Los modelos grandes han seguido creciendo en tamaño, y la opinión predominante sostiene que cuantos más parámetros tenga el modelo, más se acercará a la forma de pensar humana. Sin embargo, un artículo publicado el 1 de abril en Nature Communications por un equipo de la Universidad de Zhejiang presenta una perspectiva diferente (enlace al artículo: https://www.nature.com/articles/s41467-026-71267-5). Descubrieron que cuando la escala del modelo (principalmente SimCLR, CLIP, DINOv2) aumenta, la capacidad de reconocer objetos concretos efectivamente continúa mejorando, pero la capacidad de comprender conceptos abstractos no solo no mejora, sino que incluso puede disminuir. Cuando los parámetros aumentaron de 22.06 millones a 304.37 millones, el rendimiento en tareas de conceptos concretos subió del 74.94% al 85.87%, mientras que en tareas de conceptos abstractos bajó del 54.37% al 52.82%.
La diferencia entre la forma de pensar humana y la de los modelos
Cuando el cerebro humano procesa conceptos, forma primero un conjunto de relaciones de categorización. Un cisne y un búho tienen un aspecto diferente, pero el humano los clasifica dentro de la categoría 'ave'. Subiendo de nivel, aves y caballos pueden seguir agrupándose en la categoría 'animal'. Al ver algo nuevo, los humanos a menudo piensan primero: ¿a qué cosa vista anteriormente se parece y a qué categoría pertenece大概? Los humanos aprenden continuamente nuevos conceptos, luego organizan esa experiencia y utilizan este marco de relaciones para reconocer nuevos objetos y adaptarse a nuevas situaciones.
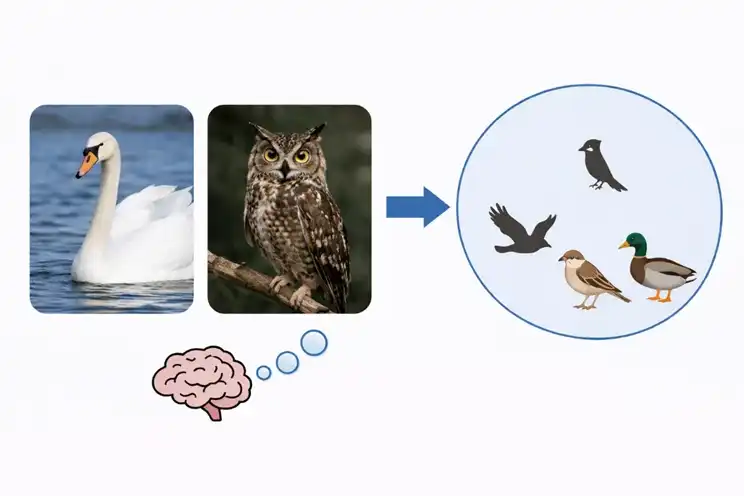
Los modelos también categorizan, pero la forma en que lo hacen es diferente. Se basan principalmente en patrones que aparecen repetidamente en grandes volúmenes de datos. Cuanto más aparece un objeto concreto, más fácil le resulta al modelo reconocerlo. Sin embargo, cuando se trata de categorías más amplias, el modelo tiene más dificultades. Necesita captar los puntos en común entre múltiples objetos y luego agrupar esos puntos comunes en la misma categoría. Los modelos actuales tienen una debilidad evidente aquí. A medida que los parámetros siguen aumentando, el rendimiento en tareas de conceptos concretos mejora, mientras que el de conceptos abstractos a veces disminuye.

El punto en común entre el cerebro humano y los modelos es que ambos forman internamente un conjunto de relaciones de categorización. Pero sus énfasis son diferentes: las regiones visuales de alto orden del cerebro humano categorizan naturalmente clases amplias como 'seres vivos' y 'objetos inanimados'. Los modelos pueden distinguir objetos concretos, pero les cuesta mucho formar establemente estas categorías más amplias. Esta diferencia hace que al cerebro humano le resulte más fácil aplicar experiencias previas a nuevos objetos, por lo que podemos clasificar rápidamente cosas nunca vistas. Los modelos, en cambio, dependen más del conocimiento existente, por lo que al encontrarse con un nuevo objeto, tienden a quedarse en las características superficiales. El método propuesto en el artículo se desarrolla en torno a esta característica, utilizando señales cerebrales para restringir la estructura interna del modelo y acercarla más a la forma de categorizar del cerebro humano.
La solución del equipo de la Universidad de Zhejiang
La solución que propone el equipo también es singular: no se trata de seguir añadiendo parámetros, sino de utilizar una pequeña cantidad de señales cerebrales como supervisión. Estas señales cerebrales provienen de registros de la actividad cerebral de personas mientras miran imágenes. El artículo original dice: transferir las estructuras conceptuales humanas (human conceptual structures) a las DNNs. Es decir, intentar enseñar al modelo cómo categoriza, cómo generaliza y cómo agrupa conceptos similares el cerebro humano.
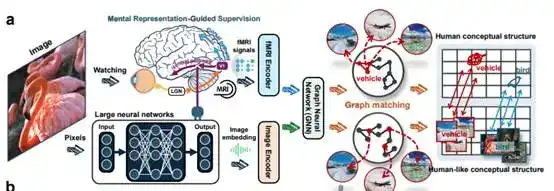
El equipo realizó experimentos con 150 categorías de entrenamiento conocidas y 50 categorías de prueba no vistas anteriormente. Los resultados mostraron que, a medida que avanzaba este entrenamiento, la distancia entre el modelo y la representación cerebral se reducía continuamente. Este cambio se produjo en ambas categorías, lo que indica que el modelo no está aprendiendo muestras individuales, sino que realmente comienza a aprender una forma de organizar los conceptos más cercana a la del cerebro humano.
Después de este entrenamiento, el modelo mostró una mayor capacidad de aprendizaje con muy pocas muestras y un mejor rendimiento ante nuevas situaciones. En una tarea donde se le daban muy pocos ejemplos pero se le pedía que distinguiera conceptos abstractos como 'ser vivo' y 'no vivo', el modelo mejoró una media del 20.5%, superando incluso a modelos de control mucho más grandes en número de parámetros. El equipo también realizó 31 pruebas específicas adicionales, donde varios tipos de modelos mostraron una mejora de casi un diez por ciento.
En los últimos años, el camino familiar para la industria de los modelos ha sido el de modelos más grandes. El equipo de la Universidad de Zhejiang ha elegido otra dirección: pasar de 'más grande es mejor' (bigger is better) a 'mejor estructurado es más inteligente' (structured is smarter). La expansión de escala es ciertamente útil, pero principalmente mejora el rendimiento en tareas conocidas. La capacidad de comprensión abstracta y transferencia humana es igualmente crucial para la IA, lo que requiere que en el futuro la estructura de pensamiento de la IA se acerque más a la del cerebro humano. El valor de esta dirección reside en que redirige la atención de la industria desde la mera expansión de escala de vuelta a la propia estructura cognitiva.
Neosoul y el futuro
Esto plantea una posibilidad mayor: la evolución de la IA podría no ocurrir solo en la fase de entrenamiento del modelo. El entrenamiento del modelo puede determinar cómo la IA organiza los conceptos, cómo forma estructuras de juicio de mayor calidad. Luego, una vez en el mundo real, comienza otra capa de evolución para la IA: cómo se registran y verifican las decisiones de los agentes de IA, cómo crecen y evolucionan continuamente en una competencia mutua real, aprendiendo y evolucionando por sí mismos como los humanos. Esto es precisamente lo que Neosoul está haciendo ahora. Neosoul no solo hace que los agentes de IA produzcan respuestas, sino que los coloca en un sistema de predicción continua, verificación, liquidación y selección, optimizándose constantemente en la predicción y los resultados, preservando las mejores estructuras y descartando las peores. Lo que el equipo de la Universidad de Zhejiang y Neosoul señalan conjuntamente es, en realidad, el mismo objetivo: que la IA no solo sepa resolver problemas, sino que tenga una capacidad de pensamiento integral y evolucione continuamente.





