Autor: Vaidik Mandloi
Título original: Know Your Agent
Compilación y organización: BitpushNews
La promesa de que los agentes de IA (AI Agents) cambiarán el panorama de Internet se está convirtiendo gradualmente en realidad. Han trascendido de ser herramientas experimentales en ventanas de chat para convertirse en una parte indispensable de nuestras operaciones diarias: desde limpiar bandejas de entrada, programar reuniones hasta responder a tickets de soporte, están aumentando silenciosamente la productividad, un cambio que a menudo pasa desapercibido.
Sin embargo, este crecimiento no es solo anecdótico.
Para 2025, el tráfico automatizado superó al tráfico humano, representando el 51% de la actividad total en la web. Solo el tráfico impulsado por IA en sitios web minoristas de EE. UU. aumentó un 4,700% interanual. Los agentes de IA ahora operan a través de sistemas internos, muchos con capacidad para acceder a datos, activar flujos de trabajo e incluso iniciar transacciones.
Sin embargo, la confianza en agentes completamente autónomos se redujo de 43% a 22% en un año, atribuido en gran medida a incidentes de seguridad en aumento. Casi la mitad de las empresas aún utilizan claves API compartidas para autenticar agentes, un método nunca diseñado para permitir que sistemas autónomos muevan valor o actúen de forma independiente.
El problema es: los agentes se están escalando más rápido que la infraestructura diseñada para gobernarlos.
En respuesta, están surgiendo nuevas pilas de protocolos. Las stablecoins, integraciones con redes de tarjetas y estándares nativos para agentes como x402 están permitiendo transacciones iniciadas por máquinas. Simultáneamente, se están desarrollando nuevas capas de identidad y verificación para ayudar a los agentes a identificarse y operar en entornos estructurados.
Pero habilitar pagos no equivale a habilitar una economía. Porque una vez que los agentes pueden mover valor, surgen preguntas más fundamentales: ¿cómo descubren de forma legible por máquina el servicio adecuado? ¿Cómo prueban identidad y autorización? ¿Cómo verificamos que las acciones que afirman realizar realmente ocurrieron?
Este artículo explorará la infraestructura necesaria para que una economía impulsada por agentes funcione a escala y evaluará si estas capas están lo suficientemente maduras para soportar participantes autónomos y persistentes que operan a velocidad de máquina.
Los agentes no pueden comprar lo que no ven
Antes de que un agente pague por un servicio, primero debe encontrarlo. Suena simple, pero es actualmente donde hay mayor fricción.
Internet fue construida para que los humanos lean páginas. Cuando un humano busca contenido, los motores de búsqueda devuelven enlaces clasificados. Estas páginas están optimizadas para la persuasión. Están llenas de diseños, rastreadores, anuncios, barras de navegación y elementos de estilo, que tienen sentido para las personas pero son principalmente "ruido" para las máquinas.
Cuando un agente solicita la misma página, recibe HTML crudo. Una publicación de blog o página de producto típica en esta forma puede requerir alrededor de 16,000 tokens. Cuando se convierte a un archivo Markdown limpio, el conteo de tokens se reduce a aproximadamente 3,000. Esto significa que el modelo debe procesar un 80% menos de contenido. Para una sola solicitud, esta diferencia puede ser irrelevante. Pero cuando un agente hace miles de estas solicitudes a través de múltiples servicios, el procesamiento excesivo se traduce en latencia, costos y mayor complejidad de inferencia.
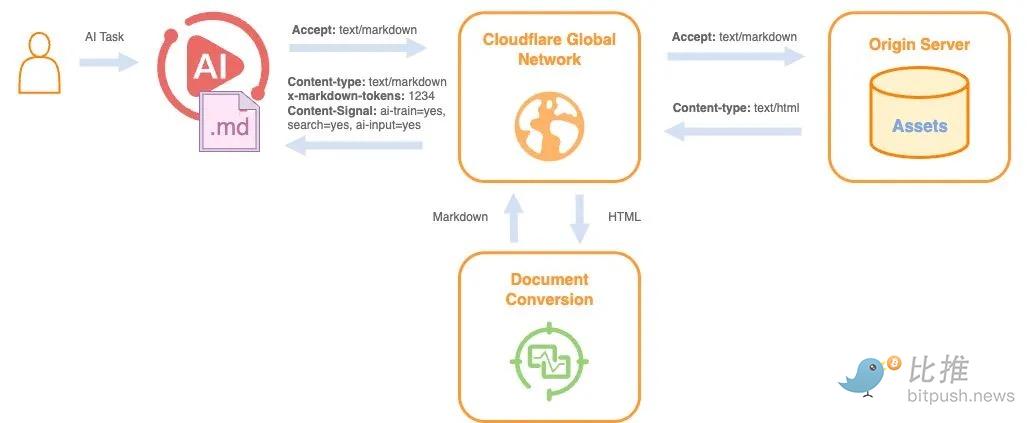
@Cloudflare
Los agentes terminan gastando una gran cantidad de esfuerzo computacional para eliminar elementos de la interfaz antes de poder acceder a la información central necesaria para actuar. Este esfuerzo no mejora la calidad de la salida, solo compensa una web que nunca fue diseñada para ellos.
A medida que crece el tráfico impulsado por agentes, esta ineficiencia se vuelve más evidente. El rastreo impulsado por IA en sitios web minoristas y de software ha aumentado significativamente en el último año y ahora representa la mayor parte de la actividad total de la web. Simultáneamente, alrededor del 79% de los principales sitios web de noticias y contenido bloquean al menos un rastreador de IA. Desde su perspectiva, esta reacción es comprensible. Los agentes extraen contenido sin interactuar con anuncios, suscripciones o embudos de conversión tradicionales. Bloquearlos protege los ingresos.
El problema es que la web no tiene una forma confiable de distinguir entre rastreadores maliciosos y agentes de abastecimiento legítimos. Ambos se presentan como tráfico automatizado, ambos se originan en infraestructura cloud. Para el sistema, se ven iguales.
El problema más profundo es que los agentes no intentan "consumir" la página, intentan descubrir posibilidades de acción.
Cuando un humano busca "boletos de avión por debajo de 500 dólares", una lista de enlaces clasificados es suficiente. La persona puede comparar opciones y tomar una decisión. Cuando un agente recibe la misma instrucción, necesita algo completamente diferente. Necesita saber qué servicios aceptan solicitudes de reserva, qué formato de entrada requieren, cómo se calculan los precios y si el pago se puede liquidar de forma programática. Muy pocos servicios publican esta información claramente.
@TowardsAI
Es por eso que la conversación está pasando de la Optimización para Motores de Búsqueda (SEO) a la Capacidad de Descubrimiento Orientada a Agentes (Agent-Oriented Discoverability), a menudo llamada AEO. Si el usuario final es un agente, clasificar en la página de resultados de búsqueda se vuelve menos importante. Lo que importa es si un servicio puede describir sus capacidades de una manera que un agente pueda interpretar sin adivinar. Si no puede, corre el riesgo de volverse "invisible" en una participación cada vez mayor de la actividad económica.
Los agentes necesitan identidad
@Hackernoon
Una vez que un agente puede descubrir servicios e iniciar transacciones, el siguiente problema principal es hacer que el sistema del otro extremo sepa con quién está tratando. En otras palabras: identidad.
Los sistemas financieros actuales ejecutan muchas más identidades de máquinas que humanas. En las finanzas, la proporción de identidades no humanas frente a humanas es de aproximadamente 96 a 1. Las API, cuentas de servicio, scripts automatizados y agentes internos dominan la infraestructura institucional. La mayoría nunca fue diseñada para tener discreción sobre el capital. Ejecutan instrucciones predefinidas, no pueden negociar, elegir proveedores o iniciar pagos en redes abiertas.
Los agentes autónomos cambian este límite. Si un agente puede mover stablecoins directamente o activar un flujo de pago sin confirmación manual, la pregunta central pasa de "¿Puede pagar?" a "¿Quién lo autorizó a pagar?"
Aquí es donde la identidad se vuelve fundamental, y toma forma el concepto de "Conoce a Tu Agente" (Know Your Agent).
Así como las instituciones financieras verifican a los clientes antes de permitirles operar, los servicios que interactúan con agentes autónomos deben verificar tres cosas antes de conceder acceso a capital u operaciones sensibles:
-
Autenticidad criptográfica: ¿Este agente realmente controla las claves que dice usar?
-
Permisos delegados: ¿Quién concedió los permisos a este agente y cuáles son sus límites?
-
Vinculación con el mundo real: ¿Está este agente vinculado a una entidad con responsabilidad legal?
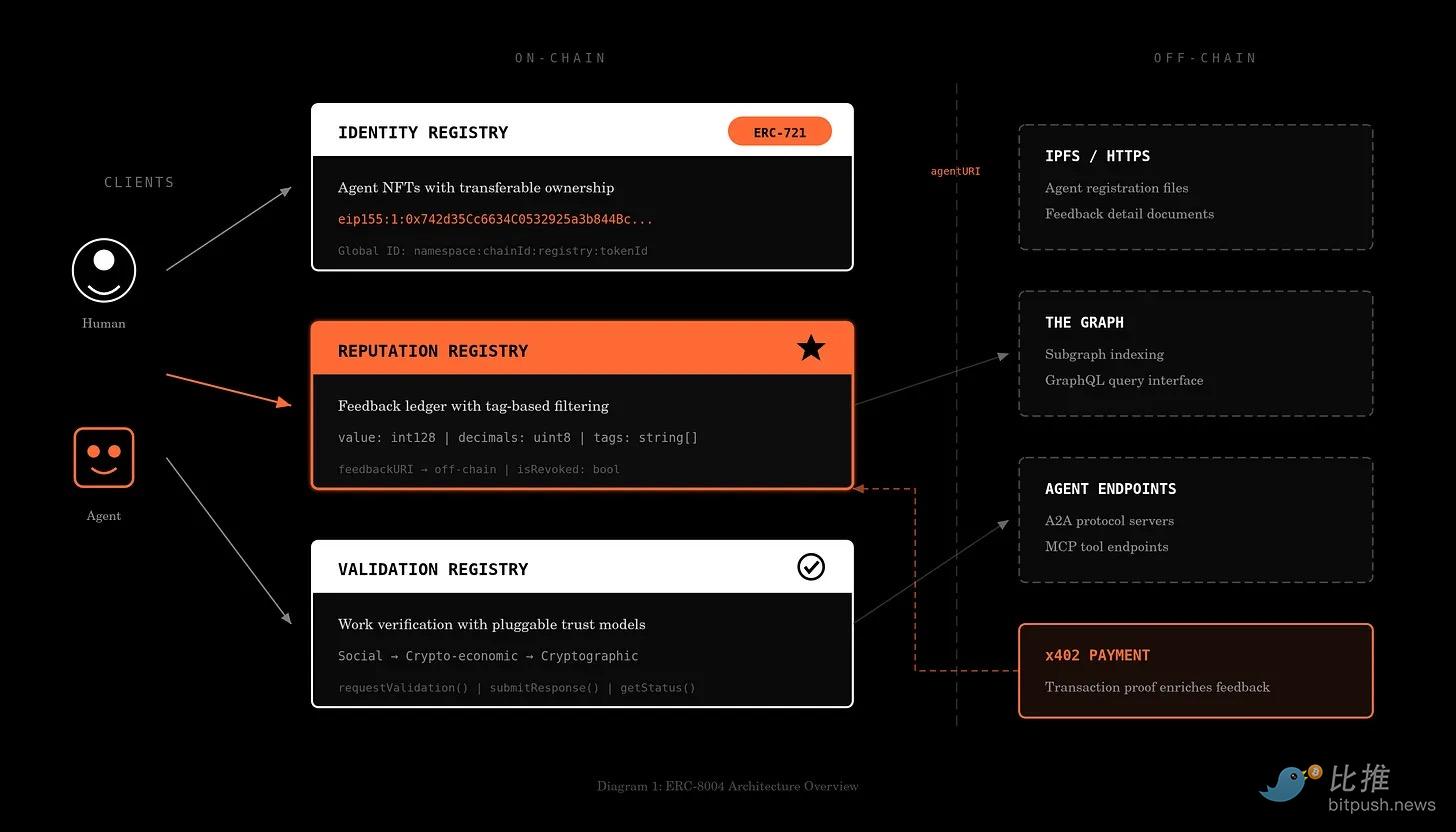
Estas verificaciones constituyen conjuntamente la pila de identidad:
-
En la base está la generación de claves criptográficas y la firma. Estándares como ERC-8004 intentan formalizar cómo un agente puede anclar una identidad en un registro verificable en cadena.
-
La capa intermedia es la de proveedores de identidad. Esto vincula las claves a entidades del mundo real, como empresas registradas, instituciones financieras o individuos verificados. Sin esta vinculación, una firma solo puede demostrar control, no responsabilidad.
-
La capa perimetral es la infraestructura de verificación. Los procesadores de pago, CDN o servidores de aplicaciones verifican firmas en tiempo real, comprueban credenciales relevantes y aplican límites de permisos. El Protocolo de Agente Confiable (Trusted Agent Protocol) de Visa es un ejemplo de comercio permitido que permite a los comerciantes verificar si un agente está autorizado para realizar transacciones en nombre de un usuario específico. El Protocolo de Comercio para Agentes (ACP) de Stripe está llevando verificaciones similares a checkout programables y flujos de stablecoins.
Mientras tanto, el Protocolo de Comercio Universal (UCP), liderado por Google y Shopify, permite a los comerciantes publicar "listas de capacidades" que los agentes pueden descubrir y con las que pueden negociar. Actúa como una capa de orquestación y se espera que se integre en la Búsqueda de Google y Gemini.
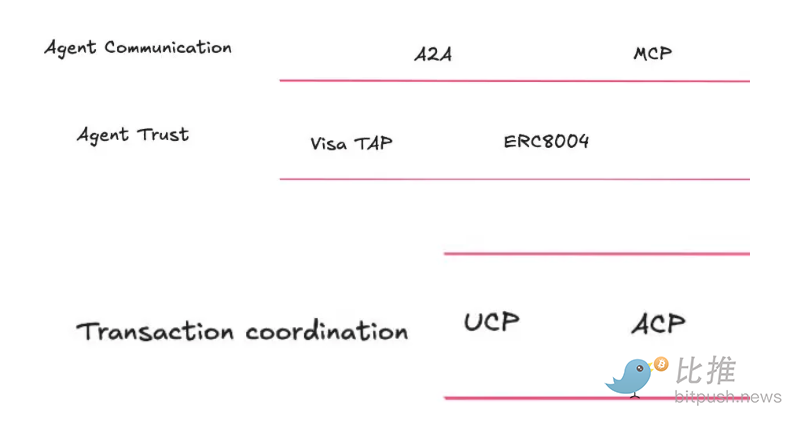
@FintechBrainfood
El matiz importante es que los sistemas sin permiso (permissionless) y con permiso (permissioned) coexistirán.
En blockchains públicas, los agentes pueden realizar transacciones sin umbrales centralizados. Esto mejora la velocidad y la composibilidad, pero también aumenta la presión de cumplimiento. La adquisición de Bridge por parte de Stripe subraya esta tensión. Las stablecoins permiten transferencias transfronterizas instantáneas, pero las obligaciones de cumplimiento no desaparecen porque la liquidación ocurra on-chain.
Esta tensión inevitablemente atrae a los reguladores. Una vez que los agentes autónomos pueden iniciar transacciones financieras e interactuar con mercados sin supervisión humana directa, las cuestiones de responsabilidad se vuelven ineludibles. El sistema financiero no puede permitir que el capital fluya a través de actores no identificados o no autorizados, incluso si esos actores son fragmentos de software.
Ya se están adoptando marcos regulatorios. La Ley de IA de Colorado entró en vigor el 1 de febrero de 2026, introduciendo requisitos de responsabilidad para sistemas automatizados de alto riesgo, y legislación similar avanza a nivel mundial. A medida que los agentes comiencen a ejecutar decisiones financieras a escala, la identidad dejará de ser opcional. Si la capacidad de descubrimiento hace visible al agente, la identidad son las credenciales que lo hacen reconocible.
Verificando la ejecución y reputación del agente
Una vez que los agentes comienzan a realizar tareas que involucran dinero, contratos o información sensible, solo tener identidad puede no ser suficiente. Un agente verificado aún podría alucinar, falsear su trabajo, filtrar información o tener un rendimiento deficiente.
Por lo tanto, la pregunta más importante es: ¿se puede probar que el agente realmente completó el trabajo que afirma haber hecho?
Si un agente declara que analizó 1,000 documentos, detectó patrones de fraude o ejecutó una estrategia de trading, debe haber una forma de verificar que este cálculo realmente ocurrió y que la salida no fue falsificada o dañada. Para ello, necesitamos una capa de rendimiento que lo permita.
Actualmente hay tres enfoques para lograrlo:
-
TEEs (Entornos de Ejecución Confiables): El primer enfoque se basa en la attestation a través de hardware como AWS Nitro e Intel SGX. En este modelo, el agente se ejecuta dentro de un enclave seguro que emite certificados criptográficos confirmando que un código específico se ejecutó en datos específicos y no fue alterado. La sobrecarga suele ser menor (alrededor de un 5-10% de latencia adicional), aceptable para casos de uso empresariales y financieros donde la integridad es más importante que la velocidad.
-
ZKML (Aprendizaje Automático de Cero Conocimiento): El segundo enfoque es matemático. ZKML permite a los agentes generar pruebas criptográficas de que una salida fue producida por un modelo específico sin revelar los pesos del modelo o las entradas privadas. DeepProve-1 de Lagrange Labs demostró recientemente la inferencia completa de GPT-2 con pruebas de cero conocimiento, de 54 a 158 veces más rápido que métodos anteriores.
-
Seguridad de Re-staking (Restake Security): El tercer modelo aplica la corrección mediante incentivos económicos en lugar de computacionales. Protocolos como EigenLayer introducen seguridad basada en staking, donde los validadores apost capital detrás de la salida de un agente. Si la salida es cuestionada y demostrada como falsa, se produce un recorte (Slashing) del stake. El sistema no prueba cada cálculo, sino que hace que el comportamiento deshonesto sea económicamente irracional.
Estos mecanismos abordan el mismo problema desde diferentes ángulos. Sin embargo, las pruebas de ejecución son episódicas. Verifican una tarea única, pero el mercado necesita algo acumulativo. Aquí es donde la reputación se vuelve crucial.
La reputación transforma pruebas aisladas en un historial de rendimiento a largo plazo. Los sistemas emergentes apuntan a hacer que el rendimiento del agente sea portable y anclado criptográficamente, en lugar de depender de evaluaciones específicas de plataforma o paneles internos opacos.
El Servicio de Pruebas de Ethereum (EAS) permite a usuarios o servicios emitir attestations firmadas y on-chain sobre el comportamiento de un agente. Una finalización exitosa de una tarea, una predicción precisa o una transacción compliant pueden registrarse de manera resistente a la manipulación y moverse con el agente a través de aplicaciones.
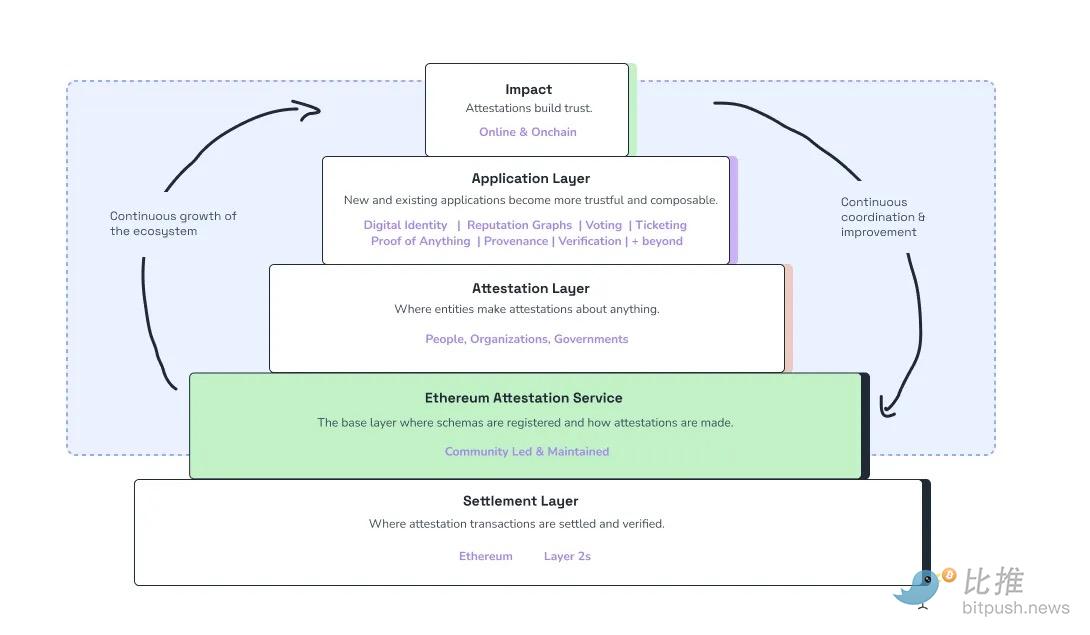
@EAS
También se están formando entornos de evaluación comparativa competitivos. Las Arenas de Agentes (Agent Arenas) evalúan agentes en base a tareas estandarizadas y los clasifican utilizando sistemas de puntuación como Elo. Recall Network informa que más de 110,000 participantes generaron 5.88 millones de predicciones, creando datos de rendimiento medibles. A medida que estos sistemas se expanden, comienzan a parecerse a un mercado de calificaciones real para agentes de IA.
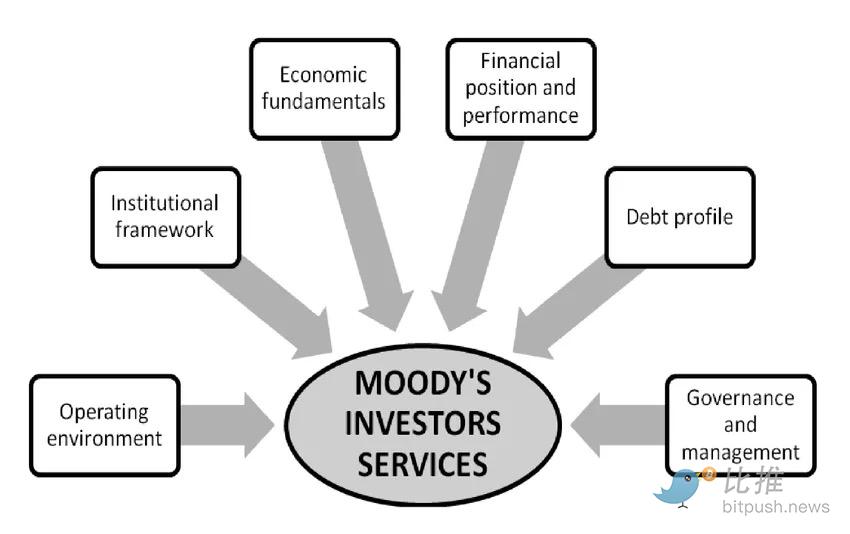
Esto permite que la reputación sea portable entre plataformas.
En las finanzas tradicionales, agencias como Moody's califican bonos para emitir señales de crédito. Una economía de agentes necesitará una capa equivalente para calificar a los actores no humanos. El mercado necesita evaluar si un agente es lo suficientemente confiable para delegarle capital, si sus salidas son estadísticamente consistentes y si su comportamiento es estable a largo plazo.
Conclusión
A medida que los agentes comienzan a tener autoridad real, el mercado necesitará una forma explícita de medir su confiabilidad. Los agentes llevarán registros portables de rendimiento basados en ejecución verificada y evaluación comparativa, con puntajes que se ajustan a medida que la calidad decae, y permisos rastreables hasta una autorización clara. Aseguradores, comerciantes y sistemas de cumplimiento confiarán en estos datos para decidir qué agentes pueden acceder a capital, datos o flujos de trabajo regulados.
En resumen, estas capas comienzan a constituir la infraestructura de la economía de agentes:
-
Capacidad de Descubrimiento (Discoverability): Los agentes deben poder descubrir servicios de forma legible por máquina, de lo contrario no pueden encontrar oportunidades.
-
Identidad (Identity): Los agentes deben probar quiénes son y quién los autorizó, de lo contrario no pueden ingresar a los sistemas.
-
Reputación (Reputation): Los agentes deben establecer un registro verificable que demuestre que son confiables, ganando así confianza económica continua.
Twitter:https://twitter.com/BitpushNewsCN
Grupo de Telegram de Bitpush:https://t.me/BitPushCommunity
Suscripción de Telegram de Bitpush: https://t.me/bitpush






