Năm 2026, sự phát triển AI toàn cầu chào đón một bước ngoặt mang tính biểu tượng – lần đầu tiên trong lịch sử, chi phí vốn đầu tư cho suy luận của các nhà cung cấp đám mây siêu quy mô vượt qua chi phí vốn đầu tư cho huấn luyện. Trọng tâm của ngành công nghiệp chuyển từ "luyện mô hình lớn" sang "sử dụng mô hình lớn", cấu trúc nhu cầu tính toán đã thay đổi một cách căn bản.
Trong thời kỳ huấn luyện, mâu thuẫn cốt lõi của tính toán là "độ chính xác kép dấu phẩy động và quy mô cụm"; còn khi bước vào thời kỳ suy luận, mâu thuẫn cốt lõi trở thành "băng thông bộ nhớ và độ trễ truyền thông".
Điểm nghẽn suy luận của mô hình lớn không còn chỉ là tính toán, mà là việc di chuyển dữ liệu – trọng số mô hình, giá trị kích hoạt trung gian và KV Cache cần tương tác thường xuyên giữa DRAM ngoài chip (như HBM) và GPU, mô hình càng lớn thì năng lượng tiêu thụ và độ trễ do di chuyển dữ liệu càng cao, cuối cùng vượt xa năng lượng tiêu thụ của bản thân việc tính toán, từ đó hình thành nên Bức tường Bộ nhớ.
GPU của NVIDIA xây dựng được pháo đài vững chắc nhờ CUDA và NVLink, nhưng vẫn không tránh khỏi điểm nghẽn băng thông gây ra tình trạng GPU nhàn rỗi.
Một công ty mô hình lớn trong nước là Zhipu AI đã làm một thí nghiệm rất đơn giản: một cụm suy luận với 512 card GPU, không thay đổi GPU, không thay đổi mô hình, không thay đổi mã nguồn, chỉ thay giới hạn băng thông mạng từ 200GB/S thành 400GB/S, thông lượng suy luận tăng ngay 10%, độ trễ đầu ra token đầu tiên giảm 19% – lý do rất đơn giản, chỉ cần mở rộng đường, xe sẽ chạy nhanh hơn.
Tuy nhiên, kiến trúc không phải GPU, đại diện là Cerebras, dường như đang xé ra một khe hở trên Bức tường Bộ nhớ.

So sánh kích thước Chip Cerebras WSE-3 và GPU NVIDIA B200
Bản chất của Cerebras: Một cỗ máy tính cận bộ nhớ dựa trên SRAM
Cerebras Systems được Andrew Feldman và những người khác thành lập tại Thung lũng Silicon, đội ngũ sáng lập ban đầu đều đến từ một công ty máy chủ vi mô tiêu thụ điện năng thấp tên là SeaMicro, công ty này sau đó được AMD mua lại, tiếp theo đó:
Năm 2015, đội ngũ sáng lập xác định lộ trình "Tính toán cấp độ Wafer";
Năm 2016, hoàn tất đăng ký, vòng tài trợ Series A, bước vào giai đoạn nghiên cứu ẩn mình;
Năm 2019, ra mắt sản phẩm đầu tiên chip WSE-1 và hệ thống CS-1, dựa trên công nghệ 16nm của TSMC;
Năm 2021, ra mắt sản phẩm thế hệ thứ hai, dựa trên công nghệ 7nm của TSMC;
Năm 2024, ra mắt sản phẩm thế hệ thứ ba (WSE-3 / CS-3), dựa trên công nghệ 5nm của TSMC, chip và hệ thống đều được sản xuất tại Mỹ, là hệ thống chip thuần Mỹ chính hiệu.
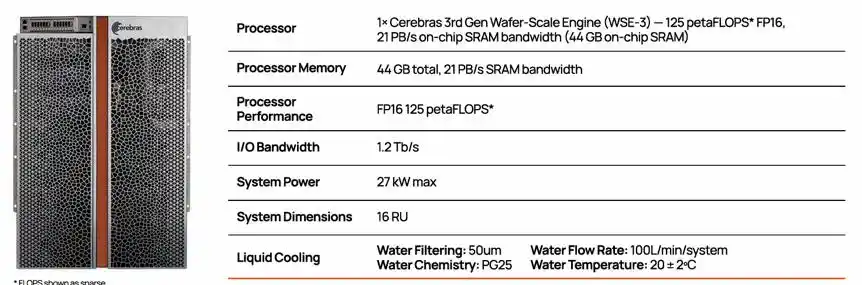
Cấu hình hệ thống CS-3, bao gồm 1 chip WSE-3
Triết lý kiến trúc Bộ xử lý Cấp độ Wafer (Wafer-Scale Engine, WSE) của Cerebras, đơn giản, thô bạo nhưng đánh trúng điểm đau: dùng sự phóng đại cực đại về không gian vật lý để đổi lấy sự nén cực hạn độ trễ di chuyển dữ liệu.
Chip thông thường là cắt một tấm wafer thành nhiều chip nhỏ, ví dụ như GPU của NVIDIA chính là theo hướng này. Cerebras làm ngược lại: không cắt, trực tiếp biến gần như toàn bộ tấm wafer thành một con chip siêu lớn, gọi là Wafer-Scale Engine, WSE.
Chip truyền thống là cắt một tấm wafer đường kính 300mm thành hàng trăm con chip nhỏ; còn Cerebras chọn giữ nguyên toàn bộ tấm wafer, trực tiếp sử dụng làm toàn bộ con chip. WSE-3 mới nhất sở hữu 4 nghìn tỷ bóng bán dẫn, 900 nghìn lõi AI, mỗi lõi được trang bị 48KB SRAM cục bộ, từ đó cho phép SRAM trên chip của toàn bộ chip đạt 44GB, cung cấp băng thông bộ nhớ trên chip (on‐chip memory bandwidth) lên tới 21PB/giây và băng thông mạng (fabric bandwidth) 214Pb/giây, đây là bội số hàng nghìn lần so với băng thông HBM truyền thống.
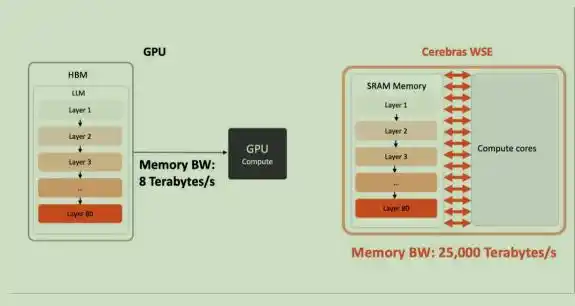
Băng thông bộ nhớ của Cerebras WSE gấp 2625 lần chip đóng gói NVIDIA B200, phá vỡ điểm nghẽn băng thông bộ nhớ trong kịch bản suy luận mô hình lớn.
Trong kiến trúc của Cerebras, trọng số mô hình không bao giờ được lưu trên SRAM, mà nằm trong bộ nhớ ngoài chip MemoryX, và được chuyển dần lên chip lớn theo từng lớp. Cách thức thực hiện là tách biệt việc lưu trữ trọng số mô hình mạng neural với các đơn vị tính toán.
Tất cả trọng số mô hình được lưu trữ bên ngoài trong mô-đun mở rộng bộ nhớ MemoryX, trọng số cần thiết cho tính toán mỗi lớp mạng sẽ được truyền theo yêu cầu từng lớp lên hệ thống CS-3. Trọng số được lưu trữ trong DRAM và bộ nhớ flash của MEMORY X, và được truyền đến hệ thống CS-3 với tốc độ băng thông tối đa. Những trọng số này sẽ không được lưu vào hệ thống CS-3, thậm chí cũng không lưu tạm thời trong bộ đệm, CS-3 dựa vào cơ chế luồng dữ liệu cốt lõi ở tầng thấp để hoàn thành tính toán.
Dựa trên kiến trúc cấp độ wafer, Cerebras thể hiện rào cản có tính chất đánh bại chiều không gian trong suy luận LLM bị giới hạn bởi băng thông bộ nhớ. Khi tạo từng Token, trọng số được truyền dạng luồng từ MemoryX ngoài chip lên CS-3 theo từng lớp, chạy các mô hình khác nhau, tốc độ token nhanh hơn 1.5 - 5 lần so với NVIDIA B200.
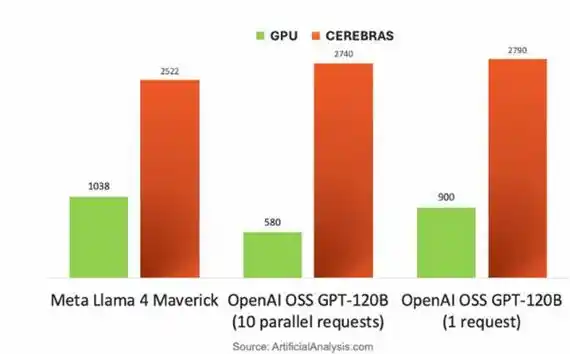
So sánh tốc độ Token khi chạy các mô hình lớn khác nhau giữa GPU NVIDIA DGX B200 và Chip Cerebras CS-3
Lợi thế cốt lõi nằm ở: 44GB SRAM trên chip của CS-3 cung cấp băng thông siêu cao 21 PB/giây (gấp 2625 lần B200) và kết nối 214 Pb/giây, giúp việc truyền luồng trọng số thoát khỏi giới hạn của giao diện HBM. Do đó, trên các khối lượng công việc TTFT (Time To First Token, thời gian từ khi gửi yêu cầu đến khi mô hình trả về token đầu tiên), ngữ cảnh dài và đại lý (agent), biểu hiện đặc biệt nổi bật.
Mặc dù trọng số nằm ngoài MemoryX, được tải theo từng lớp theo yêu cầu và không lưu trong bộ đệm trên chip, CS-3 dựa vào cơ chế luồng dữ liệu cốt lõi để hoàn thành tính toán với độ chính xác FP16 đầy đủ không mất mát trên SRAM; dựa vào khả năng mở rộng hiệu suất tuyến tính, nó cũng giải phóng tổng thông lượng đáng kinh ngạc trong điều kiện suy luận đồng thời nhiều người dùng.
Ngoài băng thông, còn có lợi thế về điện năng tiêu thụ. Gần đây, Chủ tịch Zhongji Innolight Liu Sheng trong bài phát biểu cũng đề cập, yêu cầu của khách hàng đối với mô-đun quang là 1 pJ/bit, trong khi hiện tại là 10 pJ/bit. Trong chip Cerebras, điện năng tiêu thụ của kết nối chỉ là 0.15 pJ/bit, còn điện năng tiêu thụ kết nối của GPU hiện tại là 10 pJ/bit.
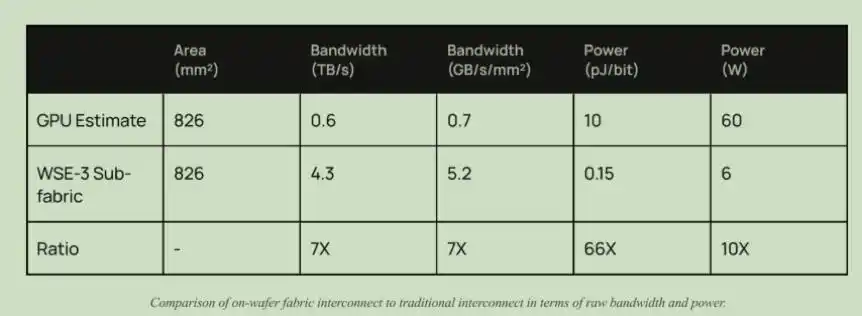
So sánh băng thông và điện năng tiêu thụ giữa kiến trúc kết nối Cerebras và kết nối GPU
Như vậy có thể thấy, nếu kiến trúc chip lớn cấp độ wafer của Cerebras trở thành xu hướng chính trong suy luận, thậm chí huấn luyện AI, có lẽ sẽ tạo ra tác động ức chế và thay đổi cấu trúc đáng kể đối với lượng xuất của mô-đun quang và CPO (đóng gói quang chung). Logic cốt lõi nằm ở: nhu cầu cao đối với mô-đun quang và CPO, về bản chất là để giải quyết điểm nghẽn băng thông của "kết nối giữa các chip" và "kết nối giữa các nút" trong cụm GPU; trong khi kiến trúc của Cerebras lại chính là giải quyết vấn đề thông qua "loại bỏ kết nối phân tán".
Trái với trực giác: "Tổn thương" thực sự và giả tạo của chip lớn cấp độ wafer
Lõi của chip luôn nằm ở Trade Off (nghệ thuật đánh đổi). Cerebras để đạt được băng thông cực hạn của SRAM trên chip, cũng mang lại một số vấn đề.
Tỷ lệ sản xuất thành phẩm (yield) thấp?
Hoàn toàn ngược lại, kích thước mỗi lõi AI riêng lẻ giảm xuống còn 0.05 milimét vuông (bằng 1% kích thước mỗi lõi tính toán của H100), do đó tỷ lệ thành phẩm thực tế lại cao hơn. Thông qua định tuyến trên chip, có thể tắt và bỏ qua các lõi bị lỗi, từ đó làm cho khả năng chịu đựng lỗi tăng lên 100 lần so với bộ xử lý đa lõi truyền thống. Thực tế toàn bộ chip có 1 triệu lõi AI, nhưng có tính đến tỷ lệ thành phẩm, công bố ra ngoài là 900 nghìn lõi AI.
Chỉ giỏi suy luận, không giỏi huấn luyện?
Trong vài năm đầu thành lập Cerebras, huấn luyện là chủ đề chủ đạo, do đó công ty luôn xoay quanh huấn luyện làm nhiều công việc, chỉ là sau khi nhu cầu suy luận bùng nổ, mọi người phát hiện lợi thế của nó trong suy luận rõ ràng hơn.
Thực tế, tính toán phân tán được đơn giản hóa cũng mang lại một loạt lợi thế như giảm độ phức tạp mã nguồn, giảm chi phí truyền thông.
Huấn luyện một mô hình 175 tỷ tham số trên 4000 GPU, thường cần khoảng 20 nghìn dòng mã huấn luyện phân tán.
Cerebras đã đạt được huấn luyện tương đương với 565 dòng mã – toàn bộ mô hình có thể được cài đặt trên wafer, và không cần xử lý sự phức tạp của tính song song dữ liệu.
SRAM co giãn đã chết, lợi thế cốt lõi đối mặt với trần vật lý.
Sản phẩm thế hệ thứ ba dựa trên 5nm của TSMC, dung lượng SRAM của nó chỉ tăng 10% so với sản phẩm thế hệ thứ hai dựa trên 7nm của TSMC, sau 5nm, diện tích đơn vị SRAM hầu như không còn thu nhỏ theo tiến trình công nghệ.
Điều này có nghĩa là Cerebras không thể tiếp tục như trước đây, thông qua nâng cấp tiến trình TSMC (ví dụ từ 5nm lên 3nm) để tăng đáng kể lợi thế cốt lõi (dung lượng SRAM) của mình.
Bị giới hạn bởi kích thước wafer, khả năng tản nhiệt và chi phí sản xuất, tài nguyên lưu trữ như SRAM trên chip khó có thể mở rộng tuyến tính đồng bộ với lõi tính toán, tỷ lệ phân bổ tài nguyên gặp phải điểm nghẽn. Điều này gần như đóng cửa con đường tiến hóa của nó.
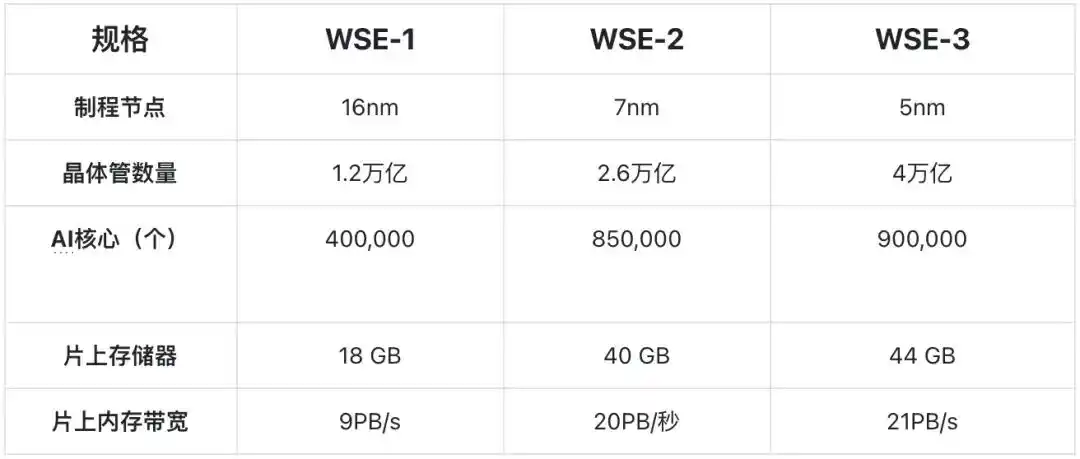
Thông số kỹ thuật ba thế hệ sản phẩm của Cerebras
Tam trùng luyện ngục: Tản nhiệt, công nghệ và hệ sinh thái.
Toàn bộ tấm wafer tập trung phát nhiệt, mật độ dòng nhiệt cao, buộc phải phụ thuộc vào phòng máy tùy chỉnh và hệ thống làm mát chất lỏng chuyên dụng, ngoài ra, tính phổ dụng của hệ sinh thái có nghĩa là khách hàng phải thích ứng với phần mềm tùy chỉnh của nó, khả năng tương thích với các khuôn khổ lập trình phổ dụng hiện có như CUDA yếu, chi phí chuyển đổi và điều chỉnh phần mềm cao.
Băng thông ngoài chip thấp, trở thành "ốc đảo" khó mở rộng.
Do hạn chế của thiết kế vật lý cấp độ wafer, số lượng chân I/O có thể rút ra ở rìa WSE cực kỳ hạn chế, dẫn đến băng thông I/O của nó chỉ là 150GB/giây. So với băng thông hai chiều 1.8TB/giây của NVIDIA NVLink, điều này giống như ốc sên. Điều này có nghĩa là WSE cực kỳ khó mở rộng ra ngoài với tốc độ cao. Mặc dù kết nối SwarmX của Cerebras hoạt động khá tốt trong việc kết hợp nhiều hệ thống, nhưng trước các mô hình siêu lớn cần kết nối đa chip tốc độ cao, băng thông ngoài chip cực thấp đã trở thành xiềng xích vật lý mang tính cấu trúc.
Tranh chấp lộ trình: Các ông lớn tự nghiên cứu, thời gian cửa sổ của Cerebras còn bao lâu?
Các phương pháp của các ông lớn để giải quyết "suy luận cần băng thông cao hơn + độ trễ thấp hơn" không chỉ có một con đường wafer-scale, họ đang thông qua ba con đường song song để vây bắt, lợi nhuận công nghệ của các công ty khởi nghiệp.
1 Chip ASIC tự nghiên cứu
Google TPU v8 đã phân chia thành hai phiên bản chuyên biệt cho huấn luyện và chuyên biệt cho suy luận; AWS Trainium 4 đang trên đường; Microsoft Maia đã được sử dụng nội bộ trong Azure, được xây dựng dựa trên công nghệ 3nm của TSMC, lõi tensor FP8/FP4 nguyên bản, hệ thống bộ nhớ được thiết kế lại, được trang bị 216GB HBM3e, 272MB SRAM trên chip; thậm chí cả Anthropic cũng bắt đầu đánh giá chip suy luận tự nghiên cứu.
Xác suất của con đường này cực cao, nó sẽ trực tiếp dẫn đến việc "mua sắm suy luận của bên thứ ba" vào năm 2028 bị nén giới hạn trên TAM (Thị trường Tổng thể Có thể Đạt được) từ 10% đến 25%.
2 Quá trình phổ dụng hóa công nghệ của lộ trình đóng gói tiêu chuẩn
Đây là đòn đánh hạ thấp chiều không gian trực tiếp nhất đối với Cerebras.
SoW (System-on-Wafer) của TSMC đã mở rộng cho khách hàng sử dụng, interposer CoWoS 9.5x cũng sẽ ra mắt vào năm 2027.
Việc mà hai sản phẩm này làm – ghép nhiều die ở cấp độ wafer – về bản chất chính là phổ dụng hóa, bình dân hóa quy trình vật lý của Cerebras.
Vera Rubin của NVIDIA sẽ bước vào hệ sinh thái này vào nửa cuối năm 2026.
Mặc dù việc ghép cross-reticle do Cerebras tự làm là độc quyền, nhưng thời gian cửa sổ độc quyền dài nhất chỉ từ 2 đến 3 năm, sau năm 2027 - 2028, rào cản công nghệ của nó sẽ bị làm loãng bởi đóng gói tiên tiến của TSMC.
3 Sự đột phá của kết nối quang/tính toán quang
Kết nối và Bức tường Bộ nhớ của chip điện tử đã đạt đến giới hạn, băng thông cao, độ trễ thấp, nhiễu chéo bằng không của photon là giải pháp cuối cùng.
Lộ trình quang học đại diện bởi Lumentum đang trỗi dậy. Ưu thế lớn nhất của Wafer-scale là tính toán trên chip, nhưng mô hình chắc chắn sẽ ngày càng lớn, kết nối tốc độ cao mở rộng trên wafer scale là nhu cầu cứng.
Với sự trưởng thành của CPO (đóng gói quang chung) và Kết nối Quang học, trong tương lai chúng ta rất có thể sẽ thấy I/O quang được đưa trực tiếp vào wafer WSE, phá vỡ xiềng xích kết nối điện; và NVIDIA cũng có thể thông qua việc mua lại các công ty có ưu thế kiến trúc đặc thù như LPU (ví dụ Groq), kết hợp với kết nối quang, phát triển hệ thống cấp độ wafer tương thích với phần mềm siêu nút NV hiện có.
Chạy nước rút trên vách đá: Thương mại và giao hàng của Cerebras
Cerebras hiện đang đối mặt với một cuộc chạy nước rút trên vách đá, bị thúc ép bởi các đơn hàng khổng lồ.
Các giao dịch với khách hàng lớn hàng đầu như OpenAI, buộc Cerebras chuyển đổi từ một công ty chip thành một nhà cung cấp dịch vụ đám mây kiểu mới. Nó không chỉ còn bán phần cứng, mà cần phải trong thời gian ngắn khóa chặt và xây dựng cơ sở hạ tầng điện lực và công trình trung tâm dữ liệu khổng lồ.
Theo yêu cầu hợp đồng, Cerebras cần giao công suất trung tâm dữ liệu 250MW mỗi năm trong giai đoạn 2026 - 2028. Tuy nhiên, yêu cầu của hệ thống cấp độ wafer đối với phòng máy cực cao, không thể nhét trực tiếp vào IDC làm mát bằng không khí truyền thống. Hiện tại, tiến độ chuẩn bị công suất trung tâm dữ liệu của Cerebras đã tụt hậu rõ ràng so với yêu cầu hợp đồng.
Từ quá trình sản xuất thử đến xây dựng nhà máy, từ phê duyệt điện lực đến triển khai hệ thống làm mát, đây là một vũng lầy tài sản nặng, chu kỳ dài.
Kết: Rẽ trái hay rẽ phải?
Quay lại mệnh đề ban đầu, khi điểm ngoặt tính toán suy luận đã đến, cốt lõi của kiến trúc tính toán luôn nằm ở sự đánh đổi.
Không có đúng sai tuyệt đối, chỉ có giải pháp tối ưu tương đối dưới khối lượng công việc quan trọng nhất. Khối lượng công việc thực tế đã thay đổi.
Cerebras rẽ trái, chọn tối ưu hóa vật lý cực hạn, dùng toàn bộ wafer và SRAM khổng lồ để đổi lấy độ trễ cực thấp trong nhiệm vụ đơn lẻ, điều này là vô địch trong các kịch bản cực kỳ nhạy cảm với độ trễ token đầu tiên.
NVIDIA rẽ phải, chọn duy trì tính phổ dụng, dùng HBM + NVLink + thông lượng cụm siêu lớn để đối phó với sự thay đổi muôn hình vạn trạng của khối lượng công việc, lấy bất biến ứng vạn biến.
Gió nổi mây vần, con đường phía trước chưa thể đoán định. Chính sự không chắc chắn song trùng này về công nghệ và thương mại mới ấp ủ khả năng đột phá. Trong dòng chảy tính toán hướng tới AGI, đưa ra kết luận bây giờ còn quá sớm – bởi vì không chắc chắn, mới có cơ hội.
Bài viết này từ tài khoản công chúng WeChat "Garlic Particle Machine Research Institute", tác giả: Pili Youxia