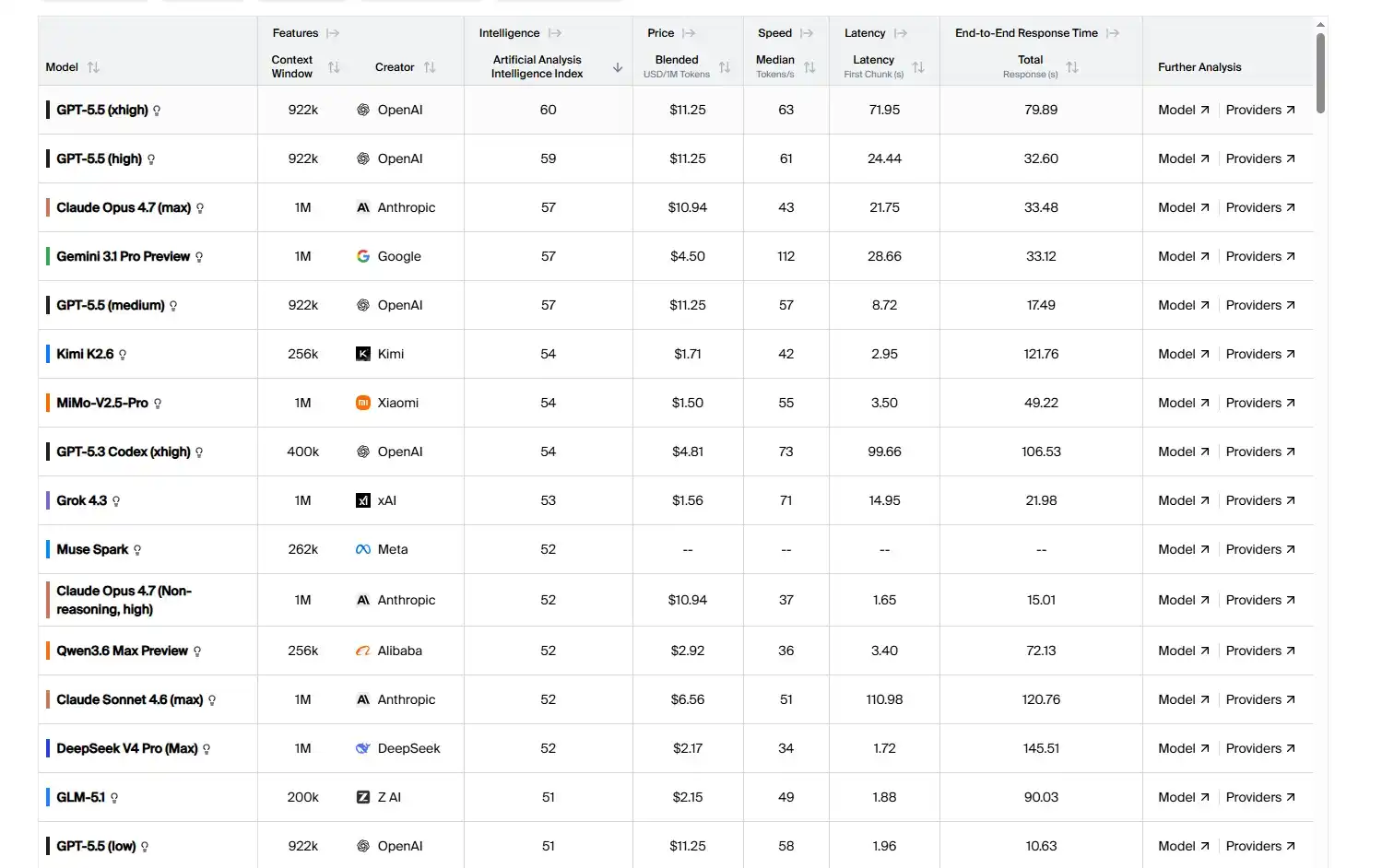
Si vous êtes un utilisateur intensif de programmation, vous n'avez pas nécessairement besoin de confier toutes les tâches à des modèles onéreux ou à une station relais. Une approche plus sûre est d'utiliser les modèles par couches : utiliser les grands modèles les plus puissants pour la décomposition des besoins, les choix techniques, la conception d'architecture et la revue de code ; puis utiliser des modèles chinois moins chers pour le développement fonctionnel plus concret, l'exécution quotidienne, etc. Et avec les progrès constants des modèles chinois, pour gérer le développement quotidien, les capacités de nombreux modèles chinois sont déjà proches des modèles américains de pointe, et le prix peut être bien inférieur à celui de nombreuses stations relais. Prenons l'exemple de Kimi K2.6, le prix de sortie est de 4 $ par million de tokens, soit seulement 13 % de celui de ChatGPT 5.5, un prix inférieur à celui de nombreuses stations relais.
Bien sûr, cette approche n'est pas parfaite, mais elle correspond mieux à la structure des coûts. Pour les tâches complexes, le plus important est le jugement directionnel et la capacité de cadrage ; la mise en œuvre concrète peut être divisée en plusieurs petites tâches à faible risque et à faible coût. Pour les développeurs individuels et les petites équipes, décomposer d'abord la tâche, puis décider quels maillons nécessitent des modèles haut de gamme, est généralement plus rationnel que d'acheter directement un gros quota sur une station relais.
Ce n'est que lorsque l'utilisateur a un besoin d'appel continu, fréquent et multi-modèles, par exemple une utilisation à long terme d'outils de programmation IA, le traitement d'une grande quantité de documents publics, la comparaison de modèles, la mise en place de flux d'automatisation internes, et que les quotas officiels sont clairement insuffisants, qu'une station relais peut devenir une option. Même dans ce cas, elle devrait être un « outil après sélection », et non l'entrée par défaut.
III. Comment choisir et utiliser une station relais ?
Si après évaluation vous confirmez avoir besoin d'une station relais, la question suivante n'est plus « faut-il l'utiliser », mais « comment l'utiliser sans encombre ». Voici un processus opérationnel complet, de l'évaluation à l'usage quotidien.
Étape 1 : Vérifier avant de recharger
Après avoir obtenu une adresse de station relais, ne vous précipitez pas pour recharger. Faites d'abord trois choses :
Vérifier l'authenticité du modèle. Utilisez le même prompt pour appeler la station relais et l'API officielle, comparez la qualité de la sortie, le format de la réponse, l'utilisation des tokens. Certaines stations relais peuvent utiliser un modèle de version inférieure en se faisant passer pour une version supérieure, ou injecter des prompts système supplémentaires dans la sortie. Un test simple est de demander au modèle de s'auto-décrire (version), puis de croiser avec le comportement officiel. Cela ne garantit pas une parfaite authenticité, mais permet d'éliminer les plateformes manifestement douteuses.
Tester la latence et la stabilité. Effectuez 20 à 50 appels consécutifs, observez s'il y a des timeouts fréquents, des erreurs aléatoires ou des fluctuations de qualité de réponse. La chaîne d'une station relais a une couche supplémentaire par rapport à une connexion directe. Si la stabilité de base n'est pas satisfaisante, les problèmes en cours d'utilisation ne feront qu'augmenter.
Vérifier la qualité de la documentation. Une station relais sérieuse fournira généralement une documentation API complète, des instructions de connexion compatibles avec le format OpenAI, une liste claire des modèles et un tableau des prix. Si une plateforme a une documentation bâclée, ou une liste de modèles vague, il faut être plus vigilant.
Étape 2 : Isoler la configuration, ne pas mélanger
Après avoir confirmé que la plateforme est utilisable, vient l'isolation technique. Beaucoup d'utilisateurs sautent cette étape, mais elle détermine l'étendue des pertes en cas de problème.
Utiliser une clé API indépendante. Ne mettez pas la clé que vous avez demandée sur la plateforme officielle directement dans la station relais, et n'utilisez pas la même clé sur plusieurs stations relais. Générez une clé indépendante pour chaque station relais. Si une plateforme pose problème, vous pouvez immédiatement l'invalider sans affecter les autres services.
Gérer les clés via des variables d'environnement. Dans votre environnement de développement local, stockez la clé API dans un fichier .env ou dans les variables d'environnement du système, ne l'encodez pas en dur dans le code. Pour Cursor par exemple, lorsque vous remplissez l'URL de base de l'API et la clé dans les paramètres, assurez-vous que ces configurations ne seront pas soumises au dépôt Git. Si vous utilisez des outils en ligne de commande comme Claude Code ou Codex, vérifiez vos fichiers de configuration shell pour vous assurer que la clé n'apparaît pas dans l'historique du contrôle de version.
Définir une limite d'utilisation. La plupart des stations relais sérieuses permettent de fixer une limite mensuelle de tokens ou de dépense. Après recharge, la première chose à faire est de définir cette limite. Ce n'est pas seulement un contrôle des coûts, c'est aussi une sécurité de dernier recours. Si votre clé est accidentellement exposée, la limite d'utilisation limitera les dégâts.
Étape 3 : Établir une habitude de classification des données
Une fois la configuration technique terminée, l'élément clé de l'utilisation quotidienne est d'effectuer un jugement rapide de classification des données pour chaque appel. Pas besoin d'écrire un rapport de sécurité à chaque fois, mais il faut développer un réflexe conditionné de vérification.
Avant d'envoyer, posez-vous cette question : si ce contenu apparaissait demain sur un forum public, pourrais-je l'accepter ?
Si la réponse est « oui », par exemple un résumé de documents publics, une traduction générale, une discussion technique sur un projet open source, l'analyse d'une documentation publique, alors vous pouvez utiliser directement la station relais.
Si la réponse est « pas vraiment, mais les pertes sont contrôlables », par exemple des comptes-rendus de réunion interne, des brouillons de documents commerciaux, des modèles de communication client, des extraits de code, alors effectuez un anonymisation avant envoi. Concrètement : remplacer les noms par des rôles (« Client A », « Collègue B »), remplacer les montants précis par des proportions ou des plages, remplacer les identifiants internes par des espaces réservés, supprimer les adresses de connexion à la base de données, les endpoints API internes et les descriptions de logique métier non publiques. Ce processus ne prend pas longtemps, généralement une ou deux minutes, mais il réduit le risque de « possible problème » à « essentiellement gérable ».
Si la réponse est « absolument pas », par exemple des clés privées, des phrases de récupération (seed phrases), des clés d'environnement de production, des mots de passe de base de données, des données financières non publiées, des informations privées de clients, des dépôts de code privés complets, alors ne les confiez à aucune station relais, peu importe ce qu'elle prétend en matière de sécurité.
Étape 4 : Traiter séparément les outils de programmation IA
Ce point mérite d'être souligné séparément, car la surface d'exposition des données des outils de programmation IA est bien plus grande que celle d'une conversation ordinaire.
Lorsque vous connectez une station relais dans des outils comme Cursor, Claude Code, Cline, le modèle obtient non seulement le prompt que vous avez saisi activement, mais peut aussi inclure : le contenu des fichiers ouverts, la structure du répertoire du projet, l'historique de la sortie terminal, les fichiers de configuration de dépendances (comme package.json, requirements.txt), l'historique des commits Git, ainsi que les chemins de fichiers et noms de variables d'environnement dans les messages d'erreur.
Cela signifie que pour une demande apparemment ordinaire comme « aide-moi à corriger ce bug », la quantité de données réellement envoyée à la station relais peut dépasser largement vos attentes.
Recommandation opérationnelle : Lorsque vous utilisez une station relais dans des outils de programmation IA, privilégiez le traitement de tâches de code indépendantes, sans lien avec le cœur de votre activité. Si vous devez traiter du code concernant un dépôt privé ou un environnement de production, deux pratiques relativement sûres existent : premièrement, ne coller que des extraits de code anonymisés, plutôt que de laisser l'outil lire l'intégralité du projet ; deuxièmement, repasser sur l'API officielle ou un modèle local pour le développement des projets sensibles, et utiliser la station relais uniquement pour les projets non sensibles. Aucune des deux méthodes n'est parfaite, mais c'est bien mieux que de confier sans distinction tout le contexte de développement à un proxy tiers.
Étape 5 : Surveiller en continu, se préparer à quitter
Utiliser une station relais n'est pas une décision ponctuelle, mais un processus d'évaluation continue.
Vérifier régulièrement les historiques de débit. Confirmer que la consommation de tokens correspond à votre utilisation réelle. Si l'utilisation n'augmente pas significativement sur une période, mais que les débits s'accélèrent, la plateforme a peut-être ajusté ses règles de facturation, ou votre clé fait l'objet d'appels anormaux.
Suivre les annonces de la plateforme et les retours de la communauté. L'état opérationnel d'une station relais peut changer à tout moment : ajustement des canaux amont, changement de politique de quotas, arrêt soudain du service, tout est possible. Si vous dépendez d'une station relais comme point d'accès principal, ayez au moins une solution de repli. Il est conseillé de s'inscrire simultanément sur 2-3 plateformes, de maintenir un minimum de recharge sur chacune, et d'éviter de concentrer tous vos appels sur un seul canal.
S'assurer de pouvoir migrer. Lors de la configuration de la station relais, utilisez l'interface standard compatible avec le format OpenAI. Ainsi, lors du changement de plateforme, vous n'aurez généralement qu'à modifier l'URL de base et la clé API, sans toucher à la logique du code. Si votre projet est fortement lié à des interfaces privées ou des fonctionnalités spécifiques d'une station relais, le coût de migration augmentera considérablement, ce qui est aussi un risque à anticiper.
Au final, une station relais est un outil, pas une croyance. Sa valeur réside dans la résolution de besoins réels d'accès à un coût contrôlé, mais ce « contrôlé », c'est à vous de le définir et de le maintenir, en vérifiant, isolant, classifiant, traitant spécifiquement et surveillant en continu, pour garder l'initiative entre vos mains.







